Python从零到就业
Python面向对象编程五步曲
- 基础阶段
-
- 01-Python的注释
- 02 乱码原因
- 02-Python变量
- 03-数据类型
- 04-数据类型转换
- 05-Python运算符
- 06-Python输入
- 07-Python输出
- 08-占位格式符(补充)
- 09-Python分支
- 10-Python循环(while)
- 11-Python循环(for)
- 12-Python循环打断
- 13-Python循环和分支的互相嵌套
- 14-Python pass语句
- 15-Python常用数据类型(数值)
- 16-Python常用数据类型(布尔)
- 17-Python常用数据类型(字符串)
- 18-Python常用数据类型(字符串函数操作)
- 19-Python常用数据类型(列表)
- 20-Python常用数据类型(元组)
- 21-Python常用数据类型(字典)
- 待更新
基础阶段
01-Python的注释
- 什么是注释?
一段文字性的描述 - 注释的特性?
(1)、当程序被处理的时候,这些注释会被自动忽略。
(2)、不会被当做代码处理 - 注释应用场景:
(1)、帮助我们自己理清楚代码逻辑
(2)、与别人合作开发时,添加注释,可以减少沟通成本
(3)、开发模块的时候添加注释可以减少他人使用成本
(4)、可以临时注释一段代码, 方便调试 - 注释的分类:
#单行注释
'''
多行注释
'''
"""
多行注释
"""
特殊注释1:为了能够在linux下以./+文件名.py方式运行代码,需要在py文件中添加
#!/usr/bin/python
#!/usr/bin/env python
特殊注释2:以什么编码方式解析文件,python2默认不支持中文,需要加上;python3直接中文支持,不需要加
# encoding=utf-8
# coding=utf-8
正规的Python推荐写法:# _*_ coding:utf-8 _*_
02 乱码原因
字符编码规定了:
(1)按照怎样的规范把字符转换成数字?
(2)按照怎样的方式存储数字(如: 用多少个字节?)
在将字符存储到内存时就会面临两个问题:
(1)编码:按照什么规范将字符转换成0-1二进制进行存储
(2)解码:按照什么规范将存储的0-1二进制转换成字符
正是解码和编码这两个过程不统一,才会导致读取的文件发生乱码。
为什么有这么多字符码?
- 一开始英语主要包括26个字母(大小写)、10个数字、标点符号、控制符等等的编码关系,最终就制定了ASCII字符编码, 映射了字符和字符码的关系, 并使用一个字节的后七位(0 - 127)来存储
- 随着计算机的普及,对ASCII码进行了扩展,叫 EASCII编码; 还是一个字节, 从128 – 255;
- 后来, 由国际标准化组织(ISO) 以及国际电工委员会(IEC)联合制定了一个标准 ISO/8859-1(Latin-1), 继承了CP437的128-159; 重新定义了160-255;
- 到了中国,自己搞了一个GB2312来存储中文, 6763个汉字;(双字节, 兼容ASCII);GB2312之上的扩充即GBK,包含了繁体字, 藏文, 蒙文等等。
- 为了统一各国编码,统一联盟国际组织, 提出了Unicode编码; 涵盖了世界上所有的文字, 每一个字符都有对应的唯一一个字符码
02-Python变量
1. 怎样定义变量:
- 方式1:
变量名 = 值
a = 2
print(a)#输出 2
- 方式2:
变量名1,变量名2 = 值1,值2
a,b = 1,2
print(a,b) #输出:1 2
- 方式3:
变量名1 = 变量名2 = 值
a = b = 2
print(a,b)输出:2 2
2. 为什么要产生变量
- 方便维护,使用变量来维护一系列值
- 节省空间,缩小源码文件占比,节省磁盘空间
03-数据类型
1. 为什么要区分数据类型?
- 区分存储空间,为不同的数据类型分配不同大小的存储空间
- 赋值语句a=2,该赋值语句会开辟一段存储空间,并将该存储空间的唯一标识返回给 a a a,以后就可以通过 a a a来找到这一段存储空间。
- 赋值语句将 2 2 2赋值给 a a a,那么会分配 4 4 4字节的空间去存储该数字,可以有效的避免存储空间的浪费。
- 根据不同数据类型的特性,做不同的数据处理
#例如,根据不通的数据类型进行不同的+操作
print(6+6)#输出:12
print("6"+"6")#输出:66
2.数据类型:
| 常用数据类型 | 例子 |
|---|---|
| Numbers(数值类型) | i n t 、 l o n g 、 f l o a t 、 c o m p l e x int、long、float、complex int、long、float、complex |
| Bool(布尔类型) | T r u e 、 F a l s e True、False True、False |
| String(字符串) | ′ s t r ′ 、 ′ ′ ′ s t r ′ ′ ′ 、 " s t r " 、 " " " s t r " " " 'str'、'''str'''、"str"、"""str""" ′str′、′′′str′′′、"str"、"""str""" |
| List(列表) | [ 1 , 2 , 3 ] [1,2,3] [1,2,3] |
| Set(集合) | [ s e t ( [ 1 , 2 ] ) [set([1, 2]) [set([1,2]) |
| Tuple(元组) | ( " 小王 " , 18 ) ) ("小王", 18)) ("小王",18)) |
| Dictory(字典) | n a m e : " 王顺子 " , a g e : 18 {name: "王顺子", age: 18} name:"王顺子",age:18 |
| NoneType(空类型) | N o n e None None |
P y t h o n 3 Python3 Python3无 l o n g long long类型,会自动根据数值大小,调整 i n t int int字节长度
3. 查看类型:
t y p e ( ) type() type()
num = 6
print(type(num))#这个类型是属于数值的,不是属于变量的。type会根据num的引用找到数值所在地,然后输出该数值的类型。
04-数据类型转换
1. 概念:
将一个数据转换成指定的类型, 方便处理
2.应用场景举例:
银行存钱:
money = input("输入你要存储的金额")
total_money = 20+ money
此时就会报错:
TypeError: unsupported operand type(s) for +: 'int' and 'str'
因为 i n t int int类型的20不能和 S t r i n g String String类型的 m o n e y money money进行相加。
因此,需要进行数据转换。
3.方式:
将 m o n e y money money改成 i n t int int类型:
i n t ( ) int() int()方法
money = input("输入你要存储的金额")
total_money = 20+ int(money)
其余类型转化函数如下:
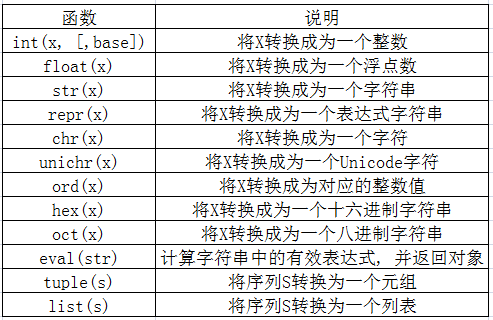
4. 面试补充 \color{red}{4.面试补充} 4.面试补充
- 动态类型/静态类型:
- 静态类型:类型是编译的时候确定的,后期无法修改
- 如 J A V A JAVA JAVA中的数据类型, i n t a = 2 int a=2 inta=2,在编译时就已经确定 a a a的类型是 i n t int int了;
- 动态类型:类型是运行时进行判定的, 可以动态修改
- 如 P y t h o n Python Python中的数据类型, a = 2 a=2 a=2,在运行时才会确定 a a a的类型是 i n t int int;且可以在后续运行中进行修改;
- 静态类型:类型是编译的时候确定的,后期无法修改
- 强类型/弱类型
- 强类型:类型比较强势, 不轻易随着环境的变化而变化。
- P y t h o n Python Python就是强类型语言,如 p r i n t ( " a " + 1 ) print("a"+1) print("a"+1)在运行时会报错, P y t h o n Python Python不会将 1 1 1转为 s t r i n g string string类型;
- 弱类型:类型比较柔弱, 不同的环境下, 很容易被改变。
- J a v a Java Java就是弱类型语言,如 S y s t e m . o u t . p r i n t ( " a " + 1 ) System.out.print("a"+1) System.out.print("a"+1)在运行时不会报错,输出 " a 1 " "a1" "a1", J a v a Java Java会将 1 1 1转为 s t r i n g string string类型再进行运算;
- 强类型:类型比较强势, 不轻易随着环境的变化而变化。
05-Python运算符
1.算数运算符:
| 算数运算符 | 名称 |
|---|---|
| + | 加法运算符 |
| - | 减法运算符 |
| * | 乘法运算符 |
| ** | 幂运算符 |
| / | 除法运算符 |
| // | 整除运算符 |
| % | 求模运算符 |
| = | 赋值运算符 |
扩展:
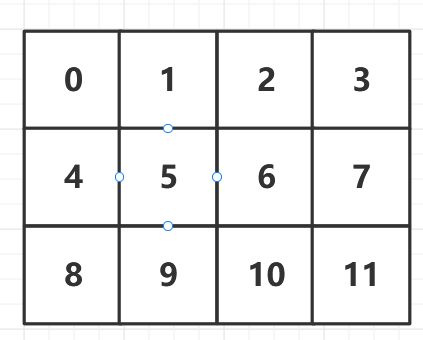
整除和求余的应用场景:
假设存在一个数组,序号如下所示。
以序号 9 9 9的元素为例子,
获取 9 9 9的行号:9//4=2,即第2行
获取 9 9 9的列号:9%4=1,即第1列
2.复合运算符:
| 复合运算符 | |
|---|---|
| += | a + = b → a = a + b a+=b→a=a+b a+=b→a=a+b |
| -= | a − = b → a = a − b a-=b→a=a-b a−=b→a=a−b |
| *= | a ∗ = b → a = a ∗ b a*=b→a=a*b a∗=b→a=a∗b |
| **= | a ∗ ∗ = b → a = a ∗ ∗ b a**=b→a=a**b a∗∗=b→a=a∗∗b |
| /= | a / = b → a = a / b a/=b→a=a/b a/=b→a=a/b |
| //= | a / / = b → a = a / / b a//=b→a=a//b a//=b→a=a//b |
| %= | a % = b → a = a % b a\%=b→a=a\%b a%=b→a=a%b |
3.比较运算符:
| 比较运算符 | |
|---|---|
| > | 是否大于 |
| < | 是否小于 |
| != | 是否不等于 |
| <> | P y t h o n 2. Python 2. Python2.的不等于, 3.0 3.0 3.0版本不支持 |
| >= | 是否大于等于 |
| <= | 是否小于等于 |
| == | 是否等于 |
| is | 对比唯一标识 |
| 链状比较运算符 | 10 < a < = 66 10 |
关于 i s : is: is:
这里对比的是唯一标识,
如,赋值语句 a = 10 a=10 a=10,此时会开辟一段存储空间,并将存储空间的唯一标识返回给 a a a。
i s is is比较的就是上述的唯一标识,可以理解为存储地址。
如下图:
这里 a a a和 b b b相等的原因是,它们值相等,为了提高性能, P y t h o n Python Python将这两个变量分配了相同的唯一标识
==比较的是只,is比较的是唯一标识


