【详解】计算机视觉之图像分类
目录
-
-
- 图像分类
-
- 1 定义
- 2 常用数据集
-
- 2.1 mnist数据集
- 2.2 CIFAR-10和CIFAR-100
- 2.3 ImageNet
- 3 经典深度学习网络
-
- 3.1 AlexNet
- 3.2 VGG
- 3.3 GoogLeNet
- 3.4 ResNet
- 4 图像增强方法
-
- 4.1 tf.image进行图像增强
- 4.2 使用ImageDataGenerator()进行图像增强
- 5 模型微调
-
- 5.1 微调
- 5.2 热狗识别
-
图像分类
1 定义
从给定的类别集合中为图像分配对应标签的任务
2 常用数据集
2.1 mnist数据集
该数据集是手写数字0-9的集合,共有60k训练图像、10k测试图像、10个类别、图像大小28×28×1.我们可以通过tf.keras直接加载该数据集:
from tensorflow.keras.datasets import mnist
# 加载mnist数据集
(train_images, train_labels), (test_images, test_labels) = mnist.load_data()
随机选择图像展示结果如下所示:

2.2 CIFAR-10和CIFAR-100
- CIFAR-10数据集5万张训练图像、1万张测试图像、10个类别、每个类别有6k个图像,图像大小32×32×3。下图列举了10个类,每一类随机展示了10张图片:

- CIFAR-100数据集也是有5万张训练图像、1万张测试图像、包含100个类别、图像大小32×32×3。
在tf.keras中加载数据集时:
import tensorflow as tf
from tensorflow.keras.datasets import cifar10,cifar100
# 加载Cifar10数据集
(train_images, train_labels), (test_images, test_labels) = cifar10.load_data()
# 加载Cifar100数据集
(train_images, train_labels), (test_images, test_labels)= cifar100.load_data()
2.3 ImageNet
ImageNet数据集是ILSVRC竞赛使用的是数据集,由斯坦福大学李飞飞教授主导,包含了超过1400万张全尺寸的有标记图片,大约有22000个类别的数据。ILSVRC全称ImageNet Large-Scale Visual Recognition Challenge,是视觉领域最受追捧也是最具权威的学术竞赛之一,代表了图像领域的最高水平。从2010年开始举办到2017年最后一届,使用ImageNet数据集的一个子集,总共有1000类。
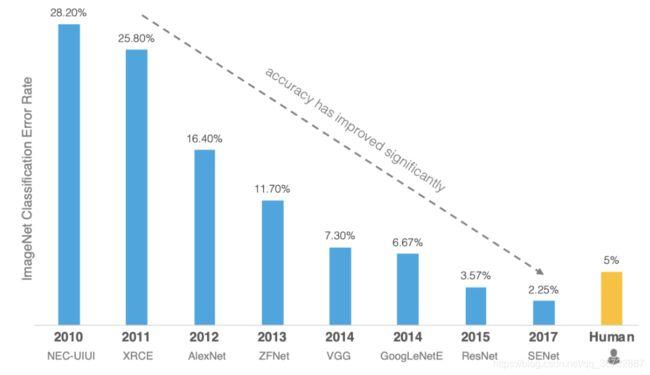
该比赛的获胜者从2012年开始都是使用的深度学习的方法:
- 2012年冠军是
AlexNet,由于准确率远超传统方法的第二名(top5错误率为15.3%,第二名为26.2%),引起了很大的轰动。自此之后,CNN成为在图像识别分类的核心算法模型,带来了深度学习的大爆发。 - 2013年冠军是
ZFNet,结构和AlexNet区别不大,分类效果也差不多。 - 2014年亚军是
VGG网络,网络结构十分简单,因此至今VGG-16仍在广泛使用。 - 2014年的冠军网络是
GooLeNet,核心模块是Inception Module。Inception历经了V1、V2、V3、V4等多个版本的发展,不断趋于完善。GoogLeNet取名中L大写是为了向LeNet致敬,而Inception的名字来源于盗梦空间中的"we need to go deeper"梗。 - 2015年冠军网络是
ResNet。核心是带短连接的残差模块,其中主路径有两层卷积核(Res34),短连接把模块的输入信息直接和经过两次卷积之后的信息融合,相当于加了一个恒等变换。短连接是深度学习又一重要思想,除计算机视觉外,短连接思想也被用到了机器翻译、语音识别/合成领域 - 2017年冠军
SENet是一个模块,可以和其他的网络架构结合,比如GoogLeNet、ResNet等。
3 经典深度学习网络
3.1 AlexNet
2012年,AlexNet横空出世,该模型的名字源于论文第一作者的姓名Alex Krizhevsky 。AlexNet使用了8层卷积神经网络,以很大的优势赢得了ImageNet 2012图像识别挑战赛。它首次证明了学习到的特征可以超越手工设计的特征,从而一举打破计算机视觉研究的方向。

