Python数据分析之Numpy,Pandas,Matplotlib Pyplot
文章目录
- 一、Python数据分析之Numpy
-
- 0.数组的引入
- 1.创建数组
- 2.数组的属性
- 3.数组的基本操作
-
- 3.1 索引
- 3.2 切片
- 3.3花式索引
- 3.4 "不完全"索引
- 3.5 数组变形
- 4.数组聚合操作
- 5.数组连接
- 6.numpy内置函数
- 7.numpy mat的使用
- 8.矩阵的相关运算
- 二、Pandas
-
- 1.Pandas基本介绍
- 2.Pandas 基本数据结构
- 3.Series 的创建
- 4.访问Series数据
-
- 4.1 索引—index
- 4.2 值—values
- 4.3 切片
- 5.DataFrame
-
- 5.1 DataFrame简介
- 5.2 DataFrame的创建
- 5.3 DataFrame 的属性
- 5.4 DataFrame的索引和切片
- 5.5 DataFrame读取数据及数据操作
- 5.6 缺失值处理
- 三、Matplotlib Pyplot
-
- 1.matplotlib pyplot简介
- 2.plot函数
- 3.理解plt与ax
- 4.子图形的构成
-
- 4.1 Figure
- 4.2 subplot函数
- 5.图形标注
-
- 5.1 坐标轴相关设置
- 5.2 设置标题(title)
- 5.3 图例设置
- 5.4 文本注释
- 5.5 设置网格线
- 6.柱状图
- 7.条形图
- 8.饼状图
一、Python数据分析之Numpy
0.数组的引入
-
假设我们想将列表中的每个元素增加1,但列表不支持这样的操作:
a = [1,2,3,4] a+1 #报错 #但可以这样操作 [x+1 for x in a] -
数组与另一个数组相加,得到对应元素相加的结果:
a = [1,2,3,4] b = [2,3,4,5] a+b #[1, 2, 3, 4, 2, 3, 4, 5]并不是我们想要的结果 [x+y for(x,y) in zip(a,b)] #都需要利用到列表生成式 -
这样的操作比较麻烦,而且在数据量特别大的时候会非常耗时间。如果我们使用Numpy,就会变得特别简单
1.创建数组
-
先导入numpy包,有三种导入方式
#import numpy import numpy as np#导入numpy包并起别名为np #from numpy import * -
使用np.array()创建:从其他python结构(如列表,元组)转换
l = [0,1,2,3] print(l)#[0, 1, 2, 3] a = np.array([0,1,2,3]) print(a,type(a))#[0 1 2 3]a = np.array([[0,1,2,3],[10,11,12,13]])#创建二维数组 -
NumPy 原生数组的创建(如 arange、ones、zeros等)
-
np.arange(start, end, step): 返回一个ndarray对象, 起始值为start,终止值为end,但不含终止值,步长为step
a = np.arange(1,10,0.5) #左闭右开区间,和range的使用方式同理 print(a,type(a))#[1. 1.5 2. 2.5 3. 3.5 4. 4.5 5. 5.5 6. 6.5 7. 7.5 8. 8.5 9. 9.5] -
np.ones(shape, dtype=None): 函数返回给定形状和数据类型的新数组,其中元素的值设置为1
one=np.ones(5,dtype="bool") print(one,type(one))#[ True True True True True]array_2d = np.ones((2, 3)) print(array_2d,array_2d.dtype)# [[1. 1. 1.] [1. 1. 1.]] float64 -
np.zeros(shape,dtype=None): 函数返回给定形状和数据类型的新数组,其中元素的值设置为0
- 用法同ones()
-
np.linspace(start,stop,num): 指定间隔起始点、终止端,以及指定分隔值总数(包括起始点和终止点),最终函数返回间隔类均匀分布的数值数组
该函数共有7个参数,主要介绍前面3个
-
start:数据的起始点,即区间的最小值
-
stop:数据的结束点,即区间的最大值
-
num:数据量,可以理解成分割了多少份,不写默认为50
a = np.linspace(1,50) #右边是包括在里面的,从a-->b一共c个数的等差数列 print(a)# [ 1. 2. 3. 4. 5. 6. 7. 8. 9. 10. 11. 12. 13. 14. 15. 16. 17. 18. 19. 20. 21. 22. 23. 24. 25. 26. 27. 28. 29. 30. 31. 32. 33. 34. 35. 36. 37. 38. 39. 40. 41. 42. 43. 44. 45. 46. 47. 48. 49. 50.] a = np.linspace(1,50,10) print(a)# [ 1. 6.44444444 11.88888889 17.33333333 22.77777778 28.22222222 33.66666667 39.11111111 44.55555556 50. ]
-
-
Numpy中的random.rand(d0,d1,…,dn) 主要用于返回一个或一组0到1之间的随机数或随机数组
-
dn表示每个维度
-
示例:
np.random.rand(2,3) #array([[0.34510296, 0.26100149, 0.55205447], [0.1093094 , 0.43907452, 0.29931807]])
-
-
numpy.random.randn(d0,d1,…,dn):返回一个或一组样本,具有标准正态分布
-
用法同rand()
-
示例:
np.random.randn(10) #标准正态分布 array([-1.4237624 , 1.63058904, -1.9223658 , 0.17736421, 0.54337908, -1.46049834, 0.2146448 , -0.32785131, -1.08990638, -0.75152502])
-
-
numpy.random.randint(low, high=None, size=None, dtype=’l’): 返回随机整数,范围区间为[low,high),包含low,不包含high
-
参数:low为最小值,high为最大值,size为数组大小(没写默认为1),dtype为数据类型,默认的数据类型是np.int
-
high没有填写时,默认生成随机数的范围是[0,low)
np.random.randint(1,20,10) #生成随机整数,从1-20中随机10个
-
-
-
注意:
-
numpy默认ndarray的所有元素的类型是相同的
-
如果传进来的列表中包含不同的类型,则统一为同一类型,优先级:str>float>int
-
示例:
c = np.array([4,23.4,12.4]) print(c,c.dtype)#[ 4. 23.4 12.4] float64 # 如果既有字符串,又有数字,按照优先级,统一为字符串 b = np.array(["你好帅",2,3,4]) print(b,b.dtype)#['你好帅' '2' '3' '4']
-
2.数组的属性
-
查看数组中元素类型dtype
a=np.random.rand(2,3) a.dtype#dtype('float64')-
类型转换
-
利用dtype属性
a = np.array([1.5,-3],dtype = int) a#array([ 1, -3]) -
astype方法:返回一个新数组
a = np.array([1,2,3]) a.astype(float)#array([1., 2., 3.])
