tensorflow2 目标检测_基于Tensorflow 2.x实现并可视化Faster-RCNN运行过程

写这篇的原因和动力——
What you can't create, you don't understand.
基于2.0版本的tensorflow,使用VOC2007数据集实现Faster-RCNN目标检测算法。这系列Blog将尽可能的详细介绍并讲解算法的每个模块和每个函数的功能。这篇文章将作为一个总览,可视化一张图片在训练和测试过程中的经过。
github:[cmd23333/Faster-rcnn-tensorflow2.x](https://github.com/cmd23333/Faster-rcnn-tensorflow2.x)
欢迎给star ^_^
对应demo文件:faster-rcnn-visualization.ipynb
整个工程化的代码还是使用PyCharm,但平时开发算法的某一模块或者可视化、画图啥的,用notebook还是很不错的!
读取数据
这部分的具体代码都在utils/data.py模块下,主要是用来读取(img, bboxes, labels, scale)的数据对。
按照原论文的提法,将图片按照长边不超过1000,短边不超过600进行放缩(bbox坐标也对应缩放)。放缩时用到了tf.image.resize,两个参数分别代表了原始图片的tensor和一个长度为2的列表或元组,代表放缩后的图片高度和宽度。对坐标信息的放缩也很简单,只要每个坐标乘以相同的放缩比例(scale)就可以了。我们知道,其实Faster-RCNN算法是支持对任意尺度的图片进行目标检测的,那我们这里为什么要对图片放缩处理呢?个人认为是如果训练时候的图片尺寸相差太悬殊可能会影响模型的效果。
回到程序中,导入相应的功能后,直接用dataset[i]的方式就能取出训练数据集中的第$i$个数据。【注意:这边需要修改config的voc_data_dir为本地的VOC数据集目录】

如上图所示,我们取出了数据集中的第1张图片和对应的标签。其shape为(1, 600, 900, 3)分别代表了batch维度,图片的高和宽,通道数。注意img的最大值和最小值,这是减去平均值([0.485, 0.456, 0.406])并除以方差([0.229, 0.224, 0.225])后归一化的结果。然后是bboxes,其形状为(n, 4),数值上最大值接近900,说明是原图尺度的(y1,x1,y2,x2)绝对坐标,n代表一张图片中的目标个数(不固定),label的形状为(n,),这时候label还不包括背景,只有20种目标,6代表汽车对应的类别索引。
调用utils/data.py里的vis函数后,画出图片和对应的目标。

Backbone网络
backbone可以视作特征提取网络,输入的图片经过backbone网络提取特征,得到feature map。原始的算法使用了VGG16作为主干网络。VGG16里有4个2×2的max pooling层,其余卷积层都是SAME形式,不改变长宽这两个维度。
对于输入为四维的图片(batch, h, w, c),第一个维度代表batch size,我们的程序暂时只支持batch=1的情形。经过backbone之后,我们获得了这张图片的feature map,形状为(1, 38, 57, 512),1代表batch size,38和57代表特征图的高度和宽度,数值上为原来(600, 900)的1/16(中间会有向下取整操作),512代表通道数。如下图所示,最小值是0,因为最后一层用了Relu。

我们还可以尝试可视化一下feature_map到底学到了啥,使用tf.reduce_max()对feature_map最后一维求和,即把512个通道的值加起来,然后用plt.imshow()绘制出来。可以看出,feature map在车的轮廓的地方,感应比较强烈;好像那条小路也被感应到了。

Regional Proposal Network
得到feature map之后,我们进入RPN网络,RPN是2-stage的第一个stage,用来获得图片中比较有可能有目标的区域,并且送到后续的网络中做进一步的计算。具体来说的话,我们将feature map送入RPN网络,首先先用一个3*3的卷积接着RELU激活函数对feature map做进一步的特征提取,还是512个通道,得到新的特征图(后面还是用feature map),形状仍然是(1, 38, 57, 512)。
接下来将feature map分别传给两条支路,其中一条是36(4×9)个1*1卷积核的卷积层,后面不加激活函数,可以得到(1, 38, 57, 36)的输出,代表了可能有目标的区域的位置信息;另一条支路是18(2×9)个1*1的卷积核,得到(1, 38, 57, 18)的输出,代表这些区域有目标和没有目标的概率。并且为了后续处理,我们将有无目标的概率reshape成(1, -1, 2)的形状,做一次softmax,表示每个点上的每个anchor有无目标的得分,即(1, 38×57×9, 2)。
上面提到了9和anchor,这其实是算法在做目标检测的时候,在特征图上的每个点都 **生成(并不是真的生成)** 了9个anchors,anchors相当于一个先验信息,我们想要知道这些anchors内是否包含物体,以及物体的坐标。

如上图所示,先看最后一个输出anchor,他的形状为19494×4,代表所有的38×57×9个anchor在原图上的坐标(其最大值为1266,甚至已经超出了原图)。我们可以把anchor画出来,如下图所示。首先要对img作去标准化,放缩回[0,1]的数值,才能使用imshow,其次,我们只画出了前9个anchor。至于为什么是9个,因为3种长宽比(ratio)×3种尺度(scale)。


