聚类篇——(五)层次聚类
前面博文介绍了两种常用基于划分的聚类算法K-means聚类、K-Medoids聚类,还有有序样品聚类。本篇博文介绍基于层次的聚类算法,层次聚类主要有两种类型:合并的层次聚类和分裂的层次聚类。合并的层次聚类是一种自底向上的聚类算法,从最底层(即每个数据点为一类)开始,每一次合并最相似的类,直到全部数据点都合并到一类时或者达到某个终止条件时停止,大部分层次聚类都是采用这种方法处理。分裂的层次聚类是一种自顶向下的聚类方法,从最顶层(即全部数据点为一类)开始,然后把根节点分裂为一些子类,每个子类再递归地继续往下分裂,直到每个类中仅包含一个数据点。

在此主要介绍合并的层次聚类,其思想是开始每个样本为一类,根据类与类之间的距离,再进行逐级合并。类与类之间的距离计算方法有直接距离法、最短距离法、最远距离法、中间距离法、重心法、类平均法、离差平方和法,不同的方法,最终的聚类结果可能会有所不同。下面基于一个实际应用例子,某个地区9个农业区进行层次聚类,(具体指标数值见表1),详细介绍不同方法的计算过程,以及如何确定类的个数。

1. 对数据进行标准化处理
数据标准化方法可参见前面的博文“聚类篇——(一)聚类分析概述”,在此采用极差法对原数据进行标准化处理,得到表2
z i = x i − x min x max − x min {{z}_{i}}=\frac{{{x}_{i}}-{{x}_{\min }}}{{{x}_{\max }}-{{x}_{\min }}} zi=xmax−xminxi−xmin

