数字图像处理期末总结
前言概述部分
-
数字媒体包含哪些类型,涉及哪些研究领域?
-
1)可视数字媒体包含图像、视频、图形和可视化数据等媒体类型,这些媒体类型之间具有很强的相关性,但又有明确的差异性;
2)可视数字媒体涉及计算机视觉、计算机图形学、人工智能、数字图象处理、图像视频压缩、虚拟现实技术等研究领域;
3)应用领域:机器人(立体视觉、自动驾驶)遥感,医学(图像分析,植被、骨骼) •安全,监控(门禁、视频监控) •国防(目标识别与跟踪、地形匹配) •其他(游戏、动画、人机交互、场景重建、图像搜索匹配、人脸分析和识别……)
-
百度百科:数字媒体是指以二进制数的形式记录、处理、传播、获取过程的信息载体。这些载体包括数字化的文字、图形、图像、声音、视频影像和动画等感觉媒体,和表示这些感觉媒体的表示媒体(编码)等,通称为逻辑媒体,以及存储、传输、显示逻辑媒体的实物媒体
-
定义:数字媒体包括了图像、文字以及音频、视频等各种形式,以及传播形式和传播内容中采用数字化,即信息的采集、存取、加工和分发的数字化过程。
-
研究领域:数字媒体技术主要研究与数字媒体信息的获取、处理、存储、传播、管理、 安全、输出等相关的理论、方法、技术与系统。其它基于数字传输技术和数字压缩处理技术的广泛应用于数字媒体网络传输的流媒体技术,基于计算机图形技术的广泛应用于数字娱乐产业的计算机动画技术,以及基于人机交互、计算机图形和显示等技术且广泛应用于娱乐、广 播、展示与教育等领域的虚拟现实技术等也是数字媒体技术研究的主要内容。
-
-
说明图像处理、计算机视觉、计算机图形学的关系和差异
-
图像处理(image processing),用计算机对图像进行分析,以达到所需结果的技术。又称影像处理。图像处理一般指数字图像处理。数字图像是指用工业相机、摄像机、扫描仪等设备经过拍摄得到的一个大的二维数组,该数组的元素称为像素,其值称为灰度值。图像处理技术一般包括图像压缩,增强和复原,匹配、描述和识别3个部分。
-
图像处理主要与数学函数和图像变换的使用和应用有关,而不考虑对图像本身进行任何智能推理。它仅仅意味着算法对图像进行一些转换,如平滑、锐化、对比度、拉伸。
-
计算机视觉就是用各种成像系统代替视觉器官作为输入敏感手段,由计算机来代替大脑完成处理和解释。
-
图形学和计算机视觉的联系:Computer Graphics和Computer Vision是同一过程的两个方向。Computer Graphics将抽象的语义信息转化成图像,Computer Vision从图像中提取抽象的语义信息。
-
图像处理和计算机视觉的联系:图像处理是计算机视觉的一个子集。计算机视觉系统利用图像处理算法对人体视觉进行仿真。例如,如果目标是增强图像以便以后使用,那么这可以称为图像处理。如果目标是识别物体、汽车自动驾驶,那么它可以被称为计算机视觉。
-
三者联系:CG 中也会用到 DIP,现今的三维游戏为了增加表现力都会叠加全屏的后期特效,原理就是 DIP,只是将计算量放在了显卡端。
CV 更是大量依赖 DIP 来打杂活,比如对需要识别的照片进行预处理。
最后还要提到近年来的热点——增强现实(AR),它既需要 CG,又需要 CV,当然也不会漏掉 DIP。它用 DIP 进行预处理,用 CV 进行跟踪物体的识别与姿态获取,用 CG 进行虚拟三维物体的叠加。 -
区别:计算机图形学(Computer Graphics)讲的是图形,也就是图形的构造方式,是一种从无到有的概念,从数据得到图像。是给定关于景象结构、表面反射特性、光源配置及相机模型的信息,生成图像。
计算机视觉(Computer Vision)是给定图象,从图象提取信息,包括景象的三维结构,运动检测,识别物体等。
数字图像处理(Digital Image Processing)是对已有的图像进行变换、分析、重构,得到的仍是图像。
-

色彩和图像基础
-
常用的色彩空间、每个色彩空间包含的分量及其含义
-
