【杂谈】概率与随机以及手游抽卡机制的科普
原文:NGA的一篇随机科普,其中包含了对手游抽卡机制的探讨。本文摘选了我自己感兴趣的部分。
真随机
先说点题外话,请先看这个问题
一杯热水和一杯冷牛奶哪个热量更高?
很显然这个问题从物理学和营养学的层面会得出相反的答案,( 先不考虑物理学层面说“一杯热水的热量”实际上是错误的 ),而关于“随机”的问题上的大部分疑惑与争论都恰如这个问题一般:
扔硬币算不算真随机?
计算机是否只能生成伪随机?
伪随机是不是就一定能找到规律?
想要解决这些问题,就必须从两个层面去理解“随机”,接着看下面两句话:
1.让我们丢硬币/骰子(或其他机制)来随机生成一串数字吧
2.这一串数字是随机的
我们往往认为第一句是第二句的必要前提,第二句是第一句的必然结果,而实际上它们分别代表了随机的两个不同层面的特征:
1.不可预测
2.不可压缩
一、不可预测——“原理”层面的随机
我们为什么要使用硬币或者骰子去决定一件事情?其本质在于我们要的是一个不可预测的结果,自然有人会说,只要准确测量掷出角度速度以及引力空气阻力等等参数,硬币的正反是完全可以预测的。然而,这真的是“预测”吗?
试想几种情况:
硬币直接平拍在地上——正面
硬币弹跳了几下落在地上——正面
硬币斜着滚了几圈后倒下——正面
……
这实际上完全不是同一个状态,这里所谓的“正面”与其说是“预测”更接近“归纳”。试想我们做一枚2亿面的骰子,一半的面标记为正,另一半为反,那么在理想情况下它和硬币在“掷出去获取正反两种结果”这件事上是完全等价的(可以互相代替且都不能做得比对方更多),现在你就很难再准确预测它的结果了。你说你可以提升测量精度,于是我又掏出了20亿面骰子、200亿面骰子,直到让你的测量精度需求撞上一堵叹息之墙——“普朗克尺度“。
1.注:量子力学与随机
- 有相当多的人觉得“量子力学是玄学”,诚然“不确定性”和“波粒二象性”等等概念实在不像经典物理学所描绘的图景那么容易理解,然而非常讽刺的是,经典力学的大厦不是被量子力学推倒的,而是被铁一般的实验事实摧毁的,而量子力学恰恰是构建在这些实验事实上的理论,其基本概念并非是新增的,而是在经典力学里面砍掉诸如“刚体”、“瞬时作用”、“无穷远处”等等我们做题时候习以为常但是在理论层面却极其臃肿丑陋的假设后提炼出来的。量子力学中带有概率的描述反而是当代物理学中对于客观现实最精确的描述,远远超过经典力学。
- 关于“量子不确定性原理”最简单的理解就是“
对于一个物体位置和动量的测量(描述并预测物体运动所必须的条件),两者的不确定性之积必然大于等于普朗克常数除以4π”,很多人会觉得这仿佛是造物主设下的限制一般,然而正如我前面所讲,这一概念也是建立在一个非常朴素的实验事实上:“我们的测量过程必然存在微观粒子的相互作用”。举个例子:你拿皮尺量腰围,想要精确测量就必然要把皮尺收紧,这实际上就极微小的改变了腰围,而“恰好搭在腰上不产生压力”,不管在==(现代物理的)理论上还是在现实中==都是做不到的,因为构成人体和皮尺的微观粒子还存在永不停息的热运动,最终造成了不管在理论还是实验层面都无法避免的不确定性。 - “普朗克尺度”也是一个经常被误用的概念,很多人把他理解成一个“bit”性质的“最小单位”,而实际上它只是一个范围而非单位,其物理意义也是基于一个客观事实上——“
想取得更准确的测量结果就需要使用波长更短的基本粒子去和被测量物产生相互作用”(这也是为什么微观领域可见光显微镜不行了需要上电子显微镜的原因),而波长越短,单个粒子的能量就越高,根据相对论它的质量也会越高,最终会导致其史瓦西半径大于康普顿波长,从而成为一个黑洞,同时我们也就失去了该粒子的一切信息——测量失败。(这里的概念如果难以理解的话其实可以不管的,因为想真正理解这些概念还需要量纲相关的知识,非专业领域实在没有了解的必要。)
总结来说,就是预测的精度无法无限制地往上提升,最终总是会以概率的形式呈现(这在前些天和小丁同学讨论完事万物是不是可以预测测时候也提到过)
我们可以更简单直接一点,直接用微观粒子来做骰子,这样“不确定性原理”就可以保证结果从理论上永远无法准确预测。
你或许会说,技术上测量精度应该是领先加工精度的,也就是你有做多少面骰子的技术我就应该有那个精度的测量能力,所以依然是可以预测结果的,然而,在叹息之墙前面还有一道名为“混沌(注二)”的冥界之河。
2.注:混沌和随机
-
简单来说就是:我们实际上并不需要2亿面的骰子,只需要拿3枚硬币放在一个盒子里摇上10秒钟,准确预测结果所需的测量精度和计算量就已经爆炸级的增长了,只要继续增加硬币数量和摇晃的时长,预测所需的计算能力很快就会达到即使把可观测宇宙中的所有物质都转化成运算资源也不够的程度。
-
小时候在电视上看到过彩票开奖,在一个装置里摇球。只要摇奖的时间足够长,不管你把某一次摇奖的参数测量的多么准确,都无法用这些参数去准确重演结果,甚至一次摇奖对奖球造成的分子尺度的磨损都会影响下一次的摇奖结果,所以进行准确预测或控制也是不可能的。
题外话:彩票舞弊也都是通过视频作假或者伪造出票时间(后者基本上就是现实中所有的彩票舞弊实例,开奖后买,后台修改出票时间为开奖前,尤其是在没有互联网的时代)。
于是综合以上两点,量子力学和混沌动力学在原理层面保证了随机性的诞生,而在实验层面上还有一个影响因素就是“自由意志”,即使你可以预测硬币的结果,但是你把硬币交给别人丢,你没法预测他选择什么时候用什么力度和角度去丢,而“自由意志”在现代已经不是哲学概念这么简单,已经把物理学和数学牵扯进来,这里就不做过多展开了。
二、不可压缩——“结果”层面的随机
首先让我们试想一个场景
有三位朋友A、B、C
A在房间里反复丢一枚硬币并将结果报给房间外面的B
B用1代表正面,0代表反面把结果记录下来,再将其转发给C
下面是B的记录表格:
次数 1 2 3 4 5 6 7 8 9 10 11 12 13 …… 结果 1 0 1 0 1 0 0 0 1 1 0 0 1 …… 如果B想把A丢硬币的结果完整的传输给C,显然他只能把这个表格整个传输过去,无法进行任何压缩以减少传输的数据量。
请务必仔细理解这句话,这是本文出现的第一个需要理解的数学概念——“不可压缩性”——即我们对某一个数列最简短的描述就是这个数列本身。
那什么情况可以压缩呢?
