MAE自监督算法介绍和基于EasyCV的复现
作者:贺弘、谦言、临在
导言
自监督学习(Self-Supervised Learning)能利用大量无标注的数据进行表征学习,然后在特定下游任务上对参数进行微调。通过这样的方式,能够在较少有标注数据上取得优于有监督学习方法的精度。近年来,自监督学习受到了越来越多的关注,如Yann Lecun也在 AAAI 上讲 Self-Supervised Learning 是未来的大势所趋。在CV领域涌现了如SwAV、MOCO、DINO、MoBY等一系列工作。MAE是kaiming继MOCO之后在自监督学习领域的又一力作。首先,本文会对MAE进行解读,然后基于EasyCV库的精度复现过程及其中遇到的一些问题作出解答。
概述
MAE的做法很简单:随机mask掉图片中的一些patch,然后通过模型去重建这些丢失的区域。包括两个核心的设计:1.非对称编码-解码结构 2.用较高的掩码率(75%)。通过这两个设计MAE在预训练过程中可以取得3倍以上的训练速度和更高的精度,如ViT-Huge能够通过ImageNet-1K数据上取得87.8%的准确率。
模型拆解
MAE属于自编码器(AutoEncoder)的一种,由编码器和解码器两个部分组成。类似于常见的自编码器,MAE会先通过编码器将图片patch映射到隐空间。然后,基于解码器将隐空间上的特征变量重构成图片patch。和常见自编码器的区别是非对称的编码解码结构。这个非对称性主要体现在以下两点:
- 轻量化的解码器结构
- 在编码器阶段,仅将未被mask掉的图片patch作为输入。在解码器阶段会将编码器输出的隐变量和mask token共同作为输入去重建完成的图片。

掩码策略
首先,直接采用ViT的做法将图片分成不重叠的patch(如vit-b会将图片划分成16x16的图像块),然后通过均匀采样策略对这些patch进行采样,并丢弃未被选中的部分。MAE所采用的掩码策略有如下两个特点:
1.在算法中,使用了75%的masking ratio来丢弃图片patch。作者指出,通过high masking ratio可以有效减少输入的冗余程度,使重建任务不能够通过简单的参考邻近patch来完成。文中,也通过实验证明了这一观点。

关于Masking ratio的实验是MAE最精彩的一部分,随着mask ratio的增加,fine-tuning和linear proing的精度逐渐攀升,甚至到75%还没有下降,这一点打破了BERT(15%)、BEiT(40%)的做法,进一步将mask 预训练方式在NLP领域的成功在CV领域实现复制。
2.采用了均匀采样策略可以有效的避免potential center bias(丢弃掉的patch都靠近图片中心)。对mask策略的消去实验如下表所示。

编码器
MAE encoder采用的是ViT结构。在对图像patch进行采样后,仅保留25%未被mask的图像patch作为输入,通过linear Projection进行编码后,加上positional embedding,然后输入到一系列的Transformer blocks中。相比于Bert中用mask token来代替被mask区域的做法,MAE encoder直接舍弃掉了mask的部分,通过这种方式可以有效的减少预训练过程中需要消耗的计算资源和训练时间。
文中,作者对编码器是否保留mask token进行了消融实验,可以看出在编码器阶段舍弃mask token不会对预训练模型的表征能力造成影响,同时能够显著的加速训练进程。

解码器
MAE decoder由一连串的Transfomer block组成。和encoder不同的是,MAE decoder的输入不仅包括未被mask的图像patch经过encoder编码后的特征,还包括了被mask掉的部分。对于mask掉部分的输入,会用一个共享参数,且可学习的mask token代替作为输入。除此之外,为了保证不同的mask token能够区分在图像中的不同位置,在输入到decoder之前,会对整体的输入加上positional embedding。