RGB 使用红、绿、蓝三原色的亮度来定量表示颜色,是以RGB三色光互相叠加来实现混色的方式。三种颜色所占比例不同,得到的颜色就不同。变换混合的比例,就会得到各种各样的混合效果。RGB颜色空间可以看作是三维直角坐标系中的一个单位正方体。任何一种颜色在RGB颜色空间中都可以用三维空间中的一个点来表示。在RGB颜色空间,任意色光F都可以用RGB三种颜色不同分量的相加混合而成:F=r[R]+g[G]+b[B]
RGB分量分别表示红、绿蓝三颜色光的亮度
计算机中使用最为广泛的色彩空间
显示设备兼容性
不是非常符合人对颜色的认知
颜色中值:色调 方差:饱和度 面积:亮度
-
YUV “Y”表示明亮度(Luminance或Luma),也就是灰阶值,“U”和“V”表示的则是色度(Chrominance或Chroma),作用是描述影像色彩及饱和度,用于指定像素的颜色。
-
颜色转化:Y’= 0.299R’ + 0.587G’ + 0.114*B’
U’= -0.147R’ - 0.289G’ + 0.436B’ = 0.492(B’- Y’)
V’= 0.615R’ - 0.515G’ - 0.100B’ = 0.877(R’- Y’)
R’ = Y’ + 1.140*V’
G’ = Y’ - 0.394U’ - 0.581V’
B’ = Y’ + 2.032*U’
-
HSV (hue色度, saturation饱和度, value亮度)颜色空间的模型对应于圆柱坐标系中的一个圆锥形子集,圆锥的顶面对应于V=1. 它包含RGB模型中的R=1,G=1,B=1 三个面,所代表的颜色较亮。色彩H由绕V轴的旋转角给定。红色对应于角度0° ,绿色对应于角度120°,蓝色对应于角度240°。是对用户一种直观的颜色模型,适用领域范围:颜色识别。
色调H
用角度度量,取值范围为0°~360°,从红色开始按逆时针方向计算,红色为0°,绿色为120°,蓝色为240°。它们的补色是:黄色为60°,青色为180°,紫色为300°;
饱和度S
饱和度S表示颜色接近光谱色的程度。一种颜色,可以看成是某种光谱色与白色混合的结果。其中光谱色所占的比例愈大,颜色接近光谱色的程度就愈高,颜色的饱和度也就愈高。饱和度高,颜色则深而艳。光谱色的白光成分为0,饱和度达到最高。通常取值范围为0%~100%,值越大,颜色越饱和。
明度V
明度表示颜色明亮的程度,对于光源色,明度值与发光体的光亮度有关;对于物体色,此值和物体的透射比或反射比有关。通常取值范围为0%(黑)到100%(白)。
RGB和CMY颜色模型都是面向硬件的,而HSV(Hue Saturation Value)颜色模型是面向用户的。
HSV模型的三维表示从RGB立方体演化而来。设想从RGB沿立方体对角线的白色顶点向黑色顶点观察,就可以看到立方体的六边形外形。六边形边界表示色彩,水平轴表示纯度,明度沿垂直轴测量。
H参数表示色彩信息,即所处的光谱颜色的位置。该参数用一角度量来表示,红、绿、蓝分别相隔120度。互补色分别相差180度。
纯度S为一比例值,范围从0到1,它表示成所选颜色的纯度和该颜色最大的纯度之间的比率。S=0时,只有灰度。
V表示色彩的明亮程度,范围从0到1。有一点要注意:它和光强度之间并没有直接的联系。
RGB转化到HSV的算法:
max=max(R,G,B);
min=min(R,G,B);
V=max(R,G,B);
S=(max-min)/max;
if (R = max) H =(G-B)/(max-min) 60;
if (G = max) H = 120+(B-R)/(max-min) 60;
if (B = max) H = 240 +(R-G)/(max-min) 60;
if (H < 0) H = H+ 360;
HSV转化到RGB的算法:
if (s = 0)
R=G=B=V;
else
H /= 60;
i = INTEGER(H);
f = H - i;
a = V * ( 1 - s );
b = V * ( 1 - s * f );