显然如果B从A那里收到的结果是101010101010……这样,他就可以告诉C“奇数次的结果是正面,偶数次的结果是反面”——这一描述显然要比记录这些结果的数据串要短得多,这就是一种压缩。
此时我们可以给数列是否“随机”定下一个判断标准:
我们说一个数列是“随机的”,当且仅当该数列是“不可压缩的”,反之亦然。
这里一定要分清楚“不可压缩”和“没有规律”的区别,比如掷理想硬币生成的数列,1和0的比值最终应该是1:1,这也是一种“规律”(不可压缩也满足这个规律),但是和“奇数位是1偶数位是0”这样的规律不同,无法“基于这一规律使对数列的完整描述变短”,仍然还是“只能用数列本身来完整描述”,这是这部分最容易混淆的概念,一定要想明白。
就是对”规律”这个词理解,注意一下就行。
这一判断方式并不需要参考这一数列是如何产生的,这一点在本文接下来的部分也很重要。
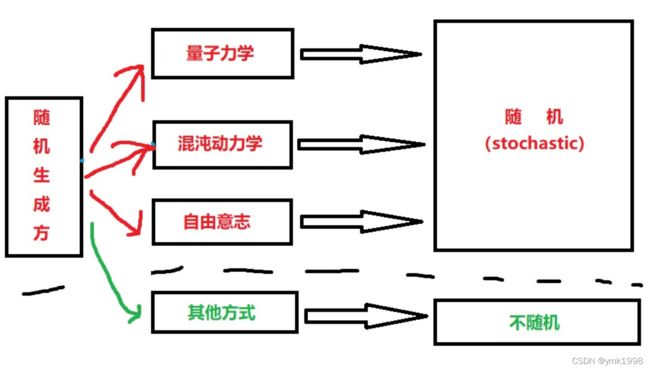

可以看到图中出现了两个新的英文单词stochastic和random,此处这两个单词的使用是根据默里·盖尔曼的建议,分别描述随机过程(stochastic process)和随机结果(random variable),也就是对应上文的两个层面,但需要注意的是这仅仅是为了方便理解的划分,这两个词在专业领域往往有更严谨的定义,不要拿这张图当成严谨定义
总之,这一部分就是讲述“真随机”的判断条件——虽然文中我用只用了“随机”这个词,但实际上所谓“随机”就是指“真随机”,而“伪随机”是要归入“不随机”中的,具体请看下一部分。
伪随机
什么是伪随机?
用非stochastic的方式去生成random的尝试
依然用上面的例子
A、B、C又一次在进行掷硬币的游戏,B正准备把根据A告诉他的结果制作的如下表格逐个数字发给C:
次数 1 2 3 4 5 6 7 8 9 10 11 12 13 …… 结果 1 0 1 1 1 0 0 1 1 1 0 1 1 …… 就在这时,他们的朋友“大聪明”前来拜访,他看了一眼B记录的表格说:“不用记了,接下来13位是1101000000110。”随后A报出来的13次结果果然是“正正反正反反反反反反正正反”。
B非常惊讶,不知道“大聪明”是怎么猜到的,“大聪明”诶嘿一笑,画出了如下的表格:
?? 1 4 1 5 9 2 6 5 3 5 8 9 7 …… 结果 1 0 1 1 1 0 0 1 1 1 0 1 1 …… 相信大家应该看出来“ ??”代表什么了,原来,A根本没有投掷硬币,而是用π小数点后每一位的奇偶性来生成结果并报给B的,那么问题来了:
显然在“大聪明”眼里A投掷硬币的表格是可压缩的(红色就是压缩),显然不是随机(random),但是在Bob眼里却是不可压缩的,符合随机(random)的定义,那么这到底算不算随机(random)呢?
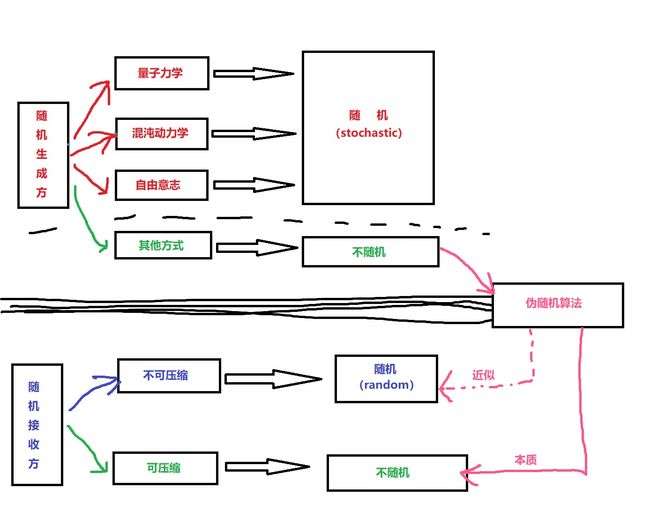
由此我们可以得出伪随机(pseudo random)的定义:
用非随机过程(non-stochastic process)生成
近似于随机结果(random variable)的尝试称之为伪随机(pseudo random)。
如何实现伪随机
伪随机是用随机算法(randomized algorithm)生成的,比如上文中的“根据π小数点后每一位数的奇偶性生成1或0”就是一种伪随机算法,这并不是一种很好的算法,首先他生成的数列实际上是固定的,无法在实际应用中重复使用,并且还会被Dave这样的人破解。而且它无法应付巨量的伪随机数需求,比如这一次应用取了几百万位,下一次再取几百万位,很快存储器中的π值小数点后的位数就不够用了,只能一边算一边生成,导致所需的存储空间越来越大。
一个优秀的、可实际应用的伪随机算法通常至少要满足两个条件:
- 可以生成有明显不同的无数组数列;
- 可以用有限的运算能力和存储空间生成任意长的数列。我们通常使用一种非常简单精妙的方式来解决这个问题——迭代(iteration)。
例子:
比如今天是11月25日,我们取1125这个数字,将它进行平方运算,得到1265625,将其前面补一个0凑成八位数01265625,取中间四位2656再平方得到7054336,补足八位取中间四位0543再平方……每进行一次“平方取中”操作就称为一次迭代,不断进行下去可以生成如下表格:
迭代次数 0 1 2 3 4 5 6 7 8 9 10 11 12 …… 取值结果 1125 2656 0543 2948 6907 7066 9283 1740 0276 0761 5791 5356 6867 1556 看起来非常完美是不是,因为“平方取中”操作的“取中(包括补位)”看起来是一个带有主观性质的操作,生成的数列似乎和真随机(random)没什么两样。
然而,50次迭代之后,取到了4100这个值,接下来的迭代会出现“4100、8100、6100、2100、4100、8100……”这样周期仅为4的循环,这样的伪随机算法显然也不能满足实际需要。
实际上,上面那个最终看起来似乎很愚蠢的算法是冯·诺依曼发明的,可见构造一个优秀的伪随机算法是多么困难的事情。之后的线性同余发生器(LCG, Linear Congruential random number Generator)虽然速度极快且周期够大(2^31-1),但是存在很大的缺陷,甚至可以说一直到1997年基于梅森旋转算法(Mersenne twister)的MT19937出现,才有了在实际应用中可以当成真随机(random)来用的伪随机算法。
随机数发生器和随机数表