该网络的特点是:
- AlexNet包含8层变换,有5层卷积和2层全连接隐藏层,以及1个全连接输出层
- AlexNet第一层中的卷积核形状是11x11。第二层中的卷积核形状减小到5x5,之后全采用3x3。所有的池化层窗口大小为3x3、步幅为2的最大池化。
- AlexNet将sigmoid激活函数改成了ReLU激活函数,使计算更简单,网络更容易训练
- AlexNet通过dropOut来控制全连接层的模型复杂度。
- AlexNet引入了大量的图像增强,如翻转、裁剪和颜色变化,从而进一步扩大数据集来缓解过拟合。
在tf.keras中实现AlexNet模型:
# 构建AlexNet模型
net = tf.keras.models.Sequential([
# 卷积层:96个卷积核,卷积核为11*11,步幅为4,激活函数relu
tf.keras.layers.Conv2D(filters=96,kernel_size=11,strides=4,activation='relu'),
# 池化:窗口大小为3*3、步幅为2
tf.keras.layers.MaxPool2D(pool_size=3, strides=2),
# 卷积层:256个卷积核,卷积核为5*5,步幅为1,padding为same,激活函数relu
tf.keras.layers.Conv2D(filters=256,kernel_size=5,padding='same',activation='relu'),
# 池化:窗口大小为3*3、步幅为2
tf.keras.layers.MaxPool2D(pool_size=3, strides=2),
# 卷积层:384个卷积核,卷积核为3*3,步幅为1,padding为same,激活函数relu
tf.keras.layers.Conv2D(filters=384,kernel_size=3,padding='same',activation='relu'),
# 卷积层:384个卷积核,卷积核为3*3,步幅为1,padding为same,激活函数relu
tf.keras.layers.Conv2D(filters=384,kernel_size=3,padding='same',activation='relu'),
# 卷积层:256个卷积核,卷积核为3*3,步幅为1,padding为same,激活函数relu
tf.keras.layers.Conv2D(filters=256,kernel_size=3,padding='same',activation='relu'),
# 池化:窗口大小为3*3、步幅为2
tf.keras.layers.MaxPool2D(pool_size=3, strides=2),
# 伸展为1维向量
tf.keras.layers.Flatten(),
# 全连接层:4096个神经元,激活函数relu
tf.keras.layers.Dense(4096,activation='relu'),
# 随机失活
tf.keras.layers.Dropout(0.5),
# 全链接层:4096个神经元,激活函数relu
tf.keras.layers.Dense(4096,activation='relu'),
# 随机失活
tf.keras.layers.Dropout(0.5),
# 输出层:10个神经元,激活函数softmax
tf.keras.layers.Dense(10,activation='softmax')
])
我们构造一个高和宽均为227的单通道数据样本来看一下模型的架构:
# 构造输入X,并将其送入到net网络中
X = tf.random.uniform((1,227,227,1)
y = net(X)
# 通过net.summay()查看网络的形状
net.summay()
网络架构如下:
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) (1, 55, 55, 96) 11712
_________________________________________________________________
max_pooling2d (MaxPooling2D) (1, 27, 27, 96) 0
_________________________________________________________________
conv2d_1 (Conv2D) (1, 27, 27, 256) 614656
_________________________________________________________________
max_pooling2d_1 (MaxPooling2 (1, 13, 13, 256) 0
_________________________________________________________________
conv2d_2 (Conv2D) (1, 13, 13, 384) 885120
_________________________________________________________________
conv2d_3 (Conv2D) (1, 13, 13, 384) 1327488
_________________________________________________________________
conv2d_4 (Conv2D) (1, 13, 13, 256) 884992
_________________________________________________________________
max_pooling2d_2 (MaxPooling2 (1, 6, 6, 256) 0
_________________________________________________________________
flatten (Flatten) (1, 9216) 0
_________________________________________________________________
dense (Dense) (1, 4096) 37752832
_________________________________________________________________
dropout (Dropout) (1, 4096) 0
_________________________________________________________________
dense_1 (Dense) (1, 4096) 16781312
_________________________________________________________________
dropout_1 (Dropout) (1, 4096) 0
_________________________________________________________________
dense_2 (Dense) (1, 10) 40970
=================================================================
Total params: 58,299,082
Trainable params: 58,299,082
Non-trainable params: 0
_________________________________________________________________
3.2 VGG

2014年,牛津大学计算机视觉组(Visual Geometry Group)和Google DeepMind公司的研究员一起研发出了新的深度卷积神经网络:VGGNet,并取得了ILSVRC2014比赛分类项目的第二名,主要贡献是使用很小的卷积核(3×3)构建卷积神经网络结构,能够取得较好的识别精度,常用来提取图像特征的VGG-16和VGG-19。

