x-vector
文章目录
- 背景
- 核心思路
- 系统架构
-
- Time-delay NN(TDNN)
- 统计池化层
- x-vector提取
- 实现细节
背景
介绍x-vector的文章:
[1]Deep Neural Network Embeddings for Text-Independent Speaker Verification
//介绍x-vector的整体和细节部分
[2]X-Vectors: Robust DNN Embeddings for Speaker Recognition
//对实验部分进行补充分析
核心思路
将系统分为两个部分:
- embedding:将不定长的语音通过加噪和加混响进行数据扩充,然后经由深度神经网络映射成定长的向量,映射之后的向量称为x-vector
- compare pairs of embeddings:采用PLDA
系统架构
输入:24维fBank(在[1]中是20维MFCC),帧长25ms,经过
a. 3秒滑动窗口的均值归一化
b. speech activity detection(SAD)去除没有说话人语音的帧
上述处理。
系统框架:图源[1]
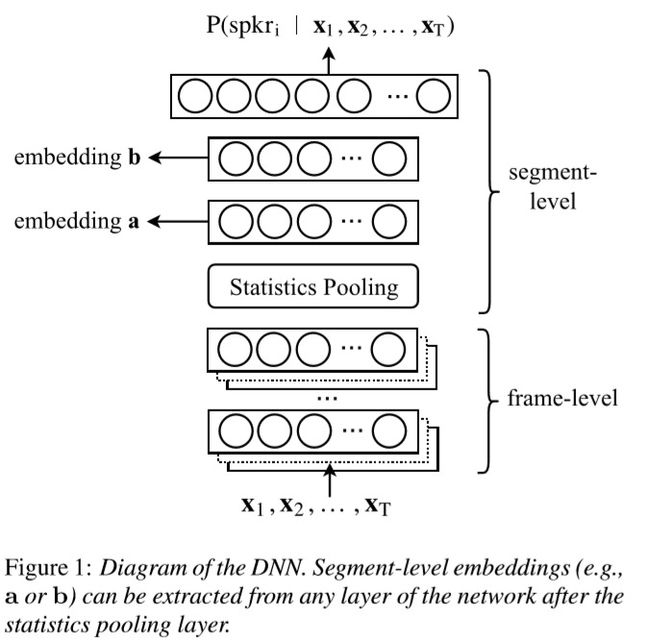
Time-delay NN(TDNN)
系统框架中statistics pooling之前的部分就是TDNN,
图源:《A time delay neural network architecture for efficient modeling of long temporal contexts》
对于一般DNN在处理上下文时,想法一般是这样:如果想提取具有上下文分别7帧共15帧的特征表达,一般会将这15帧的特征直接拼接起来,形成一个15*F(F是每一帧的特征维度)的特征,然后去学习15*F的特征映射。
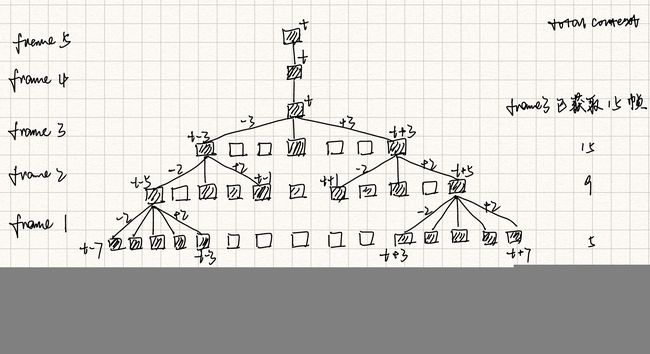
对于TDNN,假如要处理时序上15帧的上下文的特征表达,在初始层中,会处理比15帧更加窄的时序上下文,然后送入更深的网络。即更深的网络的时间分辨率比底层网络要长。也就是说,将“获取时序上15帧上下文的特征”这个目标交给更深的网络去完成,而不是用一层网络来完成。
上图中,第一层的时间分辨率为5,最上层的时间分辨率为23。
而且,TDNN在同一层,不同时间步上的transform参数都是共享的(就好像CNN中的卷积核在整张map上的参数共享),所以TDNN的一个超参数就是每一层的input context(layer context)。
从上图可看出,每一层的输出中,相邻时间步有很大的context重叠,在进行特征拼接输入下一层时不必拼接紧挨着的时间步,可以隔几个时间步进行拼接。

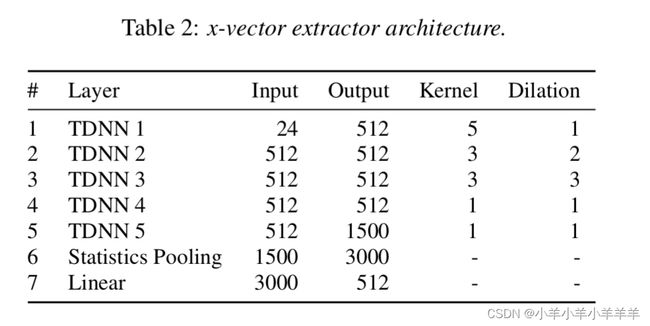
系统参数:图源[2]

根据系统参数有如下TDNN图示:
input:T帧
for t in T:
frame1-5 operates 以t为中心的小时间上下文
frame3 输出15帧的上下文
由系统参数所示,每15帧提取一次1500维向量,总共T帧,就有T个1500维向量