-
-
-
查看数组的形状shape
a.shape#(2, 3) np.shape(a)#另一种写法 -
查看数组元素的个数size
a.size#6 -
查看数组的维度ndim
a.ndim#2
3.数组的基本操作
3.1 索引
-
一维数组与列表基本一致
a = np.array([0,1,2,3]) a[0]#0 a[0] = 10 a#array([10, 1, 2, 3]) -
二维数组
a = np.array([[0,1,2,3],[10,11,12,13]]) a[1,3]#13 a[1][3]#另一种写法 #其中,1是行索引,3是列索引,中间用逗号隔开。事实上,Python会将它们看成一个元组(1,3),然后按照顺序进行对应。 #事实上,我们还可以使用单个索引来索引一整行内容: a[1]#array([10, 11, 12, -1])
3.2 切片
-
数组中的切片与列表中基本相同
-
示例:
a = np.array([11,12,13,14,15]) a[1:3] #左闭右开,从0开始算array([12, 13]) a[1:-2] #等价于a[1:3] a = np.array([[0,1,2,3,4,5],[10,11,12,13,14,15],[20,21,22,23,24,25],[30,31,32,33,34,35],[40,41,42,43,44,45],[50,51,52,53,54,55]]) a# array([[ 0, 1, 2, 3, 4, 5], [10, 11, 12, 13, 14, 15], [20, 21, 22, 23, 24, 25], [30, 31, 32, 33, 34, 35], [40, 41, 42, 43, 44, 45], [50, 51, 52, 53, 54, 55]]) #想得到第一行的第4和第5两个元素 a[0,3:5]#array([3, 4]) #得到第三列 a[:,2]#array([ 2, 12, 22, 32, 42, 52]) -
注意: 在数组中切片在内存中使用的是引用机制
a = np.array([0,1,2,3,4]) b = a[2:4] print(b)#[2 3] b[0] = 10 a#array([ 0, 1, 10, 3, 4]) #引用机制意味着,Python并没有为b分配新的空间来存储它的值,而是让b指向了a所分配的内存空间,因此,改变b会改变a的值 #而这种现象在列表中并不会出现 a = [1,2,3,4,5] b = a[2:4] b[0] = 10 print(a)#[1, 2, 3, 4, 5]
3.3花式索引
-
切片只能支持连续或者等间隔的切片操作,要想实现任意位置的操作。需要使用花式索引 fancy slicing。
-
一维花式索引
- 指定索引位置
a = np.arange(0,100,10) #array([ 0, 10, 20, 30, 40, 50, 60, 70, 80, 90]) index = [1,2,-3] y = a[index] print(y,type(y))#[10 20 70]- 使用布尔数组
#mask必须是布尔数组,长度必须和数组长度相等 mask = np.array([0,2,2,0,0,1,0,0,1,0],dtype = bool) mask# array([False, True, True, False, False, True, False, False, True, False]) a[mask]#array([10, 20, 50, 80]) -
二维花式索引
- 对于二维花式索引,我们需要给定行和列的值
a = np.array([[0,1,2,3,4,5],[10,11,12,13,14,15],[20,21,22,23,24,25],[30,31,32,33,34,35],[40,41,42,43,44,45],[50,51,52,53,54,55]]) a[(0,1,2,3,4),[1,2,3,4,5]]#元组或者列表都可以 array([ 1, 12, 23, 34, 45])#array([ 1, 12, 23, 34, 45]) #返回的是最后三行的1,3,5列 a[3:,[0,2,4]] #array([[30, 32, 34], [40, 42, 44], [50, 52, 54]])- 使用mask(bool数组)进行索引
mask = np.array([1,0,1,0,0,1],dtype = bool) a[mask,2]#array([ 2, 22, 52]) -
注意: 与切片不同,花式索引返回的是原对象的一个复制而不是引用
-
3.4 "不完全"索引
-
对于二维数组只给定一个索引时,为行索引
y = a[:3] y# array([[ 0, 1, 2, 3, 4, 5], [ 1, 1, 1, 1, 1, 1], [20, 21, 22, 23, 24, 25]])
3.5 数组变形
-
利用shape属性
a = np.arange(6)#array([0, 1, 2, 3, 4, 5]) a.shape=(2,3) a #array([[0, 1, 2], [3, 4, 5]]) a.shape#(2, 3) -
使用reshape() 函数:它不会修改原来数组的值,而是返回一个新的数组
a = np.arange(6) arr=a.reshape(2,3) print(arr)# array([[0, 1, 2], [3, 4, 5]]) a#没变 -
数组转置 T(转置)
a=np.array([[0, 1, 2], [3, 4, 5]]) print(a.T) [[0 3] [1 4] [2 5]] print(a) [[0 1 2] [3 4 5]] #转置不会改变原值 a.transpose()#另一种写法
4.数组聚合操作
- 聚合操作:指的是在数据查找基础上对数据的进一步整理筛选行为
-
求和np.sum(a,axis=None)
-
axis参数:
- 当axis=0时,对列进行聚合操作
- 当axis=1时,对行进行聚合操作
-
示例:
##评分人数 mv_num = np.array([692795,42995,327855,580897,478523,157074,306904,662552,284652,159302]) np.sum(mv_num)#3693549 mv_num.sum()#另一种写法 a = np.array([[0,1,2,3],[10,11,12,13]]) a.sum(axis=0)#array([10, 12, 14, 16]) a.sum(axis=1)#array([ 6, 46])
-
-
最大最小值np.max()/np.min()
- 用法同sum()
-
平均值np.mean()
- 用法同sum()
-
标准差np.std()
- 用法同sum()
-
相关系数矩阵numpy.cov()
##评分 mv_score = np.array([9.6,9.5,9.5,9.4,9.4,9.4,9.4,9.3,9.3,9.3]) ##电影时长(分钟) mv_length = np.array([142,116,116,142,171,194,195,133,109,92]) np.cov(mv_score,mv_length) #array([[9.88888889e-03, 4.55555556e-01], [4.55555556e-01, 1.26288889e+03]]) -
数组排序
- np.sort(a, axis=1, kind=‘quicksort’, order=None)
-
a:所需排序的数组
-
axis:数组排序时的基准,axis = 0,按列排列;axis = 1 ,按行排列(默认axis=1)
-
kind:数组排序时使用的方法,其中:kind = ′quicksort′为快排;kind = ′mergesort′为混排;kind = ′heapsort′为堆排
-
示例:
arr = np.array([[3, 2, 4], [5, 0, 1]]) print(np.sort(arr)) [[2 3 4] [0 1 5]] print(np.sort(arr,axis=0)) [[3 0 1] [5 2 4]]
- np.argsort(a, axis=1, kind=‘quicksort’, order=None)
-
返回从小到大的排列在数组中的索引位置
-
用法与sort基本一致
-
示例:
##评分人数 mv_num = np.array([692795,42995,327855,580897,478523,157074,306904,662552,284652,159302]) order = np.argsort(mv_num) order#array([1, 5, 9, 8, 6, 2, 4, 3, 7, 0], dtype=int64) arr = np.array([[3, 2, 4], [5, 0, 1]]) order=np.argsort(arr) order# array([[1, 0, 2], [1, 2, 0]], dtype=int64)
5.数组连接
-
有时候我们需要将不同的数组按照一定的顺序连接起来,此时便可以用到concatenate((a0,a1,…,aN),axis = 0)
-
aN表示数组
-
axis表示按什么方向进行连接,默认为0,即按列连接
-
数组为一维数组(向量)直接在其后面进行连接
arr1 = np.array([1, 2, 3]) arr2 = np.array([4, 5, 6]) arr = np.concatenate((arr1, arr2)) print(arr1.shape,arr2.shape)#(3,) (3,) print(arr)#[1 2 3 4 5 6] -
数组为二维数组
arr1 = np.array([[1, 2, 3]]) arr2 = np.array([[4, 5, 6]]) arr = np.concatenate((arr1, arr2)) print(arr1.shape,arr2.shape)#(1, 3) (1, 3) print(arr) #[[1 2 3] #[4 5 6]] arr = np.concatenate((arr1, arr2),axis=1) print(arr)#[[1 2 3 4 5 6]]
-
-
hstack() 沿行堆叠