在MAE中,解码器仅会在预训练阶段用于图片的重建工作。文中采用了轻量化的解码器结构,对于每个token的计算量仅有相对于解码器的10%以下。通过这种设计,就算在解码阶段用了完整数量的token作为输入,对计算资源的消耗也不会显著增加。
文中,作者对解码器的depth和width两个维度进行对比实验,可以看出一个较轻量化的解码器,就足以是模型学习到有效的表征。

重建目标
MAE预训练任务的目标是重建被mask掉的像素值。MAE decoder输出关于每个图像patch的表征后,会经过一个linear projection层映射成与图像像素数目相同维度的向量(PxPx3)。仅采用MSE作为损失函数,计算预测向量和被mask掉像素值之前的MSE loss。
需要额外指出的是,作者使用了归一化后的图像patch作为重建的目标。通过实验证明,这种做法可以提升模型的表征能力。

模型评价
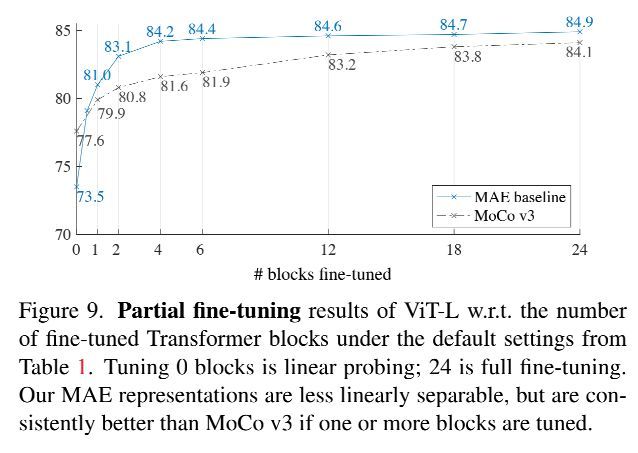
文中除了从linear probing和Finetuning两个角度对模型的表征能力做出评价外,还采用了Partial Fine-tuning的方式进行评价,相比于linear probing这种之前普遍采用的评价方式,能够更好的反映预训练模型对非线性特征的表征能力。从下图可以看出,MAE算法仅仅对一个transformer block进行fintune精度就从73.5%提升到81%。同时与MOCOv3相比,MOCOv3虽然在linear probing的时候具有更高的精度,但是在partial fine-tuning时,MAE的精度都要高于MOCOv3。可以看出,MAE虽然对线性特征的表征能力要弱于MOCOv3,但是具有更好的非线性特征表征能力。
EasyCV介绍
EasyCV是阿里巴巴开源的基于Pytorch,以自监督学习和Transformer技术为核心的 all-in-one 视觉算法建模工具。在数据层面,EasyCV提供了提供了不同数据源(data_source)的抽象,支持多种开源数据集例如Cifar、ImageNet、CoCo等,并将各种数据预处理抽象成若干独立的pipeline,可以通过配置文件灵活的配置数据预处理流程。在API层面,提供了统一的训练、评估、模型导出、预测的API。因此,基于EasyCV,仅需要实现模型部分的代码,就可以很便捷的完成MAE的复现。
除此之外,EasyCV支持aliyun PAI产品中方便的进行部署(如PAI-DLC),无需多余的修改即可在DLC上同时进行多机或者多组实验,加快复现进度。
复现过程 & 踩坑总结
接下来我们介绍如何在EasyCV框架中进行MAE算法的复现和踩坑总结,首先,说明一下预训练的整体流程。
1.将输入图像划分成不同的patch,并将patch经过Linear Projection进行映射,再加上positional embedding得到image token
# embed patches
x = self.patch_embed(x)
# add pos embed w/o cls token
x = x + self.pos_embed[:, 1:, :]2.将image token按75%的比例进行随机mask,通过随机生成的张量noise进行argsort操作的方式来完成对image patch的随机mask。其中,需要注意,该函数中额外传回两个参数mask和ids_restore。mask记录了mask patch在原始图片中的位置,用于后续损失函数的计算。ids_restore记录了传入encoder的image token在原始图片中的位置,用于后续再decoder前进行unshuffle操作。
def random_masking(self, x, mask_ratio):
"""
Perform per-sample random masking by per-sample shuffling.
