seer文献_基于 SEER 数据库,如何构建一篇临床预测模型的文章?
上次给大家分享了一篇 SEER 数据库的扫盲文,看到大家留言点赞要求分享数据分析的方法,当时我就拿起我的小本本记下了。
今天,就给各位分享如何基于 SEER 数据库构建一篇临床预测模型的文章。
在详细介绍前,请大家品一品下面的数据:
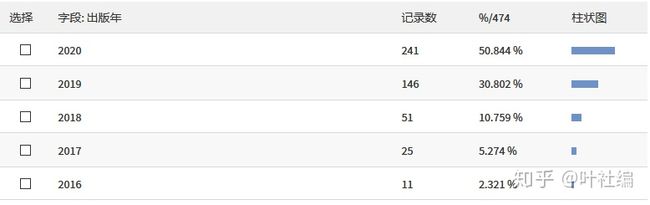
在 Web of Science 中根据 Nomogram(即列线图,是一种临床预测模型的常用可视化形式) 和 Seer 检索,近五年共发表了 474 篇文章,其中 2020 年居然占了 50% 以上。
出于好奇,我又看了一下 2020 年发表的 241 篇中有多少是国人发表的。看到数据的我惊呆了,居然占了将近 95%,看来疫情并没有阻挡大家科研的热情啊!

一、什么是临床预测模型?
临床预测模型,是指根据多因素模型估算患有某病的概率或者未来某结局发生的概率。
听起来很高端,其实就是在单因素与多因素分析之后,再添加几张图就可以了。
临床预测模型包括诊断模型和预后模型。由于笔者的经历,后面主要介绍预后模型。
预后模型关注的是处于某种疾病情况下(如肺癌),未来某结局事件发生的概率(如死亡、肿瘤复发、并发症的出现),属于纵向研究。
二、临床预测模型有什么用呢?
对于临床医生而言,当然是用于指导临床实践(高尚的理想)和发表文章啦(现实的需求)。
如预测免疫治疗的肺癌患者发生腹泻的概率,或基于 SEER 数据库中的 TNM 分期、年龄、性别、放化疗、手术情况等信息构建早期肺癌患者的 1 年、3 年、5 年生存情况。
三、基于 SEER 数据库如何构建临床预测模型?

接下来将基于上图的文章进行讲解。
作者从 SEER 数据库中提取了性别、年龄、种族、T、N、M 分期、AJCC 分期、手术情况、AFP 水平、纤维化分数等基础指标。

