昆明房价的聚类分析(链家网爬虫+数据可视化+k-means算法聚类分析)
源码参见我上传的资源或者私聊我
昆明房价聚类分析(链家网爬虫+聚类分析房价)(k-means聚类分析)_聚类分析房价,kmeans聚类分析房价-机器学习文档类资源-CSDN下载
源码参见我上传的资源或者私聊我
昆明房价聚类分析(链家网爬虫+聚类分析房价)(k-means聚类分析)_聚类分析房价,kmeans聚类分析房价-机器学习文档类资源-CSDN下载
源码参见我上传的资源或者私聊我
昆明房价聚类分析(链家网爬虫+聚类分析房价)(k-means聚类分析)_聚类分析房价,kmeans聚类分析房价-机器学习文档类资源-CSDN下载
摘要: 科技加快了时代的进步,信息的传播更加迅速,面对大量的数据,数据挖据实现了对数据进行分析和获取相关知识的研究过程,目的为了使人们在其中提取所需要的数据。然而住房是民生之本,房价成了生活中大家所关注的问题,不少购房者将视线转移到二手的普通住房,但更多的人更多的缺少信息筛选的方法。本文研究通过机器学习工具Python。采用scratch爬虫对链家网的昆明市二手房源数据进行获取小区名称、类型、地址、售价等相关信息。经过数据清洗,使用 K-means聚类算法,对所获取的750余条数据(链家网前100页) 进行聚类分析,将其属性相似度较高进行划分。
关键词:数据挖掘、二手房价、网络爬虫、聚类分析
- 问题概述
我国地产市场发展十分迅速,而房屋价格总体上一直呈现上涨趋势,在房产交易中,二手房更加显得普遍,但房屋的架构受到多种因素的影响,本文以昆明二手住房为范例,探索影响房屋价格的多种因素,并做出聚类分析。
在对昆明二手房源进行聚类分析时,可以通过几个数据支撑数据挖掘过程,一是要明确解决的问题,确定挖掘的目标,二是根据不同的数据,选用不同的数据挖掘方法,三是数据集的准备与预处理,四是聚类分析,五是实验总结。
此次数据挖掘选取昆明所有城区且在网络(链家)显示在售房源进行分析。在爬取的过程中给,采用焦距爬虫的形式进行,针对网络中显示的二手房的地址、标题、价格、大小进行爬取分析。在数据挖掘的过程中,数据的预处理起到了十分重要的作用,它决定了数据挖掘的成败,因为在利用各种方式获取的原始数据中,会存在大量的缺失值或严重偏离预处理数据,在预处理阶段会对数据挖掘的结果有明显的影响的数据进行补充、删除等相关的处理。处理之后通过K-means算法,使得一簇中的实例间相似度较高的。

