PicoDet论文译读笔记
PP-PicoDet: A Better Real-Time Object Detector on Mobile Devices
摘要
在目标检测中如何实现更好的精度-速度均衡是一个具有挑战性的问题。在本文中,作者致力于目标检测中关键组件的优化和神经网络架构的选择,以提升精度和效率。本文探索了anchor-free侧路在轻量级目标检测模型上的应用。本文增强了主干网络的结构;设计了neck部分的轻量型结构,此结果可以提升网络的特征提取能力。本文改进了标签分配策略(label assignment strategy)以及损失函数,使得训练更加得稳定高效。通过这些优化策略,本文创造出新型的实时目标检测器系列,命名为PP-PicoDet,此模型在移动设备上的目标检测实现了卓越的性能。与其它常见的模型相比,PicoDet实现了更好的速度和时延之间的均衡。PicoDet-S使用仅0.99M参数实现30.6%-mAP,与YOLOX-Nano相比,在mAP上具有4.8%的绝对值提升,同时在移动CPU推理时延下降55%;与NanoDet相比,在mAP上具有7.1%的绝对值提升。PicoDet在移动端ARM-CPU上达到了123-FPS(使用Paddle-Lite达到150-FPS),输入图像尺寸为320。PicoDet-S使用仅3.3M参数实现40.9%-mAP,与YOLOv5s相比,在mAP上具有3.7%的绝对值提升,且速度加快44%。代码和预训练模型开源在PaddleDetection仓库。
1 引言
如图1所示,PicoDet模型在轻量级目标检测中远远优于最先进的结果。
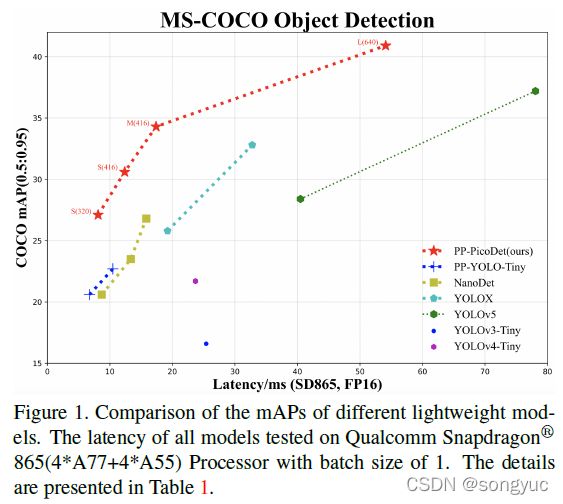
目标检测被广泛应用于许许多多的计算机视觉任务中,包括自动驾驶、机器视觉、智能交通、工业质量检测和目标跟踪等。Two-stage模型常常具有更好的性能;然而,这类资源较高的网络常常会限制其在实际场景中的应用。为了克服这个问题,轻量级移动端目标检测模型已经吸引了越来越多研究者的兴趣,致力于设计更加高效的检测方法。现今YOLO系列【1_YOLOv3, 2_YOLOv4, 3_YOLOv5, 4_YOLOX】的目标检测方法变得十分流行,因为它们很好地考虑了资源的限制。相较于two-stage模型,YOLO系列模型具有更好的效率和较高的精度。然而,YOLO系列模型无法解决下面提到的这些问题:1)需要小心对锚框进行重新设计来适应于不同的数据集。2)正样本和负样本之间的不平衡问题,因为大多数生成的锚框都是负样本。
近些年来,许多工作致力于发展更加高效的检测架构,例如anchor-free的检测器。FCOS【5_FCOS】解决了 GT labels之间重合的问题。相较于其它的anchor-free检测方法,FCOS不需要复杂的超参数调整。然而,大多数anchor-free模型都是用于大规模服务器的模型。有少数方法如NanoDet和YOLOX-Nano【4_YOLOX】既是anchor-free也是移动端的检测模型。其中的问题是轻量级anchor-free模型常常难以实现精度和效率之间的平衡。因此在本文中,受到FCOS和GFL【7_GFL】的启发,本文提出一种移动端友好且高效的anchor-free检测模型,命名为PP-PicoDet。总的来说,本文的主要贡献如下:
