文献阅读:基于时延深度神经网络的说话人识别通用背景模型
论文
论文:TIME DELAY DEEP NEURAL NETWORK-BASED UNIVERSAL BACKGROUND MODELS FOR SPEAKER RECOGNITION
摘要
DNN被引入i-vector说话人识别系统并取得了显著的性能提升。在这些系统中,DNN被用于搜集充足的统计量用于i-vector的提取。在本研究中使用的DNN是最近被开发的延时深度神经网络(TDNN),该网络在大词汇量连续语音识别任务中取得了良好的效果。我们认为基于时延深度神经网络的系统在SRE10上取得了最好的报告结果,并且相对于基准系统在EER上取得了50%的提升。对于一些应用,DNN的计算花销过高。因此,我们也研究了一种轻量级的选择–一种派生自TDNN后验值的有监督的GMM。这种方法保持了传统无监督GMM的速度并且在EER上实现了20%的相对提升。
提出了两种模型,一种是TDNN,性能很好,但计算花销大,一种是sup-GMM,也比baseline性能好,并且速度快计算花销。
模型结构
论文介绍两种文本无关的说话人识别方法,其中GMM-UBM作为基准系统,sup-GMM和TDNN-UBM是提出的方法,其中使用的DNN的配置也做了简要介绍。
基准系统:GMM-UBM

1.模型:输入(60-d) → \rightarrow →UBM(2048,4096,5297-c) → \rightarrow →i-vector extractor(600-d) → \rightarrow →PLDA;
2.输入:共60维,20维MFCC+Delta+acceleration,25ms帧长,平均归一化,3s窗口,基于能量的VAD;
3.UBM:full-covariance GMM with 2048, 4096, and 5297 components;
4.i-vector:600-d,均值减法,长度归一化;
5.PLDA:i-vector的均值m,类间和类内协方差矩阵Γ 和 Λ 。
sup-GMM
与Fig1中的系统不同的是sup-GMM使用DNN的后验以及说话人特征(即MFCC)来生成,与无监督的GMM的不同仅在UBM的训练过程,i-vector提取过程中都如Fig.1所示。

PS:该图来自[2],本论文中并没有,我将它放在这里方便理解,同时本文使用的UBM模型与[2]中UBM模型不同是本文模型使用了全协方差(full-covariance)。
DNN配置
TDNN
该系统基于[1]中描述的多重时延深度神经网络。从第一层开始到最后一层,输入的上下文的时间跨度逐渐增大,这种做法会让后面的层能学习到更多时间上的关系。
1.输入:MFCC(40-d),25ms帧长,无倒谱减法,等效于滤波器组,但更易压缩,倒谱均值减法(6s窗口);
2.激活函数:p-norm(p=2)
3.输出层:softmax
TDNN共有6层,具体连接配置类似[1]中所示。[t-2,t+2] → \rightarrow →输入层(layer 0),在第1层、第3层和第4层,我们分别将帧{t−2,t + 1}、{t−3,t + 3}和{t−7,t + 2}拼接在一起。总之,DNN的左上下文为13,右上下文为9.(注意‘[ ]'和’{ }‘的不同,前者表示一串连续的帧叠加,后者表示括号中的两个帧叠加,具体参见[1)。
TDNN-UBM
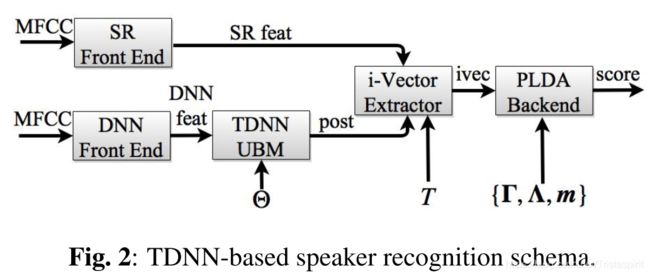
模型结构:首先输入MFCC到一个DNN(TDNN),然后使用DNN的输出(后验)以及说话人特征创建一个UBM,也就是之前提到的sup-GMM,然后使用UBM的输出以及声学特征生成一个TDNN,然后使用该TDNN的后验以及说话人特征提取i-vectro。如下图:
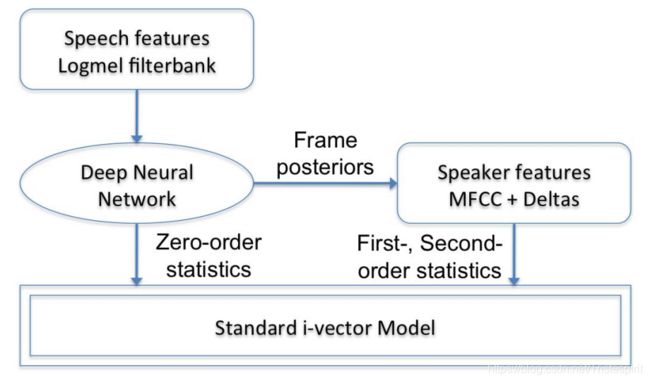
PS:该图来自[2],本论文中同样没有,放在这里结合之前一张同样来自[2]的图片方便理解该模型。
在i向量提取过程中,它与之前基于gmm的系统的唯一区别是该模型被用于计算后验。结合说话人识别特征,TDNN后端为i向量提取创建了足够的统计信息。与其他系统一样,说话人识别特征使用帧级VAD进行过滤。然而,为了保持正确的时间上下文,我们不能从TDNN输入特征中删除帧。相反,VAD的结果被用来过滤出对应于非语音帧的后验值,也就是说最终被删除的是非语音帧对应的后验值。
数据集
评估系统:SRE10 条件5的扩展任务;
UBM和i矢-vector extractor的训练数据:2010年之前,SWB和NIST SREs的男性和女性话语。SWB数据包含1962个说话人和20905个SWB移动电话、SWB 2阶段II和III的语音。SRE数据集包括3,805个说话者和36,614个话语。为了创建域内系统,PLDA后端只对SRE数据进行训练。Fisher的英语部分大约有1800小时用于训练TDNN。
结果