(链家网部分截图)
- 重点
- 此次分析过程中数据来源主要依据于网络数据,因此挑选数据集的来源尤为重要,同时在爬取的过程中需要做好预防放爬虫机制。
- 在数据清洗的过程中,需要做好数据的格式转化、存储方案的考虑方便后期方便进行数据的分析使用。
- 在数据的预处理时,应该充分考虑到数据值缺省、或者对数据会产生较大的影响的数据进行预处理。
- 在使用K-means算法时需要注意K值得选取,同时需要注意对离群点, 噪声敏感 (中心点易偏移)
- 难点:
- 在爬取数据的过程中需要注意所爬取资源网站的选取、网站的反爬虫机制,如果有反爬虫机制需要绕开其机制。
- 在爬取数据结束后需要对数据进行清洗过程,需要保证数据格式的一致性,同时需要保证所爬取数据有效。
- 采用K-means对数据进行聚类分析的过程中需要注意特殊点导致新的聚类新中心变化过大,从而影响整体效果。同时需要控制好迭代的次数。
- 国内外研究
随着数据挖掘的兴起,数据获取于数据分析的方式也更加多样化。目前针对是不护具获取,大多都是使用专用工具或者爬虫框架,目前国内较大的二手房网站较大的有链家网、五八同城、安居客等相关网站。
在对房价分析的解决方案,目前主要呈现为多元回归,通过多元回归方程找出房价价格影响因素之间的相互关系,从而建立回归方程。机器学习分析,通过建立机器学习的学习路径,通过训练数据建立大数据分析模型,利用梯度下降,形成分析决策模型。聚类分析,通过对房屋属性,将相似度大致相同的事物聚为一类。但更多的是通过R语言进行实现。目前国内比较常见为基于空间数据挖掘的房价聚类分析法。分析较为典型为北京、深圳等相关城市数据。
在针对房价问题进行分析问题中,较为成熟的有波士顿房价预测分析问题。针对此类问题,解决方式大多为基于线性回归分析、支持向量机、随机森林(机森林是一种多功能的机器学习算法,能够执行回归和分类的任务。)、增强回归树以及BP神经网络进行需求分析。本文主要利用K-means聚类分析算法对昆明房价进行分析。
- 数据来源及说明
- 数据说明
本次实验采用数据集合为针对于昆明地区的二手房源数据,主要是通过爬虫对链家网络中所公布在售的数据进行爬取,爬取数据总量为网络中前100页数据(包括失帧于错误数据)约800条。其中主要获取的信息包括:房屋的售价、地址、大小、类型。由于后期数据分析时需要对房屋价值进行分析,但是网络数据为房屋总价,且房价大多已设置了价格区间,则通过选取房屋公示价值的中位数作为房屋的总价值,房屋总面积与总价进行计算房屋单价。最终形成具有统一格式的完整数据集合,在保存时,第一列为房屋所在的小区,第二列为房屋类型,第三列为房屋所在的具体位置,具体格式为所属区域+所在片区+详细地址方式进行记录,第三列为房屋的每平米的单价。

(python爬取数据清洗后csv文件)
2、爬虫应用
利用python语言变写的链家网络爬虫进行原始数据的获取,主要的功能为爬取网站中所售房源的地址、类型、大小、售价等相关的属性,之后将爬取数据保存为csv文件方便下次的使用,为了能使得爬虫程序能够完整运行,在实现之前需要先进性其功能模块于需求的分析,在爬取的过程中通过构建header头伪装为浏览器避免反爬虫机制,之后通过构造HTTP请求中的GET请求抓取整个页面信息,通过利用BeautifulSoups进行解析网页。在爬取网页的时候由于原始数据通过网络爬虫的形式抓取,恒容易造成信息失真的情况,同时也会有部分数据丢失或者是失帧数据对后期聚类分析产生影响。

(爬虫爬取过程)
在爬取过程中可能会遇到频繁快速的爬取网络资源通过会造成IP被封,通常我们可以通过设置IP代理池来解决此类情况。而在抓取的过程中可采用time.sleep(4)方法增加爬取时间减少被封的可能。
- 数据清洗
由于网络中爬取的数据为通过HTTP请求进行整个页面信息的获取,对于抓取到的数据还需要进行进一步的数据加工处理,从而得到需要的数据集合,对于Python语言自带了urlib.urllib2d等常用库,而urllib2包中更加提供了丰富的API,我们在抓取之间后使用beautifulsoap4更加可以使得网络解析更加清晰快速的提取文本。由于原始数据中可能含有特殊符号或者统计的单位,在清洗时我们需要去除其属性中的特殊符号,通过进一步的处理数据保证了数据格式的完整统一。从而形成CSV文件。
- 数据预处理
在对二手房进行分析的过程中还需要对所爬取的数据进行进一步的预处理,例如对于有些缺失的数据,要进行填充或者舍去,对于及个例的数据需要分析是否会对聚类产生较大的影响,数据分析时采用的为K-means算法,需要确定聚类个数k以及n个实例,因此为了是得到同一簇所组成真的类中实例间的相似度较高,如果会产生较大的影响,应该尽量避免其产生的影响。
针对出现的问题,所采取的措施为数据在预处理时,先将缺失的数据在读取的过程中进行舍去处理,避免造成程序的错误或者统计不准确,之后我们将预处理后的数据进行图形化界面显示,可进一步分析昆明相关的在售楼盘所集中的位置,同时可以对相关的楼盘类型进行相关的统计,通过利用散点图的显示楼盘所集中的价格区间,挑选其集中的区域进行聚类分析,避免由于个例数据对整个聚类分析造成影响。
四、数据分析
- 数据可视化
在进行聚类分析之前我们通过对数据进行可视化显示、既可方便对数据的分析,同时便于在采用聚类分析的时候造成及个别的数据对聚类的整个结果产生影响。
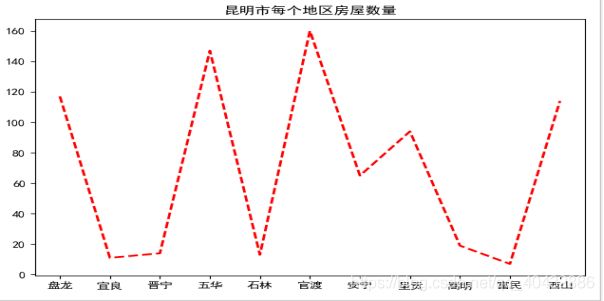
在数据可视化的过程中通过对CSV文件的读取,从而获取二手房的最高最低售价,以及最高最低售价所在处。在读取的过程中统计其类型,将其“商业类”、“低商”、“写字楼”总体归纳为商业类,从而得到房屋的主要类别为住宅、别墅、商业类共计3个类别。通过利用链表、数组等对整体的数据进行存储统计,最终调用Python中的matplotlib库对数据进行绘图显示。

