卷积神经网络 实战CIFAR10-基于pytorch
本文将展示一个3+3层的卷积神经网络模型,并给出其在cifar10上的测试效果。
上篇文章指路-> 卷积神经网络-MNIST实战(基于pytorch)_m0_62001119的博客-CSDN博客
目录
代码展示
一、导包工作
二、数据集处理
三、可视化数据
四、搭建网络
五、训练网络
测试效果
问题
验证
心得
参考
代码展示
一、导包工作
import time
import numpy as np
import torch
import torchvision
from torchvision import transforms
import torchvision.datasets as datasets
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
import torch.nn as nn
import torch.optim as optim二、数据集处理
代码如下:
# ToTensor():[0,255]->[C,H,W];Normalize: 标准化(均值+标准差);数据增强(随机翻转图片,随机调整亮度)
transform1 = transforms.Compose([
transforms.RandomHorizontalFlip(),
transforms.RandomGrayscale(),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
transform2 = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
# cifar_size: 50000+10000 32*32*3 10classes
data_train = datasets.CIFAR10('./c10data', train=True, transform=transform1, download=True)
data_test = datasets.CIFAR10('./c10data', train=False, transform=transform2, download=False)
# 定义batch, 即一次训练的样本量大小
train_batch_size = 128
test_batch_size = 128
# 对数据进行装载,利用batch _size来确认每个包的大小,用Shuffle来确认打乱数据集的顺序。
train_loader = DataLoader(data_train, batch_size=train_batch_size, shuffle=True)
test_loader = DataLoader(data_test, batch_size=test_batch_size, shuffle=False)
# 定义10个分类标签
classes = {'plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck'}三、可视化数据
代码如下:
# 可视化数据
examples = iter(test_loader)
images, labels = examples.next()
img = torchvision.utils.make_grid(images)
img = img/2 + 0.5
npimg = img.numpy()
plt.imshow(np.transpose(npimg, (1, 2, 0)))
plt.show()图片示例:

四、搭建网络
代码如下:
# 搭建CNN网络
class CNN(nn.Module):
def __init__(self):
super(CNN, self).__init__()
# 卷积层
self.conv1 = nn.Sequential(
# [(W-F+2P)/S + 1 ] * [(W-F+2P)/S + 1] * M
# [b,32,32,3]->[b,32,32,64]->[b,16,16,64]
nn.Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=1),
nn.ReLU(inplace=True),
nn.BatchNorm2d(64), # Batch Normalization加速神经网络的训练
nn.MaxPool2d(kernel_size=2, stride=2),
)
self.conv2 = nn.Sequential(
# [b,16,16,64]->[b,16,16,128]->[b,8,8,128]
nn.Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=1),
nn.ReLU(inplace=True),
nn.BatchNorm2d(128),
nn.MaxPool2d(kernel_size=2, stride=2),
)
self.conv3 = nn.Sequential(
# [b,8,8,128]->[b,8,8,256]->[b,4,4,256]
nn.Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=1),
nn.ReLU(inplace=True),
nn.BatchNorm2d(256),
nn.MaxPool2d(kernel_size=2, stride=2),
)
# 全连接层
self.dense = nn.Sequential(
# 线性分类器
nn.Linear(4*4*256, 512),
nn.ReLU(),
nn.Dropout(p=0.5),
nn.Linear(512, 256),
nn.ReLU(),
nn.Dropout(p=0.5),
nn.Linear(256, 10),
)
# 前向计算
def forward(self, x):
x = self.conv1(x)
x = self.conv2(x)
x = self.conv3(x)
# print("x_shape:", x.size())
x = x.view(x.size(0), -1)
return self.dense(x)
model = CNN() # 实例化模型
print(model) # 打印模型五、训练网络
代码如下:
# 设置训练次数
num_epochs = 25
# 定义损失函数
criterion = nn.CrossEntropyLoss()
# 定义优化方法
optimizer = optim.Adam(model.parameters(), lr=0.001)
# 定义存储损失函数和准确率的数组
train_losses = []
train_acces = []
eval_losses = []
eval_acces = []
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# 训练模型
print("start training...")