- 本文使用CSP(Cross Stage Partial)结构来构建CSP-PAN作为neck部分。CSP-PAN用 1 × 1 1\times1 1×1卷积将neck所有分支的输入通道数全部统一为相同的通道数(96),从而能够有效的增强网络的特征提取能力,且减少网络参数。本文还将 3 × 3 3\times3 3×3可分离卷积增加到 5 × 5 5\times5 5×5可分离卷积(替换ShuffleNetv2中的Channel-Shuffle操作),从而增大感受野(reception field)。
- 标签分配策略(label assignment strategy)在目标检测中是十分重要的。本文使用SimOTA【4_YOLOX】动态标签分配策略,并优化了一些计算细节。具体来说,本文使用 Varifocal Loss (VFL)【8_VFNet】和 GIoU loss【9_DIoU】来计算代价矩阵(cost matrix),在降低效率的情况下提高了精度。
- ShuffleNetV2【10_ShuffleNetV2】是在移动端上计算高效。本文在此基础上改进了网络结构并提出了一种新的主干网络,称为 Enhanced ShuffleNet (ESNet),性能优于ShuffleNetV2。
- 本文提出一种改进的用于检测的 One-Shot Neural Architecture Search (NAS)方法,;来自动找到目标检测的最优架构。本文直接在检测数据集上训练超网络,从而显着节省计算量并优化检测性能。本文中NAS生成的模型实现了更好的效率精度均衡。
通过上述优化,本文提出了一系列大大超越轻量级SOTA结果的模型。如表1所示,
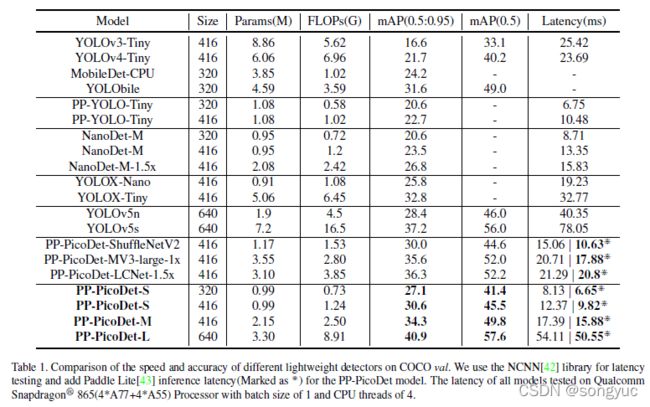
PicoDet-S以0.99M参数以及1.08G-FLOPs实现30.06%mAP。它在移动端ARM-CPU上实现了150FPS,输入尺寸为320。PicoDet-M在仅2.15M参数和2.5G-FLOPs的情况下实现34.3%mAP。PicoDet-L在仅3.3M参数和8.74G-FLOPs情况下实现40.9%mAP。本文提供了小、中、大三种模型来支持不同的部署场景。本文中所有的实验基于PaddlePaddle实现。代码和预训练模型可以在PaddleDetection【11_PaddleDetection】中获得。
2 相关工作
目标检测是计算机视觉中的经典任务,旨在图像和视频中识别出物体的类别和位置。现有的目标检测模型,可以分为两类:anchor-based检测器和anchor-free检测器。Two-stage检测器【12_FastRCNN, 13_SPPNet, 14_FasterRCNN, 15_FPN, 16_MaskRCNN, 17_CascadeRCNN】通常都是anchor-based,会从图像中产生region-proposals,并从region-proposals产生最终的定位框。为了提升目标定位的精度,FPN【15_FPN】会融合多尺度高层的语义特征。Two-stage检测器在目标定位上常常更加精确,然而很难在CPU或ARM设备上实现实时检测。一阶段检测器【18_SSD, 19_YOLO9000, 1_YOLOv3, 2_YOLOv4, 3_YOLOv5, 20_PPYOLO, 21_PPYOLOv2, 4_YOLOX】也是anchor-based的检测模型,在速度和精度间有着更好的平衡,因此被广泛应用于实际场景。SSD【18_SSD】,会检测多个尺度的目标,对小物体更加友好,但是精度不高。同时,YOLO系列(除了YOLOv1【22_YOLOv1】)在精度和速度上表现较好。然而,仍然无法解决本文在之前章节中分析的问题。
