Python数据分析5——数据清洗
目录
Python数据清洗
数据清洗介绍
处理缺失值
判断数据是否为NaN
过滤缺失值
补全缺失值
异常值
处理重复数据
判断重复值
删除重复值
离散化
向量化字符串函数
Python数据清洗
数据清洗介绍
数据清洗实际上也是数据质量分析,检查原始数据中是否存在脏数据(不符合要求,或者不能直接进行分析的数据),并且处理脏数据。
常见情况如下
- 缺失值
- 异常值
- 重复数据
处理缺失值
Pandas使用浮点值NaN(not a Number)表示缺失值,并且缺失值在数据中时常出现。那么Pandas的目的之一就是"无痛地"处理缺失值。
判断数据是否为NaN
- pd.isnull(df) 返回哪些值是缺失值的布尔值
- pd.notnull(df) 返回值是isnull的反集
注意
- Python内建的None值也被当作NaN
过滤缺失值
- dropna(axis=0,how='any',inplace=False)
-
- axis 指定轴 默认为0 代表行
- how 默认为any 代表删除含有NaN的行 当为all 时代表删除所有值为NaN的行
- inplace 修改被调用的对象 而不是一个备份
补全缺失值
- df.fillna(value=None,method=None,axis=None,inplace=False,limit=None)
-
- value 标量或字典对象用于填充缺失值
- method 插值方法 默认为"ffill"
- axis 需填充的轴 默认为0
- inplace 修改被调用的对象 而不是一个备份
- limit 用于向前或向后填充时最大的填充范围
异常值
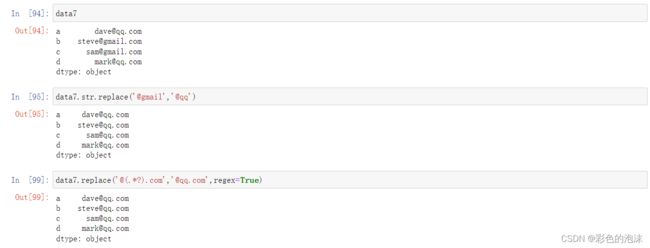
脏数据也包含不符合要求的数据,那么对这块数据处理不能直接使用fillna填充。使用replace更加灵活。
- df.replace(to_replace=None,value=None)
-
- to_replace 去替换的值
- value 替换的值
处理重复数据
判断重复值
- df.duplicated(subset=None, keep='first') 返回的一个布尔值Series 默认反映的是每一行是否与之前出现过的行相同
-
- subset 指定子列判断重复
- keep 默认为first保留首个出现的 last保留最后出现的
删除重复值
- df.drop_duplicates(),返回的是DataFrame 默认删除重复行
-
- subset 指定的数据任何子集是否有重复
- keep 默认为first保留首个出现的 last保留最后出现的
离散化
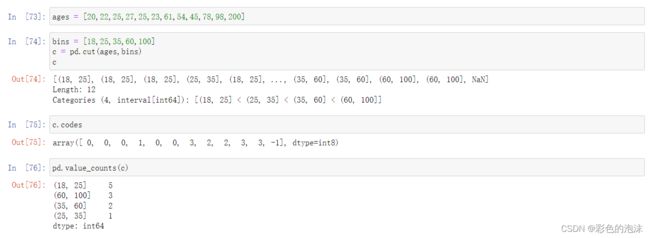
离散化是把无限空间中有限的个体映射到有限的空间中去,以此提高算法的时空效率。
可以简单的理解为离散化就是将连续值进行分区间。
- pd.cut(x,bins) 将连续数据x进行离散化
-
- x 要进行离散化的数据
- bins 分组
- pd.value_counts(cates) 统计每个区间的数值分布
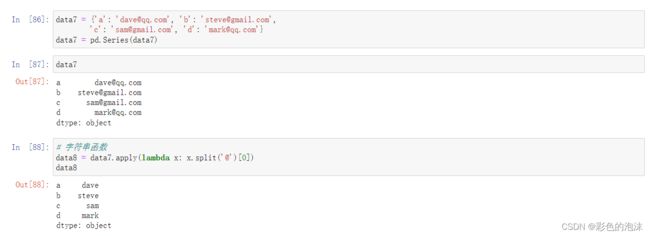
向量化字符串函数
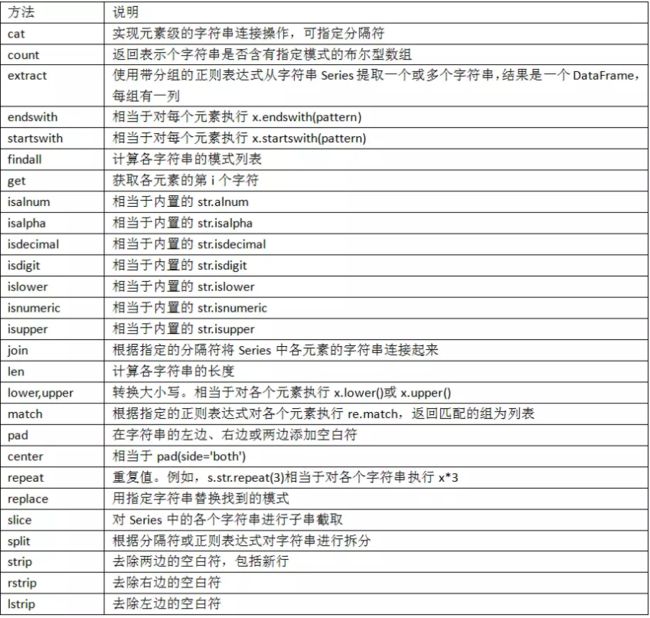
使用例子:
(可以结合正则使用)