for epoch in range(num_epochs):
# 记录训练开始时刻
start_time = time.time()
train_loss = 0
train_acc = 0
model.train()
for i, data in enumerate(train_loader):
inputs, labels = data
# inputs, labels = inputs.to(device), labels.to(device)
outputs = model(inputs)
loss = criterion(outputs, labels)
optimizer.zero_grad() # 模型参数梯度清零
loss.backward() # 误差反向传递
optimizer.step() # 更新参数
train_loss += loss
_, pred = outputs.max(1)
num_correct = (pred == labels).sum().item()
acc = num_correct / labels.shape[0]
train_acc += acc
# 取平均存入
train_losses.append(train_loss / len(train_loader))
train_acces.append(train_acc / len(train_loader))
# 测试集:
eval_loss = 0
eval_acc = 0
# 将模型设置为测试模式
model.eval()
# 处理方法同上
for i, data in enumerate(test_loader):
inputs, labels = data
# inputs, labels = inputs.to(device), labels.to(device)
outputs = model(inputs)
loss = criterion(outputs, labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
eval_loss += loss
_, pred = outputs.max(1)
num_correct = (pred == labels).sum().item() # 记录标签正确的个数
acc = num_correct / labels.shape[0]
eval_acc += acc
eval_losses.append(eval_loss / len(test_loader))
eval_acces.append(eval_acc / len(test_loader))
# 输出效果
print('epoch:{},Train Loss:{:.4f},Train Acc:{:.4f},'
'Test Loss:{:.4f},Test Acc:{:.4f}'
.format(epoch, train_loss / len(train_loader),
train_acc / len(train_loader),
eval_loss / len(test_loader),
eval_acc / len(test_loader)))
# 输出时长
stop_time = time.time()
print("time is:{:.4f}s".format(stop_time-start_time))
print("end training.")测试效果
作者设置的是25个epochs,不过由于CPU计算实在太慢,于是只能先跑了个10次,最终效果还算不错。
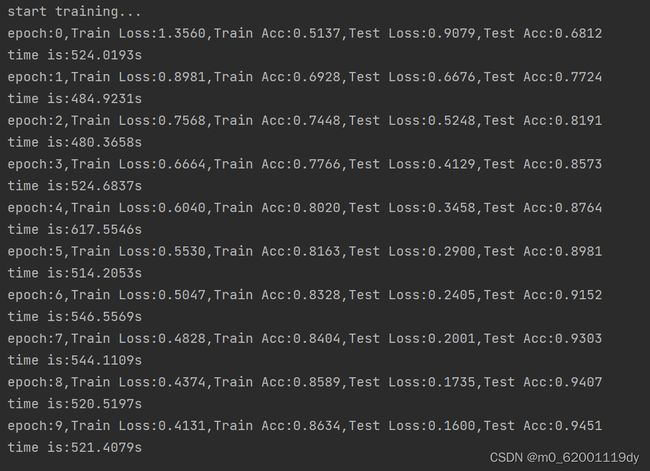
问题
1. 模型测试的准确率总比训练的高很多。
作者在测试模型的时候也进行了误差反向传播,有些教程上说测试时不用再进行误差反向传播和参数的更新,猜想这可能是原因之一;
作者在定义模型时使用了Dropout函数进行正则化,这个函数只在训练时网络时用到,测试阶段不会有这一层,这可能是导致训练的acc小于测试的原因;
作者这个网络训练迭代的次数比较少,可能模型还不稳定,等模型稳定后,两个loss值基本上应该会保持一致。
验证
作者将上述问题进行了部分整改,最后测试的结果相对来说“正常”了许多。但是这次测试的准确率降低了很多,很明显训练时出现了过拟合,所以,通过Dropout函数进行正则化(或者使用其他方法,如数据增强等)来减少模型的过拟合是非常必要的手段。
最终效果图:
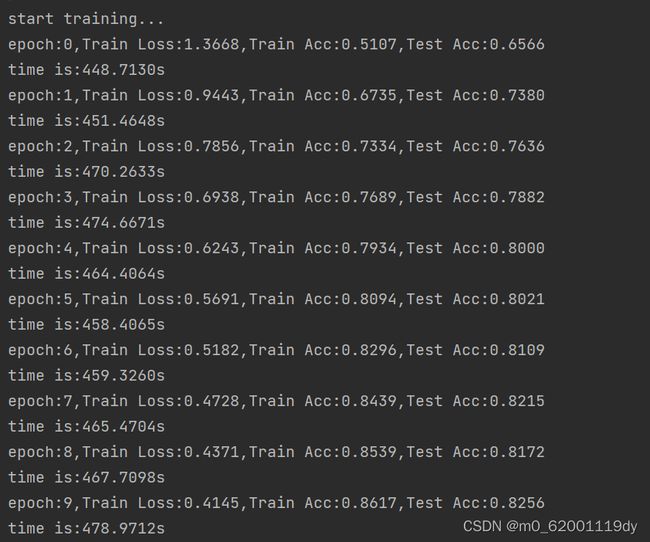
心得
这次的神经网络比上次搭建的框架略为复杂一些,数据集由mnist变为cifar10,数据复杂度在一定程度上有所提升。同时,这次的卷积层引入了Batch Normalization函数,旨在加速训练过程。关于该函数的详细介绍可移步至这个链接
ps: 本文还有很多地方知识点不够准确,表达不够清晰,敬请指正!
参考
CNN笔记:通俗理解卷积神经网络_结构之法 算法之道-CSDN博客_卷积神经网络