arr1 = np.array([1, 2, 3]) arr2 = np.array([4, 5, 6]) arr = np.hstack((arr1, arr2)) print(arr)#[1 2 3 4 5 6] -
vstack() 沿列堆叠
arr1 = np.array([1, 2, 3]) arr2 = np.array([4, 5, 6]) arr = np.vstack((arr1, arr2)) print(arr) #[[1 2 3] [4 5 6]] -
dstack() 沿高度堆叠,该高度与深度相同
arr1 = np.array([1, 2, 3]) arr2 = np.array([4, 5, 6]) arr = np.dstack((arr1, arr2)) print(arr)# [[[1 4] [2 5] [3 6]]]
6.numpy内置函数
-
np.abs(a): 绝对值函数,其中a为数组
-
np.exp(a): 指数函数即 e x e^x ex
示例:
a = np.array([-1,1,0,-2]) np.exp(a) #array([0.36787944, 2.71828183, 1. , 0.13533528]) -
np.median(a): 中值函数
np.median(a) #中值-0.5 -
np.cumsum(a): 累积和函数
np.cumsum(a) #累积和 #array([-1, 0, 0, -2], dtype=int32) -
numpy.where(condition): 输出满足条件元素的坐标
a = np.array([0,12,5,20]) b=np.where(a>10) print(b,type(b))#(array([1, 3], dtype=int64),) -
numpy的内置函数非常多,不需要死记,懂得查资料
https://blog.csdn.net/nihaoxiaocui/article/details/51992860?locationNum=5&fps=1
7.numpy mat的使用
虽然array也可以进行运算,但mat更符合矩阵
-
numpy.mat(data, dtype=None): 将数据转化成矩阵类型
-
Parameters 参数介绍
- data:array_like 数组、列表之类
- dtype:data-type Data-type of the output matrix
-
Returns 返回值:matrix
-
-
索引
m= np.mat([1,2,3]) #创建矩阵 m[0] #取一行 m[0,1] #第一行,第2个数据 m[0][1] #注意不能像数组那样取值了,这样写会报错 -
示例:
A=np.array([[1,2,3],[4,5,6]]) A1=np.mat(A) print(A1,type(A1)) #结果 [[1 2 3] [4 5 6]] <class 'numpy.matrix'> #也可以直接传参数 B=np.mat('1 2 3;4 5 6')#单引号,双引号均可 print(B,type(B)) #结果 [[1 2 3] [4 5 6]] <class 'numpy.matrix'>注:如果输入本身就是一个矩阵,则np.mat不会对该矩阵make a copy.仅仅是创建了一个新的引用。np.matrix(data, copy = True)创建了一个新的相同的矩阵。当修改新矩阵时,原来的矩阵不会改变。
#导入模块 import numpy as np #创建ndarray二维数组 x = np.array([[1, 2], [3, 4]]) #生成矩阵 m = np.mat(x) #打印 m 矩阵 print(m) [[1 2] [3 4]] #如果此时修改 x 数组,m矩阵也会随之发生变化 x[0,0] = 5 print(m) [[5 2] [3 4]]
8.矩阵的相关运算
-
矩阵乘法
-
数据结构为numpy.ndarray(数组) 或者numpy.matrix(矩阵)可以使用numpy.dot(a, b, out=None)
- a : ndarray 数组
- b : ndarray 数组
- out : ndarray, 可选,用来保存dot()的计算结果
-
数据结构为numpy.matrix(矩阵)时也可以使用星号(*)
-
示例:
#矩阵 A=np.mat("1;2;3") B=np.mat('1 2 3;4 5 6') np.dot(B,A) #B*A 矩阵乘法要注意先后顺序 #B.dot(A)另一种写法 #结果 matrix([[14], [32]]) #数组 A=np.array([[1],[2],[3]]) print(A.shape)#(3, 1) B=np.array([[1,2,3],[4,5,6]]) print(B.shape)#(2, 3) B.dot(A) #输出结果 array([[14], [32]]) B*A#会报错,对于数组*计算的时对应位置的乘法,需要两个数组的形状相同 #operands could not be broadcast together with shapes (2,3) (3,1)
-
-
矩阵对应元素相乘
-
np.multiply(): 数组和矩阵对应位置相乘,输出与相乘数组/矩阵的大小一致
-
数据结构为numpy.ndarray(数组)时也可以使用星号(*)
-
示例
#数组 A=np.array([[1,1,1],[2,2,2]]) B=np.array([[1,2,3],[4,5,6]]) B*A np.multiply(A,B) #输出结果 array([[ 1, 2, 3], [ 8, 10, 12]]) #矩阵 A=np.mat(A) B=np.mat(B) np.multiply(A,B) #输出结果 matrix([[ 1, 2, 3], [ 8, 10, 12]])
-
-
计算矩阵的行列式值
-
numpy.linalg.det() 函数计算输入矩阵的行列式
-
示例
import numpy as np a = np.array([[1,2], [3,4]]) print (np.linalg.det(a))#-2.0
-
-
逆矩阵
-
numpy.linalg.inv() 函数计算矩阵的乘法逆矩阵
-
示例
x = np.array([[1,2],[3,4]]) y = np.linalg.inv(x) print (x) print (y) print (np.dot(x,y)) #输出结果 [[1 2] [3 4]] [[-2. 1. ] [ 1.5 -0.5]] #近似于E [[1.00000000e+00 1.11022302e-16] [0.00000000e+00 1.00000000e+00]]
-
-
解线性方程组
-
linalg.solve(a,b) 形如:AX = B
- a: Coefficient matrix(系数矩阵)
- b: 列向量
-
示例:Solve the system of equations
x0 + 2 * x1 = 1 and
3 * x0 + 5 * x1 = 2
a = np.array([[1, 2], [3, 5]]) b = np.array([1, 2]) x = np.linalg.solve(a, b) x array([-1., 1.])
-
二、Pandas
1.Pandas基本介绍
Python Data Analysis Library 或 Pandas是基于Numpy的一种工具,该工具是为了解决数据分析任务而创建的。Pandas纳入了大量库和一些标准的数据模型,提供了高效地操作大型数据集所需的工具。pandas提供了大量能使我们快速便捷地处理数据的函数和方法。
2.Pandas 基本数据结构
pandas有两种常用的基本结构:- Series:
- 带标签的一维数组,与Numpy中的一维array类似。二者与Python基本的数据结构List也很接近。Series可存储整数、浮点数、字符串、Python 对象等类型的数据
- DataFrame:
- 二维的表格型数据结构,可以将DataFrame理解为Series的容器。
- Series:
3.Series 的创建
-
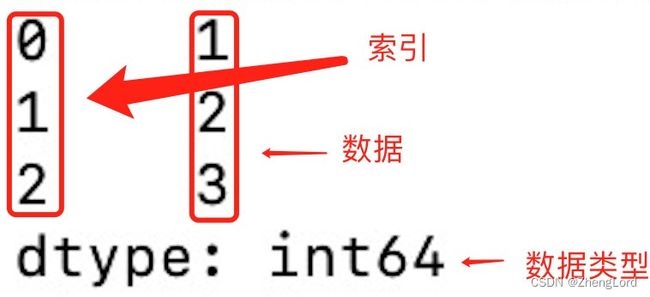
series由两部分组成
-
values:一组数据(ndarray类型)
-
index:相关的数据索引标签
-
形式如下:
-
-
Pandas 使用 Series() 函数来创建 Series 对象
-
pandas.Series( data, index, dtype, name, copy)
- data:一组数据(ndarray 类型)
- index:数据索引标签,如果不指定,默认从 0 开始
- dtype:数据类型,默认会自己判断
- name:设置名称
- copy:拷贝数据,默认为 False
-
创建一个空series对象
#输出数据为空 s = pd.Series() print(s,type(s))#Series([], dtype: float64) -
用列表list构建Series
my_list=[7,'Beijing','19大',3.1415,-10000,'Happy'] s=pd.Series(my_list) print(type(s)) print(s) #输出结果 <class 'pandas.core.series.Series'> 0 7 1 Beijing 2 19大 3 3.1415 4 -10000 5 Happy dtype: object-
pandas会默认用0到n来做Series的index,但也可以自己指定index
s=pd.Series([7,'Beijing','19大',3.1415,-10000,'Happy'], index=['A','B','C','D','E','F']) print(s) #输出结果 A 7 B Beijing C 19大 D 3.1415 E -10000 F Happy dtype: object
-
-
ndarray创建Series对象
d=pd.Series(np.random.randn(5),index=['a','b','c','d','e']) print(d) #输出结果 a -0.329401 b -0.435921 c -0.232267 d -0.846713 e -0.406585 dtype: float64 -
用字典dict来构建Series,因为Series本身其实就是key-value的结构