c = V * ( 1 - s * (1 - f ) );
switch(i)
case 0: R = V; G = c; B = a;
case 1: R = b; G = v; B = a;
case 2: R = a; G = v; B = c;
case 3: R = a; G = b; B = v;
case 4: R = c; G = a; B = v;
case 5: R = v; G = a; B = b;
-
-
为什么视频中更多使用类YUV色彩空间
- UV色差信息:色彩信息可以表示为色差(Chrominance或Chroma),每一个色差表示了RGB与Y的差,红色差=R-Y,蓝色差=B-Y。通过Y信息和色差信息就可以还原出RGB色彩信息。而UV信号(称为色度信号)是通过压缩红色差和蓝色差数值信号对视频频带高频端的色副载波进行调制而成的信号,经压缩后的蓝色差和红色差信号就称为U、V。UV信号告诉了显示器要偏移某象素的的颜色,而不改变其亮度。或者UV信号告诉了显示器使得某个颜色亮度依某个基准偏移。UV的值越高,代表该像素会有更饱和的颜色。
- 为什么色差信号能压缩呢?这是因为人类的视觉系统(HVS)对色度的敏感程度低于亮度,人眼对彩色细节的分辨能力远比对亮度细节的分辨能力低,这样就可以把几个相邻像素不同的彩色值当作相同的彩色值来处理,从而减少所需的存储容量和传输量。例如可以将相邻N个像素各自的Y值保留成N个不同的Y值,但它们可以共用一个相同的UV值,这种N+1的模式压缩了存储空间但还原RGB色彩后不影响人的感知。
- YUV解决了彩色电视机与黑白电视的兼容问题,它将亮度信息(Y)与色彩信息(UV)分离,没有UV信息一样可以显示完整的图像,只不过是黑白的。
YUV更方便对视频信号进行压缩,占用的带宽更低。符合人眼的视觉特性,人眼对亮度的敏感度要大于红蓝,所以我们可以保留Y原始值的基础上,降低U和V的值,而不影响观看,从而更加有效的存储图像数据。
YUV不像RGB那样要求三个独立的的视频信号同时传输,所以YUV方式传送占用极少的频宽。
-
图像在计算机中存储的方式-矩阵
- 图像数字化之后在计算机中其实就是一个数字矩阵,阵列中的元素称为像素(Pixel)。像素(或像元)是数字图像的基本元素。每个像素具有整数行(高)和列(宽)位置坐标,同时每个像素都具有一个整数值。
按照像素值的不同通常可以将数字图像表示成三种形式,二值图像,灰度图像,彩色图像。
(1)二值图像 (Binary Image)
二值图像只有一个通道,0表示黑,255表示白。(255是怎么来的?因为图像的每个像素是使用8位二进制来表示的,2^8=256,对应数字为0-255。)
(2)灰度图像 (Gray Scale Image)
灰度图像也只有一个通道,像素值数值越大则图片越白。0表示黑,255表示白,0-255之间其他数字表示不同的灰度。
(3)彩色图像 (Color Image)
彩色图像一般有三个通道,它们组成了颜色空间。常见的颜色空间有RGB、HSV、HLS三种。
- 图像数字化之后在计算机中其实就是一个数字矩阵,阵列中的元素称为像素(Pixel)。像素(或像元)是数字图像的基本元素。每个像素具有整数行(高)和列(宽)位置坐标,同时每个像素都具有一个整数值。
-
图像的色彩调整的处理过程
-
对比度调节、色彩饱和度调节、灰度化
# 读取图像 def read(url): img = cv.imread(url, 1) if img.shape[0] >= 400: HEIGHT_MAX = 400 height, width, _ = img.shape ration = HEIGHT_MAX / height width = int(width * ration) height = HEIGHT_MAX img_resize = cv.resize(img, (width, height)) return img_resize return img # 改变图像亮度 def