下面我们再关注前面两个输出rpn_locs和rpn_scores。rpn_locs代表了一个比较有可能有目标的区域相对于一个anchor的相对位置,对每个anchor都生成了一份(d_x, d_y, d_h, d_w),共19494份。假设anchor的中心点为(x_a, y_a),高度和宽度为(h_a, w_a),则预测的比较有可能有目标的区域的中心点和宽高为
所以我们会看到rpn_locs的取值并不是很大。在程序中,我们使用loc2bbox函数将相对位置转换为对应anchor的绝对坐标(y1,x1,y2,x2形式)。可视化效果如下图[只挑了大约20个画了一下]:


可以看出这些预测还是很离谱的。不过没关系,虽然一共生成了大约20000个预测框,但rpn的训练我们只用到了256个。在程序中,对应的类是AnchorTargetCreator。那这256个是怎么选出来的呢?
- 对于每一个真实的bbox(gt_bbox),选择和它重叠度(IoU)最高的一个anchor作为正样本。
- 对于剩下的anchor,从中选择和任意一个gt_bbox重叠度超过0.7的anchor,作为正样本,正样本的数目不超过128个。
- 随机选择和gt_bbox重叠度小于0.3的anchor作为负样本。负样本和正样本的总数为256。
对于每个anchor, 其label 要么为1(前景),要么为0(背景),所以这样实现二分类。在计算回归损失的时候,只计算正样本(前景)的损失,不计算负样本的位置损失。如下图所示,只有256份相对位置的label不为−1

下面我们展示一下被选为正样本的rpn_locs在原图中的情况,红色代表所有的正样本,蓝色是*随机*挑选的一些负样本。
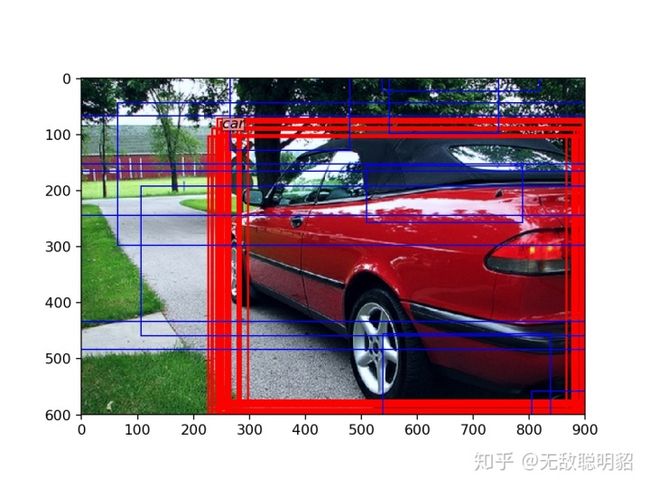
因为是训练了一段时间后再加载的权重,所以正样本已经框的不错了。
这边的gt_rpn_loc其实就是我们预测的rpn_loc的真实值,计算损失函数时,我们希望被选出的256份预测的rpn_loc和gt_rpn_loc越接近越好。如果使用loc2bbox(anchor, gt_rpn_loc),则得到的bbox是完全和真实的目标框重合的。


除了上面这些,这个stage就只剩最后一个事情了:选出一些比较有可能有目标的区域送入第2个stage。还记得程序rpn的输出吗。
观察第三个输出rois,形状是1220×4,最大值为900。这是原图尺度(y1,x1,y2,x2)的比较有可能有目标的区域。在程序中是Proposal Creator做的操作。具体来说,先将前面约20000份相对位置rpn_locs根据rpn_fg_score(即这一份相对位置是前景的得分)排序,分数越大越靠前,代表程序判断其是前景的概率更大。随后,先取分数靠前的12000个,再输入nms,最后得到不超过2000个rois。nms这边就不具体解释了,tensorflow2为我们提供了``tf.image.non_max_suppression()``,很方便。
ROI head
接下来就是Faster RCNN的第二个Stage了。我们不妨先看看送进来的rois长什么样,选择最前面的3个roi,因为nms返回时概率大的靠前,所以这也是最好的3个roi了:


我们发现比rpn的正样本离谱了啊?这边可能就会有饭友觉得坠机了。但实际上我们仔细想一想:前面画出来的pos_training_rpn,是通过真实的目标框选出来的,而实际操作中哪来的真实目标框给你啊?对吧,所以比正样本离谱是正常的。而且就算是前面的pos_training_rpn,用肉眼就可以观察到重合度太大了,NMS操作也必然会扔掉一些,所以我们的roi就只能像上图那样了。
下面继续起飞。
训练时,我们也不是对这所有的1220个roi进行训练,而是从中选取了128个。程序里用的操作是ProposalTargetCreator。128个训练roi的选取规则如下:
- RoIs和gt_bboxes 的IoU大于0.5的,选择一些(比如32个)
- 选择 RoIs和gt_bboxes的IoU介于0.1和0.5的补足128个作为负样本
如下图所示,我们采样了128个roi(期间使用了clip操作,限制roi的区域都在图片内部),同时还是用和获取gt_rpn_loc相似的办法得到了gt_roi_loc,即采样出来的128个roi的目标偏移量。所不同的是,rpn是ground truth相对于anchor的偏移量,而roi head这边是ground truth相对于roi的偏移量。[如果使用``loc2bbox(sample_roi, gt_roi_loc)``,得到的框将和目标完全重合]