(房屋类别统计)
通过折线图可看出各个区所售房屋数量的差异,其中官渡区呈现出峰值达到22%,其次为五华区达20%,西山区达16%,盘龙区达到14%。从整体上可看出各地区在售的房屋受到地区差异较大。
除了对各县区房屋统计外,从上图中可看出,基本住宅与商业类(店铺、底商、写字楼)所占比例基本接近于80%,可推测出,目前别墅购买者需求远远低于基本住宅于商业类的购房者。
(房屋单价散点图)
从上图中可看出更多的房屋聚集在7000-20000元之内,其中单价高于3万元基本为商业类,而对于更多的住宅基本都集中于2万元以内,而商业类的数量也呈现出出售较多的趋势。利用散点图排除其30000万元以上的个例,可有效增加聚类的准确率。
- k-means算法应用
- 聚类分析
- 聚类分析在生物学、电子商务等技术领域应用较多, 是数据挖掘和机器学习的重要内容之一, 它是一种无监督的机器学习方式。聚类分析是一种根据样本之间的距离或者说是相似性(亲疏性),把越相似、差异越小的样本聚成一类(簇),最后形成多个簇,使同一个簇内部的样本相似度高,不同簇之间差异性高。此次分析主要采用K-means方法进行分析。
以欧氏距离来衡量距离大小,作为聚类的目标函数:

k表示k个聚类中心, Ci表示第几个中心,dist表示欧几里得距离。我们在计算的过程中可以对第k个智星Ck进行求解,即对SSE进行求导,若另导数等于0,并求解Ck可得:
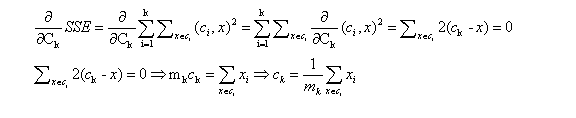
在实验中k-means的k决定了最终聚集的簇数目。k-means在作为常见的机器学习算法,基本过程为:首先任取k个样本点作为k个簇的初始中心,实验中设置center为初始中心,而对于对每一个样本点,通过计算它们与center中心的距离,把它归入距离最小的中心所在的簇中;等到所有的样本点归类完毕之后,重新计算k个簇的中心;重复以上过程直至样本点归入的簇不再变动。
- 聚类结果
在实验中通过设置聚类中心初始值为7000、10000、13000、16000,之后经过4次聚类中心的改变,最终达到聚类中心值为6399、10071、13527、17896。同时的到四种聚类房屋所占数量为112、156、190、153。

(聚类中心值变化情况)
在编码过程中通过设置center中心值为7000、10000、13000、16000,之后通过计算机聚类中心值,开始依次处理四类数据。最终绘制柱形图进行显示。

(聚类结果)

(聚类后、每个类型数量)
通过对聚类后的四个类别进行类型统计,其基本走势大致一样。武略在哪一个聚类中,都是别墅类占有率最少,基本住宅占有率最多,而商业类住房呈现趋势基本于总体一致。结合图中可看出更多的卖房者价格基本呈现在13000左右。在聚类一、二、四类基本住宅的数量基本是一样。