2. 计算样本间的距离
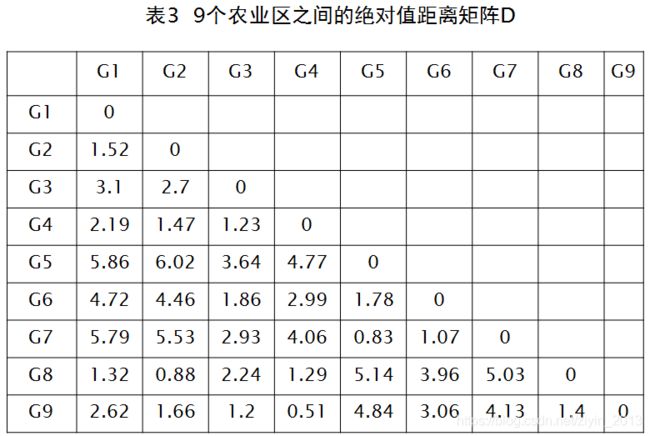
计算样本间距离的方法可参见前面的博文“聚类篇——(一)聚类分析概述”,在此采用绝对值距离法计算样本间的距离,得到表3距离矩阵D
d ( x , y ) = ∑ i = 1 n ∣ x i − y i ∣ , i = 1 , 2 , ⋯ , n d\left( x,y \right)=\sum\limits_{i=1}^{n}{|{{x}_{i}}-{{y}_{i}}|},i=1,2,\cdots ,n d(x,y)=i=1∑n∣xi−yi∣,i=1,2,⋯,n
3. 根据类与类之间的距离,进行逐级合并
根据类与类之间的距离,再进行逐级合并。类与类之间距离计算方法不同,类与类之间的合并策略不同,最终的聚类结果可能会有所不同。常用的类与类之间的距离计算方法有直接距离法、最短距离法、最远距离法、中间距离法、重心法、类平均法、离差平方和法,下面将依次展开介绍。
3.1 直接距离法
先把各个分类对象单独视为一类,然后根据距离最小的原则,依次选出一对分类对象,并形成新类。如果其中一个分类对象已归为一类,则把另一个也归为该类;如果一对分类对象正好属于已归的两类,则把这两类并为一类。每一次归并,都划去该对象所在的列与列序相同的行。依次就可以把全部分类对象归为一类,这样就可以根据归并的先后顺序做出聚类谱系图。
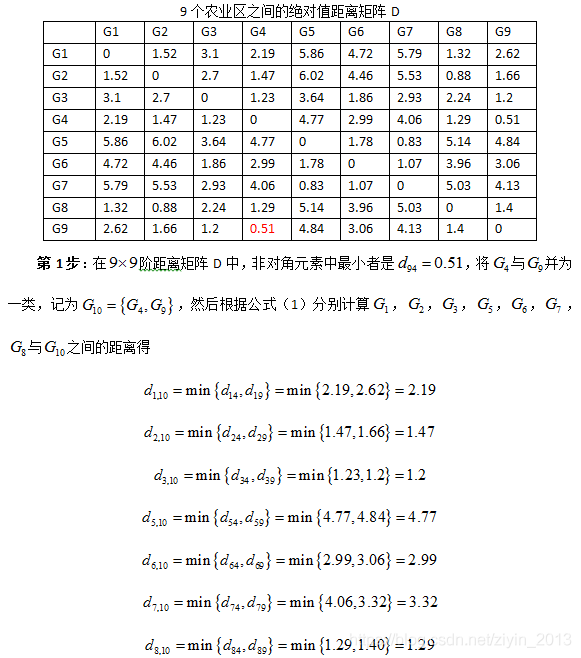
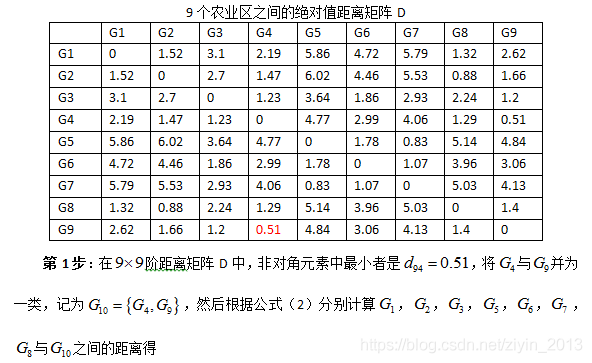
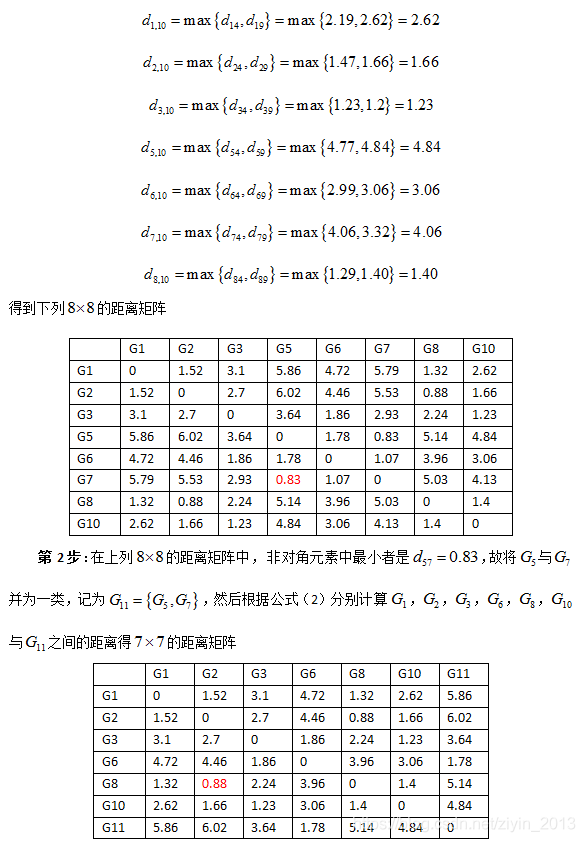
- 第1步:在表3距离矩阵D中,除去对角线元素以外, d 49 = d 94 = 0.51 {{d}_{49}}={{d}_{94}}=0.51 d49=d94=0.51为最小者,故将第4区与第9区并为一类,划去第9行和第9列;
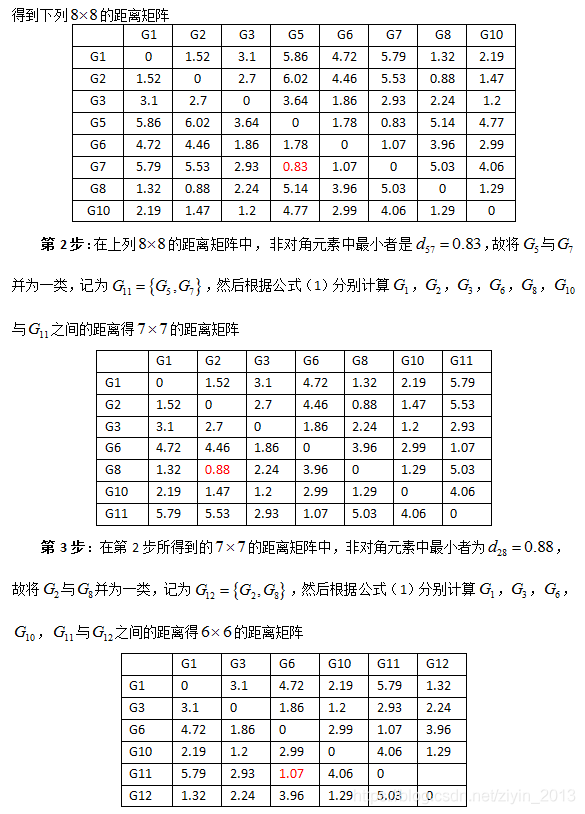
- 第2步:在余下的元素中,除去对角线元素外, d 75 = d 57 = 0.83 {{d}_{75}}={{d}_{57}}=0.83 d75=d57=0.83为最小者,故将第5区与第7区并为一类,划去第7行和第7列;
- 第3步:在第二步之后余下的元素中,除对角线元素以外, d 82 = d 28 = 0.88 {{d}_{82}}={{d}_{28}}=0.88 d82=d28=0.88为最小者,故将第2区与第8区并为一类,划去第8行和第8列;
- 第4步:在第3步之后余下的元素中,除对角先元素以外, d 43 = d 34 = 1.23 {{d}_{43}}={{d}_{34}}=1.23 d43=d34=1.23为最小者,故将第3区与第4区并为一类,划去第4行和第4列,此时第3、4、9区已归并为一类;
- 第5步:在第4步之后余下的元素中,除对角线元素以外, d 21 = d 12 = 1.52 {{d}_{21}}={{d}_{12}}=1.52 d21=d12=1.52为最小者,故将第1区与第2区并为一类,划去第2行和第2列,此时第1、2、8区已归并为一类;
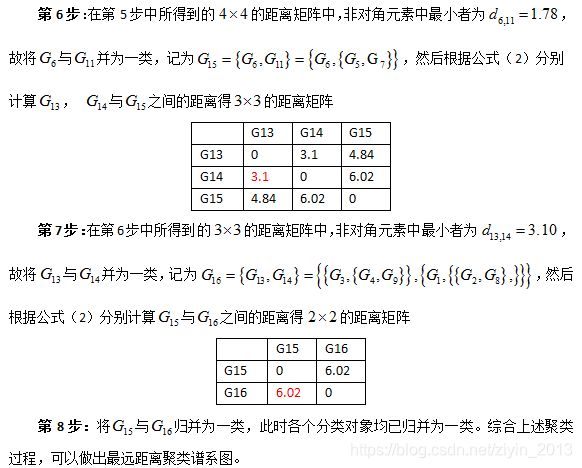
- 第6步:在第5步之后余下的元素中,除对角线以外, d 65 = d 56 = 1.78 {{d}_{65}}={{d}_{56}}=1.78 d65=d56=1.78为最小者,故将第5区与第6区并为一类,划去第6行和第6列,此时第5、6、7区已归并为一类;
- 第7步:在第6步之后余下的元素中,除对角线元素外, d 31 = d 13 = 3.10 {{d}_{31}}={{d}_{13}}=3.10 d31=d13=3.10为最小者,故将第1区与第3区并为一类,划去第3行和第3列,此时第1、2、3、4、8、9区已归并为一类;
- 第8步:在第7步之后余下的元素中,除对角线元素以外, d 51 = d 15 = 5.86 {{d}_{51}}={{d}_{15}}=5.86 d51=d15=5.86,故将第1区与第5区并为一类,划去第5行和第5列,此时第1-9区均归并为一类。