VGGNet使用的全部都是3x3的小卷积核和2x2的池化核,通过不断加深网络来提升性能。VGG可以通过重复使用简单的基础块来构建深度模型。
在tf.keras中实现VGG模型,首先来实现VGG块,它的组成规律是:连续使用多个相同的填充为1、卷积核大小为3\times 3的卷积层后接上一个步幅为2、窗口形状为2\times 2的最大池化层。卷积层保持输入的高和宽不变,而池化层则对其减半。我们使用vgg_block函数来实现这个基础的VGG块,它可以指定卷积层的数量num_convs和每层的卷积核个数num_filters:
# 定义VGG网络中的卷积块:卷积层的个数,卷积层中卷积核的个数
def vgg_block(num_convs, num_filters):
# 构建序列模型
blk = tf.keras.models.Sequential()
# 遍历所有的卷积层
for _ in range(num_convs):
# 每个卷积层:num_filter个卷积核,卷积核大小为3*3,padding是same,激活函数是relu
blk.add(tf.keras.layers.Conv2D(num_filters,kernel_size=3,
padding='same',activation='relu'))
# 卷积块最后是一个最大池化,窗口大小为2*2,步长为2
blk.add(tf.keras.layers.MaxPool2D(pool_size=2, strides=2))
return blk
VGG16网络有5个卷积块,前2块使用两个卷积层,而后3块使用三个卷积层。第一块的输出通道是64,之后每次对输出通道数翻倍,直到变为512。
# 定义5个卷积块,指明每个卷积块中的卷积层个数及相应的卷积核个数
conv_arch = ((2, 64), (2, 128), (3, 256), (3, 512), (3, 512))
因为这个网络使用了13个卷积层和3个全连接层,所以经常被称为VGG-16,通过制定conv_arch得到模型架构后构建VGG16:
# 定义VGG网络
def vgg(conv_arch):
# 构建序列模型
net = tf.keras.models.Sequential()
# 根据conv_arch生成卷积部分
for (num_convs, num_filters) in conv_arch:
net.add(vgg_block(num_convs, num_filters))
# 卷积块序列后添加全连接层
net.add(tf.keras.models.Sequential([
# 将特征图展成一维向量
tf.keras.layers.Flatten(),
# 全连接层:4096个神经元,激活函数是relu
tf.keras.layers.Dense(4096, activation='relu'),
# 随机失活
tf.keras.layers.Dropout(0.5),
# 全连接层:4096个神经元,激活函数是relu
tf.keras.layers.Dense(4096, activation='relu'),
# 随机失活
tf.keras.layers.Dropout(0.5),
# 全连接层:10个神经元,激活函数是softmax
tf.keras.layers.Dense(10, activation='softmax')]))
return net
# 网络实例化
net = vgg(conv_arch)
我们构造一个高和宽均为224的单通道数据样本来看一下模型的架构:
# 构造输入X,并将其送入到net网络中
X = tf.random.uniform((1,224,224,1))
y = net(X)
# 通过net.summay()查看网络的形状
net.summay()
网络架构如下:
Model: "sequential_15"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
sequential_16 (Sequential) (1, 112, 112, 64) 37568
_________________________________________________________________
sequential_17 (Sequential) (1, 56, 56, 128) 221440
_________________________________________________________________
sequential_18 (Sequential) (1, 28, 28, 256) 1475328
_________________________________________________________________
sequential_19 (Sequential) (1, 14, 14, 512) 5899776
_________________________________________________________________
sequential_20 (Sequential) (1, 7, 7, 512) 7079424
_________________________________________________________________
sequential_21 (Sequential) (1, 10) 119586826
=================================================================
Total params: 134,300,362
Trainable params: 134,300,362
Non-trainable params: 0
__________________________________________________________________
3.3 GoogLeNet
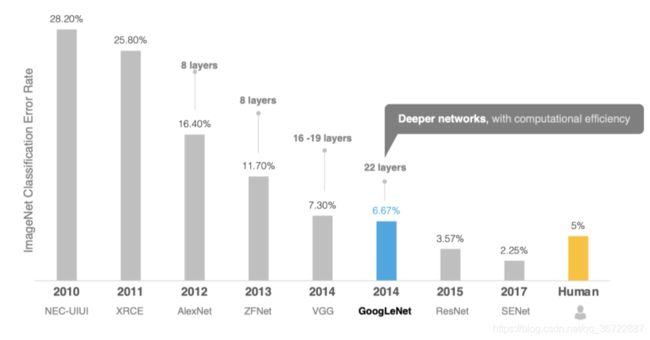
GoogLeNet的名字不是GoogleNet,而是GoogLeNet,这是为了致敬LeNet。GoogLeNet和AlexNet/VGGNet这类依靠加深网络结构的深度的思想不完全一样。GoogLeNet在加深度的同时做了结构上的创新,引入了一个叫做Inception的结构来代替之前的卷积加激活的经典组件。GoogLeNet在ImageNet分类比赛上的Top-5错误率降低到了6.7%。
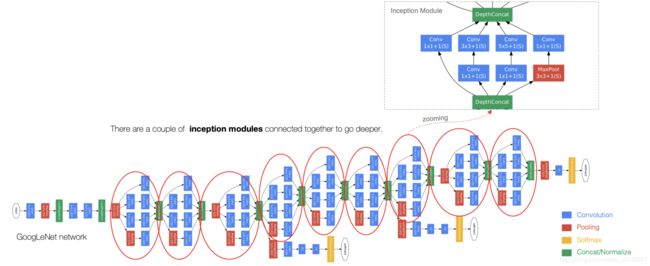
整个网络架构我们分为五个模块,每个模块之间使用步幅为2的3×33×3最大池化层来减小输出高宽。


