重温Faster RCNN算法(2)--FPN
参考自xiamentingtao:https://blog.csdn.net/xiamentingtao/article/details/78598027
1. FPN解决了什么问题?
答: 在以往的faster rcnn进行目标检测时,无论是rpn还是fast rcnn,roi 都作用在最后一层,这在大目标的检测没有问题,但是对于小目标的检测就有些问题。因为对于小目标来说,当进行卷积池化到最后一层,实际上语义信息已经没有了,因为我们都知道对于一个roi映射到某个feature map的方法就是将底层坐标直接除以stride,显然越后,映射过去后就越小,甚至可能就没有了。 所以为了解决多尺度检测的问题,引入了特征金字塔网络。
下面我们介绍一下特征金字塔网络。如下引用[1]
-
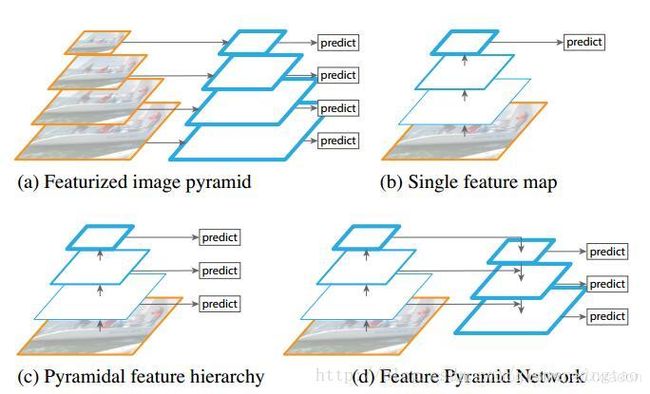
图(a)是相当常见的一种多尺度方法,称为featurized image pyramid,这种方法在较早的人工设计特征(DPM)时被广泛使用,在CNN中也有人使用过。就是对input iamge进行multi scale,通过设置不同的缩放比例实现。这种可以解决多尺度,但是相当于训练了多个模型(假设要求输入大小固定),即便允许输入大小不固定,但是也增加了存储不同scale图像的内存空间。
-
图(b)就是CNN了,cnn相比人工设计特征,能够自己学习到更高级的语义特征,同时CNN对尺度变化鲁棒,因此如图,从单个尺度的输入计算的特征也能用来识别,但是遇到明显的多尺度目标检测时,还是需要金字塔结构来进一步提升准确率。
从现在在imageNet和COCO数据集上领先的的一些方法来看,在测试的时候都用到了featurized image pyramid方法,即结合(a),(b)。 说明了特征化图像金字塔的每一级的好处在于,产生了多尺度的特征表示,每一级的特征都有很强的语义(因为都用cnn生成的特征),包括高分辨率的一级(最大尺度的输入图像)。
但是这种模式有明显的弊端,相比于原来方法,时间增长了4倍,很难在实时应用中使用,同样,也增大了存储代价,这就是为什么只是在测试阶段使用image pyramid。但是如果只在测试阶段使用,那么训练和测试在推断的时候会不一致。所以,最近的一些方法干脆舍弃了image pyramid。
但是image pyramid不是计算多尺度特征表示的唯一方法。deepCNN能够层次化的特征,而且因为池化的作用,会产生金字塔形的特征,具有一种内在的多尺度。但是问题在于,高分辨率的map(浅层)具有low-level的特征,所以浅层的目标识别性能较弱。这也是不同level融合的目的。
-
如图©,SSD较早尝试了使用CNN金字塔形的层级特征。理想情况下,SSD风格的金字塔 重利用了前向过程计算出的来自多层的多尺度特征图,因此这种形式是不消耗额外的资源的。但是SSD为了避免使用low-level的特征,放弃了浅层的feature map,而是从conv4_3开始建立金字塔,而且加入了一些新的层。因此SSD放弃了重利用更高分辨率的feature map,但是这些feature map对检测小目标非常重要。这就是SSD与FPN的区别。
-
图(4)是FPN的结构,FPN是为了自然地利用CNN层级特征的金字塔形式,同时生成在所有尺度上都具有强语义信息的特征金字塔。所以FPN的结构设计了top-down结构和横向连接,以此融合具有高分辨率的浅层layer和具有丰富语义信息的深层layer。这样就实现了从单尺度的单张输入图像,快速构建在所有尺度上都具有强语义信息的特征金字塔,同时不产生明显的代价。
下面我们再来看一下相似的网络:

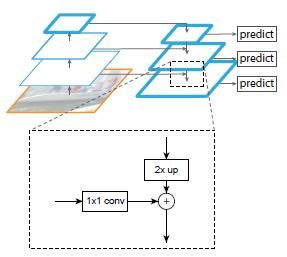
上面一个带有skip connection的网络结构在预测的时候是在finest level(自顶向下的最后一层)进行的,简单讲就是经过多次上采样并融合特征到最后一步,拿最后一步生成的特征做预测。而FPN网络结构和上面的类似,区别在于预测是在每一层中独立进行的。后面的实验证明finest level的效果不如FPN好,原因在于FPN网络是一个窗口大小固定的滑动窗口检测器,因此在金字塔的不同层滑动可以增加其对尺度变化的鲁棒性。另外虽然finest level有更多的anchor,但仍然效果不如FPN好,说明增加anchor的数量并不能有效提高准确率。
