初识神经网络和反向传播算法
今天来看一下西瓜书第五章——神经网络。
文章目录
-
-
- 定义
- 感知机与多层网络
- 误差逆传播算法
- 全剧最小与局部最小
-
以下介绍的是人工神经网络,是模拟生物神经网络进行信息处理的一种数学模型。
定义
神经网络最基本的成分是神经元模型,生物中如果某神经元的电位超过某个阈值,那么它就会被激活,向其他神经元发送化学物质。
以下是 M-P 神经元模型,由输入的信号 x i x_i xi 赋予权重 w i w_i wi 之后,对应相乘求和,通过阈值 θ \theta θ 比较,最后通过激活函数输出 0/1 一个新的神经元。

常用的激活函数有以下 4 种:

感知机与多层网络
感知机接收多个信号,输出一个信号。
y = { 0 , ∑ i = 1 n w i x i ≤ θ 1 , ∑ i = 1 n w i x i > θ y= \begin{cases} 0,\sum_{i=1}^{n}w_ix_i \le\theta \\\\ 1,\sum_{i=1}^{n}w_ix_i >\theta \end{cases} y=⎩⎪⎨⎪⎧0,∑i=1nwixi≤θ1,∑i=1nwixi>θ
感知机的学习规则:
对训练样例 ( x , y ) (x,y) (x,y),若当前的感知机输出为 y ^ \hat{y} y^,则感知机权重调整如下:
- w i ← w i + Δ w i w_i \gets w_i+\Delta w_i wi←wi+Δwi, Δ w i = η ( y − y ^ ) x i \Delta w_i=\eta(y-\hat{y})x_i Δwi=η(y−y^)xi
- 其中 η ∈ ( 0 , 1 ) \eta \in (0,1) η∈(0,1) 称为学习率,学习率越高,梯度下降的越快。
多层网络,即输入层和输出层还有多层神经元,称为隐含层。隐含层和输出层的神经元都需要通过激活函数生成。
更一般的,若每层神经元没有同层连接,也没有跨层连接,我们称该网络为多层前馈神经网络,当然,前馈并不意味着网络信号不能向后传,只是没有环或回路即可。例子如下图:
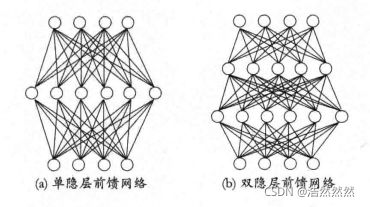
误差逆传播算法
误差逆传播算法简称 BP 算法,该算法不仅能训练多层前馈神经网络,也能训练递归神经网络。
给定训练集 D = { ( x 1 , y 1 ) , ⋯ , ( x m , y m ) } D=\left \{ (x_1,y_1),\cdots ,(x_m,y_m)\right \} D={(x1,y1),⋯,(xm,ym)},其中 x i ∈ R d x_i \in R^d xi∈Rd, y i ∈ R l y_i \in R^l yi∈Rl,分别为 d d d 维和 l l l 维的实数域。

为了方便描述,假定网络只有一个隐含层。
- 不妨设输入层有 d d d 个神经元,隐含层有 q q q 个神经元,输出层有 l l l 个神经元。
- 隐含层第 h h h 个神经元阈值为 γ h \gamma_h γh
- 输出层第 j j j 个神经元阈值为 θ j \theta_j θj
- 输入层第 i i i 和隐含层第 h h h 个神经元的权值为 v i h v_{ih} vih
- 隐含层第 h h h 和输出层第 j j j 个神经元的权值为 w h j w_{hj} whj。
- 隐含层第 h h h 个神经元的输入为 α h = ∑ i = 1 d v i h x i \alpha_h=\sum_{i=1}^{d}v_{ih}x_i αh=∑i=1dvihxi
- 输出层第 j j j 个神经元的输入为 β j = ∑ h = 1 q w h j b h \beta_j=\sum_{h=1}^{q}w_{hj}b_h βj=∑h=1qwhjbh
其中 b h b_h bh 为隐含层第 h h h 个神经元的输出值,即 b h = S i g m o i d ( α h − γ h ) b_h=Sigmoid(\alpha_h-\gamma_h) bh=Sigmoid(αh−γh)
那么,对样本 ( x k , y k ) (x_k,y_k) (xk,yk) 来说,若输出为 y ^ k = ( y ^ 1 k , ⋯ , y ^ l k ) \hat{y}_k=(\hat{y}_1^k,\cdots,\hat{y}_l^k) y^k=(y^1k,⋯,y^lk),那么就会有