Anchor-free的检测器【23_Cornernet, 24_CenterKeypoint, 5_FCOS】旨在消除锚框,是目标检测研究中的重要进展。YOLOv1的主要思想是将图像分成多个网格,然后在物体中心点附近预测定位框。CornerNet【23_Cornernet】检测定位框的一对角点,因而不需要设计锚框作为先验框。CenterNet【25_CenterNet】去掉了左上角点和右下角点,直接检测中心点。FCOS【5_FCOS】首先以像素预测的方式重新构建模型,并提出“centerness”分支。Anchor-free检测器解决了一些anchor-based检测器存在的问题,降低了内存占用,并且对定位框的计算更加准确。
后来的工作从多个方面提升了检测器的性能。ATSS【26_ATSS】提出自适应的训练采样选择方法,根据目标的统计特征来自动选择正负样本。GFL(Generalized Focal Loss)去掉了FCOS中的“centerness”分支,并将质量估计合并到类别预测向量中(译者注:这里的“质量”也就是可信度的意思),来形成定位质量和分类的联合表示。
在移动端目标检测中,许多工作致力于实现更加准确高效的目标检测器。通过使用YOLOv4【2_YOLOv4】中的压缩-编译设计,YOLObile【27_YOLObile】在移动设备上实现了实时目标检测。PP-YOLO-Tiny【11_PaddleDetection】采用了MobileNetV3【28_MobileNetV3】的主干网络,以及基于PP-YOLO【 20_PPYOLO】的TinyFPN结构。NanoDet使用ShuffleNetV2【10_ShuffleNetV2】作为主干网络使模型更加轻量,并使用ATSS和GFL来提高精度。YOLOX-Nano是目前YOLOX【4_YOLOX】系列中最轻量的模型,使用动态标签分配策略SimOTA,在参数可接受的条件下实现最佳的性能。
手工设计模型严重依赖于专家知识和繁琐试验。近些年来,NAS在发现和优化网络架构上展示出令人欣喜的成果,例如:MobileNetV3、EfficientNet【29_EfficientNet】和MnasNet【30_MnasNet】。NAS因此成为生成具有更好效率-精度均衡检测器的绝佳选择。One-shot NAS方法通过共享同样的权重来节省计算资源。近些年来许多 One-shot NAS工作致力于图像分类,例如:ENAS【31_ENAS】和SMASH【32_SMASH】。根据我们所知,很少有工作将NAS用于目标检测的任务。NAS-FPN【33_NASFPN】搜索特征金字塔网络(FPN)。DetNas【34_DetNas】首先在ImageNet上训练超网主干,然而在COCO上对超网络进行微调。MobileDets【35_MobileDets】使用NAS并提出一种增强搜索空间系列模型,以在移动设备上实现更好的时延-精度均衡。
3 方法
在本章中,首先会介绍本文的设计思想和对更优主干网络的NAS搜索方法,这些会有助于提升精度和降低时延。之后,本文将提出对于neck和head模块的增强策略。最后,本文将描述使用的标签分类策略和其它用来提升性能的策略。
3.1 更好的主干网络