代码实现:
## B1模块
# 定义模型的输入
inputs = tf.keras.Input(shape=(224,224,3),name = "input")
# b1 模块
# 卷积层7*7的卷积核,步长为2,pad是same,激活函数RELU
x = tf.keras.layers.Conv2D(64, kernel_size=7, strides=2, padding='same', activation='relu')(inputs)
# 最大池化:窗口大小为3*3,步长为2,pad是same
x = tf.keras.layers.MaxPool2D(pool_size=3, strides=2, padding='same')(x)
## B2模块
# 卷积层1*1的卷积核,步长为2,pad是same,激活函数RELU
x = tf.keras.layers.Conv2D(64, kernel_size=1, padding='same', activation='relu')(x)
# 卷积层3*3的卷积核,步长为2,pad是same,激活函数RELU
x = tf.keras.layers.Conv2D(192, kernel_size=3, padding='same', activation='relu')(x)
# 最大池化:窗口大小为3*3,步长为2,pad是same
x = tf.keras.layers.MaxPool2D(pool_size=3, strides=2, padding='same')(x)
## B3模块
# Inception
x = Inception(64, (96, 128), (16, 32), 32)(x)
# Inception
x = Inception(128, (128, 192), (32, 96), 64)(x)
# 最大池化:窗口大小为3*3,步长为2,pad是same
x = tf.keras.layers.MaxPool2D(pool_size=3, strides=2, padding='same')(x)
## B4模块
def aux_classifier(x, filter_size):
#x:输入数据,filter_size:卷积层卷积核个数,全连接层神经元个数
# 池化层
x = tf.keras.layers.AveragePooling2D(
pool_size=5, strides=3, padding='same')(x)
# 1x1 卷积层
x = tf.keras.layers.Conv2D(filters=filter_size[0], kernel_size=1, strides=1,
padding='valid', activation='relu')(x)
# 展平
x = tf.keras.layers.Flatten()(x)
# 全连接层1
x = tf.keras.layers.Dense(units=filter_size[1], activation='relu')(x)
# softmax输出层
x = tf.keras.layers.Dense(units=10, activation='softmax')(x)
return x
# Inception
x = Inception(192, (96, 208), (16, 48), 64)(x)
# 辅助输出1
aux_output_1 = aux_classifier(x, [128, 1024])
# Inception
x = Inception(160, (112, 224), (24, 64), 64)(x)
# Inception
x = Inception(128, (128, 256), (24, 64), 64)(x)
# Inception
x = Inception(112, (144, 288), (32, 64), 64)(x)
# 辅助输出2
aux_output_2 = aux_classifier(x, [128, 1024])
# Inception
x = Inception(256, (160, 320), (32, 128), 128)(x)
# 最大池化
x = tf.keras.layers.MaxPool2D(pool_size=3, strides=2, padding='same')(x)
## B5模块
# Inception
x = Inception(256, (160, 320), (32, 128), 128)(x)
# Inception
x = Inception(384, (192, 384), (48, 128), 128)(x)
# GAP
x = tf.keras.layers.GlobalAvgPool2D()(x)
# 输出层
main_outputs = tf.keras.layers.Dense(10,activation='softmax')(x)
# 使用Model来创建模型,指明输入和输出
model = tf.keras.Model(inputs=inputs, outputs=[main_outputs,aux_output_1,aux_output_2])
model.summary()
Model: "functional_3"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input (InputLayer) [(None, 224, 224, 3)] 0
_________________________________________________________________
conv2d_122 (Conv2D) (None, 112, 112, 64) 9472
_________________________________________________________________
max_pooling2d_27 (MaxPooling (None, 56, 56, 64) 0
_________________________________________________________________
conv2d_123 (Conv2D) (None, 56, 56, 64) 4160
_________________________________________________________________
conv2d_124 (Conv2D) (None, 56, 56, 192) 110784
_________________________________________________________________
max_pooling2d_28 (MaxPooling (None, 28, 28, 192) 0
_________________________________________________________________
inception_19 (Inception) (None, 28, 28, 256) 163696
_________________________________________________________________
inception_20 (Inception) (None, 28, 28, 480) 388736
_________________________________________________________________
max_pooling2d_31 (MaxPooling (None, 14, 14, 480) 0
_________________________________________________________________
inception_21 (Inception) (None, 14, 14, 512) 376176
_________________________________________________________________
inception_22 (Inception) (None, 14, 14, 512) 449160
_________________________________________________________________
inception_23 (Inception) (None, 14, 14, 512) 510104
_________________________________________________________________
inception_24 (Inception) (None, 14, 14, 528) 605376
_________________________________________________________________
inception_25 (Inception) (None, 14, 14, 832) 868352
_________________________________________________________________
max_pooling2d_37 (MaxPooling (None, 7, 7, 832) 0
_________________________________________________________________
inception_26 (Inception) (None, 7, 7, 832) 1043456
_________________________________________________________________
inception_27 (Inception) (None, 7, 7, 1024) 1444080
_________________________________________________________________
global_average_pooling2d_2 ( (None, 1024) 0
_________________________________________________________________
dense_10 (Dense) (None, 10) 10250
=================================================================
Total params: 5,983,802
Trainable params: 5,983,802
Non-trainable params: 0
___________________________________________________________
3.4 ResNet

