智能数字图像处理之FastRCNN(pytorch)代码解读之train_resnet50_fpn.py
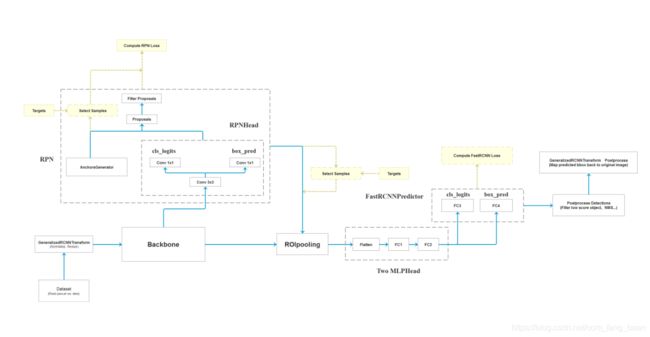
解读create_model方法
1. num_classes:分类数
2.backbone = resnet50_fpn_backbone()
model = FasterRCNN(backbone=backbone, num_classes=91)-》调用faster_rcnn_framework的FasterRCNN方法,传入分类数num_classes为91
3.weights_dict = torch.load("./backbone/fasterrcnn_resnet50_fpn_coco.pth")
missing_keys, unexpected_keys = model.load_state_dict(weights_dict, strict=False)-》加载预训练的权重文件
4. if len(missing_keys) != 0 or len(unexpected_keys) != 0:
print("missing_keys: ", missing_keys)
print("unexpected_keys: ", unexpected_keys)-》打印预训练权重信息
5.in_features = model.roi_heads.box_predictor.cls_score.in_features-》获取分类器输入特征的数量
6.model.roi_heads.box_predictor = FastRCNNPredictor(in_features, num_classes)-》用一个新的头替换一个预先训练好的头
解读main方法:
1.device = torch.device(parser_data.device if torch.cuda.is_available() else "cpu")-》查看设备是否有可用的GPU
2.data_transform = {-》图像预处理函数
"train": transforms.Compose([transforms.ToTensor(),
transforms.RandomHorizontalFlip(0.5)]),-》随机水平翻转
"val": transforms.Compose([transforms.ToTensor()])
}
3.VOC_root = parser_data.data_path-》数据集根目录
4.train_data_set = VOC2012DataSet(VOC_root, data_transform["train"], True)-》加载数据集的VOC2012DataSet方法
5.加载训练数据集
train_data_loader = torch.utils.data.DataLoader(train_data_set,
batch_size=1,
shuffle=False,
num_workers=0,
collate_fn=utils.collate_fn)
val_data_set = VOC2012DataSet(VOC_root, data_transform["val"], False)
val_data_set_loader = torch.utils.data.DataLoader(val_data_set,
batch_size=2,
shuffle=False,
num_workers=0,
collate_fn=utils.collate_fn) -》加载验证数据集
6. model = create_model(num_classes=21)-》创建模型分类数为20个类
7.model.to(device)-》加载模型到GPU
8.params = [p for p in model.parameters() if p.requires_grad]
optimizer = torch.optim.SGD(params, lr=0.005,
momentum=0.9, weight_decay=0.0005)-》设置优化器、学习率、动量等。
9.lr_scheduler = torch.optim.lr_scheduler.StepLR(optimizer,
step_size=5,
gamma=0.33)-》学习速率调度器
10.if parser_data.resume != "":
checkpoint = torch.load(parser_data.resume)
model.load_state_dict(checkpoint['model'])
optimizer.load_state_dict(checkpoint['optimizer'])
lr_scheduler.load_state_dict(checkpoint['lr_scheduler'])
parser_data.start_epoch = checkpoint['epoch'] + 1
print("the training process from epoch{}...".format(parser_data.start_epoch))-》如果指定了上次训练保存的权重文件地址,则接着上次结果接着训练
11.训练一个新纪元,打印每10次迭代
for epoch in range(parser_data.start_epoch, parser_data.epochs):
# train for one epoch, printing every 10 iterations
utils.train_one_epoch(model, optimizer, train_data_loader,
device, epoch, train_loss=train_loss, train_lr=learning_rate,
print_freq=50, warmup=True)
lr_scheduler.step()-》更新学习率
utils.evaluate(model, val_data_set_loader, device=device, mAP_list=val_mAP)-》对测试数据集进行评估
save_files = {
'model': model.state_dict(),
'optimizer': optimizer.state_dict(),
'lr_scheduler': lr_scheduler.state_dict(),
'epoch': epoch}
torch.save(save_files, "./save_weights/resNetFpn-model-{}.pth".format(epoch))-》保存权重参数
12. if len(train_loss) != 0 and len(learning_rate) != 0:
from plot_curve import plot_loss_and_lr
plot_loss_and_lr(train_loss, learning_rate)-》图损失和lr曲线
if len(val_mAP) != 0:
from plot_curve import plot_map
plot_map(val_mAP)-》绘制地图曲线
最后:__name__ == "__main__":代码
1. version = torch.version.__version__[:5] # example: 1.6.0
if version < "1.6.0":
raise EnvironmentError("pytorch version must be 1.6.0 or above")-》控制torch版本大于等于1.6.0
2. # 设置训练设备类型
parser.add_argument('--device', default='cuda:0', help='device')
# 设置训练数据集的根目录
parser.add_argument('--data-path', default='./', help='dataset')
# 设置文件保存地址
parser.add_argument('--output-dir', default='./save_weights', help='path where to save')
# 设置若需要接着上次训练,则指定上次训练保存权重文件地址
parser.add_argument('--resume', default='', type=str, help='resume from checkpoint')
# 设置指定接着从哪个epoch数开始训练
parser.add_argument('--start_epoch', default=0, type=int, help='start epoch')
# 设置训练的总epoch数
parser.add_argument('--epochs', default=15, type=int, metavar='N',
help='number of total epochs to run')
3.args = parser.parse_args()
print(args)
# 检查保存权重文件夹是否存在,不存在则创建
if not os.path.exists(args.output_dir):
os.makedirs(args.output_dir)
main(args)-》调用main方法
附上完整代码:
import torch
import transforms
from network_files.faster_rcnn_framework import FasterRCNN, FastRCNNPredictor
from backbone.resnet50_fpn_model import resnet50_fpn_backbone
from my_dataset import VOC2012DataSet
from train_utils import train_eval_utils as utils
import os
def create_model(num_classes):
backbone = resnet50_fpn_backbone()
model = FasterRCNN(backbone=backbone, num_classes=91)
# 载入预训练模型权重
# https://download.pytorch.org/models/fasterrcnn_resnet50_fpn_coco-258fb6c6.pth
weights_dict = torch.load("./backbone/fasterrcnn_resnet50_fpn_coco.pth")
missing_keys, unexpected_keys = model.load_state_dict(weights_dict, strict=False)
if len(missing_keys) != 0 or len(unexpected_keys) != 0:
print("missing_keys: ", missing_keys)
print("unexpected_keys: ", unexpected_keys)
# get number of input features for the classifier
in_features = model.roi_heads.box_predictor.cls_score.in_features
# replace the pre-trained head with a new one
model.roi_heads.box_predictor = FastRCNNPredictor(in_features, num_classes)
return model
def main(parser_data):
device = torch.device(parser_data.device if torch.cuda.is_available() else "cpu")
print(device)
data_transform = {
"train": transforms.Compose([transforms.ToTensor(),
transforms.RandomHorizontalFlip(0.5)]),
"val": transforms.Compose([transforms.ToTensor()])
}
VOC_root = parser_data.data_path
assert os.path.exists(os.path.join(VOC_root, "VOCdevkit")), "not found VOCdevkit in path:'{}'".format(VOC_root)
# load train data set
train_data_set = VOC2012DataSet(VOC_root, data_transform["train"], True)
# 注意这里的collate_fn是自定义的,因为读取的数据包括image和targets,不能直接使用默认的方法合成batch
train_data_loader = torch.utils.data.DataLoader(train_data_set,
batch_size=1,
shuffle=False,
num_workers=0,
collate_fn=utils.collate_fn)
# load validation data set
val_data_set = VOC2012DataSet(VOC_root, data_transform["val"], False)