手工设计主干网络。基于大量实验,本文发现ShuffleNetV2在移动设备上比其它网络具有更好的鲁棒性。为了进一步提升ShuffleNetV2的性能,本文遵循PP-LCNet【36_PP-LCNet】的一些方法来增强网络结构,并构建了新的主干网络,称为ESNet(Enhanced ShuffleNet)。图3具体地描述了ESNet中的ES-Block。
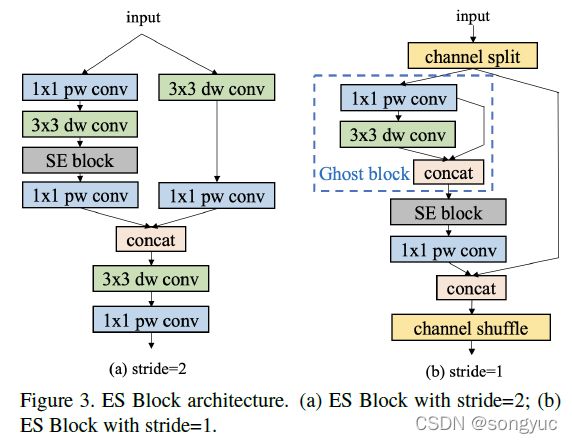
SE模块【37_SENet】能很好地对网络通道进行加权并获得更好的特征。因此,我们在所有blocks中加入了SE模块。类似于MobileNetV3,SE模块中两个layers的激活函数分别是ReLU和H-Sigmoid。Channel shuffle在ShuffleNetV2中提供了通道间的信息交换,但是也导致了特征融合的损失。为了解决这个问题,本文在stride为2时加入了 depthwise convolution和 pointwise convolution来结合不同通道的信息(图3a)。GhostNet【38_GhostNet】的作者提出了一种新型的Ghost模块能在较少参数量下产生更多特征图,从而提升网络的学习能力。本文在blocks中加入了Ghost模块并将stride设为1,来进一步增强ESNet的性能(图3b)。
Neural Architecture Search(NAS)。同时,本文提出首个针对目标检测器的one-shot搜索的工作。目标检测模型搭配在分类上高性能的主干网络,可能会因为不同任务间的差异而性能下降。本文没有去搜索一个较佳的分类器,而是在检测数据集上训练和搜索检测的超网络,从而介绍了大量计算并且达到检测而不是分类的最优。此框架仅需两步:(1)在检测数据集上训练one-shot超网,(2)使用EA(evolutionary algorithm,进化算法)算法对训练好的超网络进行架构搜索。
为了方便搜索,本文对主干网络仅使用channel-wise搜索。具体来说,本文给出了选择不同通道比率的弹性比率选项。本文会随机选择通道比率,粗略的选择范围是 [ 0.5 , 0.675 , 0.75 , 0.875 , 1 ] [0.5, 0.675, 0.75, 0.875, 1] [0.5,0.675,0.75,0.875,1]。举例来说,0.5表示宽度被调整为整个模型的0.5倍。通道数能被8整除,可以提高再硬件设备上的推理速度。因此,没有采取原始模型使用的通道数,本文首先对每个stage的block使用通道数 [ 128 , 256 , 512 ] [128, 256, 512] [128,256,512]来训练完整模型。所有的比率选项也会保持通道数为8的倍数。所选比率适用于每个块中的所有可修剪卷积。所有的输出通道都是固定的,与完整模型相同。为了避免繁琐的超参数调整,本文固定了所有在架构搜索中的原始设置。对于训练策略,本文采用了sandwich-rule,在每个训练迭代中,采样最大(full)和最小子模型以及六个随机子模型。训练策略中没有使用其它额外技术,如蒸馏,因为不同技术对不同模型的性能表现并不十分一致,尤其是对检测任务而言。最后,所选架构会在ImageNet数据集【39_ImageNet】上重新训练并在COCO【40_COCO】上微调训练。
3.2 CSP-PAN和 detector head