其实上文中已经多次提到了随机数发生器(RNG,Random Number Generator),硬币、骰子等等包括后来提到的LCG等随机算法都是随机数发生器,显然他们可以分成两类:真随机数发生器(True Random Number Generator)和伪随机数发生器(Pseudo Random Number Generator),而我们使用RNG的根本目的是为了获取随机数表(RNT,Random Number Table),也就是上文中所说的随机数列,在游戏领域的话我们通常称为乱数表,通常我们用这样的表格来呈现:
| 71 | 81 | 20 | 65 | 14 | 30 | 10 | 17 | 82 | 95 |
| 20 | 28 | 75 | 68 | 62 | 69 | 72 | 79 | 44 | 43 |
| 5 | 61 | 77 | 58 | 18 | 47 | 75 | 6 | 78 | 14 |
| 28 | 44 | 0 | 78 | 19 | 21 | 58 | 5 | 14 | 59 |
| 98 | 52 | 01 | 77 | 67 | 14 | 90 | 56 | 86 | 7 |
| 22 | 10 | 94 | 5 | 58 | 11 | 80 | 50 | 54 | 31 |
| 39 | 80 | 82 | 77 | 32 | 50 | 72 | 56 | 32 | 48 |
| 91 | 49 | 91 | 45 | 23 | 68 | 47 | 92 | 76 | 86 |
| 3 | 6 | 11 | 80 | 72 | 75 | 56 | 97 | 88 | 0 |
| 75 | 56 | 34 | 87 | 63 | 2 | 76 | 11 | 84 | 20 |
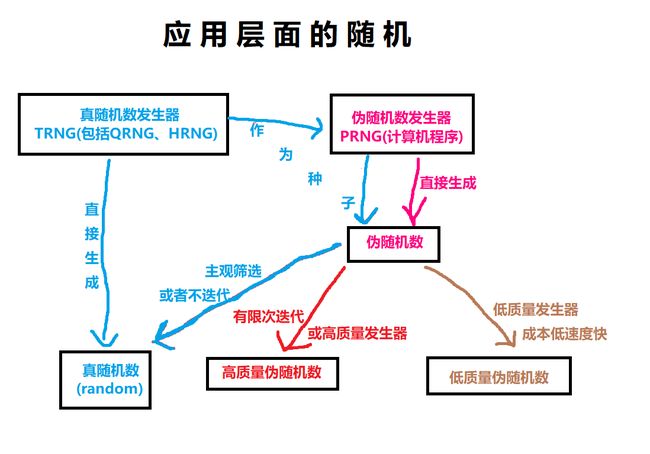
经过上文的介绍,大家应该明白用伪随机数发生器生成这样的表格是很容易的,而真随机数发生器又是怎么生成这样的表格的呢?
1.第一种最简单的方法就是直接生成,比如掷骰子生成的正面反面用1和0来记录的话就可以视为二进制数,选择适当的数字串长度划分就可以生成任意范围的随机数。在科研领域我们一般使用基于“量子骰子”的量子随机数发生器(QRNG,Quantum Random Number Generator),另外值得骄傲的是在这一领域,我国处于世界领先地位。
2.另一种是“观测”性质的生成,比方说观测某一限定空间内的微观运动或宏观混沌系统(如大气温度),然后将结果阈值化,举例来说就是这样:
把50只老鼠放进一个面积约能容纳100只老鼠的扁平且温暖的方盒中,然后不定期进行拍照,在照片上划分10*10的方格,每一格内超过1/2老鼠身体则涂黑,不足1/2则涂白,那么这张照片就可以当成二维码来扫,这样就能生成随机数表了。
随机数表的应用
随机数表在应用层面主要有两大方式:
-
提供判断:
最简单的模式就是比如做一个掷硬币的模拟游戏:
1.依次在随机数表中取数字。 2.当取值在1~50之间时输出“正面”。 3.当取值在51~100之间时输出“反面”。于是根据随机数表中的“71、81、20、65、14……”该程序就生成了“反面、反面、正面、反面、正面……”这样的结果。
实际应用中的取值要更复杂一些,比如很多游戏中的“武器强化系统”:+1的成功率是70%、+2降低到60%、+3是50%这样很常见的设定是如何实现的呢?我们可以写这样的程序:1.在随机数表中依次取值。 2.判断武器的状态。 3.当武器为+0的时候,取值在1~30之间判定为“失败”,在31~100之间判定为“成功”。 3.当武器为+1的时候,取值在1~40之间判定为“失败”,在41~100之间判定为“成功”。 3.当武器为+2的时候,取值在1~50之间判定为“失败”,在51~100之间判定为“成功”。 -
随机排序:
我们在实际应用中经常会遇到把若干个元素随机排序的需求,如果使用数学方式(随机数表属于数学范畴)实现的话也被称为洗牌算法(shuffle algorithm)。
假设我们要将100个数的顺序打乱,显然直接用上面的随机数表当序号是不行的,因为有重复的数字,而在随机数发生器中加入剔除相同数值的机制的话又会严重影响效率(因为每生成一个数都要和之前所有数进行“逐一比对”,在数据量很大的时候运算量过高),我们可以用这样的程序去实现“洗牌”:1.将需要排序的N个数按输入的顺序排列好。 2.选择第N个数字,并在数值总量大于N的随机数表中取值,设所取值为M,则将第N个数字和第M个数字位置对调,若M大于N,则用M除以N并“取余数再加1”作为M再进行操作。 3.选择第N-1个数字,在随机数表中取下一个数作为M进行同“步骤2”的操作。 4.持续操作直到对第1个数字进行操作,排序完毕。比如我们对“10、20、30、40”四个数字进行随机排序:
首先操作第4个数字“40”,随机数表第一个值是“71”>数列长度4,我们用71除以4得到17余3,再+1=4,那么最终得到的M值就是“4”,因为我们选择的已经是第4个数字了,所以不用进行对调。此时数列仍然为“10、20、30、40”
接下来操作第3个数字“30”,随机数表中取值“81”,81除以4得到20余1,再+1=2,M=“2”,于是我们就把第3个数字“30”和第2个数字“20”进行对调。此时数列变成了“10、30、20、40”
接下来选择此时的第2个数字“30”(别忘了我们刚刚在上一步把2换过来了),在随机数表中取值“20”,20除以4得到5余0,再+1=1,M值=“1”,于是我们就把第2个数字“30”和第1个数字“10”进行对调。此时数列变成了“30、10、20、40”
最后选择第1个数字“30”,在随机数表中取值“65”>数列长度4,于是用65除以4得到16余1,再+1=2,M值=“2”,于是我们就把第1个数字“30”和第2个数字“10”进行对调。此时数列变成了“10、30、20、40”,这也就是我们最终的排序结果。
当我们利用计算机生成的随机数表来进行上面的操作的时候,常常会有人这样评价“因为计算机只能生成伪随机”,所以你这个洗牌算法(或者别的机制)不够随机。”这种评价的逻辑是对的么?
