论文笔记 EMNLP 2019|Cross-lingual Structure Transfer for Relation and Event Extraction
文章目录
-
- 1 简介
-
- 1.1 动机
- 1.2 创新
- 2 方法
-
- 2.1 树结构的表示
- 2.2 GCN编码
- 2.3 在关系抽取中的应用
- 2.4 在事件论元角色标注的应用
- 3 实验
- 4 总结
1 简介
论文题目:Cross-lingual Structure Transfer for Relation and Event Extraction
论文来源:EMNLP 2019
论文链接:https://aclanthology.org/D19-1030.pdf
1.1 动机
- 公开可得到的关系和事件抽取的标注仅存在在少量语言,可能导致缺少部分信息(如构建某人的知识图).
- 最近的研究发现,关系的事实通常由语言内的可识别模式表示,表明跨语言观察到的模式一致性可用于改进关系提取.
1.2 创新
- 构建了一个新的跨语言结构迁移学习框架,将源语言训练数据和目标语言测试数据投射到公共的语义空间.可以在源语言标注数据上训练关系和事件抽取器,然后应用到目标语言文本上.
- 将文本数据转换为源自通用依赖解析的结构化表示,并通过分布信息增强,以捕获单个实体以及涉及这些实体的关系和事件
2 方法
跨语言结构迁移方法总共包含四部分(如下图):
- 基于通用的依赖解析,将各种语言的每个句子转换为语言通用的树结构.
- 对树结构的每个结点,通过拼接多语言的词编码,通用语言的POS编码,依赖角色编码,实体类型编码,创建结点的表达.所有的句子独立于它们的语言,被表示在共享的语义空间中.
- 使用GCN,利用从依赖解析树的邻居信息来生成上下文化的词表示.
- 使用共享的语义空间,在高资源的语言训练数据上训练关系和事件论元抽取器,应用抽取器到低资源的语言中

2.1 树结构的表示
在树结构中,例如动词-主体关系,动词-客体关系,可以在跨语言中发现.使用依赖树作为句子的表示,因为存在83种语言的通用语言依赖解析资源.定义一个句子的基于依赖的树表达为 G = ( V , E ) G=(V,E) G=(V,E),其中 V = { v 1 , v 2 , . . . , v N } V=\{v_1,v_2,...,v_N\} V={v1,v2,...,vN}是词表, E = { e 1 , e 2 , . . . , e M } E=\{e_1,e_2,...,e_M\} E={e1,e2,...,eM}是通用语言的句法关系.N为句子中词的数量,M为单词之间的依赖关系的数量.为了使这种树表示语言通用,首先将树的结点转换为向量,拼接三种词级别的通用语言的表示:多语言的词编码,POS编码,依赖角色编码,实体类型编码.
2.2 GCN编码
对于关系抽取和事件论元角色标注,结构的信息是重要的,通过依赖树中每个结点的邻居生成上下文词表达.一个有N个token句子的依赖解析转换为 N × N N{\times}N N×N的邻接矩阵A,对每个结点添加自连接的边帮助捕捉当前结点自身的信息. A i , j A_{i,j} Ai,j表示结点i和结点j在依赖树中存在一条有向边.最初,每个结点包含第i个单词的分布信息,包括词编码 x i w x_i^w xiw,句法信息编码包括POS标签 x i p x_i^p xip,依赖关系 x i d x_i^d xid和实体类型 x i e x_i^e xie, h i 0 h_i^0 hi0的初始化表示如下:

在第k层的卷积,隐藏表示来自第k-1层的邻居,第i个结点在第k层的隐藏表示如下:
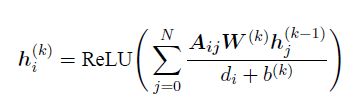
其中 d i d_i di代表第i个结点的度,分母表示用于中和结点度的负面影响的归一化因子.第k层后每个节点的最终隐藏表示是语言通用公共空间中每个单词 h i ( k ) h_i^{(k)} hi(k)的编码,在依赖树中合并最多k跳的邻居的信息。
2.3 在关系抽取中的应用
GCN生成最终的隐藏表示 h i ( k ) h_i^{(k)} hi(k),对这些最终的结点表示使用max-pooling得到句子的向量表示 h s h^s hs.使用以下方法获取句子中每个提及对的关系类型分类结果:
- 对表示实体提及的节点的最终表示进行最大池化,得到所考虑的成对中每个提及的单个向量表示 h m 1 , h m 2 h^{m_1},h^{m_2} hm1,hm2
- 合并三个max-pooling的结果 ( [ h m 1 ; h s ; h m 2 ] ) ([h^{m_1};h^s;h^{m_2}]) ([hm1;hs;hm2]),结合上下文句子信息和实体提及信息
- 使用一个线性层生成这些合并结果的连续表示
- 使用Softmax进行关系类型分类
损失函数如下:

2.4 在事件论元角色标注的应用
事件论元角色标签将参数与非参数区分开来,并按论元角色对论元进行分类。为了事件触发词 x i t x_i^t xit标记候补论元 x j a x_j^a xja的角色,首先通过max-pooling操作,生成句子表示 h s h^s hs,候补论元表示 h a h^a ha和触发词表示 h t h^t ht,从潜在空间到参数角色的映射函数,由拼接 ( [ h t ; h s ; h a ] ) ([h^t;h^s;h^a]) ([ht;hs;ha]),线性层(U^a)和Softmax组成,损失函数如下,其中N为事件提及的数量, L i L_i Li是第i个事件提及的候补论元的数量.

3 实验
实验数据使用ACE 2005,它包括三种不同语言(英语,汉语,阿拉伯语)的关系和事件注解,目标包括定义在ACE种的7种实体类型,18种关系子类型和33种事件子类型,下采样负训练实例通过限制每个文档的负样本的数量不超过正样本的数量.使用Stanford CoreNLP toolkit进行中文分词和英文tokenization,使用UDPipe进行阿拉伯语tokenization.使用UDPipe对三种语言进行词性标记和依存句法分析.使用下面标准进行评测:
- 如果一个关系提及的关系类型,两个相关的实体提及论元的头偏置是正确的,则这个关系提及是正确的.
- 一个事件论元的事件类型,偏置,角色标签与任意一个参考论元提及匹配,则这个事件论元标注正确.
使用fastText从Wikipedia学习的基于对齐单语嵌入的多语言单词嵌入,使用通用的词性标记(17个类别)和37个Universal Dependencies定义的依赖关系类别,7个ACE定义的实体类型:人物,地理政治实体,组织,设施,位置,武器和交通.
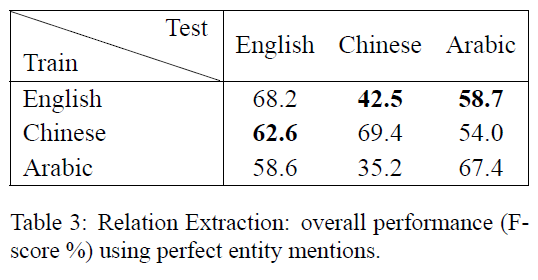
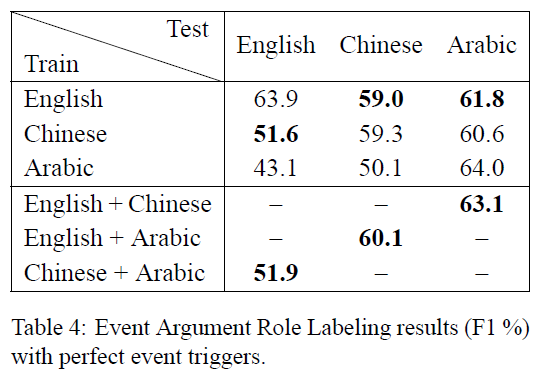
通过使用这三种语言的不同组合当作训练和测试数据,以训练的模型来评估其性能,实验结果如下
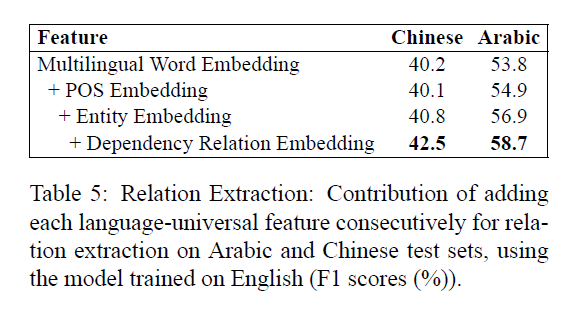
进行消融实验以展示每个特征对实验结果的影响,结果如下图:

比较使用人工标注的相同语言数据训练的监督单语言模型,结果如下:
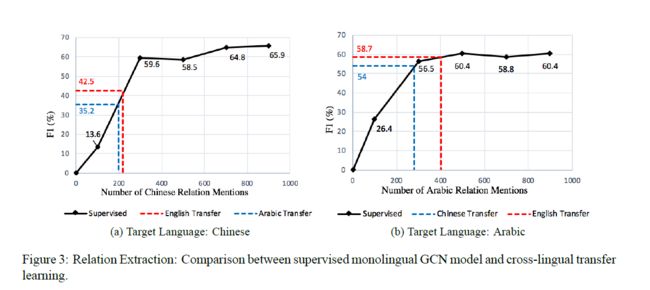

4 总结
- 展示了跨语言关系和事件论元的结构表示是如何在没有任何目标语言训练数据的情况下在语言之间传递
- 得出结论:语言的通用特征和分布表示对于跨语言结构迁移是互补的。