3.2 最短距离法
最短距离聚类法,是在原来的 n × n n\times n n×n距离矩阵的非对角线找出 d p q = min { d i j } {{d}_{pq}}=\min \left\{ {{d}_{ij}} \right\} dpq=min{dij},把分类对象 G p {{G}_{p}} Gp和 G q {{G}_{q}} Gq归并为以新类 G r {{G}_{r}} Gr,然后按计算公式
d r k = min { d p k , d q k } ( k ≠ p , q ) {{d}_{rk}}=\min \left\{ {{d}_{pk}},{{d}_{qk}} \right\}\left( k\ne p,q \right) drk=min{dpk,dqk}(k=p,q) (1)
计算原来各类与新类之间的距离,这样就得到一个新的(m-1)阶的距离矩阵;再从新的距离矩阵中选出最小者 d i j {{d}_{ij}} dij,把 G i {{G}_{i}} Gi和 G j {{G}_{j}} Gj归并成新类;再计算各类与新类的距离,这样一直下去,直至各分类对象被归为一类为止。

算法描述:
假设 N × N N\times N N×N的相似矩阵 D = ( d i j ) D=\left( {{d}_{ij}} \right) D=(dij)。聚类结果用序号0,1,2,…,(n-1)表示, L ( m ) L\left( m \right) L(m)表示第 m m m次聚类的层次。簇的序号用(m)表示,簇 ( r ) (r) (r)和 ( s ) (s) (s)的相似系数(即距离矩阵中的值)用 d r s {{d}_{rs}} drs表示。下面是算法的具体描述:
(1) L ( 0 ) = 0 L\left( 0 \right)=0 L(0)=0, m = 0 m=0 m=0;
(2) 从当前所有簇对中,根据 d r s = min d i j {{d}_{rs}}=\min {{d}_{ij}} drs=mindij找距离最近(最相似)的两个簇 ( r ) (r) (r), ( s ) (s) (s);
(3) 将簇的序列号加1,即 m = m + 1 m=m+1 m=m+1,将簇 ( r ) (r) (r), ( s ) (s) (s)合并,并将聚类的层次 L ( m ) = d r s L\left( m \right)={{d}_{rs}} L(m)=drs;
(4) 更新相似矩阵D,删除簇 ( r ) (r) (r), ( s ) (s) (s)相应的行和列,并在矩阵中加上新生成的簇相应的行和列。相似矩阵中新生成的簇(r,s)和原来簇(k)的相似度由下列定义:
d k , r s = min { d k r , d k s } {{d}_{k,rs}}=\min \left\{ {{d}_{kr}},{{d}_{ks}} \right\} dk,rs=min{dkr,dks}
(5) 重复(2)~(4),直到所有对象都被合到一个簇为止。


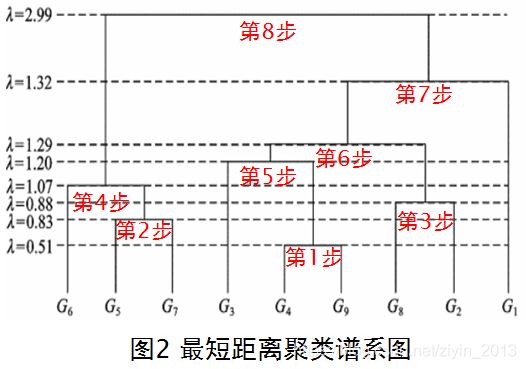
由于最短距离法每次并类后都是将该类与其它类中距离最近的两个样本之间的距离作为该类与其他类的距离,所以此聚类方法的逐次并类距离之间的差距一般来说可能会越来越小。因此该方法具有距离收缩的性质。但是最短距离法认为,只要单个样本之间的相异度小,就认为两个组是紧密靠拢的,而不管其他样本的相异度如何,这倾向于合并由一系列本身位置靠近的样本。这种现象称为“链条”,是该方法的不足之处,故最短距离聚类方法产生的聚类可能破坏类的“紧凑性”。
3.3 最远距离法
最远距离聚类法与最短距离聚类法的区别在于计算原来的类与新类之间的距离时采用的公式不同。 G p {{G}_{p}} Gp和 G q {{G}_{q}} Gq归并为以新类 G r {{G}_{r}} Gr,计算原来各类 G k {{G}_{k}} Gk与新类 G r {{G}_{r}} Gr之间的距离为
d r k = max { d p k , d q k } ( k ≠ p , q ) {{d}_{rk}}=\max \left\{ {{d}_{pk}},{{d}_{qk}} \right\}\left( k\ne p,q \right) drk=max{dpk,dqk}(k=p,q) (2)


对于最远距离法,只有当两个组的并集中所有的样本都相对近似时才被认为是靠近的。这将倾向于产生具有小直径的紧凑类。然而,它可能产生违背“闭合性”的类。也就是说,分配到某个类的样本距其他类成员的距离可能比距离本类中的某些成员的距离更短。
3.4 中间距离法
中间距离法是苟沃(Gower,1966)提出的方法,又称平均连接法。此聚类方法在定义类与类之间的距离时,既不采用两类之间的最近距离也不采用两类之间的最远距离,而是介于两者之间的中间距离,它避免了最远距离与最短距离计算上的弊端。 G p {{G}_{p}} Gp和 G q {{G}_{q}} Gq归并为以新类 G r {{G}_{r}} Gr,计算原来各类 G k {{G}_{k}} Gk与新类 G r {{G}_{r}} Gr之间的距离为
d k r 2 = 1 2 d k p 2 + 1 2 d k q 2 − 1 4 d p q 2 , ( k ≠ p , q ) d_{kr}^{2}=\frac{1}{2}d_{kp}^{2}+\frac{1}{2}d_{kq}^{2}-\frac{1}{4}d_{pq}^{2},\left( k\ne p,q \right) dkr2=21dkp2+21dkq2−41dpq2,(k=p,q) (3)

