标签

进入正题,首先,把urllib和beautifulsoup包安装下来(python3.x)
pip install beautifulsoup4
pip install urllib
pip install lxml
然后,用urllib获取网页信息,并用 beautifulsoup解析并抽取需要的链接
import urllib.request
from bs4 import BeautifulSoup
url = 'http://www.baidu.com'
data=urllib.request.urlopen(url).read()
page_data=data.decode('utf-8')
# print(page_data)
soup = BeautifulSoup(page_data, 'lxml')
a_tag_list = soup.find('div', {'id':'s-top-left'}).children
for a_tag in a_tag_list:
print(a_tag.get('href'), a_tag.text)
最终,控制台输出了如下结果
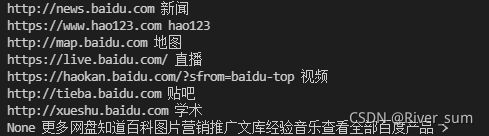
PS:“更多”那个地方需要一些额外处理来获取其内部的其余子标签,这里就不详细展示了
PS:beautifulsoup的详细方法,可以参考官方中文文档Beautiful Soup 4.2.0 文档 — Beautiful Soup 4.2.0 documentation (crummy.com)
2.Python 多线程
实现python的多线程需要threading这个内置的包,我们首先
from threading import Thread
一般来说,创建一个线程的具体思路是:定义一个线程需要执行的函数,声明一个线程,然后启动该线程,对于多线程而言,就是在一个for循环中不断声明线程(设置线程对应的函数及参数)并启动他们:
2.1 多线程的简单demo
import threading
#定义线程要调用的方法,*add可接收多个以非关键字方式传入的参数
def action(*add):
for arc in add:
#调用 getName() 方法获取当前执行该程序的线程名
print(threading.current_thread().getName() +" "+ arc)
#定义为线程方法传入的参数
my_tuple = ("http://c.biancheng.net/python/",\
"http://c.biancheng.net/shell/",\
"http://c.biancheng.net/java/")
#创建线程
thread = threading.Thread(target = action,args =my_tuple)
#启动线程
thread.start()
创建线程的详细方法可以参考 Python创建线程(2种方式)详解 (biancheng.net)
其次,在爬虫中,为实现线程间的通讯,我们需要一个queue包,其中提供了同步的、线程安全的队列类。举个例子,在inQueue中,我们存放所有需要爬取的url,在outQueue中,我们存放爬虫返回的信息,于是我们再导入:
from queue import Queue
一些Queue主要的方法:
- Queue.qsize() 返回队列的大小
- Queue.empty() 如果队列为空,返回True,反之False
- Queue.full() 如果队列满了,返回True,反之False,Queue.full 与 maxsize 大小对应
- Queue.get([block[, timeout]])获取队列,timeout等待时间
- Queue.get_nowait() 相当于Queue.get(False),非阻塞方法
- Queue.put(item) 写入队列,timeout等待时间
- Queue.task_done() 在完成一项工作之后,Queue.task_done()函数向任务已经完成的队列发送一个信号。每个get()调用得到一个任务,接下来task_done()调用告诉队列该任务已经处理完毕。
- Queue.join() 实际上意味着等到队列为空,再执行别的操作
一个多线程爬虫的具体思路为:先向inQueue中put(url),再开启n个线程,在每个线程中,当队列inQueue不为空时,线程不断get()队首的url进行爬取,并将爬取到的信息put()进outQueue,再inQueue.task_done()宣告该url爬取结束(即让队首的url出队),再继续get新的url,最终,当inQueue为空时,调用inQueue.join()宣告当前爬取任务结束,继续解释后面的python脚本
2.2 一个简单的爬虫+多线程demo
爬虫的代码来自1.urllib与beautifulsoup
import urllib.request
from bs4 import BeautifulSoup
from queue import Queue
from threading import Thread
url_Quene = Queue()
result_Queue = Queue()
url_list = [
'http://www.baidu.com',
'http://www.baidu.com',
'http://www.baidu.com',
'http://www.baidu.com',
'http://www.baidu.com'
]
for index, url in enumerate(url_list):
# 存放url
url_Quene.put([index, url])
def do_something(in_Quene:Queue, out_Quene:Queue):
# 定义每个线程需要执行的内容
while in_Quene.empty() is not True:
index, url = in_Quene.get()
# 用url爬取并获得信息
data=urllib.request.urlopen(url).read()
page_data=data.decode('utf-8')
soup = BeautifulSoup(page_data, 'lxml')
a_tag_list = soup.find('div', {'id':'s-top-left'}).children
result_list = []
for a_tag in a_tag_list:
result_list.append([a_tag.get('href'), a_tag.text])