然后根据 7:3 的比例分成了建模队列和验证队列。在建模队列中,将单因素 COX 分析中 P 值 <0.05 的变量纳入多因素 COX 分析。
然后,根据多因素 COX 分析中 P<0.05 的自变量构建了 Nomogram 图(诺莫图或列线图)。
然后,使用验证队列评估模型的区分度(Discrimination)和校准度(Calibration)。前者通过 ROC 曲线下面积(AUC)或 C 指数来评价,后者通过校准图评价。
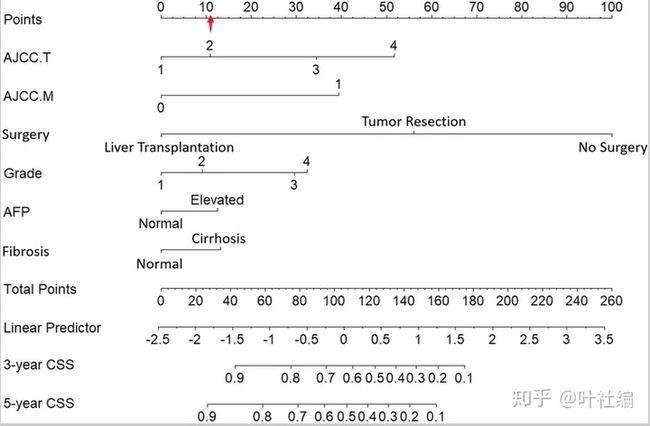
上图即是 Nomogram 图,将每个指标向上投射到 Points,会得出单独的分数。
最后,再将这六个指标的分数相加得出总分,根据 Total Points 向下投射即可得到 3 年、5 年的 CSS(Cancer-Specific Survival 肿瘤特异性生存)。
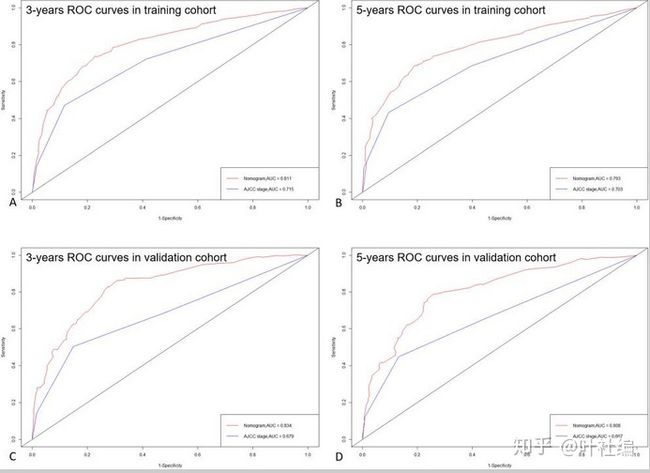
ROC 曲线提示,新的预测模型比传统的 AJCC 模型更佳(比较曲线下面积的大小)。
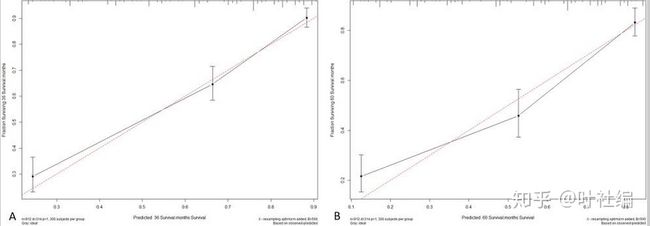
上图为校准图,可以看出,一致性还是可以的(与对角线越接近,一致性越强)。
到这里,其实这篇文章就结束了。为什么选择这篇文献?主要是这篇文章发表时间新(2020 年 12 月 7 日),里面涉及的方法和内容又相对简单。属于初阶版的临床预测模型,思路理解起来比较简单,也很容易学习复用。
归纳起来,基于这类 SEER 构建临床预测模型主要分为以下六个步骤:
1)从 SEER 数据库提取你想要的数据,整理好数据;
2)一般根据 7:3 的原则分配建模人群和验证人群的数量;
3)在 COX 回归分析前,应当评估两组间的基线均衡情况(通常连续变量用 t 检验、分类变量用卡方检验),如果基线不均衡。可以采用倾向性分析的方法,按照 1:1 或者 1:2 的方法进行匹配。使用匹配后的人群进行后续分析。(如果样本量够多,十分建议,这是一个加分项,可以减少混杂因素)
4)使用单因素 COX 和多因素 COX 分析筛选出独立预测因子(多因素中 P<0.05 的);
5)基于独立预测因子构建 Nomogram 图;
6)评价预测模型:三个维度—区分能力、校准度、临床有效性。
区分能力:
a. ROC 曲线下面积(AUC)或 C 指数:
在预测模型中,AUC 也可以称之为 C 指数。C 指数的范围为 0.5-1.0 之间。C 指数处于 0.5-0.7 为较低区分度;0.7-0.9 为中等区分度;大于 0.9 则为高区分度。
b. 净重新分类指标(NRI):
加入某个新预测因素,与旧模型进行对比,评估预测能力改善情况。NRI>0,表示正改善,说明新模型较旧模型预测能力有所改善。反之,NRI<0,表示预测能力下降。
c. 综合判别改善指数(IDI):
综合反映两个模型预测概率的差距。IDI 的评估方式与 NRI 一致。两者的区别在于 NRI 是针对某个设定好的切点水平下进行比较,IDI 则是基于每个个体的预测概率计算的综合指标。都可以用于区分度的评价。
校准度:
a. Hosmer-Lemeshow 检验(拟合优度检验)
P 值越大,提示预测模型的校准度越好。若 P<0.05,表示模型预测值与实际值之间存在差异,模型校准度差。
b. 校准图:散点图、条形图、线图。(示例范文中展示的是线图)。与标准曲线越接近,校准度越好。
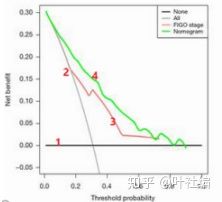
c. 临床有效性:决策曲线分析法(DCA):探究的临床的净获益(Net Benefit)情况。
横坐标表示阈概率,纵坐标表示净获益。
曲线 1 表示的是所有样本都为阴性,且均不采取治疗,净获益为 0。
曲线 2 表示所有患者都为阳性,且均选择治疗,则净获益为斜率为负值的反斜线。
曲线 3 和曲线 4 均较曲线 1 和 2 高,曲线 4 所代表的模型又比 3 更好一些。
笔者认为,临床预测模型有点像回顾性分析的高阶版。推荐在临床一线的同学与同行们学习,毕竟像这样临床科研兼顾的科研方法,对咱医生可太友好了!