PCA(一)
文章目录
- 一、知识点
-
- 1.1 概念理解
- 1.2 常见降维算法
- 二、PCA(Principal Component Analysis)降维
-
- 2.1 PCA无监督降维技术
- 2.2 PCA算法步骤:
- 2.3 低维空间维数d的选取
- 2.4 PCA降维的准则
- 2.5 降维的优化目标
- 2.6 PCA算法的数学基础
- 三、核PCA
- 四、奇异值分解
- 五、主成分数目分析方法
-
- 5.1 随机
- 5.2 累积变异的百分比
- 5.3 变异的百分比
- 六、LDA一种监督学习的降维技术
-
- 6.1 LDA理解
- 6.2 LDA总结
- 6.3 LDA与PCA的相同点
- 6.4 LDA与PCA的不同点
- 七、奇异值分解(SVD)
-
- 7.1 SVD用于PCA
- 7.2 SVD小结
- 7.3 SVD的应用
- 八、应用
- 有趣的事,Python永远不会缺席
- 培训说明
一、知识点
1.1 概念理解
所谓的降维就是指采用某种映射方法,将原高维空间中的数据点映射到低维度的空间中,即PCA通过线性变换将原始数据变换为一组各维度线性无关的表示,可用于提取数据的主要特征分量,常用于高维数据的降维。在降低维度的过程中,我们想要保留更多的特征,PCA就是经过数学推导,保留最多特征同时降维的方法。
PCA是一个线性方法,由于PCA只是简单对输入数据进行变换,所以它既可以用在分类问题,也可以用在回归问题。非线性的情况可以使用核方法kernelized PCA,但是由于PCA有良好的数学性质、发现转换后特征空间的速度、以及再原始和变换后特征间相互转换的能力,在降维或者说特征抽取时,它已经可以满足大部分情况。
给定原始空间,PCA会找到一个到更低维度空间的线性映射。因为需要使所有样本的投影尽可能分开,则需要最大化投影点的方差。
具有如下性质
1.保留方差是最大的
2.最终的重构误差(从变换后回到原始情况)是最小的
降维有两种方法
-
特征消除:将会直接清除那些我们觉得不重要的特征,这会使我们丢失这些特征中的很多信息。
-
特征提取:通过组合现有特征来创建新变量,可以尽量保存特征中存在的信息。
1.2 常见降维算法
- 主成分分析PCA(Principal Component Analysis)
- 线性判别分析LDA(LinearDiscriminantAnalysis)
- 奇异值分解SVD(Singular Value Decomposition)
- 因子分析FA(factor analysis)
- 独立成分分析ICA(Independent Component Correlation Algorithm)
- 局部线性嵌入LLE(Locally Linear Emding)
- 拉普拉斯矩阵Laplacian Eigenmaps
二、PCA(Principal Component Analysis)降维
2.1 PCA无监督降维技术
PCA(主成分分析)就是一种常见的特征提取方法,会将关系紧密的变量变成尽可能少的新变量,使这些新变量是两两不相关的,于是就可以用较少的综合指标分别代表存在于各个变量中的各类信息。
2.2 PCA算法步骤:
1)对所有样本进行中心化操作
2)计算样本的协方差矩阵
3)对协方差矩阵做特征值分解
4)取最大的d个特征值对应的特征向量,构造投影矩阵W
具体PCA操作步骤
1)将原始数据按列组成n行m列矩阵X
2)将X的每一行(代表一个属性字段)进行零均值化,即减去这一行的均值
3)求出协方差矩阵
4)求出协方差矩阵的特征值及对应的特征向量
5)将特征向量按对应特征值大小从上到下按行排列成矩阵,取前k行组成矩阵P
6)Y=PX即为降维到k维后的数据
2.3 低维空间维数d的选取
通常低维空间维数d的选取有两种方法:
1)通过交叉验证法选取较好的d
2)从算法原理的角度设置一个阈值,比如t=0.95,然后选取使得下式成立的最小的d值:
Σ(i->d)λi/Σ(i->n)λi>=t,其中λi从大到小排列
2.4 PCA降维的准则
-
最近重构性:重构后的点距离原来的点的误差之和最小
-
最大可分性:样本点在低维空间的投影尽可能分开
2.5 降维的优化目标
降维问题的优化目标:将一组N维向量降为K维(K大于0,小于N),其目标是选择K个单位(模为1)正交基,使得原始数据变换到这组基上后,各字段两两间协方差为0,而字段的方差则尽可能大(在正交的约束下,取最大的K个方差)。
2.6 PCA算法的数学基础
假设我们有M条数据,每个数据有N个特征,被称为样本集X。
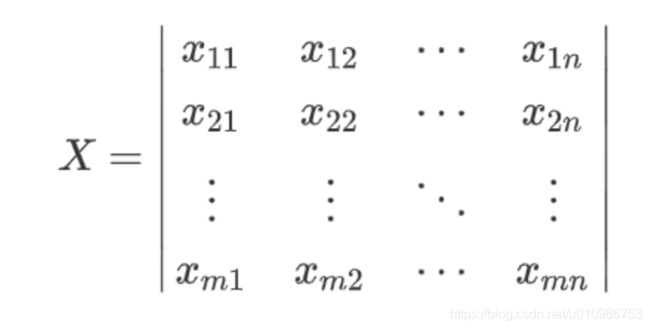
-
对于矩阵X而言,其协方差矩阵为:(协方差矩阵的计算方法可以自行查阅资料,在此不作赘述)
-
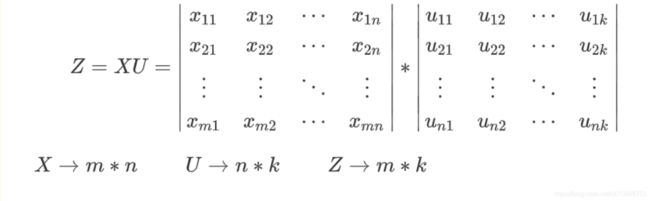
特征矩阵X中可能存在很多冗余的信息,那么现在我们将其映射到另外一个特征空间中,得到矩阵Z
Z的协方差矩阵为D。 -
可以发现Z的协方差矩阵也为一个对角矩阵,对角线的值是方差,其余值是协方差,为0,代表向量正交。
-
我们将特征空间转换的过程写作Z = XU,代入矩阵D,可知:
也就是说 U = Q 。
U 就是矩阵 C 特征向量所组成的矩阵。
矩阵 D 对角线上每个值就是矩阵 C 的特征值。
三、核PCA
针对非线性数据集进行降维。核类别有:线性、多项式、sigmoid、余弦值、预先计算的、RBF。
PCA: Principle Component Analysis, PCA 主成分分析,计算代价高昂,只适用于特征向量间
(1)存在线性相关的环境下。
(2)将数据集中心化;
(3)找出数据集的相关矩阵和单位标准偏差值;
(4)将相关矩阵分解成它的特征向量和值;
(5)基于降序的特征值选择Top-N特征向量;
(6)投射输入的特征向量矩阵到一个新空间。
四、奇异值分解
奇异值分解:Singular Value Decomposition, SVD, 与PCA不同,直接作用于原始数据矩阵。SVD把mn矩阵分解成三个矩阵的乘积:A = USV^T 。
(1)U:左奇异矩阵,mk矩阵。
(2)V:右奇异矩阵,nk矩阵。
(3)S:该矩阵的对角线值为奇异值,kk矩阵。
五、主成分数目分析方法
5.1 随机
-
我们只需要选择一个合适的特征数目即可。
-
这种方法高度依赖于数据集本身的特征以及我们想要分析的内容是什么
-
例如在二维平面内将多维数据进行可视化是非常有用的。
-
那么我们只需要将多维的数据逐渐缩小,直至成为二维数据为止。
5.2 累积变异的百分比
-
我们通过计算每个成分因子能够解释原始数据变异的百分比。
-
然后将不同成分因子所能解释的变异百分比相加。
-
我们就得到了一个值,被称之为累积变异百分比。
-
在PCA的过程中,我们将选择能使得这个值最接近于1的维度个数。
-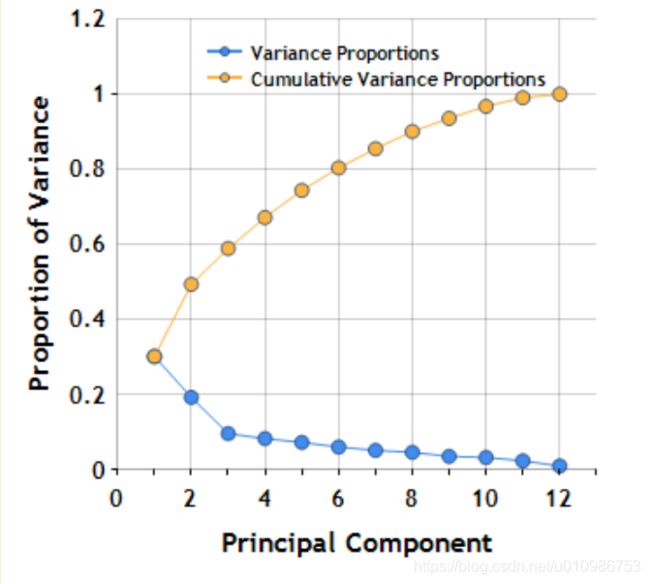
显然可以看出,随着成分数目的增加,累积变异百分比逐渐增加。
当我们需要累积变异百分比大于0.8时,我们至少需要6个主成分因子。
通常不建议使得累积百分比等于1,这将会导致有些主成分带来冗余信息。
5.3 变异的百分比
-
我们通过计算每个成分因子能够解释原始数据变异的百分比。
-
如上图所示,我们也可以选择三个成分。
-
因为当我们增加第四个主成分因子时,会发现其变异的百分比很小。
-
而且增加它对于累积变异的百分比没有太大的影响。只有略微的增加。
-
如果我们把 D 中的特征值按照从大到小,将特征向量从左到右进行排序。
-
然后取其中前 k 个,经过转换(Z = XU),就得到了我们降维之后的数据矩阵 Z