网络越深,获取的信息就越多,特征也越丰富。但是在实践中,随着网络的加深,优化效果反而越差,测试数据和训练数据的准确率反而降低了。
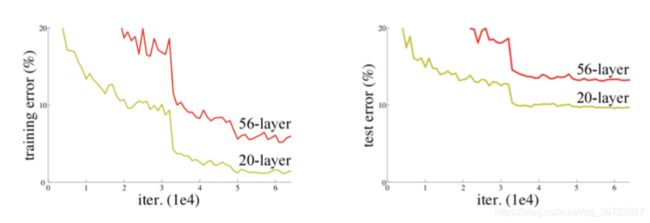
针对这一问题,何恺明等人提出了残差网络(ResNet)在2015年的ImageNet图像识别挑战赛夺魁,并深刻影响了后来的深度神经网络的设计。

ResNet网络中按照残差块的通道数分为不同的模块。第一个模块前使用了步幅为2的最大池化层,所以无须减小高和宽。之后的每个模块在第一个残差块里将上一个模块的通道数翻倍,并将高和宽减半。
下面我们来实现这些模块。注意,这里对第一个模块做了特别处理。
# ResNet网络中模块的构成
class ResnetBlock(tf.keras.layers.Layer):
# 网络层的定义:输出通道数(卷积核个数),模块中包含的残差块个数,是否为第一个模块
def __init__(self,num_channels, num_residuals, first_block=False):
super(ResnetBlock, self).__init__()
# 模块中的网络层
self.listLayers=[]
# 遍历模块中所有的层
for i in range(num_residuals):
# 若为第一个残差块并且不是第一个模块,则使用1*1卷积,步长为2(目的是减小特征图,并增大通道数)
if i == 0 and not first_block:
self.listLayers.append(Residual(num_channels, use_1x1conv=True, strides=2))
# 否则不使用1*1卷积,步长为1
else:
self.listLayers.append(Residual(num_channels))
# 定义前向传播过程
def call(self, X):
# 所有层依次向前传播即可
for layer in self.listLayers.layers:
X = layer(X)
return X
ResNet的前两层跟之前介绍的GoogLeNet中的一样:在输出通道数为64、步幅为2的7×77×7卷积层后接步幅为2的3×33×3的最大池化层。不同之处在于ResNet每个卷积层后增加了BN层,接着是所有残差模块,最后,与GoogLeNet一样,加入全局平均池化层(GAP)后接上全连接层输出。
# 构建ResNet网络
class ResNet(tf.keras.Model):
# 初始化:指定每个模块中的残差快的个数
def __init__(self,num_blocks):
super(ResNet, self).__init__()
# 输入层:7*7卷积,步长为2
self.conv=layers.Conv2D(64, kernel_size=7, strides=2, padding='same')
# BN层
self.bn=layers.BatchNormalization()
# 激活层
self.relu=layers.Activation('relu')
# 最大池化层
self.mp=layers.MaxPool2D(pool_size=3, strides=2, padding='same')
# 第一个block,通道数为64
self.resnet_block1=ResnetBlock(64,num_blocks[0], first_block=True)
# 第二个block,通道数为128
self.resnet_block2=ResnetBlock(128,num_blocks[1])
# 第三个block,通道数为256
self.resnet_block3=ResnetBlock(256,num_blocks[2])
# 第四个block,通道数为512
self.resnet_block4=ResnetBlock(512,num_blocks[3])
# 全局平均池化
self.gap=layers.GlobalAvgPool2D()
# 全连接层:分类
self.fc=layers.Dense(units=10,activation=tf.keras.activations.softmax)
# 前向传播过程
def call(self, x):
# 卷积
x=self.conv(x)
# BN
x=self.bn(x)
# 激活
x=self.relu(x)
# 最大池化
x=self.mp(x)
# 残差模块
x=self.resnet_block1(x)
x=self.resnet_block2(x)
x=self.resnet_block3(x)
x=self.resnet_block4(x)
# 全局平均池化
x=self.gap(x)
# 全链接层
x=self.fc(x)
return x
# 模型实例化:指定每个block中的残差块个数
mynet=ResNet([2,2,2,2])
这里每个模块里有4个卷积层(不计算 1×1卷积层),加上最开始的卷积层和最后的全连接层,共计18层。这个模型被称为ResNet-18。通过配置不同的通道数和模块里的残差块数可以得到不同的ResNet模型,例如更深的含152层的ResNet-152。虽然ResNet的主体架构跟GoogLeNet的类似,但ResNet结构更简单,修改也更方便。这些因素都导致了ResNet迅速被广泛使用。 在训练ResNet之前,我们来观察一下输入形状在ResNet的架构:
X = tf.random.uniform(shape=(1, 224, 224 , 1))
y = mynet(X)
mynet.summary()
Model: "res_net"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d_2 (Conv2D) multiple 3200
_________________________________________________________________
batch_normalization_2 (Batch multiple 256
_________________________________________________________________
activation (Activation) multiple 0
_________________________________________________________________
max_pooling2d (MaxPooling2D) multiple 0
_________________________________________________________________
resnet_block (ResnetBlock) multiple 148736
_________________________________________________________________
resnet_block_1 (ResnetBlock) multiple 526976
_________________________________________________________________
resnet_block_2 (ResnetBlock) multiple 2102528
_________________________________________________________________
resnet_block_3 (ResnetBlock) multiple 8399360
_________________________________________________________________
global_average_pooling2d (Gl multiple 0
_________________________________________________________________
dense (Dense) multiple 5130
=================================================================
Total params: 11,186,186
Trainable params: 11,178,378
Non-trainable params: 7,808
_________________________________________________________________
4 图像增强方法
图像增强(image augmentation)指通过剪切、旋转/反射/翻转变换、缩放变换、平移变换、尺度变换、对比度变换、噪声扰动、颜色变换等一种或多种组合数据增强变换的方式来增加数据集的大小。图像增强的意义是通过对训练图像做一系列随机改变,来产生相似但又不同的训练样本,从而扩大训练数据集的规模,而且随机改变训练样本可以降低模型对某些属性的依赖,从而提高模型的泛化能力。
常见的图像增强方式可以分为两类:几何变换类和颜色变换类
- 几何变换类,主要是对图像进行几何变换操作,包括翻转,旋转,裁剪,变形,缩放等。