# 存放在out_Quene
out_Quene.put([index, result_list])
# 当前队首执行完,出队
in_Quene.task_done()
# 开n个线程,并执行
n = 100
print('start spider*{}'.format(n))
for index in range(n):
# 创建线程,指定函数及参数
thread = Thread(target=do_something, args=(url_Quene, result_Queue, ))
thread.daemon = True # 后台运行
thread.start() # 线程启动
url_Quene.join() # 结束
print('get id info*{}'.format(url_Quene.qsize()))
# 输出结果
while result_Queue.empty() is not True:
index, result_list= result_Queue.get()
print(index, result_list)
result_Queue.task_done()
result_Queue.join() # 结束
print('done.')
3.Wikidata api
wiki data的api说明详见:
https://www.mediawiki.org/wiki/API:Main_page
https://www.mediawiki.org/w/api.php?action=help
我们这里只需要俩:
1.根据实体的名称查询对应实体的id
query_url = 'https://www.wikidata.org/w/api.php?action=wbsearchentities&search={}&language=en&limit=20&format=json'.format(str)
2.根据实体的id,获取详细的实体属性描述
wiki_url = 'https://www.wikidata.org/w/api.php?action=wbgetentities&ids={}&format=json&languages=en'.format(wiki_id)
基于此,解析api返回json的函数为:
import json
import urllib.request # 注意,不要只import urllib,会报错
def get_wiki_entity_id_by_str(str):
"""
根据查询关键字str的api,查询对应的id
https://blog.csdn.net/QFire/article/details/79573307
str关键字查询,返回id
"""
try:
query_url = 'https://www.wikidata.org/w/api.php?action=wbsearchentities&search={}&language=en&limit=20&format=json'.format(str)
response = urllib.request.urlopen(query_url)
html = json.loads(response.read()) # NameError: name 'null' is not defined
search_id = html['search'][0]['id']
return search_id
except:
# 查询不到,则返回unknwon
return 'unknown'
以及
import json
import urllib.request # 注意,不要只import urllib,会报错
def get_wiki_entity_by_id(wiki_id):
"""
根据实体的wikiID,查询实体的相关信息
"""
wiki_url = 'https://www.wikidata.org/w/api.php?action=wbgetentities&ids={}&format=json&languages=en'.format(wiki_id)
try:
response = urllib.request.urlopen(wiki_url)
except:
print('Request Failed with url {}'.format(wiki_url))
return 'unknown', 'unknown', 'unknown'
html = json.loads(response.read()) # NameError: name 'null' is not defined
entity_id = list(html['entities'].keys())[0]
entity_info = html['entities'][entity_id]
try:
en_title = entity_info['labels']['en']['value']
except:
print('Title not found with url {}'.format(wiki_url))
en_title = 'unknown'
property_dict = {}
for property_id, property_info in entity_info['claims'].items():
try:
for info in property_info:
if info['mainsnak']['snaktype'] != 'value':
continue
if info['mainsnak']['datatype'] == 'wikibase-item':
property = info['mainsnak']['datavalue']['value']['id']
if property_id not in property_dict:
property_dict[property_id] = [{'id':property}]
else:
property_dict[property_id].append({'id':property})
elif info['mainsnak']['datatype'] == 'external-id':
continue
else:
property = info['mainsnak']['datavalue']['value']
if isinstance(property, dict):
p = {'dict':property}
elif isinstance(property, list):
p = {'list':property}