4.逻辑运算符:
| 逻辑运算符 | |
|---|---|
| not | 非,取反 |
| and | 与(二元运算符) |
| or | 是否不等于 |
-
非布尔类型的值, 如果作为真假来判定, 一般都是非零即真, 非空即真。
-
整个逻辑表达式的结果不一定只是 T r u e True True和 F a l s e False False。
print(3 and 0) #输出 0
#上式bool值为False,输出为0标识走到0这才判断为False的
if 3 or 1:
print(3 or 1)#输出为3
#上式bool值为True,输出为3标识走到3这就能判断为True
#上面的3为非空,也不是0,所以布尔值为True
#为空,布尔值为False
print(bool(""))#输出为False
06-Python输入
1. python2中:
在 P y t h o n 2 Python2 Python2中有两个输入函数:
- r a w _ i n p u t ( ) raw\_input() raw_input()
- 使用格式:
result = raw_input('提示信息') - 功能:
- 会等待用户输入内容,直到用户按下 E n t e r Enter Enter
- 会将用户输入的内容当做"字符串",传递给接收的变量
- 使用格式:
- i n p u t ( ) input() input()
- 使用格式:
result = input('提示信息') - 功能:
- 会等待用户输入内容,直到用户按下 E n t e r Enter Enter
- 会将用户输入的内容当做“代码”进行处理!
- 使用格式:
例子:
# _*_ coding:utf-8 _*_
#Python2环境下
result = raw_input('提示信息')#输入:1+1
print type(result)#输出:2. python3中
在 P y t h o n 3 Python3 Python3中有一个输入函数:
- i n p u t ( ) input() input()
- 相当于 P y t h o n 2 Python2 Python2中的 r a w _ i n p u t ( ) raw\_input() raw_input()
- 格式:
result = input('提示信息') - 功能:
- 会等待用户输入内容,直到用户按下 E n t e r Enter Enter
- 会将用户输入的内容当做"字符串",传递给接收的变量

07-Python输出
Python2:
- print语句:
print xxx
print 123 #输出:123
Python3:
- printh函数:
print(values,sep,end,file,flush)- values:需要输出的值;多个值之间使用","进行分割
- sep:分割符;多个值, 被输出出来之后, 值与值之间, 会添加指定的分隔符
- end:输出完毕之后, 以指定的字符, 结束;默认是换行 ‘\n’
- file:表示输出的目标;
- 默认是标准的输出(控制台):
file=sys.stdout - 还可以是一个可写入的文件句柄:
f = open("xxx", "w");
file=f
- 默认是标准的输出(控制台):
- flush:表示立即输出的意思;
- 需要输出的内容, 是先存放在缓冲区, 然后再输出到目标
- flush, 就代表是否刷新缓冲区,让缓冲区的内容,立即输出到目标
- flush值为Bool类型,默认为False
使用场景:
-
输出一个值:
- Python2.x:
print 值 - Python3.x:
print(值)
- Python2.x:
-
输出一个变量:
- Python2.x:
print 变量名 - Python3.x:
print(变量名)
- Python2.x:
-
输出多个变量:
- Python2.x:
print 变量名1, 变量名2 - Python3.x:
print(变量名1, 变量名2)
- Python2.x:
-
格式化输出:
- Python2.x:
- %写法:
print "随意内容...占位符1, ... , 占位符2, ..."%(变量1, 变量2)print "我的名字是%s,年龄是%d"%("小王",12)
- format写法:
- print “随意内容…{索引}, … , {索引}, …”.format(值1, 值2)
print "我的名字是{0},年龄是{1}".format("小王",12)
- %写法:
- Python3.x:
- %写法:
print("随意内容...占位符1, ... , 占位符2, ..."%(变量1, 变量2))
- format写法:
- print “随意内容…{索引}, … , {索引}, …”.format(值1, 值2)

- %写法:
- Python2.x:
-
输出到文件中:
- Python2.x:
file = open("test.txt","w")
print>>file,"who am i" - Python3.x:
file = open("test.txt","w")
print("who am i",file=file)
- Python2.x:
-
输出不自动换行
- Python2.x:
print a. - Python3.x:
print("hello",end="")
- Python2.x:
-
输出的各个数据,使用分割符分割
print("hello","world",sep="---")
08-占位格式符(补充)
格式:
%[(name)][flags][width][.precision]typecode
中括号[]包含的部分表示是可选的,即可省略的。
-
(name):用于选择指定的名称对应的值
即根据key获取具体值;print("数学分数是%(math)d,英语分数是%(Eng)d" % {"Eng":60,"math":59})

- 当使用(name)时,后面带的是一个字典。好处在于可以摆脱原来的按序赋值
-
width:表示显示宽度
print("%4d" % (59))

输出的宽度为4,前面带有两个空格。默认是右对齐
-
flags:
-
空:表示右对齐
-
- :表示左对齐
print("%-4d|" % (59))

-
空格:表示在左侧填充一个空格
- 应用场景:在正数的左侧填充一个空格,从而与负数对齐
print("|% d" % (59))