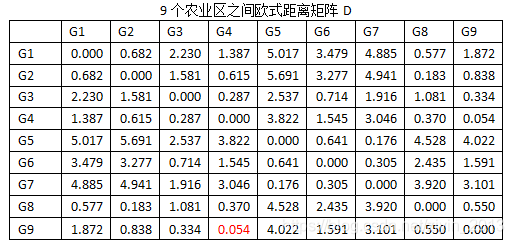




3.5 重心法(采用欧式距离)
重心法定义类与类之间距离为两类的重心(各类所有样本的均值)之间的距离,利用重心指标可以很好的代表某个类,但对样本信息的利用不是很充分。
设 G p {{G}_{p}} Gp和 G q {{G}_{q}} Gq分别有样本 n p , n q {{n}_{p}},{{n}_{q}} np,nq个,重心分别为 X ˉ p , X ˉ q {{\bar{X}}_{p}},{{\bar{X}}_{q}} Xˉp,Xˉq,重心法将 G p {{G}_{p}} Gp和 G q {{G}_{q}} Gq之间的距离定义为其重心 X ˉ p , X ˉ q {{\bar{X}}_{p}},{{\bar{X}}_{q}} Xˉp,Xˉq之间的距离,并用欧式距离来表示,即
d p q 2 = ( X ˉ p − X ˉ q ) T ( X ˉ p − X ˉ q ) d_{pq}^{2}={{\left( {{{\bar{X}}}_{p}}-{{{\bar{X}}}_{q}} \right)}^{T}}\left( {{{\bar{X}}}_{p}}-{{{\bar{X}}}_{q}} \right) dpq2=(Xˉp−Xˉq)T(Xˉp−Xˉq)
将 G p {{G}_{p}} Gp和 G q {{G}_{q}} Gq合并为 G r {{G}_{r}} Gr,则 G r {{G}_{r}} Gr内样本的个数为 n r = n p + n q {{n}_{r}}={{n}_{p}}+{{n}_{q}} nr=np+nq,它的重心是 X ˉ r = 1 n r ( n p X ˉ p + n q X ˉ q ) {{\bar{X}}^{r}}=\frac{1}{{{n}_{r}}}\left( {{n}_{p}}{{{\bar{X}}}^{p}}+{{n}_{q}}{{{\bar{X}}}^{q}} \right) Xˉr=nr1(npXˉp+nqXˉq)
设类 G k {{G}_{k}} Gk的重心为 X ˉ k {{\bar{X}}_{k}} Xˉk, G k {{G}_{k}} Gk与新类 G r {{G}_{r}} Gr之间的距离是
d r k 2 = n p n r d p k 2 + n q n r d q k 2 − n p n q n r 2 d p q 2 d_{rk}^{2}=\frac{{{n}_{p}}}{{{n}_{r}}}d_{pk}^{2}+\frac{{{n}_{q}}}{{{n}_{r}}}d_{qk}^{2}-\frac{{{n}_{p}}{{n}_{q}}}{n_{r}^{2}}d_{pq}^{2} drk2=nrnpdpk2+nrnqdqk2−nr2npnqdpq2 (4)






3.6 类平均法
类平均距离是指用两个聚类所有数据点间的距离的平均距离代表两个聚类的距离,组平均连接法采用的距离定义为两类之间的平均平方距离。将 G p {{G}_{p}} Gp类和 G q {{G}_{q}} Gq类合并为一类 G r {{G}_{r}} Gr后, G r {{G}_{r}} Gr类与其它类 G k {{G}_{k}} Gk类的距离
d k r 2 = n p n p + n q d k p 2 + n q n p + n q d k q 2 d_{kr}^{2}=\frac{{{n}_{p}}}{{{n}_{p}}+{{n}_{q}}}d_{kp}^{2}+\frac{{{n}_{q}}}{{{n}_{p}}+{{n}_{q}}}d_{kq}^{2} dkr2=np+nqnpdkp2+np+nqnqdkq2 (5)
其中, n p , n q , n r , n k {{n}_{p}},{{n}_{q}},{{n}_{r}},{{n}_{k}} np,nq,nr,nk分别是 G p , G q , G r , G k {{G}_{p}},{{G}_{q}},{{G}_{r}},{{G}_{k}} Gp,Gq,Gr,Gk类中的样品数, n r = n p + n q {{n}_{r}}={{n}_{p}}+{{n}_{q}} nr=np+nq。
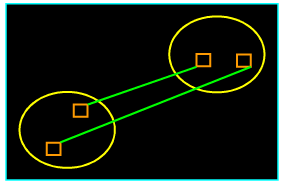

