【翻译:OpenCV-Python教程】背景减法
⚠️这篇是按4.1.0翻译的,你懂得。
⚠️除了版本之外,其他还是照旧,Background Subtraction,附原文。
目标
在本章,
- 我们来熟悉OpenCV里可用的背景减法。
基础
背景减法在许多基于是觉的应用中是一个主要的预处理步骤。比如说,考虑这样的情况,一个用于访客统计的静止摄像头,去除访客进入和离开房间的数量,或者一个交通摄像头提取车辆的信息等等。在所有的这些情况之下,首先你需要单独提取人或者车辆。技术上讲,你需要从不动的背景中提取移动的前景。
假设你有一张单独的背景图,比如一张没有访客的房间图片,没有车辆的道路等等,那事情就很好办。只要用新图片把背景减去即可。你就能得到单独的前景对象。但在多数情况下,你可能没有一张这样的图像,所以我们得从任何我们拥有的图像中提取出背景。当图片中有车辆的阴影时,事情就变的更复杂了。因为阴影也会移动,简单的图像减法会把这些也标记成前景。它会使事情变复杂。
为此我们将介绍几种算法。OpenCV 实现了三种非常简单易用的算法,我们会一个个的来看它们。
BackgroundSubtractorMOG
(译者附,MOG算法背景提取器,考虑到这个标题就是OpenCV里的方法名,为了便于记忆就不翻译了。)
这是一个基于高斯混合模型的背景/前景分割算法。它在 P. KadewTraKuPong 和 R. Bowden 在2001年的论文"An improved adaptive background mixture model for real-time tracking with shadow detection"中被介绍。它使用对每个背景像素通过一个混合K高斯分布(K = 3 到 5)来建模的方法。混合的权重表示这些颜色在场景中停留的时间比例。而可能的背景颜色是那些停留时间更长、更静态的颜色。
当编码的时候,我们需要通过函数 cv.createBackgroundSubtractorMOG() 创建一个背景对象,它有一些可选的参数,比如历史长度,高斯混合数,阈值等等,所有这些都被设了默认值。然后在视频循环中,使用 backgroundsubtractor.apply() 方法获得前景蒙版。
看下面这个简单的例子:
import numpy as np
import cv2 as cv
cap = cv.VideoCapture('vtest.avi')
fgbg = cv.bgsegm.createBackgroundSubtractorMOG()
while(1):
ret, frame = cap.read()
fgmask = fgbg.apply(frame)
cv.imshow('frame',fgmask)
k = cv.waitKey(30) & 0xff
if k == 27:
break
cap.release()
cv.destroyAllWindows()( 所有的结果都显示在最后进行比较)。
BackgroundSubtractorMOG2
这同样也是一个基于高斯混合模型的背景/前景分割算法。它基于Z.Zivkovic的两篇论文:2004年的"Improved adaptive Gaussian mixture model for background subtraction" 以及 2006年的"Efficient Adaptive Density Estimation per Image Pixel for the Task of Background Subtraction"。该算法的一个重要特点是为每个像素选择合适的高斯分布个数。(记住,在上一个例子中,我们在整个算法中使用了同一个K值)。它在由光照变化等情况引起场景改变的情况下表现除了更好的适应性。
和上一个例子一样,我们必须创建一个背景提取对象。在此,你有一个是否检测阴影的选项。如果 detectShadows = True (默认就是True),它就会检测并且标记阴影,当然这会降低速度。阴影会用灰色标记出来。
import numpy as np
import cv2 as cv
cap = cv.VideoCapture('vtest.avi')
fgbg = cv.createBackgroundSubtractorMOG2()
while(1):
ret, frame = cap.read()
fgmask = fgbg.apply(frame)
cv.imshow('frame',fgmask)
k = cv.waitKey(30) & 0xff
if k == 27:
break
cap.release()
cv.destroyAllWindows()(结果给在文末)
BackgroundSubtractorGMG
该算法结合了统计背景图像估计和逐像素贝叶斯分割。它在 B. Godbehere,Akihiro Matsukawa,和 Ken Goldberg 在它们2012年的论文 "Visual Tracking of Human Visitors under Variable-Lighting Conditions for a Responsive Audio Art Installation" 中被介绍。如这篇论文所述,该系统成功的运行了一个被叫做"我们还在那吗"的交互式音频。从2011年3月31日到7月31日,在加州旧金山的当代犹太博物馆。
它使用前几帧(默认为120帧)作为背景建模。它采用概率前景分割算法,利用贝叶斯推理来识别可能的前景对象。估计是自适应的;为了适应不断变化的光照,新的观测结果比旧的观测结果权重更大。还进行了一些形态滤波操作,如开闭算法,以消除不必要的噪声。在最初的几帧中,你会得到一个黑色的窗口。
为了去除噪声,最好将形态学开运算应用到结果中。
import numpy as np
import cv2 as cv
cap = cv.VideoCapture('vtest.avi')
kernel = cv.getStructuringElement(cv.MORPH_ELLIPSE,(3,3))
fgbg = cv.bgsegm.createBackgroundSubtractorGMG()
while(1):
ret, frame = cap.read()
fgmask = fgbg.apply(frame)
fgmask = cv.morphologyEx(fgmask, cv.MORPH_OPEN, kernel)
cv.imshow('frame',fgmask)
k = cv.waitKey(30) & 0xff
if k == 27:
break
cap.release()
cv.destroyAllWindows()结果
原始帧
下图显示了该视频的第200帧

BackgroundSubtractorMOG的结果

BackgroundSubtractorMOG2的结果
灰色表示出了影子的区域。

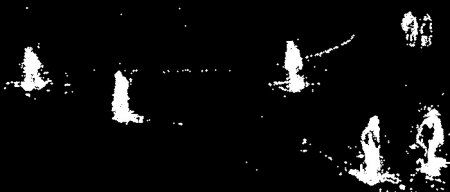
BackgroundSubtractorGMG的结果
形态学的开运算除去了噪音点。
额外资源
练习
上篇:【翻译:OpenCV-Python教程】光流
下篇:【翻译:OpenCV-Python教程】摄像头校准