计算机只能生成伪随机
经常会听到一句话:计算机只能生成伪随机
然而,相当讽刺的是,如果你带着这句话回到1951年,也就是第一台商用电子计算机Ferranti Mark 1问世的那一年,几乎所有对计算机有所了解的人的反应都会是:
什么?计算机还能生成伪随机的?你别骗人了,计算机只能生成真随机!
在Ferranti Mark 1中,阿兰·图灵设计了一个真随机数发生器(TRNG),原理是采集系统内的电气噪声生成一个20比特的随机数字串,然而这一实打实的真随机却让开发人员非常不满,因为其完全不可控,实际编程应用中对随机数的要求包括可重复性(用于编程调试)和可以在一定范围内进行调整(比如前文提到的LCG就可以通过更改参数来调整周期等)的能力。平方取中过于弱鸡,LCG因为同余运算需要进行大量除法运算,在当时计算机的能力下效率堪忧。于是在那个时代的科研与生产中,最常见的场面就是大家手捧一本巨大的《A Million Random Digits with 100,000 Normal Deviates(百万乱数表)》利用里面的随机数来进行工作,该书是兰德(RAND)公司在1955年利用电脉冲发生器产生的随机数编写的,当年技术人员几乎人手一本,可见对于高质量随机数的需求有多大。
一直到1960年第一个比较可靠的商用伪随机数发生器——IBM公司的RANDU子程序才诞生,但是其依然存在着很大的缺陷(见前文“注八”中的“奥妮酱,卒”,另外学计算机的应该都有印象,好多教材关于伪随机生成器的章节都要把RANDU拉出来当反面教材鞭尸。),并没有完全取代《百万乱数表》。一直到90年代计算机性能的提升和日渐普及的计算机网络对于安全性的极高需求,伪随机数发生器才真正进入了黄金时代。
然而一直到现代,我们的计算机包括智能手机里面,都还有真随机数发生器的存在,主要用于一些对生成速度要求不高但是对于安全性要求极高的场合,比如现代蓝牙芯片中基本都有TRNG,用于配对过程中的通信安全,这一类TRNG又被称为硬件随机数发生器(HRNG,Hardware Random Number Generator)。除了直接生成数据,也有基于“观测”的HRNG,比如1997年的LavaRand,使用摄像头对一个熔岩灯持续拍摄并将图像数字化生成随机数。
综上,这句话应该改成“计算机程序只能生成伪随机”,而广义的“计算机”概念生成真随机是非常自然的事情,且普遍应用于科研和生产的历史几乎和计算机本身的历史一样长。
然而即使是“计算机程序生成的伪随机”,我们在实际应用中利用其获取真随机数也很容易,还是让A和她的朋友们给大家示范一下:
A写了一个小程序:
1.在后台存储中生成一个“1”,0.1秒后切换成“0”,之后每0.1秒持续如此在“1”和“0”之间切换。
2.每当用鼠标点击屏幕的时候,显示此刻后台存储中的结果。
之后Alice随意的点击屏幕,生成了一串“1、1、0、1、0、1、0、0……”这样的数字。
这个程序是伪随机(pseudo random),然而Alice通过真随机(stochastic)选择输出结果,得到的就是真随机(random)的结果,这一方式最常见的应用就是滚动抽奖,就是那种屏幕上持续滚动手机号之类的,然后嘉宾选择何时停止,这些手机号的排序和滚动模式通常都是由伪随机数控制,但是最终抽选则是基于嘉宾的自由意志,当然这种抽奖模式相对于摇奖机来说想要作假还是很容易的,比如每次嘉宾按停止键时显示事先定好的数字(这种方式下通常要把滚动做的极快让人看不清),但这和随机机制本身无关。
B也写了一个小程序:
1.当输入奇数的时候,输出“1”。
2.当输入偶数的时候,输出“0”。
然后Bob持续投掷一枚骰子,将生成的点数如“6、4、1、2、2、4、3、1……”输入程序生成了一串“0、0、1、0、0、0、1、1……”这样的数字。
这个程序显然也是伪随机(pseudo random),然而Bob直接把真随机(stochastic)当作输入值(这一过程中伪随机程序实际上起的作用和“把硬币的正反记为1和0”性质相同的作用,只是一种“转换模式”),得到了真随机(random)的结果。
综上,计算机实现真随机有两种方式:
1.直接使用硬件随机数发生器(HRNG,Hardware Random Number Generator)生成真随机(random)。
2.通过在伪随机数发生器(Pseudo Random Number Generator)中增加真随机(stochastic)因素将其改造成真随机数发生器(True Random Number Generator)。
如何设计一整套随机机制
1.设计或选择一个随机数发生器(RNG,Random Number Generator)——根据实际需要选择真随机数发生器或伪随机数发生器(以及发生器的具体形式)。
2.将==初始值(此处的的“初始值”在编程领域我们通常称之为种子(seed),之后我们要经常用到这个概念)==输入随机数发生器,生成随机数表。——可以使用另外的机制(包括另一个随机数发生器)生成种子,也可以使用另外的机制(包括另一个随机数生成器)对生成的随机数表进行操作(如筛选或排序)。
3.设计随机数表实现应用要求的模式并应用这些模式进行操作得出结果。——如上文中提到的“提供判断”和“随机排序”
例子:
**用户需求:**设计某网络游戏中的抽奖机制,奖品总价值比较低,要求程序层面尽量简单,但又不容易被找出规律,需要能支持较大量用户同时抽奖并获得有差异的结果,并且对于不同价值奖品可以提供方便调整的中奖概率设定,最后就是机制层面的用户体验越高越好。
需求分析:
奖品总价值比较低——不需要太贵的商用随机数发生器了。
程序层面简单——不能用太复杂的算法。
不容易被找出规律——尽量接近真随机(random)。
能支持较大量用户同时抽奖——随机数生成要尽量高速。
获得有差异的结果——同时抽奖的用户结果要尽量不同。
对于不同价值奖品可以提供方便调整的中奖概率设定——在随机数表的应用方式上要提供调整的余地。
机制层面的用户体验越高越好——尽量让用户觉得抽奖结果更取决于自己。
程序设计
随机发生器:
1.使用“平方取中”方式,每次输入一个四位数种子,进行平方运算,结果如不足八位数则在最前面补充0直到形成八位数,将最终生成的八位数的中间四位继续进行前述的“平方取中”方式,此为1次迭代。 2.共进行10次迭代,并输出这10次的结果作为一个随机数表。 3.等待下一次种子的输入,并重复以上步骤。种子获取:
当用户点击抽奖时,抓取当时的服务器时间,取“AB分CD秒”的“ABCD”作为四位数种子输入随机发生器。随机数表使用方式:
1.用户点击抽奖后,用户界面出现10个宝箱,将随机数表中的10次迭代结果依次填入10个宝箱之中。
2.让用户自己点击选择一个宝箱开启。
3.根据宝箱中的的四位随机数值判定中奖结果。
中奖率设定方式1.0000、0100、2100、4100、6100、8100这5个会形成短周期的迭代结果设置为价值最低的奖品或“谢谢惠顾”等。 2.确定最稀有奖品的编号,如只有10个的最高奖,可以设置成“X999”,如“999、3999、9999”才可中奖等。 3.其他奖品可以用区间或倍数的形式再剔除掉大奖编号的方式定义,如“0~5000之间除X999外为末等奖”,“每逢11的倍数为四等奖”等等。
案例点评:
优点:
1.用户最终自己选择宝箱的方式极大程度提高了随机性和用户体验。
2.因为选择宝箱的方式极大的提高了随机性,对随机数发生器的要求就大大降低了,此时即可选择“平方取中”这样的极简方式大大提升效率。
3.随机数表和中奖率的设置简单合理,调整非常容易。
缺点:
1.以“XX分XX秒”作为种子在“平方取中”方式中有很大的弊端,因为有部分用户有在“00分00秒”进行抽奖的个人癖好,此时迭代结果必然全是0,影响用户体验。
2.取服务器时间为种子,大大增加了服务器同时接受的请求量,容易造成服务器压力过大导致宕机。
改进方案:
1.在服务器端设置若干计数器程序,内部以0000~9999循环滚动数字,滚动速度可以对应任何时间间隔如CPU时钟周期等,不必和现实时间周期挂钩。
2.用户发出抽奖请求时,根据用户本地时间、ip地址或网卡mac地址等信息通过一个极简算法(如随便除以一个小质数取余数)分配某一个计数程序为其取当时的数值作为种子。
3.不定期分批重置这些计数程序。

经常被误当成“伪随机”的“随机修正机制”
当你在搜索引擎里面搜索“伪随机”这三个字的时候,通常在前几个结果里面就能看到“war3的伪随机机制”,它的完整描述通常是这样的:
war3(warcraft3,魔兽争霸3)里面的剑圣(blademaster)这个英雄有一个“致命一击(critical strike)”技能,在满级的时候有20%的概率触发并造成4倍于普通攻击的伤害(实际机制要更复杂一点)。
假设剑圣一刀可以造成100点伤害,那么可以计算出每7刀造成的伤害期望就是1120点,也就是敌方英雄血量不足1120,且剑圣可以安全的进行7次攻击的情况下就可以尝试击杀对方英雄了。
然而我们同样可以计算出,连续7次攻击均不发生致命一击的概率高达21%,也就是这种尝试有超过五分之一的概率会失败。与此同时还有另一种情境,比如我方英雄尚有1000点血量,按期望计算敌方剑圣平均需要7次攻击才能击杀,
而当时游戏中的状态是敌方剑圣只能在自身安全的前提下进行4次攻击,此时按理来说可以认为我方英雄是安全的,然而敌方剑圣鲁莽的冲了上来砍了4刀,打出了2次致命一击造成100x2+400x2=1000点伤害将我方英雄直接击杀!
这种情况发生的概率实际上高达18%。或许这样的场面很有观赏性,但是对于一项严谨的电子竞技项目来说,这种情况严重的影响了职业选手的策略判断,可能会使选手的策略偏向保守,从而在深层次上影响比赛的观赏性。
为了在不改动“致命一击发动的概率为20%”的前提下改善这种情况,设计师设计了这样的机制:
设致命一击技能要求的发动概率为P(P=20%)。
在实际进行第1次攻击时给剑圣赋予一个初始概率C以发动致命一击,C100%时直接产生一次致命一击。
当任意一次攻击产生致命一击时,下一次攻击产生致命一击的概率重置为C。
根据设定的C值计算出当攻击次数趋近于无限时,实际致命一击发动的概率P',当P'=P或与P的差在设计允许的范围内时,采用此时的C值作为最终的设定。
最终计算得到的C值为5.57%
我们把这个新机制代入以上的情境进行计算,会发现连续7次攻击不触发致命一击的概率从21%降低到了16%,而4次攻击中至少有2次致命一击的概率从18%下降到了4%(特别要补充的是连续4次全触发致命一击的概率从0.16%下降到了0.001%!)