y ^ j k = S i g m o i d ( β j − θ j ) \hat{y}_j^k=Sigmoid(\beta_j-\theta_j) y^jk=Sigmoid(βj−θj)
其 M S E MSE MSE 为
E k = 1 l ∑ j = 1 l ( y ^ j k − y j k ) 2 E_k=\frac{1}{l}\sum_{j=1}^{l}(\hat{y}_j^k-y_j^k)^2 Ek=l1j=1∑l(y^jk−yjk)2
同样的,在训练的每一轮中,用感知机学习规则对参数进行更新,对任意参数 ξ \xi ξ 的更新如下表达式:
ξ ← ξ + Δ ξ \xi \gets \xi + \Delta \xi ξ←ξ+Δξ
由于 B P BP BP 神经网络是基于梯度下降寻最优参数,我们给定一个学习率 η \eta η,以负梯度方向对参数进行调整。
我们的目的是更新如下参数:
ξ ∈ { w h j 、 θ j 、 v i h 、 γ h } \xi \in \left \{w_{hj}、\theta_j、v_{ih}、\gamma_h \right \} ξ∈{whj、θj、vih、γh}
即我们要求得:
Δ ξ = { Δ w h j = − η ∂ E k ∂ w h j Δ θ j = − η ∂ E k ∂ θ j Δ v i h = − η ∂ E k ∂ v i h Δ γ h = − η ∂ E k ∂ γ h \Delta \xi= \begin{cases} \Delta w_{hj} = -\eta \frac{\partial E_k}{\partial w_{hj}} \\\\ \Delta \theta_j = -\eta \frac{\partial E_k}{\partial \theta_j} \\\\ \Delta v_{ih} = -\eta \frac{\partial E_k}{\partial v_{ih}} \\\\ \Delta \gamma_h = -\eta \frac{\partial E_k}{\partial \gamma_h} \end{cases} Δξ=⎩⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎨⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎧Δwhj=−η∂whj∂EkΔθj=−η∂θj∂EkΔvih=−η∂vih∂EkΔγh=−η∂γh∂Ek
现在,我们来推导参数的更新。
我们先将 E k E_k Ek 的公式改写如下:
E k = 1 l ∑ j = 1 l ( y ^ j k − y j k ) 2 = 1 l ∑ j = 1 l ( S i g m o i d ( β j − θ j ) − y j k ) 2 = 1 l ∑ j = 1 l ( S i g m o i d ( ∑ h = 1 q w h j b h − θ j ) − y j k ) 2 = 1 l ∑ j = 1 l ( S i g m o i d ( ∑ h = 1 q w h j S i g m o i d ( ∑ i = 1 d v i h x i − γ h ) − θ j ) − y j k ) 2 \begin{aligned} E_k&=\frac{1}{l}\sum_{j=1}^{l}(\hat{y}_j^k-y_j^k)^2\\\\ &=\frac{1}{l}\sum_{j=1}^{l}(Sigmoid(\beta_j-\theta_j)-y_j^k)^2\\\\ &=\frac{1}{l}\sum_{j=1}^{l}(Sigmoid(\sum_{h=1}^{q}w_{hj}b_h-\theta_j)-y_j^k)^2\\\\ &=\frac{1}{l}\sum_{j=1}^{l}(Sigmoid(\sum_{h=1}^{q}w_{hj}Sigmoid(\sum_{i=1}^{d}v_{ih}x_i-\gamma_h)-\theta_j)-y_j^k)^2 \end{aligned} Ek=l1j=1∑l(y^jk−yjk)2=l1j=1∑l(Sigmoid(βj−θj)−yjk)2=l1j=1∑l(Sigmoid(h=1∑qwhjbh−θj)−yjk)2=l1j=1∑l(Sigmoid(h=1∑qwhjSigmoid(i=1∑dvihxi−γh)−θj)−yjk)2
