《Show and Tell: A Neural Image Caption Generator》阅读笔记及相关知识
Image Caption 指的是自动从一张图片生成描述性语句,不仅能指出图片中包含的物体,而且能够表达图片中物体的相互关系、他们的属性以及他们共同参与的活动。
这有点类似于“看图说话”,但是对于机器来说却是一项很有挑战性的任务。因为机器不仅要能检查出图像中的物体,而且要理解物体之间的相互关系,最后还要用合理的语言表达出来。
Encoder - Decoder
在Image Caption中,使用到了encoder-decoder框架。Encoder - decoder模型解决了长度不一致的映射问题,它的结构如下图所示。
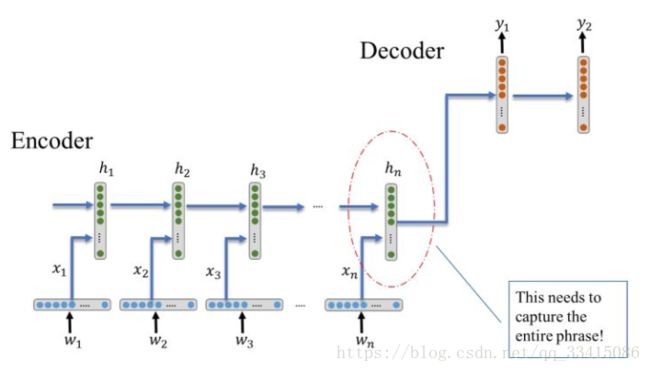
w1,w2,w3,...,wn w 1 , w 2 , w 3 , . . . , w n 是输入序列,而 y1,y2,y3,...,yn y 1 , y 2 , y 3 , . . . , y n 是输出序列。 h1,h2,h3,...,hn h 1 , h 2 , h 3 , . . . , h n 表示RNN的隐层状态(hidded state)。
Encoder
将所有的输入 w1,w2,w3,...,wn w 1 , w 2 , w 3 , . . . , w n 编码成一个古松的向量表示,即最后一个隐层状态h_{n}。将 w1,w2,w3,...,wn w 1 , w 2 , w 3 , . . . , w n 转换成 x1,x2,x3,...,xn x 1 , x 2 , x 3 , . . . , x n 也是其中的一个环节,称为word embedding。我们认为h_{n}包含了原始输入中所有的有效信息。
Decoder
进一步利用h_{n},进行“解码”,输出合适的单词序列 y1,y2,y3,...,yn y 1 , y 2 , y 3 , . . . , y n 。是以,我们完成了输入序列以及输出序列之间的转换工作。
Neural Image Caption
在Image Caption任务中,输入的是图像,输出的是单词序列。基于Encode - Decoder上,利用图像中使用的CNN作为Encoder,提取图像的视觉特征。使用性能更好的RNN作为Decoder,这样的模型称为NIC(Neural Image Caption),具体的结构如下图所示:

Example
使用的是网站pytorch-tutorial上的例子。
利用LSTM代替RNN网络,一个例子如下图所示:

训练阶段
在encoder部分,我们使用预先训练的CNN提取输入图片的特征向量。特征向量经过线性转换,维度与LSTM的输入唯独相同。在decoder部分,源文本和目标文本已经预先定义好的。如上述例子,如果图片的描述为“Giraffes atanding next to each other”,那么源序列和目标序列都包括[‘< start >’, ‘Giraffes’, ‘standing’, ‘next’, ‘to’, ‘each’, ‘other’]
测试阶段
Encoder部分与训练阶段基本相同,唯一的不同在于,batchnorm层采用了均值及方差移动,而不是最小块统计。然而decoder与训练阶段有明显差异。在测试阶段,LSTM decoder并不知道图片的描述。因此LSTM decoder利用之前的词生成下一个词。
Model
再次回到论文的内容。模型的任务如下:
Encoder: 将不同长度的输入转换成固定维度的向量
Decoder: Encoder的输出作为Decoder的输入,生成期望的序列。
提出了本文的模型:
* θ θ 是模型的参数
* I 是图像
* S是对应的翻译结果
在训练的时候,(S, I)是一个输入的pair,在全部的训练数据上,利用SGD(随机梯度下降法)来优化log概率和。
对于 p(St|I,S0,S1,...,St−1) p ( S t | I , S 0 , S 1 , . . . , S t − 1 ) ,我们采用RNN来建模。隐层的更新可以通过非线性函数f:
在本文中,我们采用LSTM网络作为f,而用CNN来表示图片。一个新颖之处在于:对于CNN模型,采用了BatchNorm。
LSTM-based Sentence Generator
LSTM的结构在另一篇博客中介绍了,详见RNN入门
LSTM的结构图如下图所示:
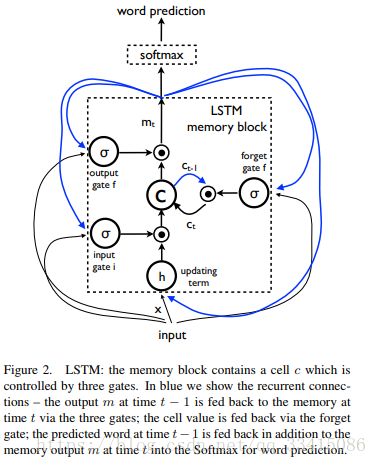
LSTM利用3个门来控制细胞状态。遗忘门(forget gate)来控制是否遗忘当前细胞的值,输入门(input gate)来控制是否读取细胞的输入,输出门(output gate)来控制是否新的细胞值。细胞状态更新以及输出如下所示:

“圈点”符号表示门的值相乘,W矩阵表示训练的参数。 σ σ (·) 表示sigmoid函数而h(·)表示双曲正切函数。 pt p t 是所有words上的概率分布输出。
Training

如果输入图片用I表示,图片的正确句子表述为 S=(S0,S1,...,SN) S = ( S 0 , S 1 , . . . , S N ) ,LSTM的展开过程为:
我们将 S0 S 0 设置为特殊开始word,将 SN S N 设置为特殊结束word。 We W e 是指word embedding。
Loss的计算如下所示:
调整LSTM网络、CNN网络的参数以及 We W e ,使得Loss的值最小。
Inference
利用NIC,对于给定图片生成sentence有几种不同的方式。
1. Sampling 采样
输入图片和起始标记 S0 S 0 后, 我们得到 p1 p 1 ,根据 p1 p 1 采样得到第一个word;将第一个word的embedding作为下一个的输入,得到 p2 p 2 ,再根据 p2 p 2 采样得到第二个word….以此类推,知道我们得到了结束标记 SN S N 或者达到了sentence指定的最大长度。
2. BeamSearch
本文采用BeamSearch的方法进行实验,beam的大小(k)设置为20。当beam的大小设置为1时,例如greedy search,会发现BLUE打分会平均低2个点。
Training Details
本文提出了解决过拟合问题的方法,例如采用预先训练的CNN网络来初始其权重(如:ImageNet数据集)。这确实带来了分数的提高。也尝试使用其他数据集训练的结果来初始化 We W e (word embedding),但是没有什么效果。最后,尝试dropout和ensembling模型,其结果给改善了BLUE分数。
因此,除了CNN外,其他参数均为随机初始化。训练所有参数时,都采用固定的学习率,且采用SGD进行优化。Embedding 和 LSTM memory均为512维。图片的描述也进行了预处理,训练集保留出现次数 ≥5 ≥ 5 的word