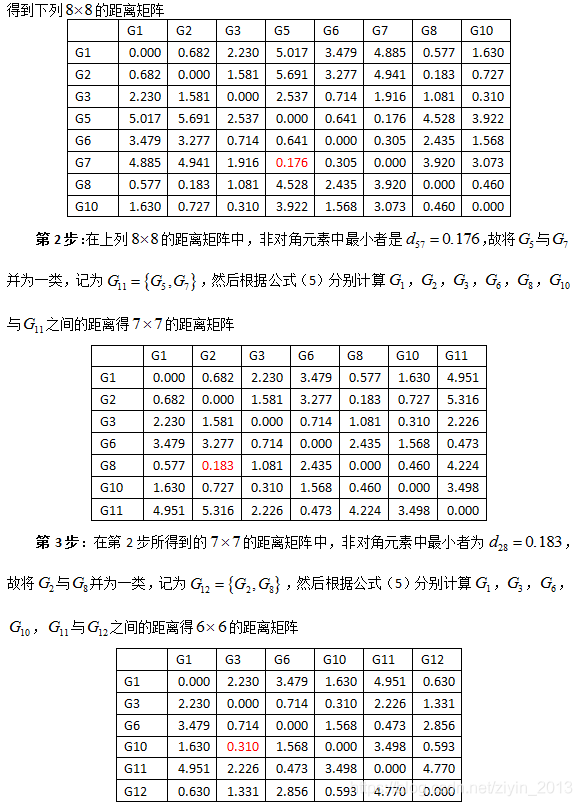

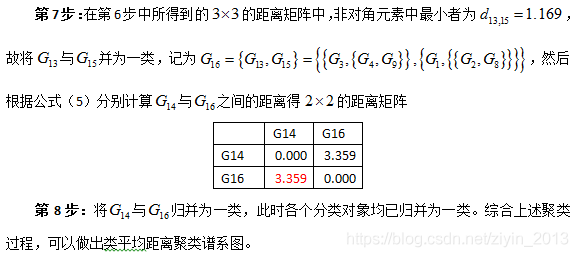

3.7 离差平方和(采用欧式距离)
离差平方和的思想来自于方差分析,是由Ward于1936年提出,1967年经Orloci等人发展建立起来的一种系统聚类方法。该方法认为,如果分类正确,同样样本的离差平方和应当较小,类与类之间的离差平方和应当较大。具体是先将n个样本看成一类,然后每次缩小一类。每缩小一类,离差平方和就要增大,选择使S增加最小的两类合并,直到所有的样本归为一类。对每一类计算所有变量的均值,然后对每一样本计算到类均值的距离平方,再对所有样本求这些距离之和。在每一步,合并的两类是使类内距离总平方和增加最小的类。
假设已对 n n n个样品进行分类,并且分类个数为 k k k, G 1 , G 2 , ⋯ , G k {{G}_{1}},{{G}_{2}},\cdots ,{{G}_{k}} G1,G2,⋯,Gk表示为 k k k个类, G t {{G}_{t}} Gt类中的样品个数用 n t {{n}_{t}} nt表示, G t {{G}_{t}} Gt类的重心用 X ˉ t {{\bar{X}}^{t}} Xˉt表示, G t {{G}_{t}} Gt类的第 i i i个样品用 X i t X_{i}^{t} Xit表示 ( i = 1 , 2 , ⋯ , n ) \left( i=1,2,\cdots ,n \right) (i=1,2,⋯,n),则 G t {{G}_{t}} Gt类中的样品离差平方和表示为
W t = ∑ i = 1 n t ( X i t − X ˉ t ) T ( X i t − X ˉ t ) {{W}_{t}}=\sum\limits_{i=1}^{{{n}_{t}}}{{{\left( X_{i}^{t}-{{{\bar{X}}}^{t}} \right)}^{T}}\left( X_{i}^{t}-{{{\bar{X}}}^{t}} \right)} Wt=i=1∑nt(Xit−Xˉt)T(Xit−Xˉt)
其中 X i t , X ˉ t X_{i}^{t},{{\bar{X}}^{t}} Xit,Xˉt为 m m m维向量, W t {{W}_{t}} Wt为一数值 ( t = 1 , 2 , ⋯ , k ) \left( t=1,2,\cdots ,k \right) (t=1,2,⋯,k)。
k k k个类的总的离差平方和为
W = ∑ t = 1 k W t = ∑ t = 1 k ∑ i = 1 n t ( X i t − X ˉ t ) T ( X i t − X ˉ t ) W=\sum\limits_{t=1}^{k}{{{W}_{t}}}=\sum\limits_{t=1}^{k}{\sum\limits_{i=1}^{{{n}_{t}}}{{{\left( X_{i}^{t}-{{{\bar{X}}}^{t}} \right)}^{T}}\left( X_{i}^{t}-{{{\bar{X}}}^{t}} \right)}} W=t=1∑kWt=t=1∑ki=1∑nt(Xit−Xˉt)T(Xit−Xˉt)
离差平方和法的基本原理是:先把 n n n个样品各自分成一类,此时 W = 0 W=0 W=0。然后每次对其中的某两个类进行合并,因每次缩小一类离差平方和就会增加,这时应该选使 W W W增加最小的两个类进行合并,直到所有的样品合并为一类为止。
离差平方和法是把某两类进行合并后所增加的离差平方和看成是这两类间的平方距离,即 D p q 2 = W r − ( W p + W q ) D_{pq}^{2}={{W}_{r}}-\left( {{W}_{p}}+{{W}_{q}} \right) Dpq2=Wr−(Wp+Wq),表示 G p {{G}_{p}} Gp类和 G q {{G}_{q}} Gq的平方距离,其中 G r = { G p , G q } {{G}_{r}}=\left\{ {{G}_{p}},{{G}_{q}} \right\} Gr={Gp,Gq}, W r , W p , W q {{W}_{r}},{{W}_{p}},{{W}_{q}} Wr,Wp,Wq分别为 G r , G p , G q {{G}_{r}},{{G}_{p}},{{G}_{q}} Gr,Gp,Gq类中样品的离差平方和,由定义得:
W r = ∑ i = 1 n r ( X i r − X ˉ r ) T ( X i r − X ˉ r ) = ∑ i = 1 n p ( X i p − X ˉ r ) T ( X i p − X ˉ r ) + ∑ i = 1 n q ( X i q − X ˉ r ) T ( X i q − X ˉ r ) {{W}_{r}}=\sum\limits_{i=1}^{{{n}_{r}}}{{{\left( X_{i}^{r}-{{{\bar{X}}}^{r}} \right)}^{T}}\left( X_{i}^{r}-{{{\bar{X}}}^{r}} \right)} =\sum\limits_{i=1}^{{{n}_{p}}}{{{\left( X_{i}^{p}-{{{\bar{X}}}^{r}} \right)}^{T}}\left( X_{i}^{p}-{{{\bar{X}}}^{r}} \right)}+\sum\limits_{i=1}^{{{n}_{q}}}{{{\left( X_{i}^{q}-{{{\bar{X}}}^{r}} \right)}^{T}}\left( X_{i}^{q}-{{{\bar{X}}}^{r}} \right)} Wr=i=1∑nr(Xir−Xˉr)T(Xir−Xˉr)=i=1∑np(Xip−Xˉr)T(Xip−Xˉr)+i=1∑nq(Xiq−Xˉr)T(Xiq−Xˉr)
其中, X ˉ r = 1 n r ( n p X ˉ p + n q X ˉ q ) {{\bar{X}}^{r}}=\frac{1}{{{n}_{r}}}\left( {{n}_{p}}{{{\bar{X}}}^{p}}+{{n}_{q}}{{{\bar{X}}}^{q}} \right) Xˉr=nr1(npXˉp+nqXˉq)
D p q 2 = W r − ( W p + W q ) = n p n q n r ( X ˉ p − X ˉ q ) T ( X ˉ p − X ˉ q ) D_{pq}^{2}={{W}_{r}}-\left( {{W}_{p}}+{{W}_{q}} \right) =\frac{{{n}_{p}}{{n}_{q}}}{{{n}_{r}}}{{\left( {{{\bar{X}}}^{p}}-{{{\bar{X}}}^{q}} \right)}^{T}}\left( {{{\bar{X}}}^{p}}-{{{\bar{X}}}^{q}} \right) Dpq2=Wr−(Wp+Wq)=nrnpnq(Xˉp−Xˉq)T(Xˉp−Xˉq)
当样品间距离采用欧式距离时,则上式为 D p q 2 = n p n q n r d p q 2 D_{pq}^{2}=\frac{{{n}_{p}}{{n}_{q}}}{{{n}_{r}}}d_{pq}^{2} Dpq2=nrnpnqdpq2,其中 d p q 2 d_{pq}^{2} dpq2为 G p 、 G q {{G}_{p}}、{{G}_{q}} Gp、Gq的重心 X ˉ p 、 X ˉ q {{\bar{X}}^{p}}、{{\bar{X}}^{q}} Xˉp、Xˉq之间的平方距离, d p q 2 = d 2 ( X ˉ p , X ˉ q ) d_{pq}^{2}={{d}^{2}}\left( {{{\bar{X}}}^{p}},{{{\bar{X}}}^{q}} \right) dpq2=d2(Xˉp,Xˉq)。
当 G p , G q {{G}_{p}},{{G}_{q}} Gp,Gq合并为新类 G r {{G}_{r}} Gr后,则 G r {{G}_{r}} Gr和其他类 G k {{G}_{k}} Gk之间的距离为:
D r k 2 = n r n k n r + n k ( X r − X ˉ k ) T ( X r − X ˉ k ) = n p + n k n r + n k D p k 2 + n q + n k n r + n k D q k 2 − n k n r + n k D p q 2 D_{rk}^{2}=\frac{{{n}_{r}}{{n}_{k}}}{{{n}_{r}}+{{n}_{k}}}{{\left( {{X}^{r}}-{{{\bar{X}}}^{k}} \right)}^{T}}\left( {{X}^{r}}-{{{\bar{X}}}^{k}} \right) =\frac{{{n}_{p}}+{{n}_{k}}}{{{n}_{r}}+{{n}_{k}}}D_{pk}^{2}+\frac{{{n}_{q}}+{{n}_{k}}}{{{n}_{r}}+{{n}_{k}}}D_{qk}^{2}-\frac{{{n}_{k}}}{{{n}_{r}}+{{n}_{k}}}D_{pq}^{2} Drk2=nr+nknrnk(Xr−Xˉk)T(Xr−Xˉk)=nr+nknp+nkDpk2+nr+nknq+nkDqk2−nr+nknkDpq2 (6)