cities={'Beijing':55000,'Shanghai':60000,'shenzhen':50000,'Hangzhou':20000,'Guangzhou':45000,'Suzhou':None} apts=pd.Series(cities,name='income') print(apts) #输出结果 Beijing 55000.0 Guangzhou 45000.0 Hangzhou 20000.0 Shanghai 60000.0 Suzhou NaN shenzhen 50000.0 Name: income, dtype: float64
-
4.访问Series数据
4.1 索引—index
s = pd.Series([1,3,5,np.nan,6,8])
print(s.index,type(s.index))
#结果
#默认情况下,Series的下标都是数字(可以使用额外参数指定),类型是统一的。
RangeIndex(start=0, stop=6, step=1) <class 'pandas.core.indexes.range.RangeIndex'>
s.index.name = '索引'
s
#
索引
0 1.0
1 3.0
2 5.0
3 NaN
4 6.0
5 8.0
dtype: float64
4.2 值—values
new_s=s.values
print(new_s,type(new_s),new_s.dtype)
#结果
[ 1. 3. 5. nan 6. 8.] <class 'numpy.ndarray'> float64
4.3 切片
s[2:5] #左闭右开
#结果
2 5.0
3 NaN
4 6.0
dtype: float64
s[::2]
#结果
0 1.0
2 5.0
4 6.0
dtype: float64
s.index = list('abcdef')
s['a':'c':2] #依据自己定义的数据类型进行切片,不是左闭右开了
#结果
a 1.0
c 5.0
dtype: float64
5.DataFrame
5.1 DataFrame简介
-
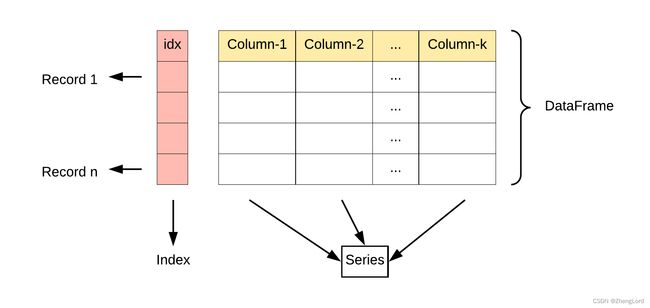
DataFrame是一个表格型的数据结构,DataFrame由按一定顺序排列的多列数据组成.设计初衷是将Series的使用场景从一维拓展到多维。其实DataFrame就是由多个Series组成的,因此可以说DataFrame是Series的容器。
-
DataFrame由3部分组成
-
行索引:index
-
列索引:columns
-
值:values
-
如下图:
-
5.2 DataFrame的创建
-
使用ndarry创建
-
pd.DataFrame(data=None, index=None, columns=None, dtype=None, copy=False)
-
index指定行索引,columns指定列索引,若不写,则默认从0开始,size指定行数和列数
-
示例:
df = pd.DataFrame(data=np.random.randint(1,10,size=(2,4)),index=["a","b"],columns=["A","B","C","D"]) #结果 A B C D a 2 9 8 1 b 6 1 2 1 #默认情况下,如果不指定index参数和columns,那么它们的值将从用0开始的数字替代 df = pd.DataFrame(np.random.randn(6,4)) print(df) #结果 0 1 2 3 0 -0.261175 -0.250175 -0.315719 1.294368 1 0.824193 -1.930705 -0.744268 0.343531 2 -0.350171 1.270669 0.783120 -0.795121 3 0.626404 -2.341512 -0.057654 -0.883903 4 -0.648448 0.253251 0.447128 1.492709 5 -0.315956 0.121005 -0.804142 -1.134788
-
-
-
使用字典创建
-
字典的每个
key代表一列,其value可以是各种能够转化为Series的对象dic = {"name":["张三","李四","王五"],"age":[1,2,3]} # key为列的索引,行索引则默认从0开始 df=pd.DataFrame(dic) print(df) #结果 name age 0 张三 18 1 李四 19 2 王五 22 df2 = pd.DataFrame({'A':1.,'B':pd.Timestamp("20181001"),'C':pd.Series(1,index = list(range(4)),dtype = float),'D':np.array([3]*4, dtype = int),'E':pd.Categorical(["test","train","test","train"]),'F':"abc"}) #B:时间戳,E分类类型 print(df2) #输出结果 A B C D E F 0 1.0 2018-10-01 1.0 3 test abc 1 1.0 2018-10-01 1.0 3 train abc 2 1.0 2018-10-01 1.0 3 test abc 3 1.0 2018-10-01 1.0 3 train abc
-
5.3 DataFrame 的属性
-
index 行索引属性
print(df2.index,type(df2.index)) #Int64Index([0, 1, 2, 3], dtype='int64') -
columns 列索引属性
print(df.columns,type(df.columns)) #Index(['A', 'B', 'C', 'D', 'E', 'F'], dtype='object') -
values 数据值属性
df2.values #结果 array([[1.0, Timestamp('2018-10-01 00:00:00'), 1.0, 3, 'test', 'abc'], [1.0, Timestamp('2018-10-01 00:00:00'), 1.0, 3, 'train', 'abc'], [1.0, Timestamp('2018-10-01 00:00:00'), 1.0, 3, 'test', 'abc'], [1.0, Timestamp('2018-10-01 00:00:00'), 1.0, 3, 'train', 'abc']], dtype=object) -
shape、size、dtypes
df2.shape (4, 6) df2.size 24 df2.dtypes #输出结果 A float64 B datetime64[ns] C float64 D int32 E category F object dtype: object
5.4 DataFrame的索引和切片
-
隐式索引的操作: 即不规定行、列索引使用默认索引
-
df[0][0] df[列][行],获取隐式索引单个元素
-
df[1] ,df[i] 获取第i+1列元素 df[1,3,5] 这种写法会报错
-
df[0:2] 对行的切片操作,获取的是0和1行,顾头不顾尾
-
df[[0,1]] 对列的操作,获取第一列和第二列
-
df.iloc[0:2,0:2] iloc对于隐式索引的操作,获取前两行和前两列组成的区域,逗号前式行,逗号后是列
-
df.iloc[[0,1],[0,1]] iloc对于隐式索引的操作,获取前两行和前两列组成的区域
-
示例:
df = pd.DataFrame(np.random.randn(6,4)) print(df) #输出结果 0 1 2 3 0 -1.724670 -0.305197 -1.235365 -0.052571 1 1.401085 1.621906 -0.526358 -1.507972 2 -0.786382 0.741458 0.306289 -1.099758 3 2.419920 -0.647299 1.194271 0.692936 4 0.347969 0.607995 -1.757885 -0.021412 5 -0.964155 0.936637 0.975647 0.731744 df[[0,2]] 0 2 0 -1.724670 -1.235365 1 1.401085 -0.526358 2 -0.786382 0.306289 3 2.419920 1.194271 4 0.347969 -1.757885 5 -0.964155 0.975647 df[0] 0 -1.724670 1 1.401085 2 -0.786382 3 2.419920 4 0.347969 5 -0.964155 Name: 0, dtype: float64 df[0:2] 0 1 2 3 0 -1.724670 -0.305197 -1.235365 -0.052571 1 1.401085 1.621906 -0.526358 -1.507972 df.iloc[0:2,0:2] 0 1 0 -1.724670 -0.305197 1 1.401085 1.621906
-
-
显式索引的操作:显式索引使用切片表达式时是闭区间
-
df[“A”] 或 df.A 获取单列, 类似于字典的操作
-
df[‘A’][‘a’] 获取单个元素,先列后行 df[列][行]
-
df[“a”:“b”] 获取是a到b行,包含b行
-
df[[“A”,“B”]] 获取A列和B列
-
df.loc[“a”:“b”,“A”:“B”] loc对于显式索引的操作, df[行区域,列区域]
-
df.loc[[“a”,“b”],[“A”,“B”]] loc对于显式索引的操作,结果同上
-
示例:
df1 = pd.DataFrame(data=np.random.randint(1,10,size=(3,4)),index=["a","b","c"],columns=["A","B","C","D"]) df1 A B C D a 2 6 2 6 b 6 8 6 6 c 1 8 5 4 df1.loc["a":"b","A":"B"] A B a 2 6 b 6 8
-
-