Per-sample shuffling is done by argsort random noise.
x: [N, L, D], sequence
"""
N, L, D = x.shape # batch, length, dim
len_keep = int(L * (1 - mask_ratio))
noise = torch.rand(N, L, device=x.device) # noise in [0, 1]
# sort noise for each sample
ids_shuffle = torch.argsort(
noise, dim=1) # ascend: small is keep, large is remove
ids_restore = torch.argsort(ids_shuffle, dim=1)
# keep the first subset
ids_keep = ids_shuffle[:, :len_keep]
x_masked = torch.gather(
x, dim=1, index=ids_keep.unsqueeze(-1).repeat(1, 1, D))
# generate the binary mask: 0 is keep, 1 is remove
mask = torch.ones([N, L], device=x.device)
mask[:, :len_keep] = 0
# unshuffle to get the binary mask
mask = torch.gather(mask, dim=1, index=ids_restore)
return x_masked, mask, ids_restore
3.将保留的image token输入到encoder得到image embeding
# apply Transformer blocks
for blk in self.blocks:
x = blk(x)
x = self.norm(x)4.将image embeding和mask token一起进行unshuffle操作,再加上positional embedding后,输入到decoder中
# append mask tokens to sequence
mask_tokens = self.mask_token.repeat(
x.shape[0], ids_restore.shape[1] + 1 - x.shape[1], 1)
x_ = torch.cat([x[:, 1:, :], mask_tokens], dim=1)
x_ = torch.gather(
x_,
dim=1,
index=ids_restore.unsqueeze(-1).repeat(1, 1, x.shape[2]))
x = torch.cat([x[:, :1, :], x_], dim=1)
# add pos embed
x = x + self.decoder_pos_embed5.将输出的vector与归一化后的image patch计算mse loss,并反向传播更新梯度。在计算loss时,有两个需要注意的点。1、首先,需要对作为target的图像patch做归一化。2、在计算损失函数时,只对mask patch的部分计算损失函数。
def forward_loss(self, imgs, pred, mask):
"""compute loss
Args:
imgs: (N, 3, H, W)
pred: (N, L, p*p*3)
mask: (N, L), 0 is keep, 1 is remove,
"""
target = self.patchify(imgs)
if self.norm_pix_loss:
mean = target.mean(dim=-1, keepdim=True)
var = target.var(dim=-1, keepdim=True)
target = (target - mean) / (var + 1.e-6)**.5
loss = (pred - target)**2
loss = loss.mean(dim=-1) # [N, L], mean loss per patch
loss = (loss * mask).sum() / mask.sum() # mean loss on removed patches
return loss精度复现
参考https://github.com/facebookresearch/mae,我们在单机八卡V100的配置下,对ViT-base和ViT-large的在ImageNet1K上fintune的精度进行了复现。结果如下表所示。
| Algorithm | ImageNet1K Top-1(%) | config |
| vit-b 400 epoch | 83.13 | mae_vit_base_patch16_8xb64_100e_lrdecay075_fintune |
| vit-b 1600 epoch | 83.55 | mae_vit_base_patch16_8xb64_100e_lrdecay065_fintune |
| vit-l 1600 epoch | 85.70 | mae_vit_large_patch16_8xb16_50e_lrdecay075_fintune |
下面分享一下在复现过程中遇到的一些问题和调参,如有问题请指出。
- 在fintune时,MAE的实现使用了mixup+cutmix的数据增广方式,若仅使用mixup精度会下降。
- 在fintune时,MAE中使用了所有token特征求平均的方式作为分类head的输入,而cls token作为输入时精度会有下降。
- 在预训练过程中,确保使用了足够大的weight_decay(如官方设为0.05),否则在下游任务fintune时,很容易出现梯度爆炸的问题。而在下游分类任务fintune时,设置一个较小的weight,精度会有一些提升。(PS 在复现vit-l时,在pretrain时设置weight_decay 0.01,在fintune时会出现梯度爆炸)
下表展示了vit-b模型的复现过程上述过程的精度提升
| parameter setting | ImageNet1K Top-1(%) |
| vit-b 1600 epoch(mixup,cls token) | 83.21 |
| vit-b 1600 epoch(mixup+cutmix,cls token) | 83.36 |
| vit-b 1600 epoch(mixup+cutmix,global_pool) | 83.55 |
我们在开源框架EasyCV中复现了MAE算法。详细参数配置和实验日志参考github上的自监督modelzoo(https://github.com/alibaba/EasyCV/blob/master/docs/source/model_zoo_ssl.md)。
Tutorial
接下来,我们将通过一个实际的例子介绍如何基于EasyCV进行MAE算法的预训练和微调,也可以在该链接查看详细步骤。
一、安装依赖包
如果是在本地开发环境运行,可以参考该链接安装环境。若使用PAI-DSW进行实验则无需安装相关依赖,在PAI-DSW docker中已内置相关环境。
二、数据准备
自监督训练只需要提供无标注图片即可进行, 你可以下载ImageNet 数据,或者使用你自己的图片数据。需要提供一个包含若干图片的文件夹路径p,以及一个文件列表,文件列表中是每个图片相对图片目录p的路径。
图片文件夹结构示例如下, 文件夹路径为./images
images/
├── 0001.jpg
├── 0002.jpg
├── 0003.jpg
|...