P.S. 如果输入的语音帧总共T帧,在边缘不补0的情况下,实际上输出应该是T-2*7个1500维向量。但是论文中写的是得到T个。
统计池化层
对这T个向量计算均值和方差(因为每个1500维向量都是从一个15帧的数据提取的,这样能够集合不同时间上的信息),将均值和方差合并起来,则得到一个2*1500=3000维的向量
x-vector提取
池化层之后,非线性之前。训练完成后,从segment6的仿射分量(affine)中提取x-vector(512维)
实现细节
参数设置:
设TDNN1输入T帧,每帧24维MFCCs
到TDNN5输出T-14个1500维向量
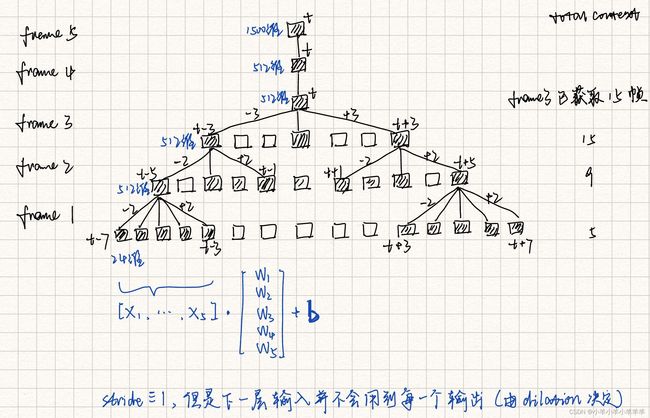
Context size和dilation决定被选择要进行拼接的帧,context size和kernel的大小对应
例如:
//x0为当前帧 t
context size 5 and dilation 1 [-2,-1,0,1,2]
context size 3 and dilation 2 [-2, 0, 2]
context size 1 and dilation 1 [0]
激活函数的选择:
在《Phoneme Recognition Using Time-Delay Neural Networks》中用的是sigmoid函数,为了降低计算开销等,其他论文选用Relu函数
# 卷积操作
# Unfold input into smaller temporal contexts
x = F.unfold(
x,
(self.context_size, self.input_dim),
stride=(1,self.input_dim),
dilation=(self.dilation,1)
) # 滑动窗口(卷)
# N, output_dim*context_size, new_t = x.shape
x = x.transpose(1,2)
x = self.kernel(x) # self.kernel = nn.Linear(input_dim*context_size, output_dim)(积)
x = self.nonlinearity(x)
from tdnn import TDNN
frame1 = TDNN(input_dim=24, output_dim=512, context_size=5, dilation=1)
frame2 = TDNN(input_dim=512, output_dim=512, context_size=3, dilation=2)
frame3 = TDNN(input_dim=512, output_dim=512, context_size=3, dilation=3)
frame4 = TDNN(input_dim=512, output_dim=512, context_size=1, dilation=1)
frame5 = TDNN(input_dim=512, output_dim=1500, context_size=1, dilation=1)