head和tail方法可以分别查看最前面几行和最后面几行的数据(默认为5)df.head() 0 1 2 3 0 -1.724670 -0.305197 -1.235365 -0.052571 1 1.401085 1.621906 -0.526358 -1.507972 2 -0.786382 0.741458 0.306289 -1.099758 3 2.419920 -0.647299 1.194271 0.692936 4 0.347969 0.607995 -1.757885 -0.021412 df.tail(3) 0 1 2 3 3 2.419920 -0.647299 1.194271 0.692936 4 0.347969 0.607995 -1.757885 -0.021412 5 -0.964155 0.936637 0.975647 0.731744 -
总结
- loc是对于显式索引的相关操作(对于标签的处理),iloc是针对隐式索引的相关操作(对于整数的处理)
- df[0:2]切片操作是针对行而言,对于df[“A”]索引操作是对于列而言;获取单个元素先列后行,df[列][行];loc和iloc操作,逗号前是行区域或行列表,逗号后是列区域或列列表
5.5 DataFrame读取数据及数据操作
-
读取Excel文件数据
- 函数原型pd.read_excel(io, sheetname=0,header=0,skiprows=None,index_col=None,names=None,
arse_cols=None,date_parser=None,na_values=None,thousands=None,
convert_float=True,has_index_names=None,converters=None,dtype=None,
true_values=None,false_values=None,engine=None,squeeze=False,**kwds) - 参数介绍
- io :excel 路径
- sheetname:默认是sheetname为0,返回多表使用sheetname=[0,1],若sheetname=None是返回全表 。注意:int/string返回的是dataframe,而none和list返回的是dict of dataframe
- header :指定作为列名的行,默认0,即取第一行,数据为列名行以下的数据;若数据不含列名,则设定 header = None
- skiprows:省略指定行数的数据
- skip_footer:省略从尾部数的行数据
- index_col :指定列为索引列,也可以使用 u’string’
- names:指定列的名字,传入一个list数据
- usecols: 默认为None,解析所有列;如果为str,则表示Excel列字母和列范围的逗号分隔列表(例如“ A:E”或“ A,C,E:F”)。范围全闭;如果为int,则表示解析到第几列;如果为int列表,则表示解析那几列
df = pd.read_excel(r"D:\BaiduNetdiskDownload\python\python\作业3\豆瓣电影数据.xlsx",index_col = 0) - 函数原型pd.read_excel(io, sheetname=0,header=0,skiprows=None,index_col=None,names=None,
-
文本文件的读取
- 函数原型 pandas.read_csv(filepath_or_buffer, sep=, delimiter=None, header=‘infer’, names=None, index_col=None, usecols=None, squeeze=False, prefix=None, mangle_dupe_cols=True, dtype=None, engine=None, converters=None, true_values=None, false_values=None, skipinitialspace=False, skiprows=None, skipfooter=0, nrows=None, na_values=None, keep_default_na=True, na_filter=True, verbose=False, skip_blank_lines=True, parse_dates=False, infer_datetime_format=False, keep_date_col=False, date_parser=None, dayfirst=False, cache_dates=True, iterator=False, chunksize=None, compression=‘infer’, thousands=None, decimal=’.’, lineterminator=None, quotechar=’"’, quoting=0, doublequote=True, escapechar=None, comment=None, encoding=None, dialect=None, error_bad_lines=True, warn_bad_lines=True, delim_whitespace=False, low_memory=True, memory_map=False, float_precision=None, storage_options=None)
- 几个重要参数
- filepath_or_buffer: 字符串。任何有效的字符串路径都可以,网址也行。
- sep: 字符串,表示分隔符,默认为逗号
- delimiter: 字符串,sep的别名,默认None(如果定义该参数,则sep参数失效)
- header: int或者int列表,默认由推断出来。这是用于规定列名的行号
- index_col: 整数或者字符串或者整数/字符串列表。指定用作的行标签的列
- nrows: 整数,选择性使用。要读取的文件行数。对于读取大文件很有用
- skiprows: 列表或者整数,选择性使用。在文件开始处要跳过的行号(索引为0)或要跳过的行数(整数)
- 返回值为DateFrame
-
数据操作
-
添加数据df.append(other,ignore_index=False,verify_integrity=False, sort=None )
-
other: DataFrame、series、dict、list等数据结构
-
ignore_index: 默认值为False,为True则不使用index标签
-
verify_integrity: 默认值为False,如果为True当创建相同的index时会抛出ValueError的异常
-
sort: boolean,默认是None
-
示例:
#append添加字典 data = pd.DataFrame() a = {"x":1,"y":2} data = data.append(a,ignore_index=True) print(data)# x y 0 1.0 2.0 #append添加series #如果不添加ignore_index=True,会报错TypeError: Can only append a Series if ignore_index=True or if the Series has a name #如果不添加ignore_index=True,则需要添加name属性 series = pd.Series({"x":1,"y":2},name="a") data = data.append(series) print(data)#输出结果 x y 0 1.0 2.0 a 1.0 2.0 #设置的name会作为index的name #append添加list #如果list是一维的,则是以列的形式添加,如果list是二维的则是以行的形式来添加 data = pd.DataFrame() a = [1,2,3] data = data.append(a) print(data)# 0 0 1 1 2 2 3 data = pd.DataFrame() a = [[1,2,3],[4,5,6]] data = data.append(a) print(data)# 0 1 2 0 1 2 3 1 4 5 6
-
-
drop(labels=None, axis=0, index=None, columns=None, level=None, inplace=False, errors=‘raise’)
-
labels: 一个字符或者数值,加上axis ,表示带label标识的行或者列;如 (labels=‘A’, axis=1) 表示A列
-
axis: axis=0表示行,axis=1表示列
-
columns: 列名
-
index: 表示dataframe的index, 如index=1, index=a
-
inplace: True表示删除某行后原dataframe变化,False不改变原始dataframe
-
示例:
df2 = pd.DataFrame({'A':1.,'B':pd.Timestamp("20181001"),'C':pd.Series(1,index = list(range(4)),dtype = float),'D':np.array([3]*4, dtype = int),'E':pd.Categorical(["test","train","test","train"]),'F':"abc"}) #B:时间戳,E分类类型 print(df2)# A B C D E F 0 1.0 2018-10-01 1.0 3 test abc 1 1.0 2018-10-01 1.0 3 train abc 2 1.0 2018-10-01 1.0 3 test abc 3 1.0 2018-10-01 1.0 3 train abc #删除A列,axis=1不能省略 df2=df2.drop('A',axis=1) #df2=df2.drop(columns='A')另一种写法
-
-
5.6 缺失值处理
- 缺失值
- 在np中,None是python自带的,其类型为object,因此,None不能参与到人任何计算中(NoneType)
- np.nan(NaN) 是浮点类型(float),能参与到计算中.但计算的结果总是NaN
- 在pandas中把None和np.nan都视作np.nan
- 缺失值处理方法
- isnull() 有缺失值则返回True