本文使用PAN【41_PAN】结构来获得多层特征图以及CSP结构来进行相邻特征图间的特征连接和融合。CSP结构被广泛用于YOLOv4【2_YOLOv4】和YOLOX【4_YOLOX】的neck部分。在原始的CSP-PAN中,每个输出特征图的通道数与来自主干网络的输入特征图保持相同。对于移动设备来说,这样大通道数的结构具有昂贵的计算成本。为了解决这个问题,本文用 1 × 1 1\times1 1×1卷积使所有特征图中的通道数与最小的通道数相等,(也就是都设为96)。通过CSP结构实现top-down和bottom-up的特征融合。缩小的特征使得计算成本更低且不损失准确性。此外,本文还在原有CSP-PAN的顶部加入了一个特征图尺度分支来检测更多物体。与此同时,所有除了 1 × 1 1\times1 1×1卷积外的卷积层都使用 Depthwise Separable Convolution。深度可分离卷积使用 5 × 5 5\times5 5×5卷积扩大感受野。这种结构在使用很少参数的情况下给精度带来了大幅度提升。模块的具体结构如图2所示。
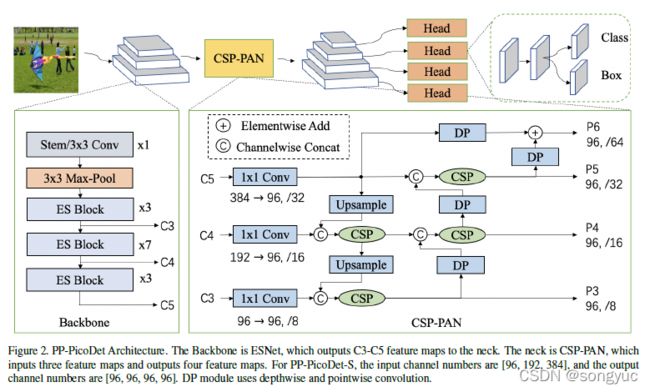
在检测头中,本文使用 Depthwise Separable Convolution和 5 × 5 5\times5 5×5卷积来扩大感受野。深度可分离卷积的数量可以被设置为2、4或更多。整体的网络结构如图2所示。Neck和head部分都有四个尺度分支。本文中head部分的通道数与neck部分保持一致,并将分类和回归分支耦合在一起。YOLOX【4_YOLOX】使用参数更少的解耦预测头来提高精度。本文中耦合预测头在没有降低通道数时表现更好。参数和推理速度与检测头解耦基本相同。
3.3 标签分配策略和损失函数
正负样本标签分配对目标检测模型有着本质的影响。大多数检测器使用fixed标签分配策略。这些策略十分简单。RetinaNet【44_RetinaNet&FocalLoss】直接用anchor跟真值的IoU来划分正负样本。FCOS【5_FCOS】将中心点在真值框内的anchors作为正样本,而YOLOv4【2_YOLOv4】和YOLOv5【3_YOLOv5】会将真值框中心点及其相邻的anchors都作为正样本。ATSS【26_ATSS】基于真值框最近anchors的统计特性来决定正负样本。上面提到的标签分配策略在整个训练过程中是保持不变的。SimOTA是一种会随着训练进程持续变化的标签分配策略,并且在YOLOX【4_YOLOX】中获得较好的效果。
本文使用SimOTA动态标签分配策来优化训练过程。SimOTA首先通过中心点先验信息决定候选区域,之后计算候选区内真值跟预测框的IoU,最后对每个真值框将n个最大的IoU求和获得参数 κ \kappa κ。通过直接计算候选区内所有预测框跟真值框的损失作为代价矩阵。对于每个真值框,选最小 κ \kappa κ损失对应的锚点作为正样本。原始SimOTA使用CE-Loss和IoU-Loss的加权和来计算代价矩阵。为了跟SimOTA中的代价矩阵和目标函数对齐,本文使用Varifocal-Loss和GIoU-Loss的加权和作为代价矩阵。GIoU-loss的权重为 λ \lambda λ,这里设置为6,因为实验显示此设置是最好的。具体的公式为
c o s t = l o s s v f l + λ ⋅ l o s s g i o u cost = loss_{vfl}+\lambda\cdot loss_{giou} cost=lossvfl+λ⋅lossgiou
在检测head中,对于分类,本文使用Varifocal-Loss来耦合分类预测和置信度预测。对于回归,本文使用GIoU-Loss和Distribution-Focal-Loss。其公式如下:
l o s s = l o s s v f l + 2 ⋅ l o s s g i o u + 0.25 ⋅ l o s s d f l loss=loss_{vfl}+2\cdot loss_{giou} + 0.25\cdot loss_{dfl} loss=lossvfl+2⋅lossgiou+0.25⋅lossdfl
在以上所有公式中, l o s s v f l loss_{vfl} lossvfl指Varifocal-Loss, l o s s g i o u loss_{giou} lossgiou指GIoU-loss, l o s s d f l loss_{dfl} lossdfl指Distribution-Focal-Loss。
3.4 其它策略
近年来出现了越来越多超越ReLU的激活函数。在这些激活函数中,H-Swish,一种简化版的Swish函数,计算更快并且对移动端更友好。本文将检测器中的激活函数从ReLU替换为H-Swish。在保持推理时延不变的情况下性能大幅度提升。
不同于线性步长学习衰减,余弦学习衰减会以指数形式衰减学习率。余弦学习率会平缓地下降,从而对训练过程更有利,特别是当batch-size较大的时候。
过多的数据增广会提高正则化效果而使得轻量模型更难以收敛。所以,本文只使用了随机翻转、随机裁剪和多尺度缩放作为训练中的数据增广。
4. 实验
4.1 实现细节
对于训练,本文使用随机梯度下降(SGD),并设置动量0.9,权重衰减为4e-5。这里使用了余弦衰减的学习率策略,且初始学习率为0.1。Batch-size默认为80x8,使用8x32G-V100-GPU设备。本文训练了300个epochs,花费了2到3天。所有的实验在COCO-2017【40_COCO】训练集上训练,此训练集包含80类和118k张图像;实验在COCO-2017的验证集上评测,验证集包含5000张图像,评测使用标准的COCO-mAP指标,且使用单尺度测试。Exponential Moving Average(EMA)有效地利用了近期的信息并直观保持了长期影响。轻量级模型更容易陷入局部最优于是更加难以收敛。因此,本文引入了一种类似于正则化的机制,称为Cycle-EMA,用于重置历史信息,由 forget step来控制。
对于架构搜索的任务,所有的超参数设置和用于超网络训练的数据集都与原始模型的设置相同,具体信息在下一章节中。本文使用L2-norm梯度裁剪来避免梯度爆炸。还有一个区别是本文在每一步中训练了八个候选模型,因为本文使用的搜索空间很大。
4.2 消融研究
所有消融实验的结果如表2所示。
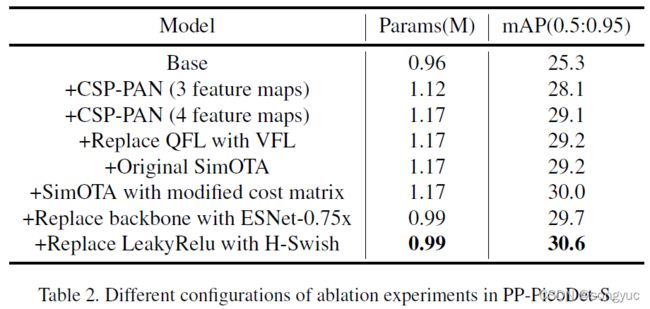
所有实验的评测是在COCO-2017验证集上进行的。
CSP-PAN:本文首先建立了一个与NanoDet类似的基线模型,主干网络使用ShuffleNetV2-1x,neck部分使用不包含卷积的PAN,损失函数使用标准GFL【7_GFL】的损失函数,还有标签分配策略使用ATSS【26_ATSS】。所有的激活函数使用LeakyRelu。于是获得mAP(0.5:0.95)结果为25.3。除此之外,本文还使用了CSP-PAN结构。其中特征图尺度为3。于是mAP(0.5:0.95)提升到28.1。最终,本文在CSP-PAN顶部增加了一个特征图尺度(就是现在图中的结构),而增加的参数量不超过50K。mAP(0.5:0.95)分数则进一步提升至29.1。结果如表2所示。