这一机制被称为PRD:Pseudo Random Distribution,翻译过来就是“伪随机分布”,又常被简称为“伪随机”。
于是,每次在网络上进行随机相关的讨论中,总会出现这样的场景:
场景A:
1.“某游戏的抽卡一定是伪随机,因为计算机只能生成伪随机。”
2.“如果是伪随机”的话,如果咱们一直抽不到五星卡,概率会越来越高。”
场景B:
1.“我从来没连续抽出过两张五星卡,说明这游戏用的一定是伪随机”
2.“那肯定的啊,计算机只能生成伪随机嘛。”
为什么会出现这种误解呢?问题实际上不出在“简称”上,而是在“断句”上,所谓“伪随机分布”不是指“==伪随机==分布”,而是指“**伪**随机分布”,下面我简单的说明一下什么叫“随机分布”:
假设我写如下4个生成只含有“1和0的数字串”的程序:
A:使用TRNG“机械装置持续投掷一枚理想硬币”并记录正反面结果,用1代表正面,0代表反面输出。 B:采集“程序A”输出的结果,然后在其中挑出所有“连续超过五个1”或者“连续超过五个0”的数字串并将其缩短至5位。 C:使用PRNG“梅森旋转算法”持续生成伪随机数,将生成的奇数记为1,偶数记为0输出。 D:采集“程序C”输出的结果,然后在其中挑出所有“连续超过五个1”或者“连续超过五个0”的数字串并将其缩短至5位。之后我们把每个程序输出的结果列出来,并进行分析,这就是所谓的“分布”:
程序A输出的结果是真随机 分布:不存在周期性,每一位都不可预测,可以存在任意长的连续1或者0数字串。
程序B输出的结果是伪随机分布:不存在周期性,每当连续出现五个1之后的下一位必然是0,每当连续出现五个0之后的下一位必然是1,其他位不可预测,只能存在最多连续5位1或者0数字串。
程序C输出的结果是伪随机分布:存在周期性,在不了解所用PRNG算法的情况下在第一个周期内每一位都不可预测,第二个周期开始每一位都可预测,在周期长度限制内可以存在充分长的连续1或者0数字串。
程序D输出的结果是伪随机分布:存在周期性,每当连续出现五个1之后的下一位必然是0,每当连续出现五个0之后的下一位必然是1,其他位在不了解所用PRNG算法的情况下在第一个周期内都不可预测,第二个周期开始每一位都可预测,在周期长度限制内可以存在最多5位连续1或者0数字串。
要理解这一段只要先明确真随机分布的特点即可,其不管称为真随机分布或者真随机分布都是一样的,甚至可以直接用随机分布来称呼,它的特点就是不可预测和不可压缩(还记得第一部分关于这两点的介绍吗?),“不存在周期性”和“可以存在任意长的连续1或者0数字串”都是这两点的自然推论。
之后伪随机分布也很好理解,它就相当于在一个周期内(因为PRNG的特点导致必然存在周期)尽量去模仿真随机分布,一个优秀的PRNG生成的伪随机分布几乎没有什么办法在周期内和真随机分布进行区分,并且还都有很长的周期(梅森旋转算法周期可以达到2^19937-1)。
理解这两者之后就很容易把伪随机分布和它们区分开,实际上它就是用某种机制把某一随机分布**(既可以是真随机分布也可以是伪随机分布)进行“修正”从而使其更符合应用需求。
在下文中为了避免混淆,我们将直接用PRD这一英文缩写来指代(war3中的这种“概率修正”性质的)伪随机分布。
抽卡游戏的三种“保底”机制
不知道有没有读者看到这个章节题目的时候会说“你可算说到有用的东西了”,某种程度上来说确实如此,“抽卡类游戏”的崛起对游戏讨论环境的改变是巨大的,过往其他类型游戏的讨论中,技术向的讨论通常只有(对游戏机制有一定了解)的小部分玩家参与,而抽卡游戏关于概率与随机的讨论则几乎所有玩家都参与进来,毕竟涉及到现实利益嘛。于是这类讨论的平均理论水平就被稀释的很低,各种错误概念错误理解甚至于种种玄学甚至成为主流,这也是促使我写这篇文章最核心的原因。
既然大家都等了很久了,我们直接进入正题,先说两个前提性质的结论:
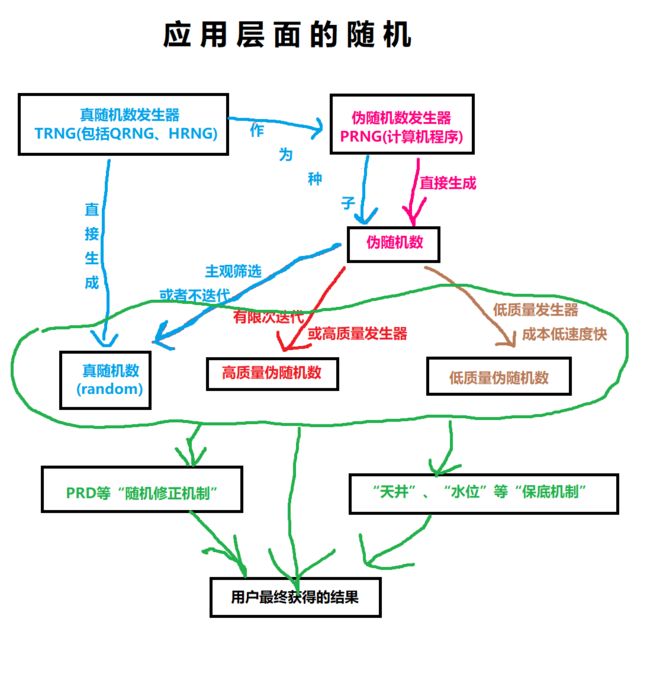
1.几乎所有抽卡游戏都是使用PRNG(伪随机数发生器Pseudo Random Number Generator)。
2.几乎所有抽卡游戏都不会使用PRD(war3中的**“概率修正”**性质的)伪随机分布Pseudo Random Distribution
第一点应该很好理解,因为此类游戏往往需要在短时间内处理极大量的抽卡请求,能满足这样需求的==TRNG==(真随机数发生器True Random Number Generator)成本太高,调试和维护也比较麻烦,而现有的高端商用PRNG加上高质量的种子生成模式足以应付需求。
第二点只要回忆一下上面我们讲PRD时候举的例子就明白了,PRD在减少“一直抽不出五星卡”的情况的同时更大幅度的减少了“连续抽到五星卡”的情况(此处“更大幅度”的前提是“抽到五星卡”的初始概率比较低,联系一下上面关于暴击的概率计算就明白了),而这种“欧洲人”的情况对于游戏体验的提升是巨大的,很多玩家持续玩下去的动力都是获得了这种体验后的喜悦或者对于获得这种体验的期待,更重要的是在“出五星卡概率恒定”和“有足够多的玩家数量”两个条件下,极少数“连续抽到五星卡”的情况是不影响运营利益的(总期望不变且更加接近理论期望)。