-
这样我们就成功的把N维数据降低到了K维
LDA一种监督学习的降维技术
六、LDA一种监督学习的降维技术
6.1 LDA理解
(1)LDA线性判别分析也是一种经典的降维方法,LDA是一种监督学习的降维技术,也就是说它的数据集的每个样本是有类别输出的。
(2)这点和PCA不同。PCA是不考虑样本类别输出的无监督降维技术。LDA的思想可以用一句话概括,就是“投影后类内方差最小,类间方差最大”。要将数据在低维度上进行投影,投影后希望每一种类别数据的投影点尽可能的接近,而不同类别的数据的类别中心之间的距离尽可能的大。
(3)例子:假设我们有两类数据分别为红色和蓝色,如下图所示,这些数据特征是二维的,我们希望将这些数据投影到一维的一条直线,让每一种类别数据的投影点尽可能的接近,而红色和蓝色数据中心之间的距离尽可能的大。
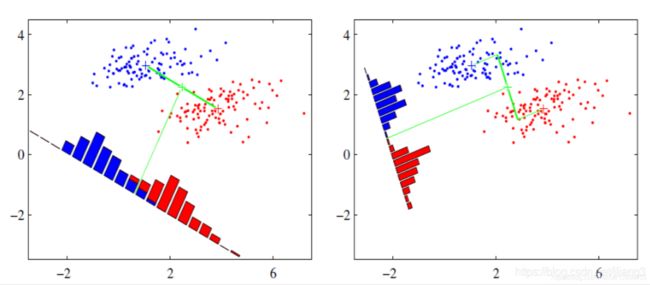
另外一种判断的方式是:通过最小化原数据和投影后的数据之间的均方误差。
(4)LDA除了可以用于降维以外,还可以用于分类。
- 一个常见的LDA分类基本思想是假设各个类别的样本数据符合高斯分布,这样利用LDA进行投影后,可以利用极大似然估计计算各个类别投影数据的均值和方差,进而得到该类别高斯分布的概率密度函数。
- 当一个新的样本到来后,我们可以将它投影,然后将投影后的样本特征分别代入各个类别的高斯分布概率密度函数,计算它属于这个类别的概率,最大的概率对应的类别即为预测类别。
6.2 LDA总结
(1)LDA算法既可以用来降维,又可以用来分类,但主要还是用于降维。在进行图像识别相关的数据分析时,LDA是一个有力的工具。
(2)LDA的中心思想是最大化类间间隔和最小化类内距离。
(3)LDA对数据做了一些很强的假设,尽管这些假设在实际中并不一定完全满足,但LDA已被证明是非常有效的一种降维方法。主要是因为线性模型对噪声的鲁棒性比较好,当表达能力有局限性,可以通过引入核函数扩展LDA以处理分布较为复杂的数据。
- 每个类数据都是高斯分布
- 各个类的协方差相等
(4)LDA的优点
-
在降维过程中可以使用类别的先验知识,而不像PCA这样的无监督学习则无法使用类别先验知识。
-
LDA在样本分类信息依赖均值而不是方差的时候,比PCA之类的算法较优。
(5)LDA的缺点
-
LDA不适合对非高斯分布样本进行降维,PCA也有这个问题。
-
LDA降维最多降到类别数k-1的维数,如果降维的维度大于k-1,则不能使用LDA。当然有一些LDA的进化版算法可以绕开这个问题。
-
LDA在样本分类信息依赖方差而不是均值的时候,降维效果不好。
-
LDA可能过拟合数据。
6.3 LDA与PCA的相同点
(1)两者均可以对数据进行降维。
(2)两者在降维时均使用了矩阵特征分解的思想。
(3)两者都假设数据符合高斯分布。
6.4 LDA与PCA的不同点
- 投影方向不同
- PCA选择的是投影后方差最大的方向。PCA假设方差越大,信息量越多,用主要成分来表示原始数据可以去除冗余的维度,达到降维。
- LDA选择的是投影后类内方差小、类间方差大的方向。其用到了类别标签信息,为了找到数据中具有判别性的维度,使得原始数据在这些方向上投影后,不同类别尽可能区分开。
- LDA是有监督降维方法,而PCA是无监督的降维方法。
- LDA降维最多降到k-1的维数(k为类别数),而PCA没有这个限制。
- LDA除了用于降维还可以用于分类,PCA只能用于降维。
七、奇异值分解(SVD)
奇异值分解(Singular Value Decomposition,以下简称SVD)是在机器学习领域广泛应用的算法,它不光可以用于降维算法中的特征分解,还可以用于推荐系统,以及自然语言处理等领域。是很多机器学习算法的基石。
7.1 SVD用于PCA