(聚类结果显示)
在聚类的最终结果显示别墅主要聚集在呈贡区、官渡区、安宁等地段,对于商业类主要出现在盘龙、五华、西山、呈贡、官渡、安宁、嵩明、晋宁等人流量比较聚集的地方,对于基本住宅则分布较为广泛。而总体上都呈现出地理位置不同房屋的价格相差较大的特点。(聚类结果显示)
- 结论
在本文中分析数据集主要属性有地区、房价、类型等相关的属性,共设置了4个聚簇,聚簇中心初始值分别设置为7000,10000,13000,16000。排除单价在2万每平米的数据,将其余所有的数据归在各簇中,最终在经过4次聚簇中心的改变后,最终中心值变化为6399、10071、13527、17896。其中以第三个为中心点的数量为最多达190,其次为聚簇二在156、聚簇三为153,聚簇1为最小值为112。而对于每一个聚簇中基本的住房都为最高比例的占有。而在四个聚簇中别墅数量都为最低。在聚簇一中数量分别为:82、7、23(依次对应:基本住宅、别墅、商业类,下文同)、第二类聚簇中数量分别为:78、8、70,聚簇三中为124、12、54,聚簇四中为76、14、63。
从整个数据中可以看出昆明地区房价基本集中在10000元左右。较少数量呈现在20000元以上。其商业类住房主要出现地区为盘龙、五华、西山、呈贡、官渡、安宁、嵩明、晋宁,
别墅主要分布地区有安宁、嵩明、西山、盘龙、官渡、呈贡,普通商品房分布最为广阔分别为呈贡、五华 、盘龙、官渡、西山、安宁、晋宁、宜良、富民、石林。而商品房受地区影响,价格变动的差异较大。在整体上昆明房价呈现正态分布。
从现有数据可以看出更多的房屋售价基本集中于1万左右。可估测昆明地区的房价的大致走势基本集中于1万元每平米,在分析的过程中,可得到的更多的购房者考虑更多的是周围的配套设施是否完善,而整体的售价中根据不同的地区呈现出的价值也不同。
- 小结
此次实验中采用K-means方法进行昆明二手房价的聚类分析,通过可视化界面的展示更加让显示更加直观、可读性更高。大部分数据均采用图标的形式呈现简洁明了,对于爬取的数据整体完善,数据的清洗过程做的很好,使得数据的格式风格进行了统一,同时对于数据集的预处理处理的较好。
在实验中采用先进行可视化分析,通过散点图的形式呈现,简洁直观的看到数据整体嗯得一个分布情况,通过排除大于20000的个例数据,从而加大了预测的准确度。同时采用折线图、柱状图的形式呈现出每个地区所售房屋的数量、以及各个分类的体现。之后进行聚类分析,将聚类过程通过可视化折线图进行展示做的完善。以及将聚类后数据在进行一个逐一的分类,使得数据分析更加有力度。
但是在这个实验中对数据结构的优化度不够高。更多的呈现出代码冗余,没有对代码的结构进行很好的优化。
- 心得体会
此次实验通过聚类分析昆明地区的二手房价,对爬虫以及k-means聚类分析有了一个整体的掌握,通过此次的实验对数据挖掘有了更加深刻认识,在实验中对数据的爬取、清洗、预处理、分析等过程虽然过程中遇到许多问题(eg:IP被封、反爬虫机制、数据格式处理等等问题)但最终完成整个实验,对爬虫与聚类分析算法进行了掌握,但是在程序的整体优化程度不够,在分析过程中,出现程序代码段冗余的情况,在程序的结构化编程方面还需要加强。
源码参见我上传的资源或者私聊我
昆明房价聚类分析(链家网爬虫+聚类分析房价)(k-means聚类分析)_聚类分析房价,kmeans聚类分析房价-机器学习文档类资源-CSDN下载
源码参见我上传的资源或者私聊我
昆明房价聚类分析(链家网爬虫+聚类分析房价)(k-means聚类分析)_聚类分析房价,kmeans聚类分析房价-机器学习文档类资源-CSDN下载
源码参见我上传的资源或者私聊我
昆明房价聚类分析(链家网爬虫+聚类分析房价)(k-means聚类分析)_聚类分析房价,kmeans聚类分析房价-机器学习文档类资源-CSDN下载