损失函数:本文在上一节的相同设置下比较了Varifocal-Loss(VFL)和Quality-Focal-Loss(QFL)的影响。这两种函数的结果十分相近,Varifocal-Loss的效果只比Quality-Focal-Loss稍微好一点。将VFL替换为QFL,mAP(0.5:0.95)分数从29.1提升到29.2。结果显示在表2中。
标签分配策略:在上一节的相同设置下,本文用原始SimOTA和改进的SimOTA替换了ATSS。本文发现n越大,效果越差。超参数n于是被设为10。ATSS的性能与原始SimOTA几乎一样。本文改进的SimOTA的mAP(0.5:0.95)分数达到了30.0。结果显示在表2中。
本文进一步比较了Varifocal-Loss和GIoU-Loss使用不同权重时SimOTA的效果。本文改变了公式(1)中 λ \lambda λ的值来进行消融实验。结果如表3所示。

当GIoU-loss的权重为6时,获得了最佳的结果。
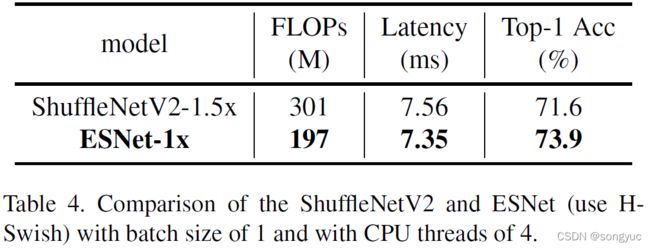
ESNet主干网络:本文在ImageNet-1k上比较了ESNet-1x与原始ShuffleNetV2-1.5x网络。表4展示了在推理时间更低的情况下,ESNet实现了更高的精度。
本文还比较了原始模型和搜索模型的性能,结果如表5所示。
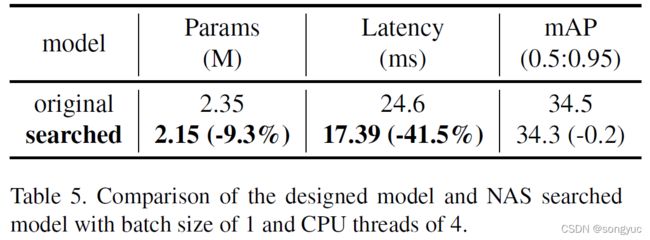
搜索的模型在实验限制下进降低了0.2%mAP,而移动端CPU推理时间提升了41.5%(使用PaddleLite达到54.9%)。本文将上述检测器的主干替换为ESNet-0.75x,参数数量降低了大约200K,mAP(0.5:0.95)最后达到29.7。结果显示在表2中。
H-Swish激活函数:最后,我们将所有激活函数从LeakyRelu替换为H-Swish,mAP(0.5:0.95)最后提升到30.6。结果显示在表2中。
4.3 与SOTA算法的对比
从表1中可知,可以看到本文的模型在精度和速度上都大大超过了所有的YOLO模型。
这些成绩主要归功于下面的改进:(1)本文的neck部分要比YOLO系列的neck要更加轻量,所以主干和head能分配更多参数。(2)本文使用针对类别不平衡的Varifocal-Loss、动态可学习的样本分配策略和基于FCOS的回归方法的组合,这种组合在轻量级模型中表现更好。在相同数量参数的情况下,PP-PicoDet-S在mAP和时延上都超越了YOLOX-Nano和NanoDet。PP-PicoDet-L的mAP和时延都优于YOLOv5s。由于使用汇编语言优化的卷积算子效率更高,本文发现本文模型在Paddle Lite上的推理时间甚至优于在NCNN上的推理时间。总结来说,本文的模型已经在很大程度上领先于SOTA模型。
5 结论和未来工作
本文提供了一系列新的轻量级目标检测模型,这些模型在移动设备的目标检测任务中有着优秀的性能。据本文所知,本文的PP-PicoDet-S模型是首个mAP(0.5:0.95)超过30同时保持1M参数、ARM-CPU上100+FPS的模型。此外,PP-PicoDet-L模型在仅用3.3M参数的条件下mAP(0.5:0.95)超过了40。未来将继续探究新的技术,以提供更多高精度高效率的检测模型。
6 致谢
本工作受到了中国国家重点研发计划项目(2020AAA0103503)的支持。