-
0:表示使用0填充
print("%04d" % (59))

-
-
.precision:表示小数点后精度
print("%.2f" % (59.99999))

typeCode:
-
i/d
将整数、浮点数转换成十进制表示,并将其格式化到指定位置
- 将二进制转成十进制输出:
print("%d" % (0b1001)) -
o
将整数转换成八进制表示,并将其格式化到指定位置 -
x
将整数转换成十六进制表示,并将其格式化到指定位置 -
e/E
将整数、浮点数转换成科学计数法,并将其格式化到指定位置(e/E输出的是小写/大写的e/E)print("%E" % (10000))

-
f/F
将整数、浮点数转换成浮点数表示,并将其格式化到指定位置(默认保留小数点后6位) -
g/G
自动调整将整数、浮点数转换成浮点型或科学计数法表示(超过6位数用科学计数法),并将其格式化到指定位置(如果是科学计数则是e/E;)print("%g" % (100000)); print("%g" % 20)

-
c
将数字转换成其unicode对应的值,10进制范围为 0 < = i < = 1114111 0<=i<=1114111 0<=i<=1114111(py27则只支持0-255);print("%c" % 26666)

-
特殊:%
想输出90%之类的加载值时,需要输入两个%,第一个%充当转义符print("%d%%" % 30)

09-Python分支
单分支判断:
格式:
if 条件:
当条件满足,执行语句
实例:
age=int(input("请输入年龄"))
if age>=18:
print("你已成年")
双分支判断:
格式:
if 条件:
条件满足时,执行语句
else:
条件不满足时,执行语句
实例:
age=int(input("请输入年龄"))
if age>=18:
print("你已成年")
else:
print("未满18岁")
练习案例:
根据分数区间, 打印出对应的级别
- 大于等于90 并且 小于等于100
输出优秀 - 大于等于80 并且 小于90
输出良好 - 大于等于60 并且 小于80
输出及格 - 大于等于0 并且 小于60
输出不及格
score = int(input("请输入成绩"))
if 90<=score<=100:
print("优秀")
if 80<=score<90:
print("良好")
if 60<=score<80:
print("及格")
if 0<=score<60:
print("不及格")
上述案例中,输入的成绩只会满足其中一个分支条件。但是在实际运行时,每个分支都会进行判断,导致效率低下。
可以考虑使用if嵌套:
格式:
if 条件1:
条件满足时,执行语句
else:
#执行条件2判断
if 条件2:
条件满足时,执行语句
else:
……
实例:
score = int(input("请输入成绩"))
if 90<=score<=100:
print("优秀")
else:
if 80<=score<90:
print("良好")
else:
if 60<=score<80:
print("及格")
else:
print("不及格")
多分支判断:
格式:
if 条件1:
满足条件1,执行语句
elif 条件2:
满足条件2,执行语句
else:
都不满足,执行语句
案例:
score = int(input("请输入成绩"))
if 90<=score<=100:
print("优秀")
elif 80<=score<90:
print("良好")
elif 60<=score<80:
print("及格")
else:
print("不及格")
注意
- t a b 缩进 \color{red}{tab缩进} tab缩进:
其他语言会根据大括号{}来识别代码块,但Python中没有{}语法。
Python会根据缩进来识别代码块
如下面的两个分支语句,其中的else处于不同的缩进状态;第一个分支语句的else属于分支2的if,第二个分支语句的else属于分支1的if。
if 分支1判断条件:
if 分支2判断条件:
执行语句
else:
执行语句
if 分支1判断条件:
if 分支2判断条件:
执行语句
else:
执行语句
- 不建议写嵌套层级太深的代码
- Python中没有类似于其他语言中的swith…case语法
10-Python循环(while)
使用场景:
- 想要多次重复执行某些操作的时候
- 想要遍历一个集合的时候
while循环
格式:
while 条件:
条件满足时执行代码
- 条件满足时, 才会执行循环体内部代码
- 循环体内部代码被执行完毕后, 会继续下次条件判断, 确定是否需要继续执行循环体代码
- 直到条件不满足时, 才会结束这次循环, 继续往下执行后续代码
流程图:

实例:
打印某句话10遍:
num = 0
while num<10:
num+=1
print(num,"打印10遍")
计算1-10数值的总和
num = ans = 0
while num<10:
num+=1
ans+=num
print(ans)
while else
格式:
while 条件:
满足条件时
else :
条件不满足时,执行的代码
- 能够顺利执行完毕, 才会执行else
- 否则不会(使用了break)
流程图:

实例:
num = ans = 0
while num<10:
num+=1
ans+=num
else:
print(ans)#输出55
注意
- 一定注意循环结束条件, 防止死循环
- 在Python中, 没有类似于其他语言的do…while循环
11-Python循环(for)
使用场景:
- 重复性的执行一些操作
- 更多的是遍历一个集合(字符串、列表)
语法:
for x in xxx:
循环语句
- xxx通常是一个集合
- x:
- 会取出集合中的每个元素,赋值给x
- 在循环体中, 可以直接使用x的值
- 当集合中的元素被遍历完毕,循环 就会结束
通常搭配range(n)函数使用,range(n)会生成0~n-1的整数列表
案例:
str = "abcdefg"
for s in str:
print(s)
'''
输出:
a
b
c
d
e
f
g
'''
for i in range(10):
print(i)
'''
输出:
0
1
2
3
4
5
6
7
8
9
'''
for与else连用:
格式:
for x in xxx:
条件满足时的执行代码
else:
条件不满足时执行的语句
- 如果for循环可以顺利的执行完毕,则会执行else
- 反之,使用了break则不会
案例:字符串反转:
str1 = "abcdefg"
str2 = ""
for s in str:
str2 = s+str2
else:
print(str2)#输出:gfedcba
12-Python循环打断
循环打断,会对while和for与else的连用产生影响:
- 如果循环正常执行完毕, 则会执行else部分
- 如果中途是因为打断而退出循环, 则不会执行else部分
break:
打断本次循环, 跳出整个循环
如下,当i==2时执行break语句;break语句中断本次循环并跳出当前循环
for i in range(10):
if i==2:
break;
print(i)
'''
0
1
'''
注意:break只会跳出一层循环
for j in range(2):
for i in range(10):
if i==2:
break;
print(i)
'''
输出:
0
1
0
1
'''
continue:
结束本次循环, 继续执行下次循环
for i in range(10):
if i==2:
continue
print(i)
'''
输出:(没有2了)
0
1
3
4
5
6
7
8
9
'''
13-Python循环和分支的互相嵌套
循环内嵌套循环和循环内嵌套if,其本质就是只要是代码,都能放在代码块的位置。
for x in xxx:
这个缩进开始就是一个代码块;
可以放if语句,也可以放循环语句
案例:打印1-100之间, 所有3的倍数
for i in range(1,101):
if i%3==0:
print(i)
案例:打印九九乘法表
外层循环每循环一次,内层循环就要循环一遍
for num in range(1,10):
for n in range(1,num+1):
print("%d * %d = %d" % (num,n,num*n),end='\t')
print("")
'''
1 * 1 = 1
2 * 1 = 2 2 * 2 = 4
3 * 1 = 3 3 * 2 = 6 3 * 3 = 9
4 * 1 = 4 4 * 2 = 8 4 * 3 = 12 4 * 4 = 16
5 * 1 = 5 5 * 2 = 10 5 * 3 = 15 5 * 4 = 20 5 * 5 = 25
6 * 1 = 6 6 * 2 = 12 6 * 3 = 18 6 * 4 = 24 6 * 5 = 30 6 * 6 = 36
7 * 1 = 7 7 * 2 = 14 7 * 3 = 21 7 * 4 = 28 7 * 5 = 35 7 * 6 = 42 7 * 7 = 49
8 * 1 = 8 8 * 2 = 16 8 * 3 = 24 8 * 4 = 32 8 * 5 = 40 8 * 6 = 48 8 * 7 = 56 8 * 8 = 64
9 * 1 = 9 9 * 2 = 18 9 * 3 = 27 9 * 4 = 36 9 * 5 = 45 9 * 6 = 54 9 * 7 = 63 9 * 8 = 72 9 * 9 = 81
'''
14-Python pass语句
概念:
pass是空语句,不做任何事情,一般用做占位语句。
作用:
是为了保持程序结构的完整性
如下面代码,并没有想好年龄大于18和小于18时要进行什么操作,但是该程序的框架就是这样。为了避免运行报错,可以使用pass代替具体的操作,等后续在用具体操作替代pass。
age = 18
if age>=18:
pass
else:
pass
15-Python常用数据类型(数值)
表现形式:
- 整数(int):
- P y t h o n 3 的整型 , 可以自动的调整大小 , 当做 L o n g 类型使用 \color{red}{Python3的整型, 可以自动的调整大小, 当做Long类型使用} Python3的整型,可以自动的调整大小,当做Long类型使用
- 二进制
0b+二进制数 - 八进制
0o+八进制数 - 十进制 0-9
- 十六进制
0x+十六进制数
- 浮点数(float):
- 由整数部分和小数部分组成:168.2
- 可以使用科学计数法表示:
1.682e2
- 复数(complex):
- 由实部和虚部组成
- complex(a, b)=a+bj
- a,b都是浮点数
常用操作:
-
内置数学函数: 内置数学函数: 内置数学函数:
-
abs(num)
返回数字的绝对值