change_brightness(img, x): # rgb转化为hsv img_t = cv.cvtColor(img, cv.COLOR_BGR2HSV) # 获取hsv h, s, v = cv.split(img_t) # 增加亮度 色调越浅越亮 v1 = np.clip(cv.add(v, x), 0, 255) img1 = np.uint8(cv.merge((h, s, v1))) img1 = cv.cvtColor(img1, cv.COLOR_HSV2BGR) return img1 # 改变图像饱和度 def change_saturation(img, x): # rgb转化为hsv img_t = cv.cvtColor(img, cv.COLOR_BGR2HSV) # 获取hsv h, s, v = cv.split(img_t) # 增加饱和度 饱和度越低,越接近灰度图像 s1 = np.clip(cv.add(s, x), 0, 255) img2 = np.uint8(cv.merge((h, s1, v))) img2 = cv.cvtColor(img2, cv.COLOR_HSV2BGR) return img2 # 改变图像对比度 def change_contrast(img, alpha): dst = np.ones(img.shape) img3 = np.uint8(np.clip(alpha * (img - 127 * dst) + 127 * dst, 0, 255)) return img3 -
对比度调节 改变图像对比度原理:
gbr色彩空间——以127为分界线,小于127的会越小,大于127的会越大
达成“亮的越亮,暗的越暗”的效果
-
图像灰度化:
-
在RGB模型中,如果R=G=B时,则彩色表示一种灰度颜色,其中R=G=B的值叫灰度值,因此,灰度图像每个像素只需一个字节存放灰度值(又称强度值、亮度值),灰度范围为0-255。0%的灰度RGB数值是255,255,255;1%灰度的RGB数值是253,253,253;2%灰度RGB值为250,250,250。
-
图像灰度化:在RGB模型中,如果R=G=B时,则彩色表示一种灰度颜色,其中R=G=B的值叫灰度值,因此,灰度图像每个像素只需一个字节存放灰度值(又称强度值、亮度值),灰度范围为0-255。0%的灰度RGB数值是255,255,255;1%灰度的RGB数值是253,253,253;2%灰度RGB值为250,250,250。
图像灰度化处理一般采用以下三种算法: 平均值法: f(i,j)=(R(i,j)+G(i,j)+B(i,j))/3 最大值法: f(i,j)=max(R(i,j),G(i,j),B(i,j)) 加权平均值法:f(i,j)=0.30R(i,j)+0.59G(i,j)+0.11B(i,j)
-
-
OpenCV中图像的基本运算
-
打开图像文件、显示图像文件、访问像素颜色值等
-
使用函数cv2.imread(filepath,flags)读入一副图片
filepath:要读入图片的完整路径
flags:读入图片的标志
cv2.IMREAD_COLOR:默认参数,读入一副彩色图片,忽略alpha通道,可以直接写1
cv2.IMREAD_GRAYSCALE:读入灰度图片,可以直接写0
cv2.IMREAD_UNCHANGED:顾名思义,读入完整图片,包括alpha通道,可以直接写-1 -
对于imshow函数,opencv的官方注释指出:根据图像的深度,imshow函数会自动对其显示灰度值进行缩放,规则如下:
如果图像数据类型是8U(8位无符号),则直接显示。
如果图像数据类型是16U(16位无符号)或32S(32位有符号整数),则imshow函数内部会自动将每个像素值除以256并显示,即将原图像素值的范围由[0 ~ 255*256]映射到[0~255]