但是,“连续不出五星卡”的“非洲人”体验带来的危害也是不能忽略的,绝大多数玩家放弃一款抽卡游戏的理由都是“沉船弃坑”,于是绝大多数抽卡游戏运营商(注意:不是“所有”)都会设置一个“保底机制”来给玩家一点安慰,在实际中才用的“保底机制”主要有以下三种:
洗牌式:
假设一个抽卡游戏的概率是这样设定的:
五星卡:1%
四星卡:9%
三星卡:20%
二星卡:30%
一星卡:40%
那么我们可以直接用1100的数字来代表这些卡,1号是五星卡,2号10号是四星卡,11号30号是三星卡,31号60号是二星卡,61号~100号是一星卡。然后使用如下抽卡程序:1.用PRNG生成的随机数表对1号~100号数字进行排序。 2.每次玩家发出抽卡请求,依次反馈排序后的序号。 3.根据序号生成抽卡结果。 4.每当1号~100号均被抽取过后,重新用PRNG生成的随机数表对其进行排序,等待玩家继续抽取。在实际应用的时候,可以把序号增加若干倍,比如使用10000个序号,这样可以容纳更多的卡牌,并且最关键的是可以对同稀有度的不同卡牌进行概率控制,具体操作是这样:
首先我们把序号扩大至10000,那么代表五星卡的序号就是10000x1%=100即1号~100号,之后比如此时卡池中有五张五星卡,分别分配20个序号即可,之后如果想让某一张卡概率翻倍,只要给它分配40个序号,其他卡平分剩下的60个序号每人15个即可,非常方便。
洗牌式与其说是抽卡游戏中的保底机制,更应该被称为所有抽卡游戏的始祖,首先现实中的(小规模)抽奖自古以来几乎都是用这种“抓阄”的方式,之后在电子游戏的雏形期,几乎所有的程序内抽卡机制都是使用的这种方式,因为它在程序上极其简单,设定和调整也非常方便,但是其缺点也非常明显:首先这种模式非常容易被玩家发现,之后如果玩家发现自己在“一个序号循环周期”的最初几次抽卡就抽出了五星,那么他就明白接下来的几乎整个周期将不会再出现五星卡,这极大的降低了游戏体验,所以这种机制目前多用于单机游戏,或者网络游戏中一些和现实货币不挂钩的抽奖系统中,还可以通过提供“卡池重置”操作来提高用户体验。
天井式:
这是最简单粗暴的一种方式,直接设定一个抽卡次数,达到该次数后,无论抽卡结果为何(即使已经出了高于理论期望值的五星卡),也直接给予玩家一张五星卡。
该次数一般设定为比实际抽出五星卡的平均期望次数高很多比如翻倍,以免对实际五星获取率提升过大,造成五星卡贬值。
天井制是最省心的方式,并且因为太容易被发现,一般采用这种方式的运营商都直接将其公之于众,促使重度消费玩家直接以天井为目标投入金钱抽卡,当然其弊端也是显而易见的,很容易打击低消费玩家,尤其是其中那些运气不好的,投入达不到天井又没有出卡,“打水漂”的感受要比没有天井机制的游戏更加强烈,最终容易导致玩家群体分布出现割裂,即只剩下高消费玩家和几乎零消费的玩家,这样沙漏型的玩家结构是不如纺锤形稳定的。
水位式:
这种模式有点像war3的PRD了,只不过不需要调整概率本身,而是给每个抽卡用户一个后台“计数器”,每当玩家进行一次抽卡,计数器就+1,只要玩家抽出五星卡,计数器就归零,否则就一直增加下去,直到预先设定好的一个“水位值”的时候,直接让玩家该次必然获得一张五星卡。该数值一般设定为比抽出五星卡的平均期望次数稍高一点,让玩家总体的最低出卡体验比较接近。
这可以说是现在最流行的一种方式了,相当于在几乎不增加“连续抽到五星卡”情况的前提下大大减少了“一直抽不出五星卡”的情况。并且还相当隐蔽,没有大量的数据收集很难被发现,同时又有很大的调整空间,然而恰恰因为后两个优点,大部分运营商都将其作为后台参数进行保密,于是一旦被发现,也会影响运营方的信誉,因为毕竟涉及到现实利益,很多玩家会觉得既然有“后台参数调整”的机制,那么即使现在运营做的是“利于玩家的调整”,但是难保以后运营方不会利用这些机制做“不利于玩家的调整”,所以说消费者的心还真的很难掌握呢。
原理层面:
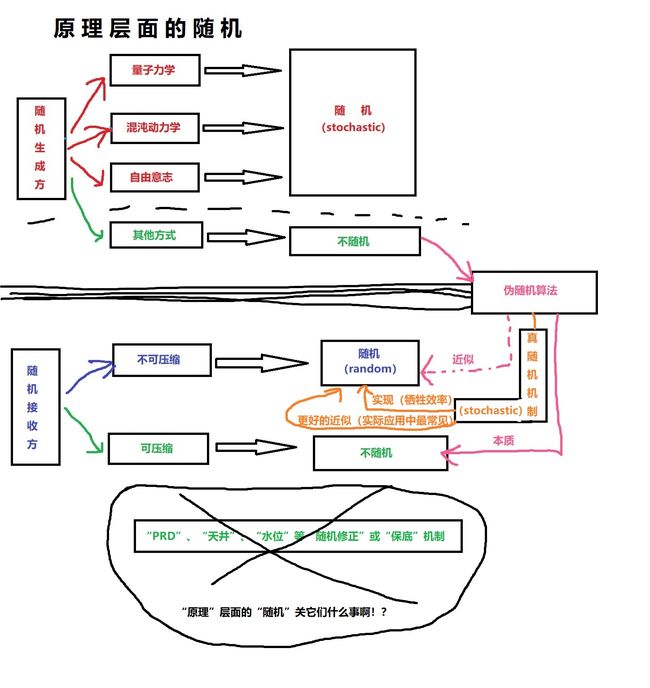
应用层面
随机在科研和生产中的应用
这里先简单说两点:
1.实际科研生产中伪随机往往优于真随机。
如今的我们很难想象,在那个“计算机只能生成真随机数的时代”,当科研人员需要使用随机数的时候,往往是捧起一本巨大的《随机数表》,随便翻一页直接用里面的随机数,甚至在我国2008年发布的关于质检的国家标准《GB/T 10111-2008》的附录中还有随机数表
真随机一定公平吗
当然不是了,首先理想的硬币就不存在,其次即使是理想的条件下,我们也可以很容易构造出一个不公平的真随机数发生器:
取一枚理想的骰子,把1、2两个面写上“正”字,把3、4、5、6四个面写上“反”字,然后把它视为一个硬币去投掷并用1和0分别代表正面和反面来记录结果。
显然它生成的由1和0组成的数列中出现0的概率是1的两倍,然而我们无法用这一规律进行预测和压缩,所以它仍然是真随机的。
有一个方法可以在保持真随机的前提下提高公平性:
我们现实中的硬币因为正反两面图案不同,所以出现的概率必然也有微小的差别,如果需要用硬币进行严肃的决定(所以说为什么严肃的决定要用硬币啊!)