- 颜色变换类,指通过模糊、颜色变换、擦除、填充等方式对图像进行处理
实现图像增强可以通过tf.image来完成,也可以通过tf.keras.imageGenerator来完成。
4.1 tf.image进行图像增强
导入所需的工具包并读取要处理的图像:
# 导入工具包
import tensorflow as tf
import matplotlib.pyplot as plt
import numpy as np
# 读取图像并显示
cat = plt.imread('./cat.jpg')
plt.imshow(cat)
1 翻转和裁剪
左右翻转图像是最早也是最广泛使用的一种图像增广方法。可以通过tf.image.random_flip_left_right来实现图像左右翻转。
# 左右翻转并显示
cat1 = tf.image.random_flip_left_right(cat)
plt.imshow(cat1)

创建tf.image.random_flip_up_down实例来实现图像的上下翻转,上下翻转使用的较少。
# 上下翻转
cat2 = tf.image.random_flip_up_down(cat)
plt.imshow(cat2)

随机裁剪出一块面积为原面积10%∼100%10%∼100%的区域,且该区域的宽和高之比随机取自0.5∼20.5∼2,然后再将该区域的宽和高分别缩放到200像素。
# 随机裁剪
cat3 = tf.image.random_crop(cat,(200,200,3))
plt.imshow(cat3)
2 颜色变换
另一类增广方法是颜色变换。我们可以从4个方面改变图像的颜色:亮度、对比度、饱和度和色调。接下来将图像的亮度随机变化为原图亮度的50%50%(即1−0.51−0.5)∼150%∼150%(即1+0.51+0.5)。
cat4=tf.image.random_brightness(cat,0.5)
plt.imshow(cat4)

类似地,我们也可以随机变化图像的色调
cat5 = tf.image.random_hue(cat,0.5)
plt.imshow(cat5)

4.2 使用ImageDataGenerator()进行图像增强
ImageDataGenerator()是keras.preprocessing.image模块中的图片生成器,可以在batch中对数据进行增强,扩充数据集大小,增强模型的泛化能力。比如旋转,变形等,如下所示:
keras.preprocessing.image.ImageDataGenerator(
rotation_range=0, #整数。随机旋转的度数范围。
width_shift_range=0.0, #浮点数、宽度平移
height_shift_range=0.0, #浮点数、高度平移
brightness_range=None, # 亮度调整
shear_range=0.0, # 裁剪
zoom_range=0.0, #浮点数 或 [lower, upper]。随机缩放范围
horizontal_flip=False, # 左右翻转
vertical_flip=False, # 垂直翻转
rescale=None # 尺度调整
)
来看下水平翻转的结果:
# 获取数据集
(x_train, y_train), (x_test, y_test) = tf.keras.datasets.mnist.load_data()
# 将数据转换为4维的形式
x_train = X_train.reshape(X_train.shape[0],28,28,1)
x_test = X_test.reshape(X_test.shape[0],28,28,1)
# 设置图像增强方式:水平翻转
datagen = ImageDataGenerator(horizontal_flip=True)
# 查看增强后的结果
for X_batch,y_batch in datagen.flow(x_train,y_train,batch_size=9):
plt.figure(figsize=(8,8)) # 设定每个图像显示的大小
# 产生一个3*3网格的图像
for i in range(0,9):
plt.subplot(330+1+i)
plt.title(y_batch[i])
plt.axis('off')
plt.imshow(X_batch[i].reshape(28,28),cmap='gray')
plt.show()
break