- notnull() 没有缺失值则返回True
- isnull().any(axis=1) axis=1是代表行,0代表列,一行中只要有一个空值则返回True
- notnull().all(axis=1) 一行中所有不为空则返回True
- df.dropna(axis=0, how=‘any’, thresh=None, subset=None, inplace=False) 删除有缺失值的整行或整列
- axis=0 这里的0代表行
- how=‘any’ how是删除方式,any只要一行或一列中有一个缺失值就删除,还有一个all代表的意思是,一行或一列中所有的都为缺失值才删除,常用的是any
- inplace=False inplace代表操作是否对原数据进行覆盖,False代表不在原数据上修改,而是复制出一份,True代表在原数据上修改
- df.fillna(value=None, method=None, axis=None, inplace=False, limit=None, downcast=None, *kwargs) 对缺失值进行填充
- value 填充的值,也可以是字典
- axis 1 代表行,0代表列
- inplace inplace代表操作是否对原数据进行覆盖,False代表不在原数据上修改,而是复制出一份,True代表在原数据上修改
- method 分为四种填充方式:‘backfill’, ‘bfill’, ‘pad’, ‘ffill’ 其中pad / ffill表示用前面行/列的值,填充当前行/列的空值; backfill / bfill表示用后面行/列的值,填充当前行/列的空值
三、Matplotlib Pyplot
1.matplotlib pyplot简介
-
Pyplot 是 Matplotlib 的子库,提供了和 MATLAB 类似的绘图 API
-
Pyplot 包含一系列绘图函数的相关函数,每个函数会对当前的图像进行一些修改,例如:给图像加上标记,生新的图像,在图像中产生新的绘图区域等等
-
导入pyplot库
import matplotlib.pyplot as plt
2.plot函数
plot() 用于画图它可以绘制点和线,语法格式如下
-
画单条线
- plot([x], y, [fmt], data=None, **kwargs)
-
画多条线
- plot([x], y, [fmt], [x2], y2, [fmt2], …, **kwargs)
-
参数介绍
-
带有[]的参数是可选参数
-
[x] 默认参数,x为0~N-1
-
可选参数[fmt] 是一个字符串来定义图的基本属性 如:颜色(color),点型(marker),线型(linestyle)具体形式 fmt = ‘[color][marker][line]’ fmt接收的是每个属性的单个字母缩写 如 ‘bo-’ 蓝色圆点实线
-
若属性用的是全名则不能用fmt参数来组合赋值,应该用关键字参数对单个属性赋值
plot(x,y2,color='green', marker='o', linestyle='dashed', linewidth=1, markersize=6)
-
-
示例1:
plt.plot([1,2,3,4],[1,4,9,16],"bo-") #也可以是ob,没顺序要求 plt.show() print(line,type(line))#[] 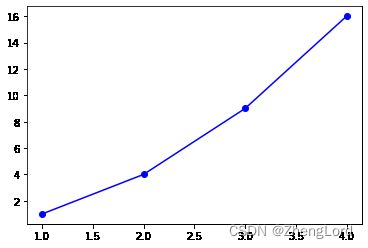
-
示例2:
t = np.arange(0.,5.,0.2) #左闭右开从0到5间隔0.2 plt.plot(t,t,"r--", t,t**2,"bs-", t,t**3,"g^-") plt.show()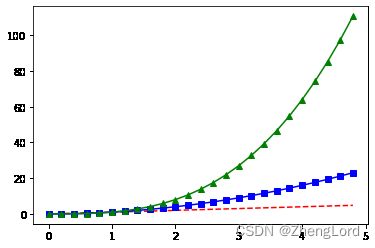
-
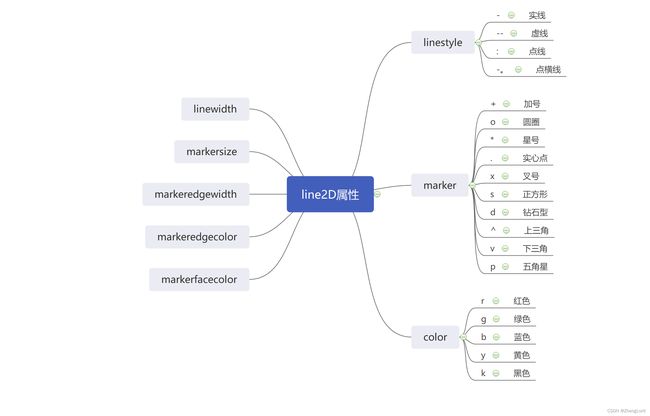
线条属性
-
color:折线的颜色
-
linestyle:指定折线的类型,可以是实线、虚线、点虚线、点点线等,默认文实线;
-
linewidth:指定折线的宽度
-
marker:可以为折线图添加点,该参数是设置点的形状;
-
markersize:设置点的大小;
-
markeredgecolor:设置点的边框色;
-
markerfactcolor:设置点的填充色;
-
图示:
-
-
设置属性
-
plt.setp(obj,*args,**kwargs)
- obj: 要设置的对象
- *args、**kwargs:需要设置的属性值
-
调用方式
-
setp(line, linewidth=2, color='r') -
setp还支持 MATLAB 式的键值对setp(lines, 'linewidth', 2, 'color', 'r') -
示例3:
x = np.linspace(-np.pi,np.pi) y = np.sin(x) line = plt.plot(x,y) #plt.setp(line, color = 'g',linewidth = 4) plt.setp(line,"color",'r',"linewidth",4) #matlab风格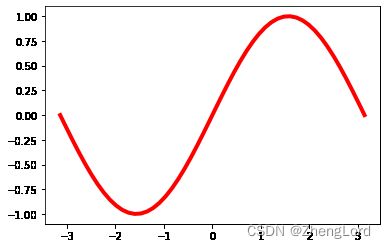
-
-
3.理解plt与ax
-
一幅图的结构: python是面向对象的,同样利用matplotlib画图从面向对象的角度更容易理解
-
Figure对象:可看成是一个画布。有了画布之后,才能在上面画各种图
-
Axes对象:画布上的一块区域,这个区域肯定要包含许多信息,比如曲线,坐标轴,标题,图例,注释等。这些就是Axes对象包含的属性,它们也是各种对象。比如Line2D,XAxis,YAxis
-
如图:
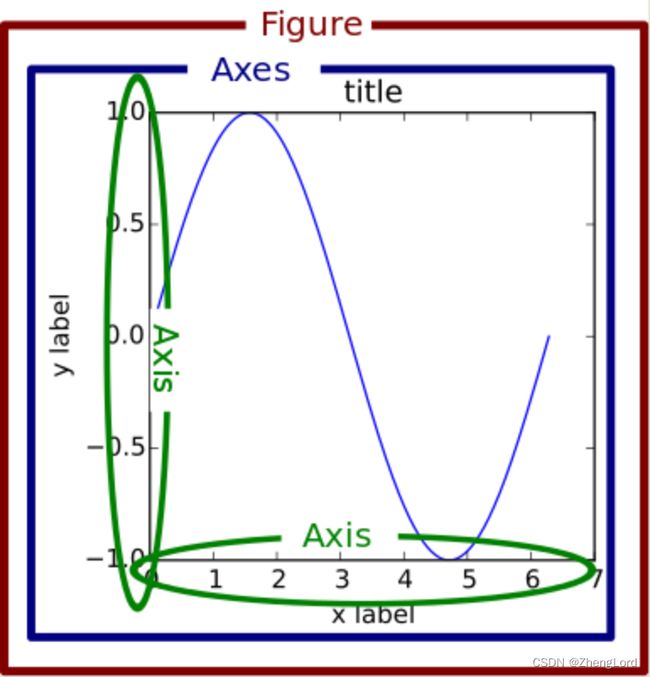
-
-
matplotlib 架构上分为三层
- 底层:backend layer
- 中层:artist layer
- 最高层:scripting layer
- 在任意一层操作都能够实现画图的目的,而且画出来还都一样。但越底层的操作越细节话,越高层越易于人机交互。
- .plt 对应的就是最高层 scripting layer。这就是为什么它简单上手,但要调细节就不灵了
- ax.plot 是在 artist layer 上操作。基本上可以实现任何细节的调试
-
两种绘图方式的区别
对这两个概念有基本的了解后,就可以来看看
plt.plot()和ax.plot()有何区别-
plt
# 第一种方式 plt.figure() plt.plot([1,2,3],[4,5,6]) plt.show() -
ax
# 第二种方式 fig,ax = plt.subplots() ax.plot([1,2,3],[4,5,6]) plt.show() -
其实就这两种方式画出的图形其实是一样的,但是
- 第一种方式的代码,先生成了一个
Figure画布,然后在这个画布上隐式生成一个画图区域进行画图 - 第二种方式同时生成了
Figure和axes两个对象,然后用ax对象在其区域内进行绘图
- 第一种方式的代码,先生成了一个
-
4.子图形的构成
4.1 Figure
-
figure简介
在绘制图形之前,我们需要一个Figure对象,可以理解成我们需要一张画板才能开始绘图
-
plt.figure(num=None,figsize=None,dpi=None,facecolor=None, edgecolor=None,frameon=True,clear=False,**kwargs): 产生一个指定编号为
num的图- num: 图像编号或名称,数字为编号 ,字符串为名称
- figsize: 指定figure的宽和高,单位为英寸
- dpi: 参数指定绘图对象的分辨率,即每英寸多少个像素,缺省值为80, 1英寸等于2.5cm,A4纸是 21*30cm的纸张
- facecolor: 背景颜色
- edgecolor: 边框颜色
- frameon: 是否显示边框
4.2 subplot函数
-
使用
subplots可以在一幅图中生成多个子图也即 axes对象 -
plt.subplot(nrows, ncols, fignum,**fig_kw): 绘图时需要指定位置
- nrows: subplot的行数
- ncols: subplot的列数,行X列就是被分成多少个图像区域
- fignum: 目前该图像位于第几个位置
- **fig_kw: 创建figure时的其他关键字
-
subplots(nrows=1, ncols=1) 方法可以一次生成多个,在调用时只需要调用生成对象的 ax 即可
- nrows:默认为 1,设置图表的行数
- ncols:默认为 1,设置图表的列数
-
函数调用:
plt.subplot(ijn) i代表划分为几行j为几列,n是指目前在第几个子区域内,当
numrows * numncols < 10时,中间的逗号可以省略,因此plt.subplot(211)就相当于plt.subplot(2,1,1) -
示例4:
def f(t): return np.exp(-t)*np.cos(2*np.pi*t) t1 = np.arange(0.0,5.0,0.1) t2 = np.arange(0.0,4.0,0.02) plt.figure(figsize = (10,6),facecolor='g')#背景设为绿色 ax1=plt.subplot(211) print(ax1,type(ax1))#AxesSubplot(0.125,0.536818;0.775x0.343182)plt.plot(t1,f(t1),"bo",t2,f(t2),'k') #子图1上有两条线 plt.subplot(212) plt.plot(t2,np.cos(2*np.pi*t2),"r--") plt.show() 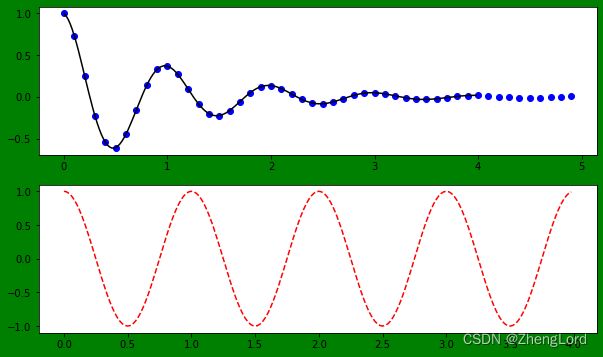
-
另一种写法:
fig = plt.figure() ax1 = fig.add_subplot(221) # 划分为2行2列四个区域,这是第一个区域,以下以此类推 ax1.set(title="标题1",ylabel='y',xlabel='x') ax2 = fig.add_subplot(222) ax2.set(title="标题2",ylabel='y',xlabel='x') ax3 = fig.add_subplot(223) ax3.set(title="标题3",ylabel='y',xlabel='x') ax4 = fig.add_subplot(224) ax4.set(title="标题4",ylabel='y',xlabel='x') plt.show()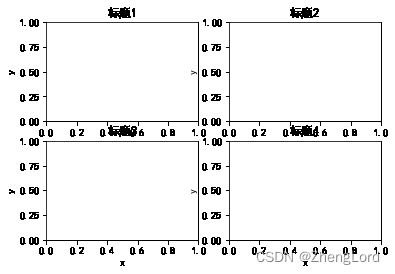