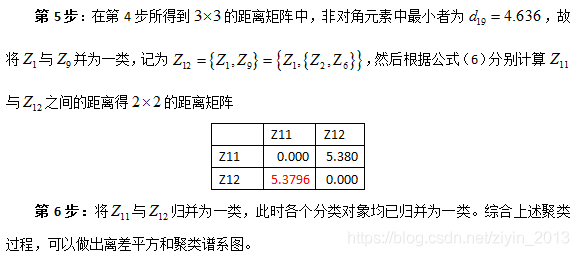

4. 类个数的确定
聚类分析中,类的个数如何确定是一个十分困难和关键的问题。下面介绍确定类个数的几种方法,参见《应用多元统计分析》–高惠璇。
4.1 按适当的阈值确定
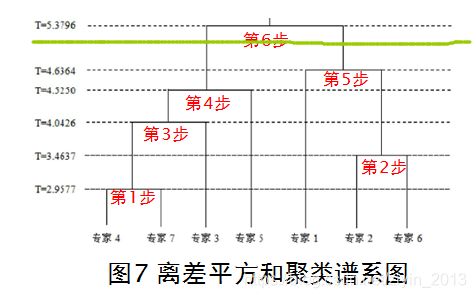
系统聚类中的谱系聚类图只反映样品间的亲疏关系,它本身并没有给出分类,因此需要规定一个临界相似性尺度,用以分割谱系图而得到样品的分类。比如给定临界值(阈值)=5,当类间距离<=5时形成的各个类中所包含的样品间关系密切,应归属为同一类,这相当于在距离>5处切一刀,则图7可划分为两类:{专家4,专家7,专家3,专家5},{专家1,专家2,专家6}。
4.2 根据数据点的散布图直观地确定类的个数
如果考察的指标只有两个,则可通过数据点的散布图直观地确定类的个数。如果有三个变量,可以绘制三维散布图并通过旋转三维坐标轴有数据点的分布来确定应分几个类。当考察的指标在三个以上时,可以由这些指标综合出两个或三个综合变量后再绘制数据点在综合变量上的散布图,从而确定分类个数。

