ACL 2020 亮点摘要
字幕组双语原文:ACL 2020 亮点摘要
英语原文:Highlights of ACL 2020
翻译:雷锋字幕组(唐里、张超726、情报理论与实践、Danielan)
今年国际计算语言学协会(ACL)变为线上举办了,很遗憾我没多少机会去和其他学者交流,和同事们叙叙旧,但是遗憾之余值得庆幸的是我也相比平时听了更多讲座。因此我决定将我做的笔记分享出来并讨论一些行业总体趋势。本文不会对 ACL 进行详尽的介绍,内容的选择也是完全基于本人的兴趣。同时我也非常推荐读者看一看最佳论文。
近年来整体趋势
在根据我自身参与的讲座来讨论研究趋势之前(当然参与讲座数量有限,会存在误差),让我们来看一看ACL网页上的一些整体数据吧。今年收到交稿量最多的方向分别是通过机器学习处理自然语言,对话和交互系统,机器翻译,信息提取和自然语言处理的应用及生成。
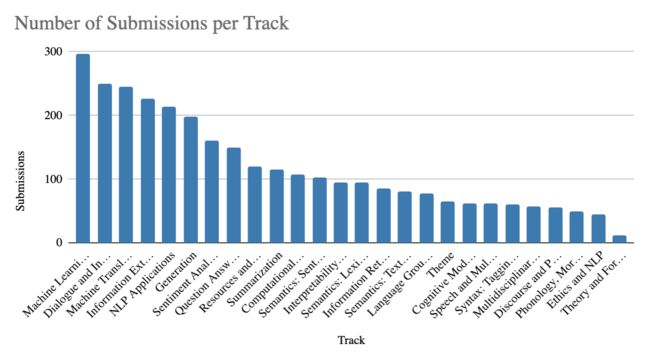
上图是每个研究方向提交稿件的数量 来源
这些数据相比往年怎么样呢?下图显示了从2010年后每个方向论文数量的变化。图源Wanxiang Che
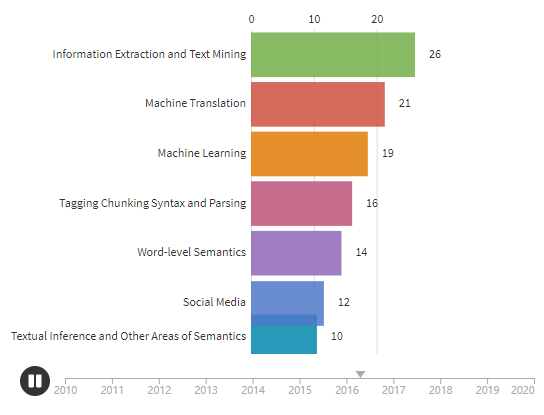
总的来说,论文有从基础任务到高级任务发展的趋势,例如从通过单词级,句子级语义和语篇的句法,过渡到对话。机器学习方向研究也正稳步增加,越来越多的文章提出具有普遍性目标的模型,而这些模型都基于多个任务来衡量。
ACL 2020 趋势
“我调整了基于某任务的BERT模型,然后在某评价标准下表现更好了”这类论文更少了
在自然语言处理研究有个反复出现的模式,1. 介绍一个新模型;2. 通过改进模型,或者将其应用于多任务实现一些容易的目标然后发表;3. 发表文章分析其不足之处或缺陷;4. 发表新的数据集。尽管某些步骤可能同时进行,我得说我们现在就处于2和3之间。小标题的结论是基于我选择的论文得出的,而我很大程度上过滤掉了这类文章。所以或许换一种说法,那就是今年ACL 2020 还是有挺多文章不是这一类型的。
不再依赖大型已标注数据集
在过去两年中我们可以发现研究向这些步骤靠近,先基于无标记文本的自监督方法进行预训练然后在更小的具体任务数据上微调。在今年会议上,很多论文聚焦于更少监督的训练模型。这有一些替代方案,及其示例论文:
无监督方法:Yadav等人提出了一个基于检索的问答方法,这种方法可以迭代地将询问提炼到1KB来检索回答问题的一些线索。在常识类多选任务上通过计算每个选项的合理性得分(利用Masked LM),Tamborrino等人取得了令人欣喜的成果。
数据增强(Data augmentation):Fabbri等人提出了一种方法可以自动生成上下文,问题和回答三合一的形式来训练问答模型。他们首先检索和原始数据相似的上下文,生成回答:是或否,并且以问句形式向上下文提问(what, when, who之类开头的问句)然后基于这三件套训练模型。Jacob Andreas提出将不常见的短语替换为在相似语境下更常用的短语从而改进神经网络中的组合泛化能力。Asai和Hajishirzi用人工例子增加问答训练数据,这些例子都是从原始训练数据中按逻辑衍生出来用以加强系统性和传递一致性。
元学习(Meta learning):Yu等人利用元学习去迁移知识用以从高源语言(high-resource language)到低源语言(low-resource language)的上义关系检测。
主动学习(Active learning):Li等人搭建了一个高效的标注框架,通过主动学习选取最有价值的样本进行批注进行共指关系解析。
语言模型并不是你所需要的全部ーー检索又回来了
我们已经知道,语言模型的知识是缺乏和不准确的。在这次会议上,来自 Kassner and Schütze 和 Allyson Ettinger 的论文表明某些语言模型对否定不敏感,并且容易被错误的探针或相关但不正确的答案混淆。目前采用了多种解决方案:
检索:在Repl4NLP研讨会上的两次受邀演讲中,有两次提到了检索增强的LMs。 Kristina Toutanova谈到了谷歌的智能领域,以及如何用实体知识来增强LMs(例如,这里和这里)。 Mike Lewis谈到了改进事实知识预测的最近邻LM模型,以及Facebook的将生成器与检索组件相结合的RAG模型。
使用外部知识库:这已经普遍使用好几年了。Guan等人利用常识知识库中的知识来增强用于常识任务的GPT-2模型。Wu等人使用这样的知识库生成对话。
用新的能力增强 LMs:Zhou 等人训练了一个 LM,通过使用带有模式和 SRL 的训练实例来获取时间知识(例如事件的频率和事件的持续时间) ,这些训练实例是通过使用带有模式和 SRL 的信息抽取来获得的。Geva 和 Gupta通过对使用模板和需要对数字进行推理的文本数据生成的数值数据进行微调,将数值技能注入 BERT 中。
可解释 NLP
检查注意力权重今年看起来已经不流行了,取而代之的关注重点是生成文本依据,尤其是那些能够反映判别模型决策的依据。Kumar 和 Talukdar 提出了一种为自然语言推断(NLI)预测忠实解释的方法,其方法是为每个标签预测候选解释,然后使用它们来预测标签。Jain 等人 开发了一种忠实的解释模型,其依赖于事后归因(post-hoc)的解释方法(这并不一定忠实)和启发式方法来生成训练数据。为了评估解释模型,Hase 和 Bansa 提出通过测量用户的能力,在有或没有给定解释的前提下来预测模型的行为。
反思NLP的当前成就,局限性以及对未来的思考
ACL今年有一个主题类别,主题是“通观现状与展望未来”。
我们求解的是数据集,而不是任务。在过去的几年中,这种说法反复出现,但是如今,我们的主要范式是训练庞大的模型,并在与我们的训练集非常相似的众包测试集上对其进行评估。荣誉主题奖论文作者塔尔·林岑(Tal Linzen)认为,我们在大量数据上训练模型,这些数据可能无法从人们可用的数据量中学到任何东西,而且这些模型在人类可能认为不相关的数据中找到统计模式。 他建议,今后,我们应该标准化中等规模的预训练语料库,使用专家创建的评估集,并奖励成功的一次性学习。
凯西·麦基翁(Kathy McKeown)的精彩主题演讲也谈到了这一点,并补充说排行榜并不总是对推动这一领域有所帮助。 基准通常会占据分布的顶端,而我们需要关注分布的尾部。 此外,很难使用通用模型(例如LM)来分析特定任务的进步。 在她的终身成就奖访谈中,邦妮·韦伯强调需要查看数据并分析模型错误。 即使是一些琐碎的事情,比如同时查看精确度和回忆,而不是只查看F1的总分,也可以帮助理解model s的弱点和长处。
当前模型和数据存在固有的局限性。 邦妮还说,神经网络能够解决不需要深入理解的任务,但是更具挑战性的目标是识别隐含的含义和世界知识。 除上述论文外,几篇论文还揭示了当前模型的局限性:例如,Yanaka等人。 和Goodwin等 指出神经NLU模型缺乏系统性,几乎不能概括学习到的语义现象。 艾米莉·班德(Emily Bender)和亚历山大·科勒(Alexander Koller)的最佳主题论文认为,仅从形式上学习意义是不可能的。 Bisk等人在预印本中也提出了类似的要求。 提倡使用多种方式学习意义。
我们需要远离分类任务。 近年来,我们已经看到了许多证据,证明分类和多项选择任务很容易进行,并且模型可以通过学习浅层的数据特定模式来达到较高的准确性。 另一方面,生成任务很难评估,人类评估目前是唯一的信息量度,但是却很昂贵。 作为分类的替代方法,Chen等。 将NLI任务从三向分类转换为较软的概率任务,旨在回答以下问题:“在假设前提下,假设成立的可能性有多大?”。 Pavlick和Kwiatkowski进一步表明,即使是人类也不同意某些句子对的并列标签,并且在某些情况下,不同的解释可以证明不同的标签合理(并且平均注释可能会导致错误)。