val_data_set_loader = torch.utils.data.DataLoader(val_data_set,
batch_size=2,
shuffle=False,
num_workers=0,
collate_fn=utils.collate_fn)
# create model num_classes equal background + 20 classes
model = create_model(num_classes=21)
# print(model)
model.to(device)
# define optimizer
params = [p for p in model.parameters() if p.requires_grad]
optimizer = torch.optim.SGD(params, lr=0.005,
momentum=0.9, weight_decay=0.0005)
# learning rate scheduler
lr_scheduler = torch.optim.lr_scheduler.StepLR(optimizer,
step_size=5,
gamma=0.33)
# 如果指定了上次训练保存的权重文件地址,则接着上次结果接着训练
if parser_data.resume != "":
checkpoint = torch.load(parser_data.resume)
model.load_state_dict(checkpoint['model'])
optimizer.load_state_dict(checkpoint['optimizer'])
lr_scheduler.load_state_dict(checkpoint['lr_scheduler'])
parser_data.start_epoch = checkpoint['epoch'] + 1
print("the training process from epoch{}...".format(parser_data.start_epoch))
train_loss = []
learning_rate = []
val_mAP = []
for epoch in range(parser_data.start_epoch, parser_data.epochs):
# train for one epoch, printing every 10 iterations
utils.train_one_epoch(model, optimizer, train_data_loader,
device, epoch, train_loss=train_loss, train_lr=learning_rate,
print_freq=50, warmup=True)
# update the learning rate
lr_scheduler.step()
# evaluate on the test dataset
utils.evaluate(model, val_data_set_loader, device=device, mAP_list=val_mAP)
# save weights
save_files = {
'model': model.state_dict(),
'optimizer': optimizer.state_dict(),
'lr_scheduler': lr_scheduler.state_dict(),
'epoch': epoch}
torch.save(save_files, "./save_weights/resNetFpn-model-{}.pth".format(epoch))
# plot loss and lr curve
if len(train_loss) != 0 and len(learning_rate) != 0:
from plot_curve import plot_loss_and_lr
plot_loss_and_lr(train_loss, learning_rate)
# plot mAP curve
if len(val_mAP) != 0:
from plot_curve import plot_map
plot_map(val_mAP)
# model.eval()
# x = [torch.rand(3, 300, 400), torch.rand(3, 400, 400)]
# predictions = model(x)
# print(predictions)
if __name__ == "__main__":
version = torch.version.__version__[:5] # example: 1.6.0
# 因为使用的官方的混合精度训练是1.6.0后才支持的,所以必须大于等于1.6.0
if version < "1.6.0":
raise EnvironmentError("pytorch version must be 1.6.0 or above")
import argparse
parser = argparse.ArgumentParser(
description=__doc__)
# 训练设备类型
parser.add_argument('--device', default='cuda:0', help='device')
# 训练数据集的根目录
parser.add_argument('--data-path', default='./', help='dataset')
# 文件保存地址
parser.add_argument('--output-dir', default='./save_weights', help='path where to save')
# 若需要接着上次训练,则指定上次训练保存权重文件地址
parser.add_argument('--resume', default='', type=str, help='resume from checkpoint')
# 指定接着从哪个epoch数开始训练
parser.add_argument('--start_epoch', default=0, type=int, help='start epoch')
# 训练的总epoch数
parser.add_argument('--epochs', default=15, type=int, metavar='N',
help='number of total epochs to run')
args = parser.parse_args()
print(args)
# 检查保存权重文件夹是否存在,不存在则创建
if not os.path.exists(args.output_dir):
os.makedirs(args.output_dir)
main(args)
https://github.com/WZMIAOMIAO