注意到 S i g m o i d ′ ( x ) = S i g m o i d ( x ) ( 1 − S i g m o i d ( x ) ) Sigmoid'(x)=Sigmoid(x)(1-Sigmoid(x)) Sigmoid′(x)=Sigmoid(x)(1−Sigmoid(x)),可以方便我们求导。
于是,容易求得上述参数,如下:
Δ ξ = { Δ w h j = − η ∂ E k ∂ w h j = 2 l η y ^ j k ( 1 − y ^ j k ) ( y j k − y ^ j k ) b h Δ θ j = − η ∂ E k ∂ θ j = − 2 l η y ^ j k ( 1 − y ^ j k ) ( y j k − y ^ j k ) Δ v i h = − η ∂ E k ∂ v i h = 2 l η ∑ j = 1 l w h j b h ( 1 − b h ) y ^ j k ( 1 − y ^ j k ) ( y j k − y ^ j k ) x i Δ γ h = − η ∂ E k ∂ γ h = − 2 l η ∑ j = 1 l w h j b h ( 1 − b h ) y ^ j k ( 1 − y ^ j k ) ( y j k − y ^ j k ) \Delta \xi= \begin{cases} \Delta w_{hj} = -\eta \frac{\partial E_k}{\partial w_{hj}}=\frac{2}{l}\eta\hat{y}_j^k(1-\hat{y}_j^k)(y_j^k-\hat{y}_j^k)b_h \\\\ \Delta \theta_j = -\eta \frac{\partial E_k}{\partial \theta_j}=-\frac{2}{l}\eta \hat{y}_j^k(1-\hat{y}_j^k)(y_j^k-\hat{y}_j^k) \\\\ \Delta v_{ih} = -\eta \frac{\partial E_k}{\partial v_{ih}}=\frac{2}{l}\eta \sum_{j=1}^{l}w_{hj}b_h(1-b_h)\hat{y}_j^k(1-\hat{y}_j^k)(y_j^k-\hat{y}_j^k) x_i \\\\ \Delta \gamma_h = -\eta \frac{\partial E_k}{\partial \gamma_h}=-\frac{2}{l}\eta \sum_{j=1}^{l}w_{hj}b_h(1-b_h)\hat{y}_j^k(1-\hat{y}_j^k)(y_j^k-\hat{y}_j^k) \end{cases} Δξ=⎩⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎨⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎧Δwhj=−η∂whj∂Ek=l2ηy^jk(1−y^jk)(yjk−y^jk)bhΔθj=−η∂θj∂Ek=−l2ηy^jk(1−y^jk)(yjk−y^jk)Δvih=−η∂vih∂Ek=l2η∑j=1lwhjbh(1−bh)y^jk(1−y^jk)(yjk−y^jk)xiΔγh=−η∂γh∂Ek=−l2η∑j=1lwhjbh(1−bh)y^jk(1−y^jk)(yjk−y^jk)
需要注意的是, B P BP BP 神经网络目标是使得 M S E MSE MSE 最小,即求 m i n ( E = 1 m ∑ k = 1 m E k ) min(E=\frac{1}{m}\sum_{k=1}^{m}E_k) min(E=m1∑k=1mEk)
以上是标准的 B P BP BP 算法,每次对一个样本进行更新权值和阈值。若推导基于累计误差最小化的更新规则,就有累积 B P BP BP 算法。
全剧最小与局部最小
神经网络在迭代求解权值和阈值的过程中,是一个寻优的过程,如果说误差函数有多个极小值,最后找到的结果不一定是最优解,如下图:
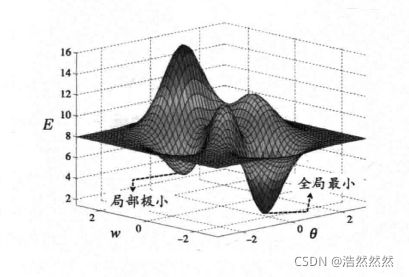
因此,我们常采用以下方法进行求解。
- 用多组不同参数值初始化多个神经网络。训练完,取误差最小的解作为参数。
- 用遗传算法寻优。
- 用随机梯度下降寻优。
参考资料
[1] 周志华.机器学习[M].北京:清华大学出版社,2020.