5.图形标注
5.1 坐标轴相关设置
-
解决乱码问题
plt.rcParams["font.sans-serif"] = ["SimHei"] #解决中文字符乱码的问题 # SimHei:微软雅黑 # FangSong:仿宋 plt.rcParams["axes.unicode_minus"] = False #正常显示负号 -
坐标轴标签设置—以xlabel函数为例
-
函数语法:
xlabel(xlabel, fontdict=None, labelpad=None, *, loc=None, **kwargs): 设置X轴的标签
-
函数参数:
- xlabel: 字符串格式,标签文本内容
- fontdict: dict, 一个字典用来控制标签的字体样式
- labelpad: 浮点数,默认值为None, x/y轴的标签离x/y轴的偏移量,以点为单位
- loc(location): 标签位置,默认在中间,对于x轴是’left’,‘center’,‘right’,对于y轴则是’bottom’, ‘center’, ‘top’
-
示例:
plt.rcParams["font.sans-serif"] = ["SimHei"] #解决中文字符乱码的问题 plt.rcParams["axes.unicode_minus"] = False #正常显示负号 line=plt.plot([1,2,3,4]) #默认以列表的索引作为x,输入的是y plt.ylabel('y轴',labelpad=20,loc='top',fontdict={'color':"red",'fontsize':20}) plt.xlabel("x轴") plt.show() #注意y轴标签与x轴的区别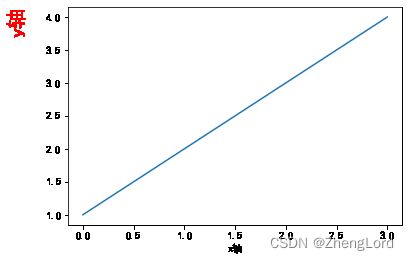
-
另一种写法ax.set_xlabel() 用法与xlabel() 相同
plt.rcParams["font.sans-serif"] = ["SimHei"] #解决中文字符乱码的问题 plt.rcParams["axes.unicode_minus"] = False #正常显示负号 def f(t): return np.exp(-t)*np.cos(2*np.pi*t) t1 = np.arange(0.0,5.0,0.1) t2 = np.arange(0.0,4.0,0.02) plt.figure(figsize = (10,6),facecolor='g') ax1=plt.subplot(211) plt.plot(t1,f(t1),"bo",t2,f(t2),'k') #子图1上有两条线 ax1.set(title="标题一") ax1.set_ylabel('y轴',labelpad=20,loc='top',fontdict={'color':"red",'fontsize':20}) plt.show()
-
-
坐标轴刻度设置
-
函数语法
yticks(ticks=None, labels=None, **kwargs) ax.yticks或者plt.yticks
-
参数说明
- ticks: 可选参数,数组,x轴刻度位置的列表。传入空列表移除所有x轴刻度
- labels: 可选参数,数组,放在指定刻度位置的标签文本。只有当ticks参数有输入值,该参数才能传入参数
-
示例:
#不使用xticks函数 x=np.linspace(1,10,100) y = np.sin(x) plt.plot(x,y) # plt.xticks(range(1,10)) plt.show() #使用xticks函数 x=np.linspace(1,10,100) y = np.sin(x) plt.plot(x,y) plt.xticks(range(1,10),['a','b','c','d','e','f','g','h','i']) plt.show() -
plt.axis([xmin,xmax,ymin,ymax]): 该方法可以让你用一行代码设置 x 和 y 的限值,它还可以按照图形的内容自动收紧坐标轴,不留空白区域
axis()函数除了支持数值列表作为输入外,还支持字符选项。Matplotlib会根据输入的字符选项自动地对轴进行调整-
axis(‘off’):关闭轴线和标签
-
axis(‘equal’):使x轴与y轴保持与屏幕一致的高宽比(横纵比)
-
axis(‘tight’):使x轴与y轴限制在有数据的区域
-
axis(‘square’):使x轴与y轴坐标一致
x=np.linspace(0,10,20) plt.plot(x,np.sin(x)) plt.axis([-1,11,-1.5,1.5]) plt.show()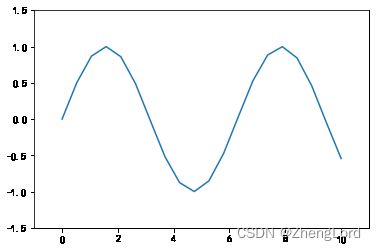
-
-
5.2 设置标题(title)
-
函数语法
plt.title(label, fontdict=None, loc=None, pad=None, *, y=None, **kwargs): 设置坐标系标题
ax.set_title() 用法同上
-
函数参数
-
label: 字符串,用于标题文本内容
-
fontdictdict: 字体字典项:控制标题文本展现,默认设置如下
{'fontsize': rcParams['axes.titlesize'], 'fontweight': rcParams['axes.titleweight'], 'color': rcParams['axes.titlecolor'], 'verticalalignment': 'baseline', 'horizontalalignment': loc} -
loc: 标题文本的位置,默认’center’,可以设置’center’, ‘left’, ‘right’,控制标题的左右移动
-
y: 浮点型,标题的垂直位置(顶部是1.0)。 如果为None(默认),则自动确定,控制标题的上下移动
-
-
示例:
plt.rcParams["font.sans-serif"] = ["SimHei"] #解决中文字符乱码的问题 plt.rcParams["axes.unicode_minus"] = False #正常显示负号 x = np.linspace(-2,2,1000) y = np.exp(x) plt.plot(x,y,ls='-',lw=2,color='g') plt.title("center",fontdict={ 'fontsize': 20, #字体大小 'fontweight':'light', #字体粗细, ‘light’, ‘normal’, ‘medium’, ‘semibold’, ‘bold’, ‘heavy’, ‘black’ 'color':'r', #字体颜色 'verticalalignment':'top',# 垂直对齐方式,'center', 'top', 'bottom', 'baseline', 'center_baseline' 'horizontalalignment':'center',#对齐方式,'center', 'right', 'left' 'family':'Times New Roman', #字体系列,它的值有很多,比如 “宋体”,“微软雅黑”等等 'fontstyle':'italic' #字体风格:它的值有:normal(默认值)、italic(斜体)、oblique(倾斜) }) plt.show()
5.3 图例设置
图例是对图形所展示的内容的解释,比如在一张图中画了三条线,那么这三条线都代表了什么呢?这时就需要做点注释,便引出下面的函数
-
plt.legend(*args,** kwargs) 或者ax.legend() 这个函数参数挺多的,主要介绍几个常用的参数
- handles: 需要传入你所画线条的实例对象
- labels: 是图例的名称(能够覆盖在plt.plot( )中label参数值)
- loc: 代表了图例在整个坐标轴平面中的位置
- ncol: 图例的列的数量,默认为1
-
用法:
-
方法一:采用plt.legend( )默认参数
-
第一步: 给plt.plot( )中参数label=''传入字符串类型的值,也就是图例的名称
-
第二步: 使用plt.legend( )使上述代码产生效果
-
示例:
plt.rcParams['font.sans-serif'] = ['SimHei'] plt.rcParams['axes.unicode_minus'] = False n = np.linspace(-5, 4, 30) m1 = 3 * n + 2 m2 = n ** 2 plt.xlabel('时间') plt.ylabel('心情') plt.plot(n, m1, color='r', linewidth=1.5, linestyle='-', label='女生购物欲望') plt.plot(n, m2, 'b', label='男生购物欲望') plt.legend() plt.show()
-
-
方法二:向plt.legend( )中设置参数,进行个性化图例定制
-
示例:
plt.rcParams['font.sans-serif'] = ['SimHei'] plt.rcParams['axes.unicode_minus'] = False n = np.linspace(-5, 4, 30) m1 = 3 * n + 2 m2 = n ** 2 plt.xlabel('时间') plt.ylabel('心情') line1, = plt.plot(n, m1, color='r', linewidth=1.5, linestyle='-', label='女生购物欲望')#label属性可不写 line2, = plt.plot(n, m2, 'b', label='男生购物欲望') plt.legend(handles=[line1, line2], labels=['girl购物欲望','boy购物欲望'], loc='best',ncol=2) plt.show()