-
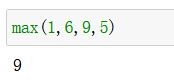
max(num1, num2…)
返回序列中的最大元素
-
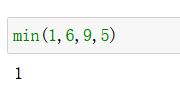
min(num1, num2…)
返回序列中的最小元素
-
round(num[, n])
四舍五入;n是可省参数,标识四舍五入的位数

-
pow(x, y)
返回 x 的 y次幂,即x**y

-
-
m a t h 函数模块 math函数模块 math函数模块
-
ceil(num)
上取整

-
floor(num)
下取整

-
sqrt(num)
开平方

-
log(x,base)
开平方
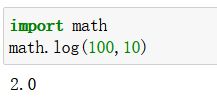
-
-
r a n d o m 模块的随机函数 random模块的随机函数 random模块的随机函数
- random()
输出[0,1)范围之内的随机小数 - choice(seq)
从一个序列中, 随机挑选一个数值 - uniform(x, y)
[x,y]范围之内的随机小数 - randint(x, y)
[x,y]范围之内的随机整数 - randrange(start, stop=None, step=1)
[start, stop)区间内的一随机整数,sep代表隔取值间隔
- random()
-
m a t h 模块的三角函数 math模块的三角函数 math模块的三角函数
-
sin(x)
正弦,x是弧度 -
cos(x)
余弦,x是弧度 -
tan(x)
正切,x是弧度 -
asin(x)
反正弦,x是弧度 -
acos(x)
反余弦,x是弧度 -
atan(x)
反正切,x是弧度 -
degrees(x)
弧度 转换成 角度 -
radians(x)
角度 转换成 弧度
-
-
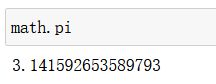
数学常量 数学常量 数学常量
math.pi
16-Python常用数据类型(布尔)
-
b o o l bool bool分为: T r u e True True和 F a l s e False False,布尔类型是 i n t int int类型的子类:
-
bool的False可以当做0与数值类型相加:
-
bool的True可以当作1与数值类型相加:



17-Python常用数据类型(字符串)
概念:
由单个字符组成的一个集合
形式:
-
非原始字符串:
- 使用单引号包含的:
'abc' - 使用双引号包含的:
"abc" - 使用3个单引号:
'''abc''' - 使用3个双引号:
"""abc"""-
混合使用可以避免使用引号转义符
-
一般内容需要写成一行,跨行需要连行符\ 或者使用 小括号

-
三引号可以直接跨行书写,可用于注释
-
- 使用单引号包含的:
-
原始字符串:
(原始字符串内部不会识别转义符)- 使用单引号包含的:
r'abc' - 使用双引号包含的:
r"abc" - 使用3个单引号:
r'''abc''' - 使用3个双引号:
r"""abc"""
- 使用单引号包含的:
-
概念补充(转义符):
- 概念:
通过转换某个指定的字符, 使它具备特殊的含义 - 常见转义符:
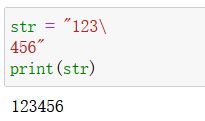
-
\(在行尾时) 续行符
-
\’ 单引号

-
\" 双引号

-
\n 换行

-
\t 横向制表符

-
- 概念:
字符串一般操作:
- 字符串拼接
-
方式1: s t r + s t r 2 str+str2 str+str2

-
方式2: s t r 1 s t r 2 str1str2 str1str2

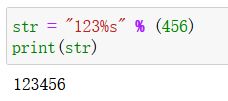
-
方式3:“xxx%sxxx”%(abc)
-
方式4:字符串乘法

-
字符串切片
-
概念:
获取一个字符串的某个片段 -
获取某个字符:
name[下标]- 下标的取值如下所示,从前往后是从0~1;从后往前是从-1~-7

- 案例:
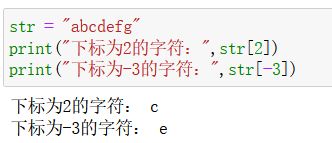
- 下标的取值如下所示,从前往后是从0~1;从后往前是从-1~-7
-
获取一个字符型片段:
name[起始:结束:步长]-
获取范围:
[起始,结束);起始包含,结束不包含 -
默认值:
- 起始默认值:0
- 结束默认值:len(name),即整个字符串的长度
- 步长默认值:1
-
获取顺序:
- 步长>0,从左往右
- 步长<0,从右往左
- 注意:注意: 不能从头部跳到尾部, 或者从尾部跳到头部(否则输出空串)
- 案例:


-
18-Python常用数据类型(字符串函数操作)
查找操作
-
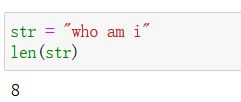
l e n len len:
- Python内置函数,直接使用
- 作用:计算字符串的字符个数
- 语法:len(str)
- 参数:字符串
- 返回值:表示字符个数的整型
- 实例:
-
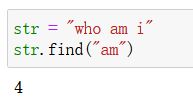
f i n d find find:
- 作用:查找子串索引位置
- 语法:find(sub, start=0, end=len(str))
- 参数:
sub:需要检索的字符串
start:检索的起始位置,可省略, 默认0
end:检索的结束位置,可省略, 默认len(str)
查找区间:[start,end)左开右闭 - 返回值:
若找到了,返回子串在字符中出现的索引位置(整型)
若找不到,返回整型-1 - 注意:
从左到右进行查找,找到后立即停止 - 实例:
-
r f i n d rfind rfind
- 功能使用, 同 f i n d find find
- 区别:从右往左进行查找
- 实例:

-
i n d e x index index
- 作用:获取子串索引位置
- 语法:index(sub, start=0, end=len(str))
- 参数
sub:需要检索的字符串
start:检索的起始位置,可省略, 默认0
end:检索的结束位置,可省略, 默认len(str)
查找区间:[start,end) - 返回值:
找到了返回指定索引(整型)
找不到,抛出异常 - 注意:
从左到右进行查找,找到后立即停止
-
r i n d e x rindex rindex
- 功能:使用同index
- 区别:从右往左进行查找
- 实例:

转换
-
c o u n t count count:
- 作用:计算某个子字符串的出现个数
- 语法:count(sub, start=0, end=len(str))
- 参数:
sub:需要检索的字符串
start:检索的起始位置,可省略, 默认0
end:检索的结束位置,可省略, 默认len(str) - 返回值:
子字符串出现的个数(整型) - 实例:

-
r e p l a c e replace replace:
- 作用:使用给定的新字符串替换原字符串中的旧字符串
- 语法:replace(old, new[, count])
- 参数:
old:需要被替换的旧字符串
new:替换后的新字符串
count:替换的个数,可省略, 表示替换全部 - 返回值:替换后的结果字符串
- 注意:并不会修改原字符串本身
- 实例:

-
c a p i t a l i z e capitalize capitalize:
- 作用:将字符串首字母变为大写
- 语法:capitalize()
- 参数:无
- 返回值:
首字符大写后的新字符串 - 注意:
并不会修改原字符串本身;
对于非小写字母开头的字符串不会发生改变 - 实例:

-
t i t l e title title:
- 作用:将字符串每个单词的首字母变为大写
- 语法:title()
- 参数:无
- 返回值:
每个单词首字符大写后的新字符串 - 注意:
并不会修改原字符串本身 - 实例:

-
l o w e r lower lower
- 作用:将字符串每个字符都变为小写
- 语法:title()
- 参数:无
- 返回值:
全部变为小写后的新字符串 - 注意:
并不会修改原字符串本身 - 实例:

-
u p p e r upper upper:
- 作用:将字符串每个字符都变为大写
- 语法:upper()
- 参数:无
- 返回值:
全部变为大写后的新字符串 - 注意:
并不会修改原字符串本身 - 实例:

填充压缩
-
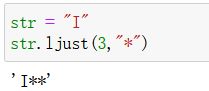
l j u s t ljust ljust:
- 作用:根据指定字符(
长度只能为1), 将原字符串填充够指定长度 - l j u s t ljust ljust的 l l l:表示原字符串靠左
- 语法:ljust(width, fillchar)
- 参数
width:指定结果字符串的长度
fillchar:填充的字符 - 返回值:
填充完毕的结果字符串 - 注意:
不会修改原字符串;
填充字符的长度为1;
只有原字符串长度 < 指定结果长度时才会填充; - 实例:
- 作用:根据指定字符(
-
r j u s t rjust rjust:
- 作用:根据指定字符(
长度只能为1), 将原字符串填充够指定长度 - r j u s t rjust rjust的 r r r:表示原字符串靠右
- 语法:rjust(width, fillchar)
- 参数:
width:指定结果字符串的长度
fillchar:填充的字符 - 返回值:
填充完毕的结果字符串 - 注意:
不会修改原字符串;
填充字符的长度为1;
只有原字符串长度 < 指定结果长度时才会填充; - 实例:

- 作用:根据指定字符(
-
c e n t e r center center:
- 作用:根据指定字符(
长度只能为1), 将原字符串填充够指定长度 - center:表示原字符串居中
- 语法:center(width, fillchar)
- 参数:
width:指定结果字符串的长度
fillchar:填充的字符 - 返回值:
填充完毕的结果字符串 - 注意:
不会修改原字符串;
填充字符的长度为1;
只有原字符串长度 < 指定结果长度时才会填充;
若不能放置在正中间,右边填充的字符会多一个。 - 实例:

- 作用:根据指定字符(
-
l s t r i p lstrip lstrip:
- 作用:移除所有原字符串指定字符(默认为空白字符)。从左端开始,碰到第一个不存在指定字符的就停止移除。
- l s t r i p lstrip lstrip的 l l l:表示从左侧开始移除
- 语法:lstrip(chars)
- 参数:
chars:需要移除的字符集,表现形式为字符串。如"abc"表示,“a”|“b”|“c” - 返回值:
移除完毕的结果字符串 - 注意:
不会修改原字符串 - 实例:

-
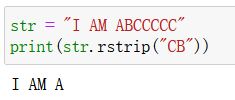
r s t r i p rstrip rstrip:
- 作用:移除所有原字符串指定字符(默认为空白字符)。从右端开始,碰到第一个不存在指定字符的就停止移除。
- r s t r i p rstrip rstrip的 r r r:表示从右侧开始移除
- 语法:rstrip(chars)
- 参数:
chars:需要移除的字符集,表现形式为字符串 - 返回值:
移除完毕的结果字符串 - 注意:
不会修改原字符串 - 实例:
分割拼接
-
s p l i t split split:
-
作用:将一个大的字符串分割成几个子字符串
-
语法:split(sep, maxsplit)
-
参数:
sep:分隔符
maxsplit:最大的分割次数(分割次数,而分割结果字符数);可省略, 有多少分割多少 -
返回值:
分割后的子字符串, 组成的列表(list 列表类型) -
注意
并不会修改原字符串本身 -
实例:

-
-
p a r t i t i o n partition partition:
- 作用:根据指定的分隔符, 返回(分隔符左侧内容, 分隔符, 分隔符右侧内容)
- 语法:partition(sep)
- 参数:
sep:分隔符 - 返回值:
如果查找到分隔符(返回tuple 类型):(分隔符左侧内容, 分隔符, 分隔符右侧内容)
如果没有查找到分隔符(返回tuple 类型):(原字符串, “”, “”) - 注意:
不会修改原字符串;
从左侧开始查找分隔符; - 实例:

-
r p a r t i t i o n rpartition rpartition:
- 作用:根据指定的分隔符, 返回(分隔符左侧内容, 分隔符, 分隔符右侧内容)
- r p a r t i t i o n rpartition rpartition的 r r r:表示从右侧开始查找分隔符
- 语法:partition(sep)
- 参数:
sep:分隔符 - 返回值:
如果查找到分隔符(返回tuple 类型):(分隔符左侧内容, 分隔符, 分隔符右侧内容)
如果没有查找到分隔符(返回tuple 类型):(原字符串, “”, “”) - 注意:
不会修改原字符串;
从右侧开始查找分隔符; - 实例:

-
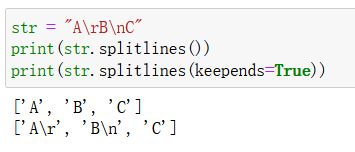
s p l i t l i n e s splitlines splitlines:
- 作用:按照换行符(\r, \n), 将字符串拆成多个元素, 保存到列表中
- 语法:splitlines(keepends)
- 参数:
keepends(bool 类型):是否保留换行符 - 返回值:
被换行符分割的多个字符串, 作为元素组成的列表(list 类型) - 注意:
不会修改原字符串 - 实例:
-
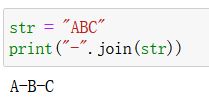
j o i n join join:
- 作用:根据指定字符串, 将给定的可迭代对象, 进行拼接, 得到拼接后的字符串
- 语法:join(iterable)
- 参数
iterable:可迭代的对象(字符串,元组,列表) - 返回值:
拼接好的新字符串 - 实例:
判定
-
i s a l p h a isalpha isalpha:
- 作用:字符串中是否所有的字符都是字母。
- 语法:isalpha()
- 参数:无
- 返回值:
是否全是字母(返回bool 类型) - 实例:

-
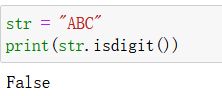
i s d i g i t isdigit isdigit:
- 作用:字符串中是否所有的字符都是数字
- 语法:isdigit()
- 参数:无
- 返回值:
是否全是数字(返回bool 类型) - 实例:
-
i s a l n u m isalnum isalnum:
- 作用:字符串中是否所有的字符都是数字或者字母
- 语法:isalnum()
- 参数:无
- 返回值:
是否全是数字或者字母(返回bool 类型) - 实例:

-
i s s p a c e isspace isspace:
- 作用:字符串中是否所有的字符都是空白符(包括空格,缩进,换行等不可见转义符,至少有一个字符)
- 语法:isspace():无
- 返回值:是否全是空白符(返回bool 类型)
- 实例:

-
s t a r t s w i t h startswith startswith:
- 作用:判定一个字符串是否以某个前缀开头
- 语法:startswith(prefix, start=0, end=len(str))
- 参数:
prefix:需要判定的前缀字符串
start:判定起始位置
end:判定结束位置 - 返回值:
是否以指定前缀开头(返回bool 类型) - 实例:

-
e n d s w i t h endswith endswith:
- 作用:判定一个字符串是否以某个后缀结尾
- 语法:endswith(suffix, start=0, end=len(str))
- 参数:
suffix:需要判定的后缀字符串
start:判定起始位置
end:判定结束位置 - 返回值:
是否以指定后缀结尾(返回bool 类型) - 实例:

-
补充
-
i n in in
判定一个字符串, 是否被另外一个字符串包含- 实例:
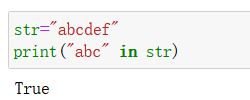
- 实例:
-
n o t i n not\ in not in
判定一个字符串, 是否不被另外一个字符串包含- 实例:

- 实例:
-
19-Python常用数据类型(列表)
列表概念:
有序的可变的元素集合
列表定义方式:
-
方式一:
[元素1,元素2,…]- 实例:

- 实例:
-
方式二:
- 列表生成式:
-
r a n g e ( s t o p ) range(stop) range(stop)
- 实例:

- 注意:
为了防止生成的列表没有被使用,python3做了一些改变,不会立即生成列表。即使用的时候才会生成列表,第一个输出的nums的值range(0,10),此时未生成列表。
- 实例:
-
r a n g e ( s t a r t , s t o p , [ , s t e p ] ) range(start,stop,[,step]) range(start,stop,[,step])
-
参数:
start:开始的数值
stop:结束的数值
step:步长;可省参数。 -
实例:

-
注意:
为了防止生成的列表没有被使用,python3做了一些改变,不会立即生成列表。即使用的时候才会生成列表,第一个输出的nums的值range(0,10),此时未生成列表。
-
-
- 列表推导式:从一个list,推导出另一个表达式
-
[表达式 for 变量 in 列表]
- 实例:
目标:将某一列表中的元都进行平方得到另一个新列表
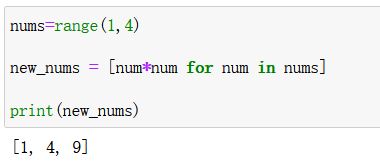
解析:

- 实例:
-
[表达式 for 变量 in 列表 if条件]
- 实例:

满足if条件的num才会进行表达式操作并作为新元素加入新列表
- 实例:
-
- 列表生成式:
列表的嵌套
与java和c++的数组不同,python的列表可以存放不同的数据类型,存放的元素也可以是一个列表。

常规操作
增
-
a p p e n d append append:
- 作用:
往列表的末端, 追加一个新的元素 - 语法:
l.append(object) - 参数:
object:想要添加的元素 - 返回值:
None - 注意:
会直接修改原数组 - 实例:

- 作用:
-
i n s e r t insert insert:
- 作用:
往列表中, 在指定索引前面追加一个新的元素 - 语法:
l.insert(index, object) - 参数:
index:索引, 插入到这个索引之前
object:想要添加的元素 - 返回值:
None - 注意:
会直接修改原数组 - 实例:

- 作用:
-
e x t e n d extend extend:
- 作用:
往列表中, 扩展另外一个可迭代序列 - 语法:
l.extend(iterable) - 参数:
iterable:可迭代集合(字符串、列表、元组) - 返回值:
None - 注意
会直接修改原数组 - 和append之间的区别:
extend可以算是两个集合的拼接
append是把一个元素, 追加到一个集合中 - 实例:

- 作用:
-
乘法运算:

-
加法运算:

- 和extend区别:
只能列表类型和列表类型相加
- 和extend区别:
删:
-
d e l del del语句:
- 作用:
可以删除一个指定元素(对象) - 语法
del 指定元素 - 注意
可以删除整个列表,或者删除一个变量,也可以删除某个元素
删除变量del会删除 - 实例:

- 作用:
-
p o p pop pop:
- 作用
移除并返回列表中指定索引对应元素 - 语法
l.pop(index=-1) - 参数
index:需要被删除返回的元素索引,默认是-1,即列表最后一个元素 - 返回值:
被删除的元素 - 注意:
会直接修改原数组;
注意索引越界,越界会报错; - 实例:

- 作用
-
r e m o v e remove remove:
-
作用:
移除列表中指定元素 -
语法:
l.remove(object) -
参数:
object:需要被删除的元素 -
返回值:
None -
注意:
会直接修改原数组- 如果元素不存在:会报错
- 若果存在多个元素:则只会删除最左边一个
-
实例:

-
一个小坑:
注意循环内删除列表元素带来的坑
如列表元素为[2,2,4,2],要求删除列表中所有的2

使用循环的方式会出现错误,如上图。
原因:
遍历开始时遍历指针指向的索引为0的位置,因为是2所以将最左边的2删除。
之后遍历指针后移指向索引为1的位置,而此时因为列表首元素删除了,索引索引为1的位置是元素4,次吃不会发生删除。
继续遍历遍历指针指向索引为2的位置,此时索引2的地方是列表最后面的2,所以此时if语句成立删除最左边的2。此时遍历结束退出循环。
-
改:
使用name[index]赋值即可。

查:
-
获取单个元素:items[index]
- 实例:

- 实例:
-
获取元素索引:index()
- 实例:

- 有相同元素,返回最左边元素的索引
- 实例:
-
获取指定元素个数:count()
- 实例:

- 实例:
-
获取多个元素:切片 items[start :end :step]
- 实例:

- 实例:
遍历:
-
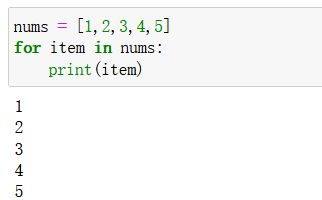
方式1:根据元素进行遍历
for item in list:print(item)- 实例
-
方式2:根据索引进行遍历
for index in range(len(list)): print(index, list[index])- 实例:

- 实例:
-
方式3:创建对应的枚举对象
- 概念:
通过枚举函数, 生成的一个新的对象 - 作用:
函数用于将一个可遍历的数据对象(如列表、元组或字符串)组合为一个索引序列
同时列出数据下标和数据 - 语法:
enumerate(sequence, [start=0]) - 参数:
sequence:一个序列、迭代器或其他支持迭代对象。
start:下标起始位置。 - 举例:

enumerate会将nums转换成列表里嵌套元组,元组包含索引和值:[(0,1),(1,2),(2,3),(3,4),(4,5)]
- 概念:
-
方式4:使用迭代器进行遍历
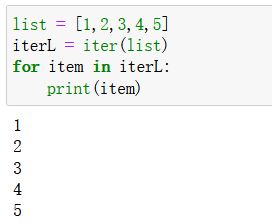
迭代器:
-
概念:
迭代是访问集合元素的一种方式,按照某种顺序逐个访问集合中的每一项。 -
可迭代对象:
能够被迭代的对象, 称为可迭代对象- 判定依据:
能作用于for in的即迭代器对象 - 判定方法
import collections
isinstance(obj, collections.Iterable) - 实例:

- 判定依据:
-
迭代器:
是可以记录遍历位置的对象。从第一个元素开始, 往后通过next()函数, 进行遍历。只能往后, 不能往前(有点类似获取数据库的next指针,依次向下获取)- 判定依据:
能作用于next()函数的就是迭代器 - 判定方法
import collections
isinstance(obj, collections.Iterator) - 注意
迭代器也是可迭代对象, 所以也可以作用于for in
- 判定依据:
-
为什么会产生迭代器?
- 仅仅在迭代到某个元素时才处理该元素
在此之前, 元素可以不存在
在此之后, 元素可以被销毁
特别适合用于遍历一些巨大的或是无限的集合 - 提供了一个统一的访问集合的接口
可以把所有的可迭代对象, 转换成迭代器进行使用
- 仅仅在迭代到某个元素时才处理该元素
-
迭代器的简单使用:
使用next()函数, 从迭代器中取出下一个对象, 从第1个元素开始。- 因为迭代器比较常用, 所以在Python中, 可以直接作用于for in
内部会自动调用迭代器对象的next(),会自动处理迭代完毕的错误 - 注意事项
当next()指向最后一个元素后,再次使用next()会报StopIteration错;
迭代器一般不能多次迭代。
- 因为迭代器比较常用, 所以在Python中, 可以直接作用于for in
额外操作:
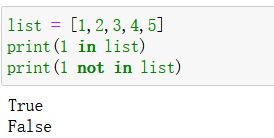
-
判定:
- 语法格式:
- 元素 in 列表
- 元素 not in 列表
- 实例:
- 语法格式:
-
比较:
-
c m p ( ) cmp() cmp():
python2.x中的内建函数。
如果比较的是列表, 则针对每个元素, 从左到右按字典序逐一比较- 当左 > 右,返回1
- 当左 == 右,返回0
- 当左 < 右,返回-1
-
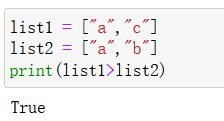
python3.x中直接使用比较符:>、<、=
针对每个元素, 从左到右逐一按字典序比较 -
实例:
第一个元素a相等,则比较第二个元素,c的字典序大于b所以list1大于list2
-
-
排序
-
方式1:
- 一个内建函数:
可以对所有可迭代对象进行排序 - 语法:
s o r t e d ( i t r e a r b l e , k e y = N o n e , r e v e r s e = F a l s e ) sorted(itrearble, key=None, reverse=False) sorted(itrearble,key=None,reverse=False) - 参数:
itrearble:可迭代对象
key:用于排序的关键字。
reverse:控制升序降序;默认False,表示升序 - 返回值:
一个已经排好序的列表 - 实例:

- 一个内建函数:
-
方式2:
- 一个列表对象方法
- 语法:
l i s t . s o r t ( k e y = N o n e , r e v e r s e = F a l s e ) list.sort(key=None, reverse=False) list.sort(key=None,reverse=False) - 参数:
key:用于排序关键字
reverse:控制升序降序;默认False,表示升序 - 返回值:
无 - 与内置函数sorted()的区别:
- sorted()不改变原数组,而是返回一个排好序的结果列表

- sort()会改变原数组,且没有返回值

- sorted()不改变原数组,而是返回一个排好序的结果列表
-
-
乱序:
随机打乱一个列表- 语法:
导入random模块
import random
random.shuffle(list) - 实例:

- 注意:
该方法没有返回值,且会改变原列表
- 语法:
-
反转
-
方式一:
- 语法:
l . r e v e r s e ( ) l.reverse() l.reverse() - 返回值:
无 - 实例

- 语法:
-
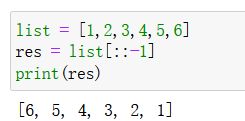
方式二:切片反转
- 语法:l[::-1]
- 实例:
-
20-Python常用数据类型(元组)
元组概念:
有序的不可变的元素集合。
有序:可按索引查询元素
不可变:没有增删改操作
和列表的区别就是, 元组元素不能修改
定义方式:
一个元素的写法: ( 元素 , ) (元素,) (元素,)
a = (1)#会把括号识别成运算优先符
print(a,type(a))#输出:1 多个元素的写法:
a=(1,2,3)
print(a,type(a)) #输出:(1, 2, 3) 多个对象,以逗号隔开,默认为元组
a= 1 ,2 , "SZ"
print(a,type(a))#输出:(1, 2, 'SZ') 从列表转换成元组
内置函数: t u p l e ( s e q ) tuple(seq) tuple(seq)
l= [1 ,2 , "SZ"]
t = tuple(l)
print(t,type(t))#输出:(1, 2, 'SZ') 常用操作:
无增、删、改
- 查:
-
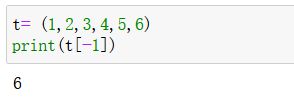
获取单个元素: t u p l e [ i n d e x ] tuple[index] tuple[index]
- index 为索引,可以为负
- 例子:
-
获取多个元素:
- 方式:切片
t u p l e [ s t a r t : e n d : s t e p ] tuple[start: end: step] tuple[start:end:step] - 实例:

- 方式:切片
-
额外操作:
-
获取:
-
t u p l e . c o u n t ( i t e m ) tuple.count(item) tuple.count(item):
统计元组中指定元素的个数(对象函数)- 实例:

- 实例:
-
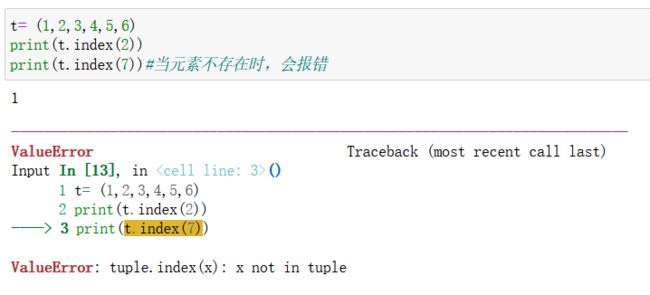
t u p l e . i n d e x ( i t e m ) tuple.index(item) tuple.index(item):
获取元组中指定元素的索引(对象函数)- 实例:
- 实例:
-
l e n ( t u p ) len(tup) len(tup):
返回元组中元素的个数(内置函数)- 实例:

- 实例:
-
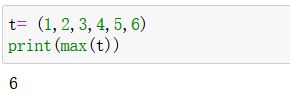
m a x ( t u p ) max(tup) max(tup):
返回元组中元素最大的值(内置函数)- 实例:
- 实例:
-
m i n ( t u p ) min(tup) min(tup):
返回元组中元素最小的值(内置函数)
-
-
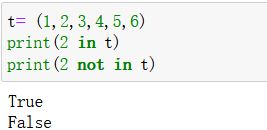
判定:
- 元素 in 元组
元素 not in 元组 - 实例:
- 元素 in 元组
-
比较
- c m p ( ) cmp() cmp():
python2.x中的内建函数。
如果比较的是列表, 则针对每个元素, 从左到右按字典序逐一比较- 当左 > 右,返回1
- 当左 == 右,返回0
- 当左 < 右,返回-1
- python3.x中直接使用比较符:>、<、=
针对每个元素, 从左到右逐一按字典序比较
比较运算符- 实例:

- 实例:
- c m p ( ) cmp() cmp():
-
拼接:
-
乘法:
(元素1, 元素2…) * int类型数值=(元素1, 元素2…, 元素1, 元素2…, …)- 实例:

- 实例:
-
加法
(元素1, 元素2) + (元素a, 元素b)= (元素1, 元素2, 元素a, 元素b)- 实例:

- 实例:
-
-
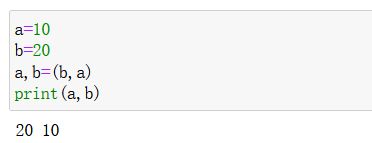
拆包:
-
实例:

-
a,b = 1,2,对于这条赋值语句,可以理解成将1,2构建成一个元组,再拆包分别赋值给a,b -
应用:交换元素的值
-
21-Python常用数据类型(字典)
字典概念:
无序的,可变的键值对集合
定义方式:
方式一: { k e y : v a l u e , k e y : v a l u e . . . } \{key: value, key: value...\} {key:value,key:value...}
d = {"name":"小王","age":18}
print(d,type(d))
#输出:{'name': '小王', 'age': 18} 方式二: f r o m k e y s ( s e q , v a l u e = N o n e ) fromkeys(seq, value=None) fromkeys(seq,value=None)
该方法是一个静态方法:即类和对象都可以调用
参数:
- s e q seq seq:可遍历序列
- v a l u e value value:需要赋的 v a l u e value value值,默认为 N o n e None None
#类调用(推荐使用)
d = dict.fromkeys("abc",666)
print(d,type(d))
#输出:{'a': 666, 'b': 666, 'c': 666} 注意:
- k e y key key不能重复:
如果重复,后面的值会把前值给覆盖
d = {"name":"小王","age":18,"name":"小红"}
print(d)#小红将前面的小王覆盖掉了
#输出:{'name': '小红', 'age': 18}
- k e y key key必须是任何不可变的类型
可变类型有:字典、列表、可变集合
不可变类型有:数值、布尔、字符串、元组
判断是否是可变类型的一个方法:
看下面的代码,首先将 a a a赋值为 10 10 10。这时候会在内存中开辟一块空间存放数字 10 10 10,并将这块空间的首地址返回给 a a a,所以当前 a a a指向存储数字 10 10 10的这块空间的地址。
之后将 a a a赋值为 20 20 20。这时候并不会去修改 a a a指向的这块地址空间。而是重新开辟一块地址空间去存储 20 20 20,将这块新开辟的地址空间返回给 a a a,则 a a a当下指向存储数字 20 20 20的空间地址。
入下面代码前后两次 i d ( a ) id(a) id(a)的值是不一样的,当出现这种情况,就可以说数值是一个不可变的类型。
a = 10
print(a,id(a))#输出:10 2363066772048
a=20
print(a,id(a))#输出:20 2363066772368
相反,如下代码。对列表进行插入操作后。 l l l并不会改变地址指向,插入的操作会在 l l l指向的地址上进行修改。
所以可以判断列表是一个可变类型。
l = [1,2,3]
print(l,id(l))#输出:[1, 2, 3] 2363180690560
l.append(4)
print(l,id(l))#输出:[1, 2, 3, 4] 2363180690560
字典的存储和查找流程:
Python的字典,采用哈希 h a s h hash hash的方式实现
简单的存储过程:
- 首先初始化一个表格,用来存放所有的值。
这个表格称为"哈希表" - 在存储一个键值对的时候, 会作如下操作:
- 根据给定的key, 通过某些操作, 得到一个在"哈希表"中的索引位置。【即将 k e y key key通过哈希函数映射到一个地址空间】
- 如果产生了"哈希冲突",则采用"开发寻址法",通过探测函数查找下一个空位。
- 根据索引位置, 存储给定的"值"【将 v a l u e value value存储到这个地址空间】
简单的查找过程:
- 再次使用哈希函数将key转换为对应的列表的索引,并定位到列表的位置获取value
字典类型存在的意义:
- 可以通过key, 访问对应的值, 使得这种访问更具意义。【相比列表的list[index]方式更有逻辑上的意义】
- 查询效率得到很大提升。【直接将 k e y key key通过哈希函数映射,就能获得地址】
常用操作:
增: d i c [ k e y ] = v a l u e dic[key] = value dic[key]=value
当key在原字典中不存在时, 即为新增操作
d = {"name":"小王"}
d["age"]=18#新增操作
print(d)#输出:{'name': '小王', 'age': 18}
删:
方式一: d e l d i c [ k e y ] del dic[key] deldic[key]
k e y key key必须要存在,否则会报 k e y E r r o r keyError keyError
d = {"name":"小王","age":18}
del d["name"]#删除操作
print(d)#{'age': 18}
方式二: d i c . p o p ( k e y [ , d e f a u l t ] ) dic.pop(key[, default]) dic.pop(key[,default])
- 删除指定的键值对, 并返回对应的值。
- 如果key, 不存在, 那么直接返回给定的default值; 不作删除动作
- 如果key,不存在,且没有给定默认值, 则报 k e y E r r o r keyError keyError错
d = {"name":"小王","age":18}
v = d.pop("name",666)#删除操作,并返回删除得value
print(v,d)#小王 {'age': 18}
d = {"name":"小王","age":18}
v = d.pop("A",666)#key不存在,则返回默认值666
print(v,d)#输出:666 {'name': '小王', 'age': 18}
方式三: d i c . p o p i t e m ( ) dic.popitem() dic.popitem()
删除字典的最后一个键值对,并以元组的形式返回该键值对。如果字典为空, 则报错
d = {"name":"小王","age":18}
v = d.popitem()#删除最后一个键值对:("age",18)
print(v,d)#('age', 18) {'name': '小王'}
方式四: d i c . c l e a r ( ) dic.clear() dic.clear()
删除字典内所有键值对,并返回 N o n e None None
d = {"name":"小王","age":18}
print(d.clear(),d)#输出:None {}
d i c . c l e a r ( ) dic.clear() dic.clear()与 d e l del del的区别:
d i c . c l e a r ( ) dic.clear() dic.clear()后字典对象本身还存在, 只不过内容被清空;而 d e l del del将该字典的内存给释放了,字典对象不存在了。
改:
只能改值,不能改key
- 修改单个键值对: d i c [ k e y ] = v a l u e dic[key] = value dic[key]=value
- 直接设置, 如果key不存在, 则新增, 存在则修改
d = {"name":"小王","age":18}
d["name"]="小红"
print(d)#{'name': '小红', 'age': 18}
- 批量修改键值对: o l d D i c . u p d a t e ( n e w D i c ) oldDic.update(newDic) oldDic.update(newDic)
- 根据新的字典, 批量更新旧字典中的键值对
- 如果旧字典没有对应的key, 则新增键值对
d = {"name":"小王","age":18}
d.update({"name":"小红","age":20,"h":180})
print(d)#{'name': '小红', 'age': 20, 'h': 180}
查:
获取单个值:
- 方式一: d i c [ k e y ] dic[key] dic[key]
如果key, 不存在, 会报错 - 方式二: d i c . g e t ( k e y [ , d e f a u l t ] ) dic.get(key[, default]) dic.get(key[,default])
- 如果不存在对应的key, 则取给定的默认值default;
- 如果没有默认值, 则为None;但不会报错,但是, 原字典不会新增这个键值对
- 方式三: d i c . s e t d e f a u l t ( k e y [ , d e f a u l t ] ) dic.setdefault(key[,default]) dic.setdefault(key[,default])
- 获取指定key对应的值
- 如果key不存在, 则返回默认值,如果默认值没给定,则使用None代替;最后将该键值对添加到字典中
d = {"name":"小王","age":18}
#方式一
print(d["name"])
#输出:小王
#方式二
print(d.get("name",666))
#输出:小王
print(d.get("h",666),d)#若没有该key,原字典不会新增这个键值对
#输出:666 {'name': '小王', 'age': 18}
#方式三
print(d.setdefault("name",666))
#输出:小王
print(d.setdefault("h",666),d)#若没有key,将其加入到字典中
#输出:666 {'name': '小王', 'age': 18, 'h': 666}
- 获取所有的值: d i c . v a l u e s ( ) dic.values() dic.values()
- 获取所有的键: d i c . k e y s ( ) dic.keys() dic.keys()
- 获取字典的键值对: d i c . i t e m s ( ) dic.items() dic.items()
d = {"name":"小王","age":18}
#获取所有的值
print(d.values())#dict_values(['小王', 18])
#获取所有的键
print(d.keys())#dict_keys(['name', 'age'])
#获取字典的键值对
print(d.items())#dict_items([('name', '小王'), ('age', 18)])
注意:在Python3.x 中是上述三个函数返回的是 D i c t i o n a r y v i e w o b j e c t s Dictionary\ view\ objects Dictionary view objects类型,而不是一个列表。即比能通过索引值来获取元素,如下面的代码:
d = {"name":"小王","age":18}
#获取所有的值
v = d.values()
print(v[0])#报错:'dict_values' object is not subscriptable
D i c t i o n a r y v i e w o b j e c t s Dictionary\ view\ objects Dictionary view objects类型的好处:
- 当字典发生改变时, view objects会跟着发生改变
- 可以转换成列表使用
- 可以转换成迭代器使用
- 也可以直接被遍历
d = {"name":"小王","age":18}
v = d.items()
print(v)#输出:dict_items([('name', '小王'), ('age', 18)])
#字典更新后,view objects会跟着发生改变
d["h"]=180
print(v)#输出:dict_items([('name', '小王'), ('age', 18), ('h', 180)])
#可以转成列表使用
l = list(v)
print(l[0])#输出:('name', '小王')
#可以使用for in进行遍历
for k,v in v: #注意:v是链表包含若干元组,索引可以使用拆包简化赋值
print(k,v)
'''
输出:
name 小王
age 18
h 180
'''
计算: l e n ( i n f o ) len(info) len(info)
键值对的个数
d = {"name":"小王","age":18}
print(len(d))#输出:2
判定
- x i n d i c x\ in\ dic x in dic:
判定dic中的key, 是否存在x - x n o t i n d i c x\ not\ in\ dic x not in dic:
判定dic中的key, 是否不存在x - d i c . h a s _ k e y ( k e y ) dic.has\_key(key) dic.has_key(key):
已过期, 建议使用in来代替。Python3中已经不存在该方法
d = {"name":"小王","age":18}
print("name" in d)#输出:True