如果图像数据类型是32F(32位浮点数)或64F(64位浮点数),则imshow函数内部会自动将每个像素值乘以255并显示,即将原图像素值的范围由[0~ 1]映射到[0~255](注意:原图像素值必须要归一化) -
可以通过坐标来访问像素值
-
图像特征
- 局部特征和全局特征
全局特征是指图像的整体属性,常见的全局特征包括颜色特征、纹理特征和形状特征,比如强度直方图等。由于是像素级的低层可视特征,因此,全局特征具有良好的不变性、计算简单、表示直观等特点,但特征维数高、计算量大是其致命弱点。此外,全局特征描述不适用于图像混叠和有遮挡的情况。局部特征则是从图像局部区域中抽取的特征,包括边缘、角点、线、曲线和特别属性的区域等。常见的局部特征包括角点类和区域类两大类描述方式。
与线特征、纹理特征、结构特征等全局图像特征相比,局部图像特征具有在图像中蕴含数量丰富 ,特征间相关度小,遮挡情况下不会因为部分特征的消失而影响其他特征的检测和匹配等特点。近年来 ,局部图像特征在人脸识别 、三维重建、目标识别及跟踪 、影视制作 、全景图像拼接 等领域得到了广泛的应用。典型的局部图像特征生成应包括图像极值点检测和描述两个阶段。好的局部图像特征应具有特征检测重复率高、速度快 ,特征描述对光照、旋转、视点变化等图像变换具有鲁棒性,特征描述符维度低,易于实现快速匹配等特点。
-
SIFT、HOG特征的概念
- 概念
SIFT称为尺度不变特征变换(Scale-invariant feature transform,SIFT),是用于图像处理领域的一种描述。这种描述具有尺度不变性,可在图像中检测出关键点,是一种局部特征描述子。
SIFT的特点
①SIFT特征是图像的局部特征,其对旋转、尺度缩放、亮度变化保持不变性,对视角变化、仿射变换、噪声也保持一定程度的稳定性;
②区分性(Distinctiveness)好,信息量丰富,适用于在海量特征数据库中进行快速、准确的匹配;
③多量性,即使少数的几个物体也可以产生大量的SIFT特征向量;
④高速性,经优化的SIFT匹配算法甚至可以达到实时的要求;
⑥可扩展性,可以很方便的与其他形式的特征向量进行联合。
- 概念
-
SIFT、HOG特征的计算过程
-
SIFT
- 尺度空间极值检测
搜索所有尺度上的图像位置。通过高斯微分函数来识别潜在的对于尺度和旋转不变的兴趣点。
关键点定位
在每个候选的位置上,通过一个拟合精细的模型来确定位置和尺度。关键点的选择依据于它们的稳定程度。
方向确定
基于图像局部的梯度方向,分配给每个关键点位置一个或多个方向。所有后面的对图像数据的操作都相对于关键点的方向、尺度和位置进行变换,从而提供对于这些变换的不变性。
关键点描述
在每个关键点周围的邻域内,在选定的尺度上测量图像局部的梯度。这些梯度被变换成一种表示,这种表示允许比较大的局部形状的变形和光照变化。
- 尺度空间极值检测
-
HOG
-
介绍
方向梯度直方图(Histogram of OrientedGradient,HOG)特征是一种在计算机视觉和图像处理中用来进行物体检测的特征描述子。它通过计算和统计图像局部区域的梯度方向直方图来构成特征。Hog特征结合SVM分类器已经被广泛应用于图像识别中,尤其在行人检测中获得了极大的成功。主要思想是在一副图像中,局部目标的表象和形状(appearanceand shape)能够被梯度或边缘的方向密度分布很好地描述。(本质:梯度的统计信息,而梯度主要存在于边缘的地方)。【优点】:
首先,由于HOG是在图像的局部方格单元上操作,所以它对图像几何的和光学的形变都能保持很好的不变性。其次,在粗的空域抽样、精细的方向抽样以及较强的局部光学归一化等条件下,只要行人大体上能够保持直立的姿势,可以容许行人有一些细微的肢体动作,这些细微的动作可以被忽略而不影响检测效果。因此HOG特征是特别适合于做图像中的人体检测的。计算步骤
-
灰度图方式加载图片,假设该图像大小为(128,64)
-
灰度图像gamma 矫正
-
梯度计算
利用一个微分Sobel函数,分别计算灰度图像X和Y方向上的梯度图像,根据着两幅图像,计算出梯度幅值图像 -