我们需要学习处理歧义和不确定性。 Ellie Pavlick在Repl4NLP上的演讲讨论了在明确定义语义研究目标方面的挑战。 将语言理论天真地转换为NLI样式的任务注定会失败,因为语言是在更广泛的上下文中定位和扎根的。 盖·艾默生(Guy Emerson)定义了分布语义的期望属性,其中之一是捕获不确定性。 冯等。 设计的对话框响应任务和模型,其中包括“以上皆非”响应。 最后,Trott等 指出,尽管语义任务关注的是识别两种话语具有相同的含义,但识别措辞上的差异如何影响含义也很重要。
有关道德伦理的讨论(很复杂)
ACL 在道德伦理方面的进步是非常显著的。前几年,NLP 中道德伦理还少有人研究,但如今却已然是 ACL 的一大类别,而且我们所有人在提交其它类别的论文时也都会考虑伦理道德。事实上,我们这个社区现在开始转向批评那些探讨重要的公平性问题而同时又未能解决其它道德伦理考虑的论文。
我强烈推荐观看 Rachael Tatman 在 WiNLP 研讨会上洞见深入的主题演讲「What I Won’t Build(我不会构建的东西)」。Rachael 说明了她个人不会参与构建的那几类系统,包括监控系统、欺骗与其交互的用户的系统、社会类别监测系统。她提供了一个问题列表,研究者可用来决定是否应该构建某个系统:
-
该系统将让哪些人获益?
-
该系统对哪些人有害?
-
用户可以选择退出吗?
-
该系统会强化还是弱化系统的不公平性?
-
该系统总体上会让世界变得更好吗?
Leins et al. 提出了许多有趣但仍待解答的道德伦理问题,比如符合道德伦理的 NLP 研究是怎样的,这应该由谁、通过什么方式决定?模型的预测结果应该由谁负责?ACL 应该尝试将自己定位为道德卫士吗?这篇论文讨论的问题之一是模型的双重使用问题:一个模型既可以用于好的目的,也可以用于坏的目的。事实上,会议期间,针对 Li et al. 的最佳演示论文发生了一场 Twitter 争论(很不幸该争论由一个匿名账号主导)。该论文提出了一个出色的多媒体知识提取系统。
其它值得关注的论文
本文作者还列举其它一些不属于以上类别的论文。
Cocos and Callison-Burch 创建了一个大规模的标注了含义的句子资源,其中的含义是通过同等含义的词进行标注的,比如 bug-microphone 中 bug 是个多义词,这里使用 microphone 进行标注,就固定了其小型麦克风 / 窃听器的含义,而非虫子的含义。
Zhang et al. 提出了一种用于跟踪文本出处的方法,包括其作者和其它来源的影响。Chakrabarty et al. 解决了将带讽刺的句子转译为不带讽刺句子的问题,他还基于对讽刺的极富洞见的观察而构建了一个模型。
Wolfson et al. 将问题理解引入为一个单独的任务,其按照人类的方式通过将复杂问题分解为更简单的问题来进行解答。
Gonen et al. 提出了一种用于测量词义变化的非常直观和可解释的方法,其具体做法为检查词分布的最近邻。
Anastasopoulos and Neubig 表明尽管使用英语作为中心语言来进行跨语言嵌入学习是最佳实践,但却往往是次优的;该论文提议了一些用于选择更优中心语言的一般原则。
最后,Zhang et al. 众包了 Winograd 模式挑战赛的解释,并分析了解决该任务所需的知识类型以及现有模型在每种类别上的成功程度。
总结和思考
这些论文和主题演讲给我带来一种感觉,尽管过去几年取得了巨大的进步,但我们还没有走上正确的方向,也没有一条非常可行的前进道路。 我认为主题类别的变化具有正面意义,这能鼓励研究者不执着于容易取得的小进步,而是着眼大局。
我喜欢能够在自己的时间里(以喜欢的速度)观看这么多演讲,但这样也确实错过了与其他学者的互动,我不认为与不同时区的参与者呆在一个虚拟聊天室里是一个很好的替代方案。我真的希望疫情之后,会议将再次线下举行,但希望同时也允许人们以更低的注册费用远程参会。
希望明年能看到你们排着队买难喝的咖啡!(译者:笑)