-
-
5.4 文本注释
-
函数语法
text(x, y, s, fontdict=None, **kwargs): 添加注释文本;在坐标(x,y)位置添加文本
-
函数参数:
-
x, y: 浮点型,放置注释文本的数字坐标位置
-
s: 字符型,文本内容
-
fontdict: 字典类型,默认为空;用于覆盖默认文本属性的字典项,若字典项为空则默认属性由rcParams确定。默认设置如下:
{'fontsize': rcParams['axes.titlesize'], 'fontweight': rcParams['axes.titleweight'], 'color': rcParams['axes.titlecolor'], 'verticalalignment': 'baseline', 'horizontalalignment': loc} -
**kwargs: 其他参数: 设置文本属性。如:weight: 注释文本内容的粗细风格,color: 注释文本内容的字体颜色
-
-
示例:
x = np.linspace(0.05, 10, 1000) y = np.sin(x) plt.plot(x, y, ls="-.", lw=2, c="r", label="plot figure") plt.legend() plt.text(3.10, 0.09, "y=sin(x)", weight="bold", color="b") plt.show()
5.5 设置网格线
-
函数语法:
plt.grid(b=None, which=‘major’, axis=‘both’, **kwargs)或者ax.grid() 设置图表中的网格线
-
参数说明:
- b:可选,默认为 None,可以设置布尔值,true 为显示网格线,false 为不显示,如果设置 **kwargs 参数,则值为 true
- which:可选,可选值有 ‘major’、‘minor’ 和 ‘both’,默认为 ‘major’,表示应用更改的网格线
- axis:可选,设置显示哪个方向的网格线,可以是取 ‘both’(默认),‘x’ 或 ‘y’,分别表示两个方向,x 轴方向或 y 轴方向
- **kwargs:可选,设置网格样式,可以是 color=‘r’, linestyle=‘-’ 和 linewidth=2,分别表示网格线的颜色,样式和宽度
-
示例:
x = np.array([1, 2, 3, 4]) y = np.array([1, 4, 9, 16]) plt.title("RUNOOB grid() Test") plt.xlabel("x - label") plt.ylabel("y - label") plt.plot(x, y) plt.grid(color = 'r', linestyle = '--', linewidth = 0.5) plt.show()
6.柱状图
bar() 函数用于绘制柱状图
-
函数语法
*plt.bar(x, height, width=0.8, bottom=None, , align=‘center’, data=None, **kwargs)
-
函数参数
- x: 浮点型或类数组对象;柱形的的x轴坐标
- height: 浮点型或类数组对象;柱形的高度
- width: 浮点型或类数组对象;柱形的宽度,默认值为0.8
- bottom: 浮点型或类数组对象; 柱形基座的y坐标,默认0
- align: 对齐方式: 中间,边缘 ,默认为中间。柱与x轴坐标的对其方式。center: x轴坐标在中间位置,edge: x轴坐标在左边
- Other Parameters:
- color: 可选参数,颜色或颜色列表 。柱形颜色
- edgecolor: 可选参数:颜色或颜色列表 。柱形边缘的颜色
-
示例:
labels = ['G1', 'G2', 'G3', 'G4', 'G5'] men_means = [20, 34, 30, 35, 27] women_means = [25, 32, 34, 20, 25] x = np.arange(len(labels)) # the label locations width = 0.35 # the width of the bars fig, ax = plt.subplots() rects1 = ax.bar(x - width/2, men_means, width, label='Men',color='g') rects2 = ax.bar(x + width/2, women_means, width, label='Women',color='b') for a,b in zip(x,men_means): #数字直接显示在柱子上(添加文本) plt.text(a-width/2,b,b,ha = "center",va = "bottom",fontsize = 10) for a,b in zip(x,women_means): #数字直接显示在柱子上(添加文本) plt.text(a+width/2,b,b,ha = "center",va = "bottom",fontsize = 10) # Add some text for labels, title and custom x-axis tick labels, etc. ax.set_ylabel('Scores') ax.set_title('Scores by group and gender') ax.set_xticks(x) ax.set_xticklabels(labels) ax.legend()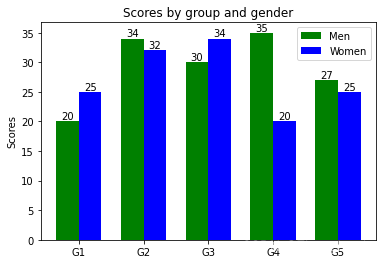
7.条形图
函数Barh() 用于绘制条形图
-
函数语法
barh(y, width, height=0.8, left=None, *, align=‘center’, **kwargs)
-
用法与bar() 基本一致
-
示例:
df = pd.read_excel(r"D:\BaiduNetdiskDownload\python\python\作业5\movie_data3.xlsx", index_col = 0) data = df["产地"].value_counts() x = data.index y = data.values plt.figure(figsize = (10,6)) #设置图片大小 plt.barh(x,y,color = "g") #绘制柱状图,表格给的数据是怎样就怎样,不会自动排序 plt.title("各国家或地区电影数量", fontsize = 20) #设置标题 plt.xlabel("国家或地区",fontsize = 18) plt.ylabel("电影数量") #对横纵轴进行说明 plt.tick_params(labelsize = 14) #设置标签字体大小 # plt.xticks(rotation = 90) #标签转90度 for a,b in zip(x,y): #数字直接显示在柱子上(添加文本) #a:x的位置,b:y的位置,加上10是为了展示位置高一点点不重合, #第二个b:显示的文本的内容,ha,va:格式设定,center居中,top&bottom在上或者在下,fontsize:字体指定 plt.text(b,a,a,fontsize = 10) #plt.grid() #画网格线,有失美观因而注释点 plt.show()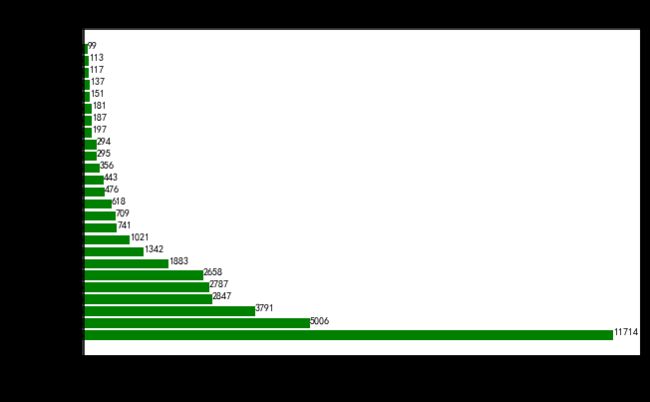
8.饼状图
饼图英文学名为Sector Graph,又名Pie Graph。常用于统计学模块。饼图中的数据点(数据点:在图表中绘制的单个值,这些值由条形,柱形,折线,饼图或圆环图的扇面、圆点和其他被称为数据标记的图形表示。相同颜色的数据标记组成一个数据系列。)显示为整个饼图的百分比。可以使用 pyplot 中的 **pie() **方法来绘制饼图。
-
函数语法
plt.pie(x, explode=None, labels=None, colors=None, autopct=None, pctdistance=0.6, shadow=False, labeldistance=1.1, startangle=0, radius=1, counterclock=True, wedgeprops=None, textprops=None, center=0, 0, frame=False, rotatelabels=False, *, normalize=None, data=None)
-
参数说明
- x:浮点型数组,表示每个扇形的面积
- explode:数组,表示各个扇形之间的间隔,默认值为0
- labels:列表,各个扇形的标签,默认值为 None
- colors:数组,表示各个扇形的颜色,默认值为 None
- autopct:设置饼图内各个扇形百分比显示格式,%d%% 整数百分比,%0.1f 一位小数, %0.1f%% 一位小数百分比, %0.2f%% 两位小数百分比
- labeldistance:标签标记的绘制位置,相对于半径的比例,默认值为 1.1,如 <1则绘制在饼图内侧
- pctdistance::类似于 labeldistance,指定 autopct 的位置刻度,默认值为 0.6
- shadow::布尔值 True 或 False,设置饼图的阴影,默认为 False,不设置阴影
- radius::设置饼图的半径,默认为 1
- startangle::起始绘制饼图的角度,默认为从 x 轴正方向逆时针画起,如设定 =90 则从 y 轴正方向画起
-
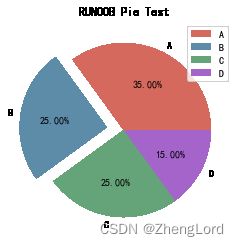
示例:
import matplotlib.pyplot as plt import numpy as np y = np.array([35, 25, 25, 15]) plt.pie(y, labels=['A','B','C','D'], # 设置饼图标签 colors=["#d5695d", "#5d8ca8", "#65a479", "#a564c9"], # 设置饼图颜色 explode=(0, 0.2, 0, 0), # 第二部分突出显示,值越大,距离中心越远 autopct='%.2f%%', # 格式化输出百分比 ) plt.title("RUNOOB Pie Test") plt.show()