elif isinstance(property, str):
p = {'str':property}
else:
p = {'other':property}
if property_id not in property_dict:
property_dict[property_id] = [p]
else:
property_dict[property_id].append(p)
except Exception as e:
print(e)
print(entity_id, property_id)
print('*********************')
return entity_id, en_title, property_dict
可以针对具体需要再做更改,我这里根据实体名称,查询实体id(选第一个),再根据实体id,查询实体的属性、名称(英文),其中,将属性的id、对应的值的内容存为一个dict键值对
可以通过在浏览器输入一个api,将返回的json放到网上的json解析工具里去解析,查看具体格式,这里就不展开讲了
4.wiki data实体搜索demo
from threading import Thread
import urllib.request
import json
from tqdm import tqdm
import re
from queue import Queue
import csv
querryID_Quene = Queue() # 获取需要根据title拿到wiki的查询str
querryEntity_Quene = Queue() # 请求id,若已知id,则提前加进来
finalResult_Quene = Queue() # 最终结果
# 1.将需要查询的title存进querryID_Quene中,这一步需要大家自己实现
# 我这里存入querryID_Quene的内容为:
# querryID_Quene.put([asin, title])
# 其中asin是查询title在亚马逊商品数据中的商品id,title为商品名称
# 2.多线程爬取,获得对应的ID
def id_spider(in_Quene:Queue, out_Quene:Queue):
while in_Quene.empty() is not True:
asin, text = in_Quene.get()
wiki_id = get_wiki_entity_id_by_str(text)
if wiki_id != 'unknown':
out_Quene.put([asin, wiki_id])
print(asin, wiki_id)
in_Quene.task_done()
n = 100 # 开n个线程
print('start id_spider*{}'.format(n))
for index in range(n):
thread = Thread(target=id_spider, args=(querryID_Quene, querryEntity_Quene, ))
thread.daemon = True
thread.start()
querryID_Quene.join() # 结束
print('get id info*{}'.format(querryEntity_Quene.qsize()))
print('done.')
# 3.正式爬取实体及属性信息
def entity_spider(in_Quene:Queue, out_Quene:Queue):
while in_Quene.empty() is not True:
asin, wiki_id = in_Quene.get()
entity_id, en_title, property_dict = get_wiki_entity_by_id(wiki_id)
if en_title != 'unknown':
out_Quene.put([asin, en_title, entity_id, property_dict])
print(asin, en_title)
in_Quene.task_done()
n = 100 # 开n个线程
print('start entity_spider*{}'.format(n))
for index in range(n):
thread = Thread(target=entity_spider, args=(querryEntity_Quene, finalResult_Quene, ))
thread.daemon = True
thread.start()
querryEntity_Quene.join()
print('get entity info*{}'.format(finalResult_Quene.qsize()))
print('done.')
# 4.写入结果
entity_csvf = open("oneJumpExteriorKG.csv","w",encoding="utf-8",newline="")
entity_csvf_writer = csv.writer(entity_csvf)
headers = ['asin', 'wiki_id', 'entity_title', 'entity_property']
entity_csvf_writer.writerow(headers)
while finalResult_Quene.empty() is not True:
asin, en_title, entity_id, property_dict = finalResult_Quene.get()
entity_csvf_writer.writerow([asin, en_title, entity_id, property_dict])
finalResult_Quene.task_done()
finalResult_Quene.join() # 结束
print('done.')
写在后面
这次用到了多线程进行数据的爬取,速度明显提了上来,实现起来简单,但肯定不能满足百万级别的快速爬虫,这种一般需要一个ip池(防止ip被ban),并结合redis、mongodb等技术进行爬取
之前和舍友一起合作爬过新浪微博,当时参考的这个大神写的WeiboSpider,大家如果有兴趣可以看看 (Gitchat备份)微博爬虫,单机每日千万级的数据_nghuyong的博客-CSDN博客WeiboSpider: This is a sina weibo spider built by scrapy [微博爬虫/持续维护] (github.com)