本文对总共3种系统在SRE10 C5数据集上对EER以及DCF的10-2和10-3阶3个指标进行了比较,结果如上表,GMM-2048,GMM-4096和GMM-5297没有特别大的性能差距,不过GMM-5297在性别无关的EER上表现稍好,所以选择其为基准模型。
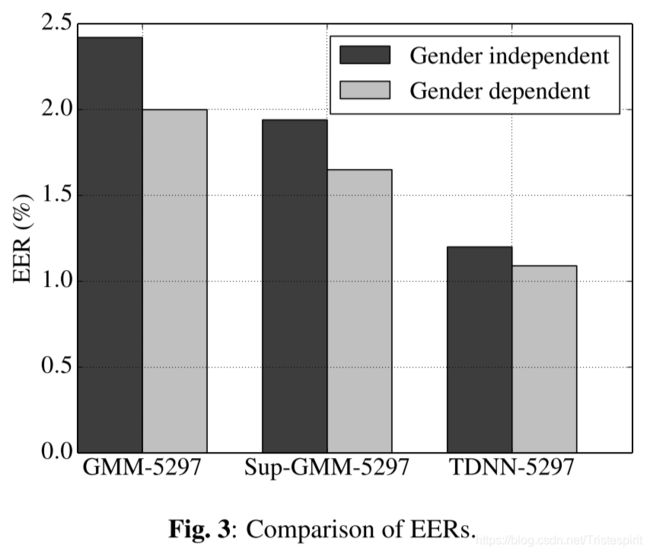
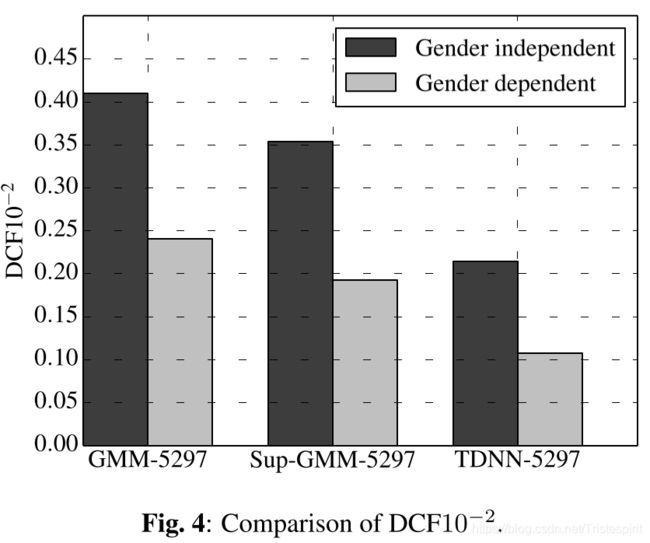

Fig.3到Fig.5比较了GMM-5297, sup-GMM-5297 和TDNN-52973种系统,其中基于DNN的系统性能最好,TDNN-5297获得性别独立和性别依赖的EERs分别为1.20%和1.09%。
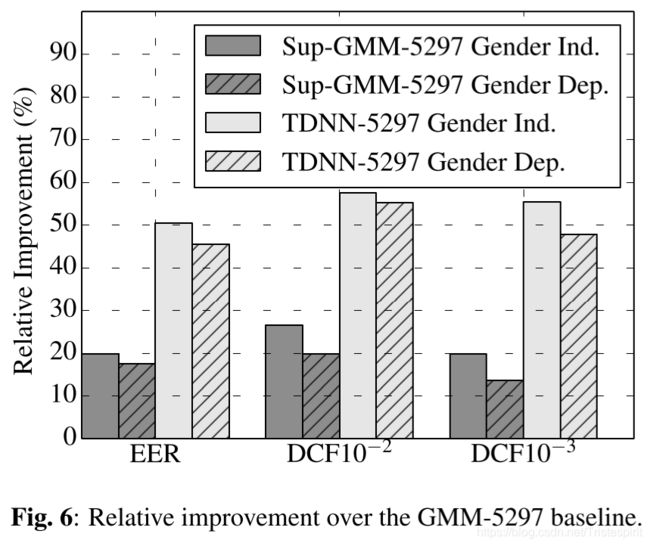
图6展示了TDNN和sup-GMM相对于基准系统的提升,虽然sup-GMM性能并没有胜过TDNN,但其性能仍比基准系统高出许多。作者还进行了猜测,也许TDNN取得高性能的潜在原因时因为使用了sup-GMM,而sup-GMM保持模型能力的原因是使用了全协方差。
之后就是对几个模型运行时间的对比图及结论,总的来讲就是sup-GMM性能强于基准GMM,且速度几乎相同,TDNN在不使用GPU并行计算的情况下要比sup-GMM慢得多,但TDNN效果是最好的。
[1]Vijayaditya Peddinti, Daniel Povey, and Sanjeev Khudanpur, “A time delay neural network architecture for efficient modeling of long temporal contexts,” http://www.danielpovey.com/files/ 2015_interspeech_multisplice.pdf, 2015,to appear in the Proceedings of INTERSPEECH.
[2]Yun Lei, Nicolas Scheffer, Luciana Ferrer, and Moray McLaren, “A novel scheme for speaker recognition using a phonetically-aware deep neural network,” in Acoustics, Speech and Signal Processing (ICASSP), 2014 IEEE International Conference on. IEEE, 2014,
pp. 1695–1699.