5 模型微调
5.1 微调
如何在只有6万张图像的MNIST训练数据集上训练模型。学术界当下使用最广泛的大规模图像数据集ImageNet,它有超过1,000万的图像和1,000类的物体。然而,我们平常接触到数据集的规模通常在这两者之间。假设我们想从图像中识别出不同种类的椅子,然后将购买链接推荐给用户。一种可能的方法是先找出100种常见的椅子,为每种椅子拍摄1,000张不同角度的图像,然后在收集到的图像数据集上训练一个分类模型。另外一种解决办法是应用迁移学习(transfer learning),将从源数据集学到的知识迁移到目标数据集上。例如,虽然ImageNet数据集的图像大多跟椅子无关,但在该数据集上训练的模型可以抽取较通用的图像特征,从而能够帮助识别边缘、纹理、形状和物体组成等。这些类似的特征对于识别椅子也可能同样有效。
微调由以下4步构成。
- 在源数据集(如ImageNet数据集)上预训练一个神经网络模型,即源模型。
- 创建一个新的神经网络模型,即目标模型。它复制了源模型上除了输出层外的所有模型设计及其参数。我们假设这些模型参数包含了源数据集上学习到的知识,且这些知识同样适用于目标数据集。我们还假设源模型的输出层跟源数据集的标签紧密相关,因此在目标模型中不予采用。
- 为目标模型添加一个输出大小为目标数据集类别个数的输出层,并随机初始化该层的模型参数。
- 在目标数据集(如椅子数据集)上训练目标模型。我们将从头训练输出层,而其余层的参数都是基于源模型的参数微调得到的。
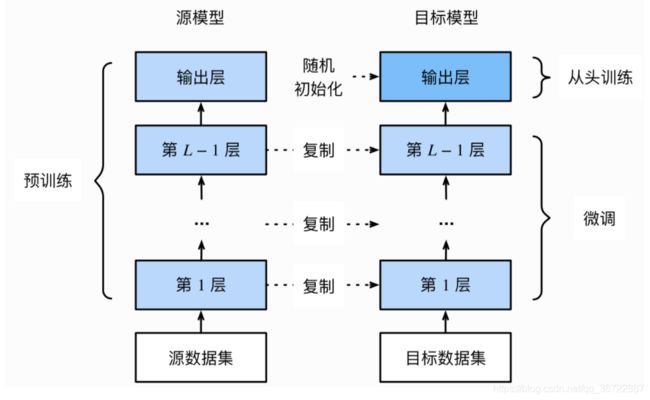
当目标数据集远小于源数据集时,微调有助于提升模型的泛化能力。
5.2 热狗识别
接下来我们来实践一个具体的例子:热狗识别。将基于一个小数据集对在ImageNet数据集上训练好的ResNet模型进行微调。该小数据集含有数千张热狗或者其他事物的图像。我们将使用微调得到的模型来识别一张图像中是否包含热狗。
首先,导入实验所需的工具包。
import tensorflow as tf
import numpy as np
5.2.1 获取数据集
我们首先将数据集放在路径hotdog/data之下:
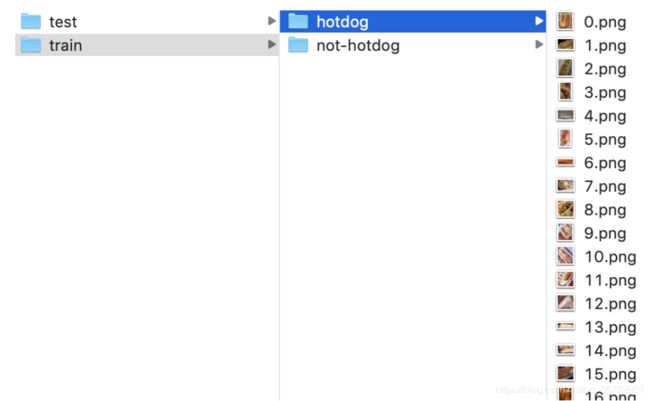
每个类别文件夹里面是图像文件。
上一节中我们介绍了ImageDataGenerator进行图像增强,我们可以通过以下方法读取图像文件,该方法以文件夹路径为参数,生成经过图像增强后的结果,并产生batch数据:
flow_from_directory(self, directory,
target_size=(256, 256), color_mode='rgb',
classes=None, class_mode='categorical',
batch_size=32, shuffle=True, seed=None,
save_to_dir=None)
主要参数:
- directory: 目标文件夹路径,对于每一个类对应一个子文件夹,该子文件夹中任何JPG、PNG、BNP、PPM的图片都可以读取。
- target_size: 默认为(256, 256),图像将被resize成该尺寸。
- batch_size: batch数据的大小,默认32。
- shuffle: 是否打乱数据,默认为True。
我们创建两个tf.keras.preprocessing.image.ImageDataGenerator实例来分别读取训练数据集和测试数据集中的所有图像文件。将训练集图片全部处理为高和宽均为224像素的输入。此外,我们对RGB(红、绿、蓝)三个颜色通道的数值做标准化。
# 获取数据集
import pathlib
train_dir = 'transferdata/train'
test_dir = 'transferdata/test'
# 获取训练集数据
train_dir = pathlib.Path(train_dir)
train_count = len(list(train_dir.glob('*/*.jpg')))
# 获取测试集数据
test_dir = pathlib.Path(test_dir)
test_count = len(list(test_dir.glob('*/*.jpg')))
# 创建imageDataGenerator进行图像处理
image_generator = tf.keras.preprocessing.image.ImageDataGenerator(rescale=1./255)
# 设置参数
BATCH_SIZE = 32
IMG_HEIGHT = 224
IMG_WIDTH = 224
# 获取训练数据
train_data_gen = image_generator.flow_from_directory(directory=str(train_dir),
batch_size=BATCH_SIZE,
target_size=(IMG_HEIGHT, IMG_WIDTH),
shuffle=True)
# 获取测试数据
test_data_gen = image_generator.flow_from_directory(directory=str(test_dir),
batch_size=BATCH_SIZE,
target_size=(IMG_HEIGHT, IMG_WIDTH),
shuffle=True)
下面我们随机取1个batch的图片然后绘制出来。
import matplotlib.pyplot as plt
# 显示图像
def show_batch(image_batch, label_batch):
plt.figure(figsize=(10,10))
for n in range(15):
ax = plt.subplot(5,5,n+1)
plt.imshow(image_batch[n])
plt.axis('off')
# 随机选择一个batch的图像
image_batch, label_batch = next(train_data_gen)
# 图像显示
show_batch(image_batch, label_batch)