4.3 根据统计量确定分类个数
可以采用一些统计量近似的检验分类个数如何选择更合适。
(1) R 2 R^2 R2 统计量
假定已将 n n n个样品分成 k k k类,记为 G 1 , G 2 , ⋯ , G k , n t {{G}_{1}},{{G}_{2}},\cdots ,{{G}_{k}},{{n}_{t}} G1,G2,⋯,Gk,nt表示 G t {{G}_{t}} Gt类的样品个数( n 1 + n 2 + ⋯ + n t = n {{n}_{1}}+{{n}_{2}}+\cdots +{{n}_{t}}=n n1+n2+⋯+nt=n), X ˉ ( t ) {{\bar{X}}^{(t)}} Xˉ(t)表示 G t {{G}_{t}} Gt的重心, X ˉ ( i ) ( t ) \bar{X}_{(i)}^{(t)} Xˉ(i)(t)表示 G t {{G}_{t}} Gt中的第 i i i个样品( i = 1 , ⋯ , n t i=1,\cdots ,{{n}_{t}} i=1,⋯,nt), X ˉ \bar{X} Xˉ表示所有样品的重心,则 G t {{G}_{t}} Gt类中 n t {{n}_{t}} nt个样品的离差平方和为
W t = ∑ i = 1 n t ( X ( i ) ( t ) − X ˉ ( t ) ) ′ ( X ( i ) ( t ) − X ˉ ( t ) ) {{W}_{t}}=\sum\limits_{i=1}^{{{n}_{t}}}{{{\left( X_{\left( i \right)}^{\left( t \right)}-{{{\bar{X}}}^{\left( t \right)}} \right)}^{\prime }}\left( X_{\left( i \right)}^{\left( t \right)}-{{{\bar{X}}}^{\left( t \right)}} \right)} Wt=i=1∑nt(X(i)(t)−Xˉ(t))′(X(i)(t)−Xˉ(t))
其中 X ( i ) ( t ) , X ˉ ( t ) , X ˉ X_{\left( i \right)}^{\left( t \right)},{{\bar{X}}^{\left( t \right)}},\bar{X} X(i)(t),Xˉ(t),Xˉ均为 m m m维向量, W t {{W}_{t}} Wt为以数值;所有样品的总离差平方和为
T = ∑ t = 1 k ∑ i = 1 n t ( X ( i ) ( t ) − X ˉ ) ′ ( X ( i ) ( t ) − X ˉ ) T=\sum\limits_{t=1}^{k}{\sum\limits_{i=1}^{{{n}_{t}}}{{{\left( X_{\left( i \right)}^{\left( t \right)}-\bar{X} \right)}^{\prime }}\left( X_{\left( i \right)}^{\left( t \right)}-\bar{X} \right)}} T=t=1∑ki=1∑nt(X(i)(t)−Xˉ)′(X(i)(t)−Xˉ)
T T T又可以分解为
T = ∑ t = 1 k ∑ i = 1 n t ( X ( i ) ( t ) − X ˉ ( t ) + X ˉ ( t ) − X ˉ ) ′ ( X ( i ) ( t ) − X ˉ ( t ) + X ˉ ( t ) − X ˉ ) = ∑ t = 1 k W t + ∑ t = 1 k n t ( X ˉ ( t ) − X ˉ ) ′ ( X ˉ ( t ) − X ˉ ) = P k + B k T=\sum\limits_{t=1}^{k}{\sum\limits_{i=1}^{{{n}_{t}}}{{{\left( X_{\left( i \right)}^{\left( t \right)}-{{{\bar{X}}}^{^{\left( t \right)}}}+{{{\bar{X}}}^{^{\left( t \right)}}}-\bar{X} \right)}^{\prime }}\left( X_{\left( i \right)}^{\left( t \right)}-{{{\bar{X}}}^{^{\left( t \right)}}}+{{{\bar{X}}}^{^{\left( t \right)}}}-\bar{X} \right)}} =\sum\limits_{t=1}^{k}{{{W}_{t}}}+\sum\limits_{t=1}^{k}{{{n}_{t}}{{\left( {{{\bar{X}}}^{^{\left( t \right)}}}-\bar{X} \right)}^{\prime }}\left( {{{\bar{X}}}^{^{\left( t \right)}}}-\bar{X} \right)}={{P}_{k}}+{{B}_{k}} T=t=1∑ki=1∑nt(X(i)(t)−Xˉ(t)+Xˉ(t)−Xˉ)′(X(i)(t)−Xˉ(t)+Xˉ(t)−Xˉ)=t=1∑kWt+t=1∑knt(Xˉ(t)−Xˉ)′(Xˉ(t)−Xˉ)=Pk+Bk
令
R k 2 = B k T = 1 − P k T R_{k}^{2}=\frac{{{B}_{k}}}{T}=1-\frac{{{P}_{k}}}{T} Rk2=TBk=1−TPk