└── 9999.jpg文件列表内容如下:
0001.jpg
0002.jpg
0003.jpg
...
9999.jpg为了快速走通流程,我们也提供了一个小的示例数据集,执行如下命令下载解压:
wget http://pai-vision-data-hz.oss-cn-zhangjiakou.aliyuncs.com/data/imagenet_raw_demo/imagenet_raw_demo.tar.gz
tar -zxf imagenet_raw_demo.tar.gz
mv imagenet_raw_demo imagenet_raw三、模型预训练
以vit-base为示例。在EasyCV中,使用配置文件的形式来实现对模型参数、数据输入及增广方式、训练策略的配置,仅通过修改配置文件中的参数设置,就可以完成实验配置进行训练。可以直接下载示例配置文件。
rm -rf mae_vit_base_patch16_8xb64_1600e.py
wget http://pai-vision-data-hz.oss-cn-zhangjiakou.aliyuncs.com/release/doc/easycv/configs/selfsup/mae/mae_vit_base_patch16_8xb64_1600e.py查看easycv安装位置
# 查看easycv安装位置
import easycv
print(easycv.__file__)执行训练命令
python -m torch.distributed.launch --nproc_per_node=1 --master_port=29930 \
/home/pai/lib/python3.6/site-packages/easycv/tools/train.py mae_vit_base_patch16_8xb64_1600e.py --work_dir work_dir/selfsup/jpg/mae --launcher pytorch四、模型微调
1、对上一步得到的预训练模型的字段进行修改,以便用于fintune任务。
import torch
weight_path = 'work_dir/selfsup/jpg/mae/epoch_5.pth'
state_dict = torch.load(weight_path)['state_dict']
state_dict_out = {}
for key in state_dict:
state_dict_out[key.replace('encoder.','')] = state_dict[key]
torch.save(state_dict_out,weight_path)2、下载分类任务示例配置文件
rm -rf mae_vit_base_patch16_8xb64_100e_lrdecay065_fintune.py
wget http://pai-vision-data-hz.oss-cn-zhangjiakou.aliyuncs.com/release/doc/easycv/configs/selfsup/mae/mae_vit_base_patch16_8xb64_100e_lrdecay065_fintune.py3、执行训练命令
python -m torch.distributed.launch --nproc_per_node=1 --master_port=29930 \
/home/pai/lib/python3.6/site-packages/easycv/tools/train.py mae_vit_base_patch16_8xb64_100e_lrdecay065_fintune.py --work_dir work_dir/selfsup/jpg/mae --launcher pytorchEND
后续EasyCV会就SOTA论文复现进行系列的工作介绍,欢迎大家关注和使用,欢迎大家各种维度的反馈和改进建议以及技术讨论,同时我们十分欢迎和期待对开源社区建设感兴趣的同行一起参与共建。
项目开源地址:https://github.com/alibaba/Easy