8 × 8 8\times88×8 Cell 梯度直方图
每个Cell 为8 × 8 8\times88×8,
所以,一共有 个Cell(灰度图像的大小为128 × 64 128\times64128×64)
将每个Cell 根据角度值(0-180)分成9个bin,并计算每个Cell的梯度直方图,每个Cell 有9个值,如: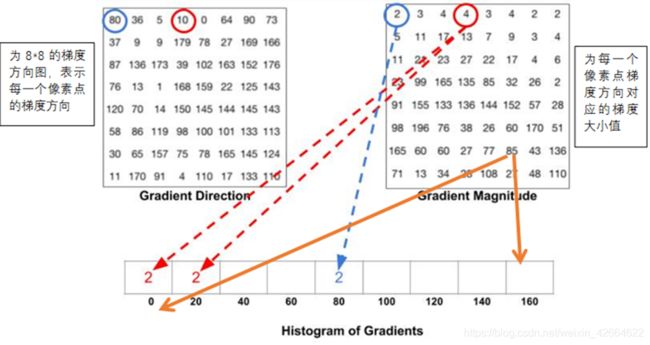
1). 蓝色的线((1, 1)处的值 ):该像素点的梯度方向为10,在直方图的取值中没有10,而10介于0和20之间,10 = 0 × 0.5 0\times0.50×0.5 + 20 × 0.5 20\times0.520×0.5 ,所以,将表示该像素点的梯度方向大小的值在梯度直方图按相同比例分配: 0:4 × 0.5 4\times0.54×0.5= 2 ;20:4 × 0.5 4\times0.54×0.5 = 2;
2). 红色的线((1, 4)处的值 ):该像素点的梯度方向为80,在直方图的取值中恰好有80,则直接把其梯度大小填在梯度直方图中
3). 黄色的线((7, 6)处的值 )当像素点梯度方向大小的取值大于160时,则为 160 – 0180 (0)之间,如:165 = 160 × 0.75 160\times0.75160×0.75 +180 × 0.25 180\times0.25180×0.25 ,则160:85 × 0.75 85\times0.7585×0.75 = 63.75,180(0):85 × 0.25 85\times0.2585×0.25 = 21.25 -
16 × 16 16\times1616×16 Block 归一化
每(2 × 2 2\times22×2)个Cell为一个block,总共15 × 7 15\times715×7个block(相当于对已经分成16*8个Cell做2 × 2 2\times22×2的卷积)
计算每个block 的梯度直方图,并归一化,每个block都有9◊4个值(一共有4个Cell,直方图以(0-180)分成了9个bin) -
计算Hog特征描述
15 × 7 × 36 ( 4 × 9 ) = 3780 15\times7\times36 (4\times9)=378015×7×36(4×9)=3780
最后得到一个长度为3780的特征向量(梯度方向直方图特征)
-
-
-
-
两张图像进行全景图拼接的计算思路(利用SIFT特征)
-
主要分为以下几个步骤:
(1) 读入两张图片并分别提取SIFT特征
(2) 利用k-d tree和BBF算法进行特征匹配查找
(3) 利用RANSAC算法筛选匹配点并计算变换矩阵 图形对齐
(3) 图像融合
-
-
图像分类的计算思路(利用HOG特征)
机器学习
-
机器学习、深度学习的概念和关系
- 深度学习是一种特殊的机器学习,它通过学习将世界表示为嵌套的概念层次结构来实现强大的功能和灵活性,每个概念都是根据更简单的概念进行定义的,而更抽象的表示则用不那么抽象的概念计算出来。
-
卷积神经网络中的卷积核计算
- 给出输入、卷积核、Stride、Padding信息、计算输出 P51
-
卷积神经网络的输入输出尺寸计算
- 给出输入尺寸、卷积核尺寸、Stride、Padding信息,给出输出尺寸 P53
-
全连接神经网络向前和向后计算过程
- 给出网络结构、初始化参数,向前计算得到结果,并反向更新参数



[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Vi4SU67v-1648277961787)(C:\Users\ACID\AppData\Roaming\Typora\typora-user-images\image-20211208201540509.png)]
-
GAN的概念、生成器、判别器之间互性竞争提升的基本原理
视频和音频
-