其次,这边的gt_roi_label不仅仅是0/1代表有无物体了,而是这个区域对应目标的具体类别(0代表背景,其余类别对应都往后移了一位,前面我们看到car的标签是6,这里已经变成7了)。不妨先可视化一下,被选中的正roi和负roi长什么样。观察到排在后面的都是负样本,前面的是正样本,我们各挑五个画一画。


随后,这128个rois被输入到faster-rcnn的roi head进行后续处理。找到每个roi在feature map对应的区域,然后进行roi pooling操作提取固定尺寸(7×7)的,属于这个roi的特征Tensor。引用一张图吧,下图举例的是提取2×2的特征。
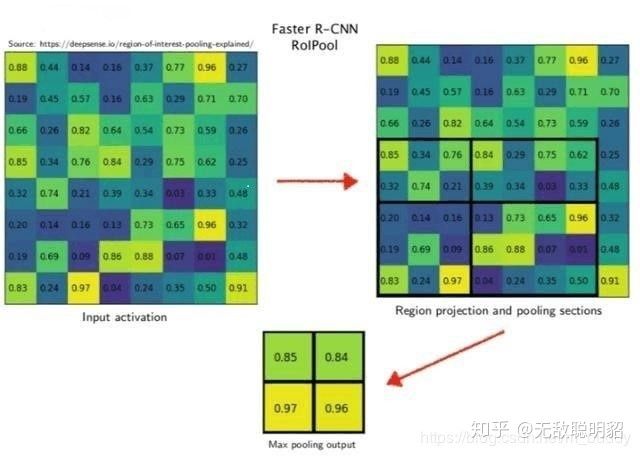
然而,我的程序里并没有用roi pooling,而是用``tf.image.crop_and_resize``这个函数,相当于实现了roi align的功能。roi align是更精确的roi pooling,这篇文章就不具体说了。但二者的目标一致,都是获取每个roi的特征。
roi pooling/align的输出Tensor形状为(128, 7, 7, 512)代表了128个被选中的roi和各自的(7, 7, 512)特征图。随后,分别进入输出维度为84(21*4)和21的两个全连接层,最终输出如下图所示。
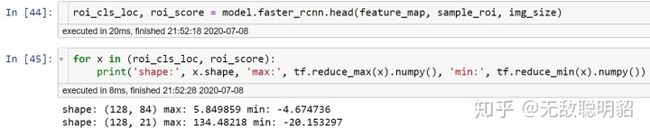
观察一下roi head的两个输出。roi_score的第二个维度21代表了这个roi属于每一类(0-背景,1-20具体物体)的得分。对于分类,直接利用交叉熵计算损失。
另一个输出为roi_loc,形状为(128, 84),代表每个roi和真实目标框的预测相对位置。回归损失,只对正样本计算损失。而且是只对正样本中的这个类别的4个参数计算损失。举例来说:如果这个RoI是负样本,则这84维向量不参与计算回归损失。如果这个RoI是正样本,属于第K类,那么它的第 K×4,K×4+1,K×4+2,K×4+3 这4个数参与计算损失,其余的不参与计算损失。
这样,Faster-RCNN的训练过程其实就结束了,他的四个损失都已经计算完毕,然后反向传播更新梯度就好了。但本文还没有结束,我们继续可视化。
我们不是输出了roi相对于真实目标框的偏移量吗?也就是相当于对比较有可能有目标的区域再做了一次优化!这也是算法被视作2-stage的原因。使用``tf.gather_nd``来取出真实类别对应的那一份(dx,dy,dh,dw),并使用``loc2bbox(sample_roi, roi_loc.numpy())``转化到原图的坐标。

结果如下图所示:

怎么样,是不是可以起飞了?其实还没有。同样的问题,我们直接选取了真实类别对应的那一份(dx,dy,dh,dw),但实际过程我们怎么选呢?
聪明的您一定也想到了,我们选roi_score中分数最高的那一类对应的那份。这边的代码就不再贴了,demo文件的最后几个cell就是。如果没有gt_roi_label,即测试过程的最终结果如下(做了NMS,把好多重合的框去了):

有识别错误的,但也不怎么拉跨对吧!有关算法流程的可视化就到这儿了。详细的工程代码介绍会在下一篇blog补上,其实用tensorflow 2.x撸一整套下来还是有很多坑的,比如计算gt_xxx_loc的时候,一开始我是转成numpy数组计算的,但后来发现这样梯度就传不回去了。还有一些莫名其妙的Bug,真的是得debug模式一步一步拉下来检查T_T。
(end.)
代码见github:[cmd23333/Faster-rcnn-tensorflow2.x](cmd23333/Faster-rcnn-tensorflow2.x),有问题可以评论或者直接issue。