则 R k 2 R_{k}^{2} Rk2值越大,也就是 B k / T {{{B}_{k}}}/{T}\; Bk/T越大,表示 k k k个类的类间偏差平方和的总和 B k {{B}_{k}} Bk在总离差平方和 T T T中占的比例越大,这说明 k k k个类越能够区分开。因此 R k 2 R_{k}^{2} Rk2统计量可用于评价合并为 k k k个类时的聚类效果。 R k 2 R_{k}^{2} Rk2越大,聚类效果越好。 R k 2 R_{k}^{2} Rk2的值总是在0和1之间,当 n n n个样品各自为不同的类时( T = B n T={{B}_{n}} T=Bn), R k 2 = 1 R_{k}^{2}=1 Rk2=1;当 n n n个样品最后合并成同一类时( T = P n T={{P}_{n}} T=Pn), R k 2 = 0 R_{k}^{2}=0 Rk2=0,而且 R k 2 R_{k}^{2} Rk2的值总是随着分类个数 k k k的减少而变小。如果孤立地看每次合并后的 R k 2 R_{k}^{2} Rk2的值,其意义是不大的。如果希望通过分析 R k 2 R_{k}^{2} Rk2的值来确定 n n n个样品应该分成几类最合适,则应该看 R k 2 R_{k}^{2} Rk2值的变化。比如,在分为4个类之前的并类过程中 R k 2 R_{k}^{2} Rk2的值减少是逐渐的,改变不大;假定分为4类时 R 4 2 = 0.797 R_{4}^{2}=0.797 R42=0.797,而下一次合并后分为3类时 R 3 2 R_{3}^{2} R32下降较多,比如 R 3 2 = 0.402 R_{3}^{2}=0.402 R32=0.402,这时通过分析 R k 2 R_{k}^{2} Rk2统计量的变化可得出,分为4类是较合适的。
(2)半偏 R 2 {{R}^{2}} R2统计量
半 偏 R k 2 = B K L 2 / T = R k + 1 2 − R k 2 半偏R_{k}^{2}={B_{KL}^{2}}/{T}\;=R_{k+1}^{2}-R_{k}^{2} 半偏Rk2=BKL2/T=Rk+12−Rk2
其中 B K L 2 = W M − ( W K + W L ) B_{KL}^{2}={{W}_{M}}-\left( {{W}_{K}}+{{W}_{L}} \right) BKL2=WM−(WK+WL),表示合并类 G K {{G}_{K}} GK和 G L {{G}_{L}} GL为新类 G M {{G}_{M}} GM后类内离差平方和的增值,该统计量用于评价合并 G K {{G}_{K}} GK和 G L {{G}_{L}} GL的效果。根据以上定义,半偏 R k 2 R_{k}^{2} Rk2的值是上一步骤 R k + 1 2 R_{k+1}^{2} Rk+12与该步骤 R k 2 R_{k}^{2} Rk2的差值,故看 R k 2 R_{k}^{2} Rk2变化的大小可以得到半偏 R k 2 R_{k}^{2} Rk2。某步骤半偏 R k 2 R_{k}^{2} Rk2的值越大,说明上一次合并为 k + 1 k+1 k+1个类后的效果好,该统计量用于评价一次合并的效果。
(3)伪 F F F统计量
伪 F k = ( T − P k ) / ( k − 1 ) P k / ( n − k ) = B k P k n − k k − 1 伪{{F}_{k}}=\frac{{\left( T-{{P}_{k}} \right)}/{\left( k-1 \right)}\;}{{{{P}_{k}}}/{\left( n-k \right)}\;}=\frac{{{B}_{k}}}{{{P}_{k}}}\frac{n-k}{k-1} 伪Fk=Pk/(n−k)(T−Pk)/(k−1)=PkBkk−1n−k
该统计量用于评价分为 k k k个类的聚类效果,伪 F k {{F}_{k}} Fk值越大表示这 n n n个样品可显著地分为 k k k个类。伪 F k {{F}_{k}} Fk统计量可以作为确定类个数的有用指标,但并不具有像 F F F统计量的分布。
(4)伪 t 2 {{t}^{2}} t2统计量
伪 t 2 = B K L 2 ( W K + W L ) / ( n K + n L − 2 ) 伪{{t}^{2}}=\frac{B_{KL}^{2}}{{\left( {{W}_{K}}+{{W}_{L}} \right)}/{\left( {{n}_{K}}+{{n}_{L}}-2 \right)}\;} 伪t2=(WK+WL)/(nK+nL−2)BKL2
该统计量用以评价此步骤合并 G K {{G}_{K}} GK和 G L {{G}_{L}} GL的效果。由伪 t 2 {{t}^{2}} t2统计量的定义可知,该值大表示 G K {{G}_{K}} GK和 G L {{G}_{L}} GL合并为 G M {{G}_{M}} GM后类内离差平方和的增量 B K L 2 B_{KL}^{2} BKL2相对于 G K {{G}_{K}} GK和 G L {{G}_{L}} GL两类的类内离差平方和大。这表明上一次被合并的两个类是很分开的,也就是上一次聚类的效果是好的。伪 t 2 {{t}^{2}} t2统计量可以作为确定类个数的有用指标,但并不具有像随机变量 t 2 {{t}^{2}} t2那样的分布。
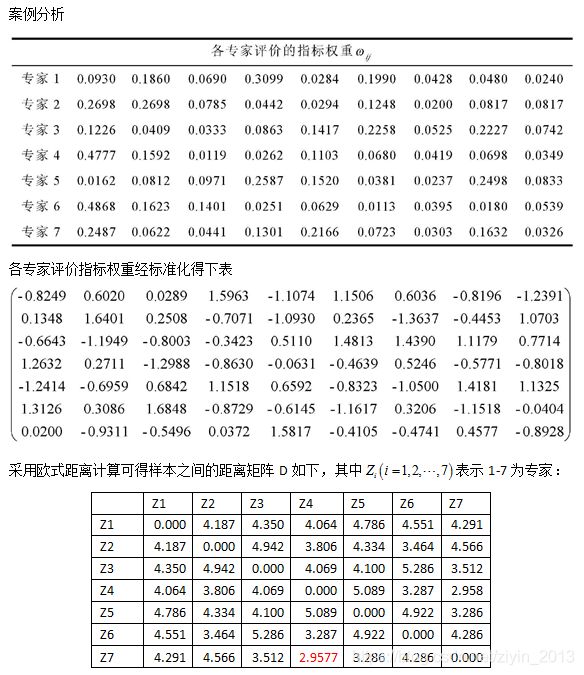
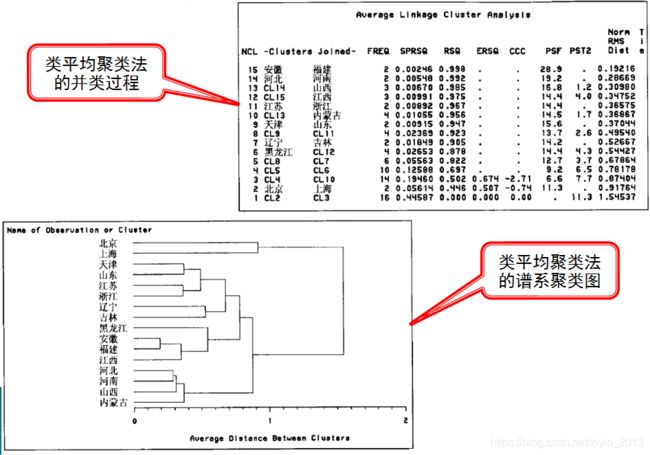
例:根据我国16个地区农民在1982年支出情况的抽样调查数据汇总资料,记录了反映每人 平均生活消费支出情况的六个指标,利用调查资料对16个地区进行分类。

对数据进行标准化变换,样本间距离采用欧式距离,类间距离采用类平均距离法,得到以下并类过程及谱系聚类图。根据谱系聚类图,很容易得到分为二类、三类、四类的聚类结果,但是分成几类最合适?


总结
层次聚类是常用的聚类算法之一,优点是可解释性好,且能产生高质量的聚类,能很好对K-means不能解决的非球形族进行聚类。但是层次聚类的时间复杂度高 O ( m 3 ) O(m^3) O(m3),m为数据点的个数,具有贪心算法的缺点,一步错步步错。层次聚类在逐级合并时采用的策略得到的聚类结果不同,在实际应用中,可以尝试采用不同策略,然后结合自己的业务知识选择一个较优的结果。
ps:初衷是通过撰写博文记录自己所学所用,实现知识的梳理与积累;将其分享,希望能够帮到面临同样困惑的小伙伴儿。如发现博文中存在问题,欢迎随时交流~~