自下而上的路径
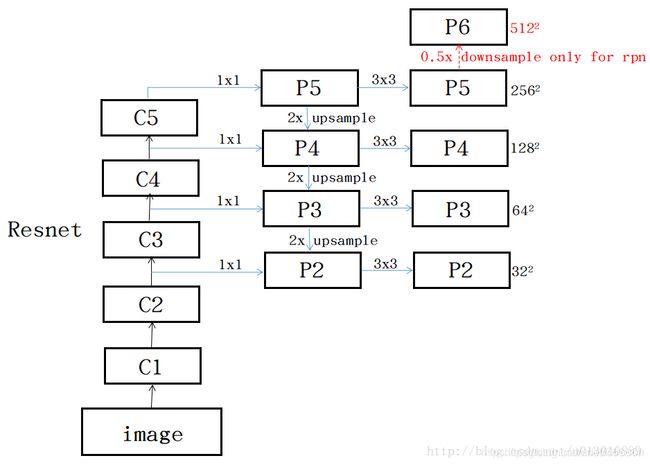
CNN的前馈计算就是自下而上的路径,特征图经过卷积核计算,通常是越变越小的,也有一些特征层的输出和原来大小一样,称为“相同网络阶段”(same network stage )。对于本文的特征金字塔,作者为每个阶段定义一个金字塔级别, 然后选择每个阶段的最后一层的输出作为特征图的参考集。 这种选择是很自然的,因为每个阶段的最深层应该具有最强的特征。具体来说,对于ResNets,作者使用了每个阶段的最后一个残差结构的特征激活输出。将这些残差模块输出表示为{C2, C3, C4, C5},对应于conv2,conv3,conv4和conv5的输出,并且注意它们相对于输入图像具有{4, 8, 16, 32}像素的步长。考虑到内存占用,没有将conv1包含在金字塔中。
自上而下的路径和横向连接
自上而下的路径(the top-down pathway )是如何去结合低层高分辨率的特征呢?方法就是,把更抽象,语义更强的高层特征图进行上取样,然后把该特征横向连接(lateral connections )至前一层特征,因此高层特征得到加强。值得注意的是,横向连接的两层特征在空间尺寸上要相同。这样做应该主要是为了利用底层的定位细节信息。
下图显示连接细节。把高层特征做2倍上采样(最邻近上采样法,可以参考反卷积),然后将其和对应的前一层特征结合(前一层要经过1 * 1的卷积核才能用,目的是改变channels,应该是要和后一层的channels相同),结合方式就是做像素间的加法。重复迭代该过程,直至生成最精细的特征图。迭代开始阶段,作者在C5层后面加了一个1 * 1的卷积核来产生最粗略的特征图,最后,作者用3 * 3的卷积核去处理已经融合的特征图(为了消除上采样的混叠效应),以生成最后需要的特征图。为了后面的应用能够在所有层级共享分类层,这里坐着固定了3*3卷积后的输出通道为d,这里设为256.因此所有额外的卷积层(比如P2)具有256通道输出。这些额外层没有用非线性。
{C2, C3, C4, C5}层对应的融合特征层为{P2, P3, P4, P5},对应的层空间尺寸是相通的。
2. 应用
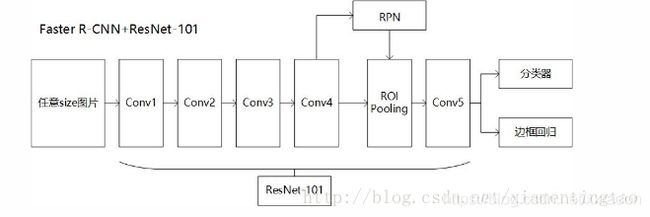
Faster R-CNN+Resnet-101
本部分来源自:http://www.voidcn.com/article/p-xtjooucw-dx.html
要想明白FPN如何应用在RPN和Fast R-CNN(合起来就是Faster R-CNN),首先要明白Faster R-CNN+Resnet-101的结构,这部分在是论文中没有的,博主试着用自己的理解说一下。
直接理解就是把Faster-RCNN中原有的VGG网络换成ResNet-101,ResNet-101结构如下图:
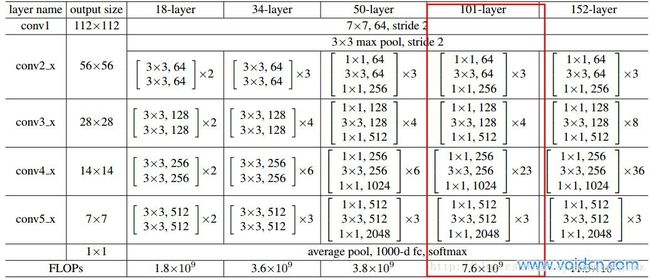
Faster-RCNN利用conv1到conv4-x的91层为共享卷积层,然后从conv4-x的输出开始分叉,一路经过RPN网络进行区域选择,另一路直接连一个ROI Pooling层,把RPN的结果输入ROI Pooling层,映射成7 * 7的特征。然后所有输出经过conv5-x的计算,这里conv5-x起到原来全连接层(fc)的作用。最后再经分类器和边框回归得到最终结果。整体框架用下图表示:
RPN中的特征金字塔网络
本部分来源自:http://www.voidcn.com/article/p-xtjooucw-dx.html
RPN是Faster R-CNN中用于区域选择的子网络,RPN是在一个13 * 13 * 256的特征图上应用9种不同尺度的anchor,本篇论文另辟蹊径,把特征图弄成多尺度的,然后固定每种特征图对应的anchor尺寸,很有意思。也就是说,作者在每一个金字塔层级应用了单尺度的anchor,{P2, P3, P4, P5, P6}分别对应的anchor尺度为{32^2, 64^2, 128^2, 256^2, 512^2 },当然目标不可能都是正方形,本文仍然使用三种比例{1:2, 1:1, 2:1},所以金字塔结构中共有15种anchors。这里,博主尝试画一下修改后的RPN结构:

从图上看出各阶层共享后面的分类网络。这也是强调为什么各阶层输出的channel必须一致的原因,这样才能使用相同的参数,达到共享的目的。
注意上面的p6,根据论文中所指添加:

正负样本的界定和Faster RCNN差不多:如果某个anchor和一个给定的ground truth有最高的IOU或者和任意一个Ground truth的IOU都大于0.7,则是正样本。如果一个anchor和任意一个ground truth的IOU都小于0.3,则为负样本。
Fast R-CNN 中的特征金字塔网络
Fast R-CNN 中很重要的是ROI Pooling层,需要对不同层级的金字塔制定不同尺度的ROI。
ROI Pooling层使用region proposal的结果和中间的某一特征图作为输入,得到的结果经过分解后分别用于分类结果和边框回归。
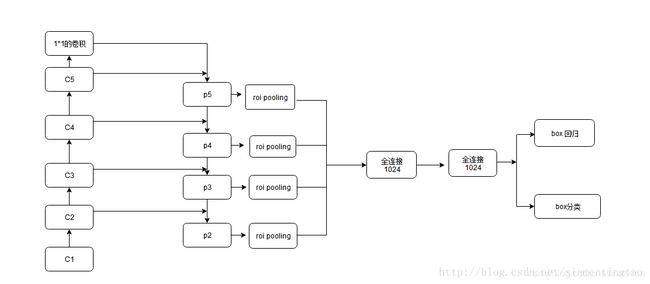
然后作者想的是,不同尺度的ROI使用不同特征层作为ROI pooling层的输入,大尺度ROI就用后面一些的金字塔层,比如P5;小尺度ROI就用前面一点的特征层,比如P4。那怎么判断ROI改用那个层的输出呢?这里作者定义了一个系数Pk,其定义为:

224是ImageNet的标准输入,k0是基准值,设置为5,代表P5层的输出(原图大小就用P5层),w和h是ROI区域的长和宽,假设ROI是112 * 112的大小,那么k = k0-1 = 5-1 = 4,意味着该ROI应该使用P4的特征层。k值应该会做取整处理,防止结果不是整数。
然后,因为作者把conv5也作为了金字塔结构的一部分,那么从前全连接层的那个作用怎么办呢?这里采取的方法是增加两个1024维的轻量级全连接层,然后再跟上分类器和边框回归,认为这样还能使速度更快一些。
最后,博主根据自己的理解画了一张草图,猜想整个网络经FPN修改后的样子,也就是Faster R-CNN with FPN。
总结
作者提出的FPN(Feature Pyramid Network)算法同时利用低层特征高分辨率和高层特征的高语义信息,通过融合这些不同层的特征达到预测的效果。并且预测是在每个融合后的特征层上单独进行的,这和常规的特征融合方式不同。
目前官方开源代码尚未公布,网上有一部分开源代码,如pytorch的
https://github.com/facebookresearch/maskrcnn-benchmark
config文件中几个参数的理解(ANCHOR_SIZES,ASPECT_RATIOS,ANCHOR_STRIDE)
# Base RPN anchor sizes given in absolute pixels w.r.t. the scaled network input
_C.MODEL.RPN.ANCHOR_SIZES = (32, 64, 128, 256, 512)
# Stride of the feature map that RPN is attached.
# For FPN, number of strides should match number of scales
_C.MODEL.RPN.ANCHOR_STRIDE = (4,,8,16,32,64)
# RPN anchor aspect ratios
_C.MODEL.RPN.ASPECT_RATIOS = (0.5, 1.0, 2.0)
# Remove RPN anchors that go outside the image by RPN_STRADDLE_THRESH pixels
# Set to -1 or a large value, e.g. 100000, to disable pruning anchors
至于为什么有五个anchor_stride,是因为fpn 要为rpn再下采样一次,所以相当于有五个层的fpn网络。结合所有的anchor_scales和anchor_ratios生成框,进行前后景的分类.