音频数据在计算机中的表示方式(采样、量化的基本理解)
-
数字化音频:采样->量化->编码
-
传统的声音处理方法是通过话筒等设备把声音的振动转化成模拟的电流, 经过放大和处理, 然后记录到磁带或传至音箱等设备发声。这种方法失真较大, 且消除噪音困难, 也不易被编辑和修改。声音卡的出现解决了模拟方法中存在的问题, 它采用数字化方法来处理声音。数字化的声音数据就是音频数据。
数字化声音的过程实际上就是以一定的频率对来自microphone 等设备的连续的模拟音频信号进行模数转换(ADC)得到音频数据的过程;数字化声音的播放就是将音频数据进行数模转换(DAC)变成模拟音频信号输出。在数字化声音时有两个重要的指标,即采样频率(Sampling Rate)和采样大小(SamplingSize)。采样频率即单位时间内的采样次数, 采样频率越大, 采样点之间的间隔越小, 数字化得到的声音就越逼真, 但相应的数据量增大, 处理起来就越困难;采样大小即记录每次样本值大小的数值的位数, 它决定采样的动态变化范围, 位数越多, 所能记录声音的变化程度就越细腻, 所得的数据量也越大。
-
-
数字媒体压缩编码的必要性
- 从信息论观点来看,图像作为一个信源,描述信源的数据 是信息量(信源熵)和信息冗余量之和。信息冗余量有许多种,如空间冗余,时间冗余,结构冗余,知识冗余,视觉冗余等,数据压缩实质上是减少这些冗余量。可见冗余量减少可以减少数据量而不减少信源的信息量。从数学上讲,图像可以看作一个多维函数,压缩描述这个 函数的数据量实质是减少其相关性。另外在一些情况下,允许图像有一定的失真,而并不妨碍图像的实际应用,那么数据量压缩的可能性就更大了。
- 数字化信息的数据量十分庞大,无疑给存储器的存储量、同新干线的信道传输率以及计算机的速度都增加了极大的压力。如果单纯靠扩大存储容量、增加通信干线传输速率的办法来解决问题时不现实的。通过数据压缩技术可以大大降低数据量,以压缩的形式存储和传输,既节约了存储空间,又提高了传输效率,同时也使计算机处理速度加快,保证播放出高质量的视频核音频节目。
-
数字媒体压缩和通用数据压缩的差异
-
压缩分类
根据压缩后的图像能否完全恢复将图像压缩方分为两种:一种是无损压缩;另一种是有损压缩。 -
- 无损压缩
- 利用无损压缩方法消除或减少的各种形式的冗余可以重新插入到数据中,因此,无损压缩是可逆过程,也称无失真压缩。 为了消除或减少数据中的冗余度,常常要用信源的统计特性或建立信源的统计模型,因此许多实用的无损压缩技术均可归结为统计编 码方法。 统计编码方法中常用的有 Huffman 编码、算术编码、RLE(Run Length Encoding)编码等。 此外统计编码技术在各种有损压缩 方法中也有广泛的应用。
- 有损压缩
有损压缩法压缩了熵,信息量会减少,而损失的信息量不能再恢复,因此有损压缩是不可逆过程。 有损压缩主要有两大类:特征 提取和量化方法。 特征提取的编码方法如模型基编码、分形编码等。 量化是有损压缩最基本的形式,其优点是可以得到比无损压缩 高得多的压缩比。 有损压缩只能用于允许一定程度失真的情况,比如对图像、声音、视频等数据的压缩。
无损压缩和有损压缩结合形成了混合编码技术,它融合了各种不同的压缩编码技术,很多国际标准都是采用混合编码技术,如 JPEG,MPEG 等标准。 利用混合编码对自然景物的灰度图像进行压缩一般可压缩几倍到十几倍,而对于自然景物的彩色图像压缩比 将达到几十甚至上百倍。
-
通用数据压缩算法针对的不是某种具体的音频或者视频信息,而是一种通用的数据信息,我们并不知道什么信息能够损失,什么信息该保留,所以它肯定就是无损压缩了。
-
-
文件格式和编码方式的差异
-
文件是既包括视频又包括音频、甚至还带有脚本的一个集合,也可以叫容器;文件当中的视频和音频的压缩算法才是具体的编码。
AVI:音视频交互存储,最常见的音频视频容器。支持的视频音频编码也是最多的
MPG:MPEG编码采用的音频视频容器,具有流的特性。里面又分为 PS,TS 等,PS 主要用于 DVD 存储,TS 主要用于 HDTV。