在主成分分析(PCA)原理总结中,我们讲到要用PCA降维,需要找到样本协方差矩阵的最大的d个特征向量,然后用这最大的d个特征向量张成的矩阵来做低维投影降维。可以看出,在这个过程中需要先求出协方差矩阵,当样本数多样本特征数也多的时候,这个计算量是很大的。
SVD也可以得到协方差矩阵最大的d个特征向量张成的矩阵,但是SVD有个好处,有一些SVD的实现算法可以不先求出协方差矩阵,也能求出我们的右奇异矩阵。也就是说,我们的PCA算法可以不用做特征分解,而是做SVD来完成。这个方法在样本量很大的时候很有效。实际上,scikit-learn的PCA算法的背后真正的实现就是用的SVD,而不是我们我们认为的暴力特征分解。
另一方面,注意到PCA仅仅使用了我们SVD的右奇异矩阵,没有使用左奇异矩阵。
7.2 SVD小结
SVD也是对矩阵进行分解,但是和特征分解不同,SVD并不要求要分解的矩阵为方阵。
SVD作为一个很基本的算法,在很多机器学习算法中都有它的身影,特别是在现在的大数据时代,由于SVD可以实现并行化,因此更是大展身手。SVD的原理不难,只要有基本的线性代数知识就可以理解,实现也很简单因此值得仔细的研究。当然,SVD的缺点是分解出的矩阵解释性往往不强,有点黑盒子的味道,不过这不影响它的使用。
7.3 SVD的应用
利用SVD降维实际上是用来简化数据,使用了奇异值分解以后仅需保留着三个比较小的矩阵,就能表示原矩阵,不仅节省存储量,在计算的时候更是减少了计算量。SVD在信息检索(隐性语义索引)、图像压缩、推荐系统等等领域中都有应用。
numpy中调用方式和求特征值特征向量类似(实际上特征分解是一种特殊的奇异值分解,<特征分解只能分解方阵,奇异值分解可以分解任意矩阵,pca中的特征分解通常会使用svd)
import numpy as np
U,Sigma,VT = np.linalg.svd(matrix)
八、应用
在语音识别中应用例子
想从一段音频中提取出人的语音信号,这时可以使用PCA先进行降维,过滤掉一些固定频率(方差较小)的背景噪声。
想要从这段音频中区分出声音属于哪个人,那么应该使用LDA对数据进行降维,使每个人的语音信号具有区分性。
在人脸识别领域应用例子
PCA的人脸识别方法(也称特征脸方法)将人脸图像按行展开成一个高纬向量,对多个人脸特征的协方差矩阵做特征值分解,其中最大特征值对应的特征向量具有与人脸相似的形状。PCA降维一般情况下保留的是最佳描述特征(主成分),而分类特征。 想要达到更好的人脸识别效果,应该使用LDA方法对数据集进行降维,使得不同人脸在投影后的特征具有一定区分性。
小婷儿的Python https://blog.csdn.net/u010986753
有趣的事,Python永远不会缺席
欢迎关注小婷儿的博客
文章内容来源于小婷儿的学习笔记,部分整理自网络,若有侵权或不当之处还请谅解
如需转发,请注明出处:小婷儿的博客python https://www.cnblogs.com/xxtalhr/
博客园 https://www.cnblogs.com/xxtalhr/
CSDN https://blog.csdn.net/u010986753
有问题请在博客下留言或加作者:
微信:tinghai87605025 联系我加微信群
QQ :87605025
python QQ交流群:py_data 483766429

培训说明
OCP培训说明连接 https://mp.weixin.qq.com/s/2cymJ4xiBPtTaHu16HkiuA
OCM培训说明连接 https://mp.weixin.qq.com/s/7-R6Cz8RcJKduVv6YlAxJA
小婷儿的python正在成长中,其中还有很多不足之处,随着学习和工作的深入,会对以往的博客内容逐步改进和完善哒。重要的事多说几遍。。。。。。