可以用这样的机制:1.将该硬币连续投掷两次。 2.将“正、反”的结果视为“正面”,将“反、正”的结果视为“反面”。 3.如果出现“正、正”或者“反、反”的结果就将其忽略,重新进行两次投掷直到出现步骤2中的情况。于是即使我们使用了一枚极其不公平的硬币,比如说正面的概率是反面的两倍,那么“正、反”的概率为2/3乘以1/3等于2/9,“反、正”的概率为1/3乘以2/3还是2/9。始终是公平的。
当然这种公平性实际上也是相对的,毕竟第一次投掷造成硬币在微观层面上的变形或磨损也可能会影响第二次投掷的结果,但是对于能用一枚硬币来决定的事情来说这种公平性应该是足够了,但是我们由此也会发现一个事实:
彩票用的摇奖机是完美的真随机发生器,但实际上对于单次摇奖结果来说并不公平,虽然这种不公平性在极微观的层面导致无法人为控制。
目前彩票中心是通过每次摇奖更换新球的方式来使这种不公平被平均化大体上消除,然而如果所有彩民都是理性的且追求公平性的话,彩票中心用一个足够优质的伪随机发生器反而更公平……
伪随机是否代表一定有“玄学时段”或者“窗口期”
先和我一起念下面这句话:
程序员第一定律:程序员永远会用最low的代码去实现用户需求。
然后回顾一下前面关于PRNG的概念,再看看那个完整的随机机制设计案例,然后请问大家,如何在伪随机发生器的层面实现可供利用(最起码长度达到数分钟)的“玄学时段”?
之后如果你真的理解了前文,你只会有一种反应:
这不是有病吗!?
首先,想要在伪随机发生器层面实现“玄学时间”本身倒不难,只要缩短周期就行了,然而别忘了,PRNG首先要保证高速生成大量高质量随机数这一要求,这就太难了,需要在随机数表的应用模式上附加大量的机制,总的来说,两个字,有病。
如果真的想要在某个时段让玩家出卡率提高,直接在概率设定上改不就好了吗?这和真随机伪随机有什么关系呢?所以总结一下就是以下几句话:
1.存不存在“玄学时段”和游戏是否采用伪随机发生器没有任何关系。
2.同理如果存在“玄学时段”也不能说明游戏采用了伪随机发生器。
3.运营方的任何概率调整唯一的原因就是利益层面,而“(非公开的)玄学时段”带不来什么利益,程序员不写没用的代码。
4.如同我前面那个案例所说,抽卡游戏几乎都是在服务器上设置单独的、不和现实时间周期有对应的、定期重置的计数器,即使运营方人为设置了“玄学时间”也和现实时间不一定存在对应关系。
可是为什么我抽卡的时候感觉有很明显的“玄学时段”或者“窗口期”呢
说明运营方使用了高质量的伪随机发生器。
如果抽卡时候让你感觉有很明显的“玄学时段”或者“窗口期”,是因为运营方使用了高质量的伪随机发生器,抽卡结果非常近似于真随机。
随机分布产生的疏密是在已经产生了结果后对结果的“归纳”,在生成层面是无法加以利用的。
举例说明就是观察一个大城市生男孩和女孩的比例,最终的结果可能是各约50%,比如女孩495811人:男孩501933人,但是如果分别观察每一栋居民楼生男孩和生女孩的比例,非常容易出现比如女孩1人:男孩3人这样“女孩25%,男孩75%”这样看似悬殊的比例,也就是所谓的疏密。
这是随机分布本身的特点,而并非有一种机制强行去制造这种疏密,同样也不存在一种机制在宏观上去平均这种疏密,如果不理解这一点,就容易陷入一种悖论之中:
假设你所在的居民楼目前有4个女孩,1个男孩,你妻子刚怀孕,你觉得生男孩的概率高还是生女孩的概率高?
**A思路:**男孩的概率高,我们这个城市的女孩和男孩比例是1:1,这栋楼现在是4:1,肯定要平衡成1:1的。
**B思路:**女孩的概率高,我们楼的女孩和男孩比例是4:1,说明我们楼更容易生女孩。
这两种思路显然都是荒谬的,然而非常不幸的是,在网络上关于概率的讨论,就我观察而言,90%以上都是按这两种思路在讨论。
伪随机是否一定可以“垫刀”
所谓“垫刀”就是“利用保底机制获利”的意思,比如war3剑圣砍杂兵好几刀没出致命一击就赶紧去砍对方英雄,因为出致命一击的概率被PRD叠高了很多,“垫刀”的称呼源自某上古网游中的武器强化机制,一旦强化失败武器会破碎消失,于是很多人先用垃圾武器去强化,连续破碎几把之后才强化高级武器。
对于这个问题,能看到这里的朋友好像不需要我再做详细解释了,直接给结论:
1.能不能“垫刀”跟是不是伪随机没有任何关系。
2.如果存在“垫刀”机制也是运营方在随机数发生器之外单独设置的,和真随机伪随机也没有任何关系。
3.对于“洗牌”或者“天井”机制来“保底”的抽卡游戏来说“垫刀”没有意义,前者垫不垫你都得轮到那个号才出五星,后者明晃晃的天井在那给你数着呢你还垫什么。
4.对于“水位”机制,看似“垫刀”很有意义,毕竟计数器一直涨上去肯定会出,然而仔细思考一下就会发现实际上根本没法垫,因为每一次抽卡的成功概率在那摆着呢啊,你想垫的过程中抽出五星了那计数器不就归零了,所谓的“垫刀操作”在这类游戏中实际不就是“普通的抽卡操作”么。
5.至于“在游戏内代币池抽若干次不出好东西再去氪金池抽”这种操作就太掩耳盗铃了,基本只有八九十年代的单机游戏才会整个游戏使用一张随机数表,抽卡游戏里不同的卡池都是使用单独的伪随机发生器的。