5.2.2 模型构建与训练
我们使用在ImageNet数据集上预训练的ResNet-50作为源模型。这里指定weights='imagenet'来自动下载并加载预训练的模型参数。在第一次使用时需要联网下载模型参数。
Keras应用程序(keras.applications)是具有预先训练权值的固定架构,该类封装了很多重量级的网络架构,如下图所示:
实现时实例化模型架构:
tf.keras.applications.ResNet50(
include_top=True, weights='imagenet', input_tensor=None, input_shape=None,
pooling=None, classes=1000, **kwargs
)
主要参数:
- include_top: 是否包括顶层的全连接层。
- weights: None 代表随机初始化, ‘imagenet’ 代表加载在 ImageNet 上预训练的权值。
- input_shape: 可选,输入尺寸元组,仅当 include_top=False 时有效,否则输入形状必须是 (224, 224, 3)(channels_last 格式)或 (3, 224, 224)(channels_first 格式)。它必须为 3 个输入通道,且宽高必须不小于 32,比如 (200, 200, 3) 是一个合法的输入尺寸。
在该案例中我们使用resNet50预训练模型构建模型:
# 加载预训练模型
ResNet50 = tf.keras.applications.ResNet50(weights='imagenet', input_shape=(224,224,3))
# 设置所有层不可训练
for layer in ResNet50.layers:
layer.trainable = False
# 设置模型
net = tf.keras.models.Sequential()
# 预训练模型
net.add(ResNet50)
# 展开
net.add(tf.keras.layers.Flatten())
# 二分类的全连接层
net.add(tf.keras.layers.Dense(2, activation='softmax'))
接下来我们使用之前定义好的ImageGenerator将训练集图片送入ResNet50进行训练。
# 模型编译:指定优化器,损失函数和评价指标
net.compile(optimizer='adam',
loss='categorical_crossentropy',
metrics=['accuracy'])
# 模型训练:指定数据,每一个epoch中只运行10个迭代,指定验证数据集
history = net.fit(
train_data_gen,
steps_per_epoch=10,
epochs=3,
validation_data=test_data_gen,
validation_steps=10
)
Epoch 1/3
10/10 [==============================] - 28s 3s/step - loss: 0.6931 - accuracy: 0.5031 - val_loss: 0.6930 - val_accuracy: 0.5094
Epoch 2/3
10/10 [==============================] - 29s 3s/step - loss: 0.6932 - accuracy: 0.5094 - val_loss: 0.6935 - val_accuracy: 0.4812
Epoch 3/3
10/10 [==============================] - 31s 3s/step - loss: 0.6935 - accuracy: 0.4844 - val_loss: 0.6933 - val_accuracy: 0.4875