VOB:DVD采用的音频视频容器格式(即视频MPEG-2,音频用AC3或者DTS),支持多视频多音轨多字幕章节等。
MP4:MPEG-4编码采用的音频视频容器,基于 QuickTime MOV 开发,具有许多先进特性。
3GP:3GPP视频采用的格式,主要用于流媒体传送。
ASF:Windows Media 采用的音频视频容器,能够用于流传送,还能包容脚本等。
RM:RealMedia 采用的音频视频容器,用于流传送。
MOV:QuickTime 的音频视频容器,恐怕也是现今最强大的容器,甚至支持虚拟现实技术,Java 等,它的变种 MP4,3GP都没有这么厉害。
MKV:MKV 它能把 Windows Media Video,RealVideo,MPEG-4 等视频音频融为一个文件,而且支持多音轨,支持章节字幕等。
WAV :一种音频容器(注意:只是音频),大家常说的 WAV 就是没有压缩的 PCM 编码,其实 WAV 里面还可以包括 MP3 等其他 ACM 压缩编码。
WMV:是微软推出的一种流媒体格式,它是在“同门”的ASF(Advanced Stream Format)格式升级延伸来得。
H.264是一种高性能的视频编解码技术。
目前国际上制定视频编解码技术的组织有两个,一个是“国际电联(ITU-T)”,它制定的标准有H.261、H.263、H.263+等,另一个是“国际标准化组织(ISO)”它制定的标准有MPEG-1、MPEG-2、MPEG-4等。
而H.264则是由两个组织联合组建的联合视频组(JVT)共同制定的新数字视频编码标准,所以它既是ITU-T的H.264,又是ISO/IEC的MPEG-4高级视频编码(Advanced Video Coding,AVC),而且它将成为MPEG-4标准的第10部分。
因此,不论是MPEG-4 AVC、MPEG-4 Part 10,还是ISO/IEC 14496-10,都是指H.264。
AVC1属于H.264的一种,是苹果开发的符合H.264/AVC的编码
MPEG-4 编码格式有多种编码器实现:1998年微软开发了第一个在PC上使用的MPEG-4编码器,它包括MS MPEG4V1、MS MPEG4V2、MS MPEG4V3的系列编码内核;DXN公司的DivX5系列。开源的Xvid.
AAC:(Advanced Audio Coding),中文称为“高级音频编码”,出现于1997年,基于 MPEG-2的音频编码技术。由Fraunhofer IIS、杜比实验室、AT&T、Sony(索尼)等公司共同开发,目的是取代MP3格式。2000年,MPEG-4标准出现后,AAC 重新集成了其特性,加入了SBR技术和PS技术,为了区别于传统的 MPEG-2 AAC 又称为 MPEG-4 AAC。
MP3: 是ISO标准MPEG1和MPEG2第三层(Layer 3),采样率16-48kHz,编码速率8K-1.5Mbps。1987年,Fraunhofer IIS就开始了“EUREKA project EU147, Digital Audio Broadcasting (DAB)”的研发,而这就是MP3的前身。通过和Dieter Seitzer教授的合作,他们开发出了著名的ISO-MPEG Audio Layer-3压缩算法。1993年这个算法被整合到MPEG-1标准中,从此MP3被投入使用。
-
文件格式(或文件类型)是指电脑为了存储信息而使用的对信息的特殊编码方式,是用于识别内部储存的资料。比如有的储存图片,有的储存程序,有的储存文字信息。每一类信息,都可以一种或多种文件格式保存在电脑存储中。每一种文件格式通常会有一种或多种扩展名可以用来识别,但也可能没有扩展名。扩展名可以帮助应用程序识别的文件格式。
对于硬盘机或任何电脑存储来说,有效的信息只有0和1两种。所以电脑必须设计有相应的方式进行信息-位元的转换。对于不同的信息有不同的存储格式。文件格式也意味着文件的用途。
-