【语义分割】12、Fully Attentional Network for Semantic Segmentation
文章目录
-
- 一、背景和动机
- 二、方法
- 三、效果

出处: AAAI2022
一、背景和动机
语义分割中,non-local (NL)的方法起到了很好了捕捉 long-range 信息的作用,大致可分为 Channel non-local 和 Spatial non-local 两种变种。但是他们却同时有一个问题——attention missing。
以 channel attention 为例:channel attention 能够找到每个通道和其他通道的关联,在计算的过程中,spatial 特征被整合了起来,缺失了不同位置之间的联系
以 spatial attention 为例:spatial attention 能够找到每个位置之间的关系,但所有channel 的特征也都被整合了起来,缺失了不同 channel 之间的联系
作者认为这种 attention missing 问题会削弱三维上下文信息的存储,这两种 attention 方法都有各自的弊端。
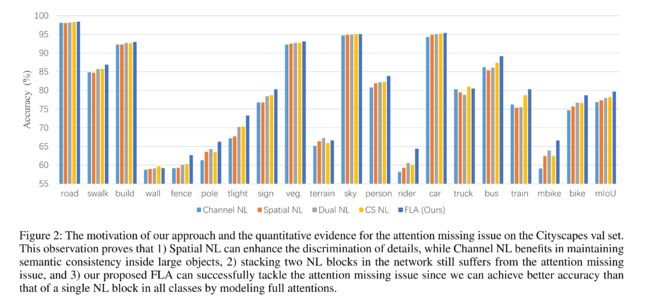
为了验证这个猜想,作者在图 2 绘制了 cityscapes 的验证集每个类别的准确率。
1、单个 attention 的效果:
channel NL 在大目标上表现较好,如 truck,bus,train
spatial NL 在小目标或细长目标上表现较好,如 poles,rider,mbike等
还有一些类别,两者表现都较差
2、复合 attention 的效果:
为了验证两个 attention 同时使用的效果,作者也使用并联的 DANet (Dual NL)和串联的 channel-spatial NL (CS NL)进行对比。
当使用两个 NL 的时候,每个类别的精度增长不亚于使用单个 NL
但是,Dual NL 在大尺度目标(truck,train)上的性能降低较多,CS NL 在细长类别 (pole,mbike)上的 IoU 较差。
所以作者认为,复合的 attention 结构,只能从 channel 和 spatial attention 中的某一方来获得性能的提升,所以,注意力 attention missing 问题就损害了特征的表示能力,不能简单地通过叠加不同的 NL 模块来解决。
受此启发,作者提出了一个新的 non-local 模块——Fully Attention block(FLA)来在所有维度上进行有效的 attention 特征保留。
二、方法
全文的基本思路在于:
在计算 channel attention map 时,使用全局上下文特征来保存空间响应特征,这能够使得在一个单一的 attention 中实现充分的注意并具有高的计算效率,图 1c 为整体结构。
- 首先,让每个空间位置来捕捉全局上下文的特征响应
- 之后,使用 self-attention 机制来捕捉两个 channel 之间和相应空间位置的全注意力相似度
- 最后,使用全注意力相似度来对 channel map 进行 re-weight。
① channel NL 的过程如图1a所示,生成的 attention map 为 C × C C\times C C×C 大小,也就是每个通道和其他所有通道的注意力权重。
② spatial NL 的过程如图1b所示,生成的 attention map 为 H W × H W HW \times HW HW×HW 大小,也就是每个点和其他所有像素点的注意力权重。
③ FLA 的过程如图 1c 所示,生成的 attention map 为 ( C × C ) ( H + W ) (C\times C)(H+W) (C×C)(H+W),其中 C × C C\times C C×C 还是通道注意力权重, ( H + W ) (H+W) (H+W) 是每行(共H行)和每列(共W列)的注意力权重。

Fully Attentional Block(FLA)结构:
FLA 结构如图 3 所示,输入为特征图 F i n ∈ R C × H × W F_{in}\in R^{C\times H \times W} Fin∈RC×H×W
生成 Q:
- 首先,将特征图输入下面的并行通路的最底下的通路(construction),这个两个并行通路都是由 global average pooling + Linear 构成的,为了得到不同的输出,作者也选用了不同的 pooling 核。
- 为了得到丰富的全局上下文信息,作者使用纵横不等的核,即长方形的核
- 为了让每个空间位置都和对应的同横轴或同纵轴的位置都保持信息交互,也就是为了在计算channel 之间的关系的时候保持空间连续性,作者给生成 Q 的这两个并行通道分别选用了 pooling window 大小分别为 H × 1 H\times 1 H×1 和 1 × W 1\times W 1×W 的核。
- 得到不同维度的 Q W Q_W QW 和 Q H Q_H QH 之后,分别进行横向和纵向的扩展,得到维度相同的特征。正是因为这种不同维度的特征抽取,对应维度的空间特征就可以被保留下来。
- 最后,对两种特征进行裁剪和融合
生成 K:
将输入特征在 H 维度进行切分,切分成 H 片,每个 slides 大小为 R C × W R^{C\times W} RC×W,然后和 Q 进行 merge,得到
![]()
然后,就可以得到每个位置和其同行同列像素的注意力权重,得到全注意力 map A ∈ R ( H + W ) × C × C A \in R^{(H+W) \times C \times C} A∈R(H+W)×C×C。

- A i , j A_{i,j} Ai,j 是在特定位置上的 i t h i^{th} ith 和 j t h j^{th} jth channel 的相关程度
生成 V:
![]()
将输入特征在 W 维度进行切分,切分成 W 片,每个 slides 大小为 R C × H R^{C\times H} RC×H,和 A 进行矩阵相乘后,得到经过 attention 后的特征


三、效果



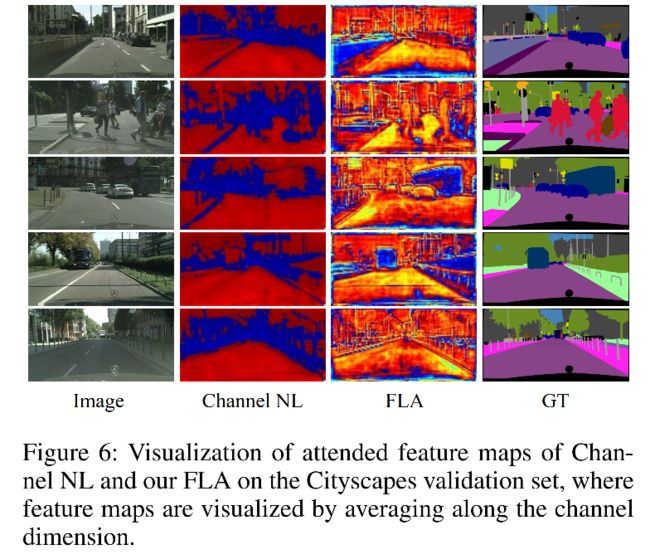
可视化:
channel NL 和 FLA 在语义区域都比较突出,并且在大目标内部都比较连续。
FLA 的注意力特征图比 channel 的注意力特征图更整齐且细腻一些,如远处的 pole 和 目标的边界。
FLA 也能更好的区分不同类别,比如第三行的 bus 和 car
这也证明了,作者提出的 FLA 能在 channel attention 特征图内部捕捉并使用空间相似性,来实现 full attention。