【学习笔记】《深入浅出Pandas》第17章:Pandas实战案例
文章目录
- 17.1 实战思想
-
- 17.1.1 链式方法
- 17.1.2 代码思路
- 17.1.3 分析方法
- 17.1.4 分析流程
- 17.1.5 分析工具
- 17.2 数据处理案例
-
- 17.2.1剧组表格道具:伪数据生成
- 17.2.2 当月最后一个星期三
- 17.2.3 同组数据转为同一行
- 17.2.4 相关性最强的两个变量
- 17.2.5 全表最大值的位置
- 17.2.6 编写年会抽奖程序
- 17.2.7 北京各区无新增新冠肺炎确诊病例天数
- 17.2.8 生成SQL
- 17.2.9 圣诞节的星期分布
- 17.2.10 试验三天中恰有两天下雨的概率
- 17.2.11 计算平均打卡上班时间
- 17.3 综合案例
-
- 17.3.1 中国经济发展分析
- 17.3.2 新冠肺炎疫情分析
- 17.3.3 利用爬虫获取房价
- 17.3.4 全国城市房价分析
- 17.3.5 客服对话文本分析
- 17.3.6 RFM用户分层
- 17.3.7 自动邮件报表
- 17.3.8 鸢尾花品种预测
17.1 实战思想
17.1.1 链式方法
在数据分析过程中,常常需要多次连续的操作才能完成一个基本的分析任务。
链式方法:链式调用。
案例:找出各团队中的第一位同学,然后从中筛选出平均分大于60分的同学,最终显示其所在团队和团队平均分。

(1)传统方法:
df = pd.read_excel('https://www.gairuo.com/file/data/dataset/team.xlsx')
df = df.groupby('team').first()
df['avg'] = df.mean(1) # 增加一列
df = df.reset_index().set_index('name')
df = df[df.avg > 60]
df = df.loc[:, ['team', 'avg']]
缺点:对数据的查询和修改是通过不断给原数据赋值完成的,这样会出现一个问题,在操作的时候数据变量df被不停修改和替换,如果操作出现失误,就需要重新读取原数据。
(2)链式方法:
(
pd.read_excel('https://www.gairuo.com/file/data/dataset/team.xlsx')
.groupby('team') # 按团队分组
.first() # 取各组第一个
.assign(avg= lambda x: x.mean(1)) # 增加平均分列avg
.reset_index() # 重置自然索引
.set_index('name') # 创建索引为name
.query('avg>60') # 筛选平均分大于60分的数据
.loc[:, ['team', 'avg']] # 只显示团队和平均分两列
)
链式方法的代码像接力一样,上一行将处理结果交给下一行代码处理。
在一般情况下,建议将数据读取和清洗放在方法链之外,对处理好的原始数据使用链式方法。
17.1.2 代码思路
- 明确需求
- 确定分析方案
- 代码设计(算法选择)
- 代码实施
- 得出结论
- 复盘迭代
实例:以下虚拟数据是一份两个年度同期的营收数据,有两个数据列,一个为日期,另一个对应日期的交易金额(GMV)。
date gmv
2020-11-05 68
2020-11-06 57
2020-11-07 65
2020-11-08 77
2020-11-09 88
2020-11-10 100
2019-11-06 65
2019-11-07 88
2019-11-08 34
2019-11-09 57
2019-11-10 44
1.业务需求:想知道2020年相对2019年同期的业务变化情况。
2.确定分析方案:将2020年和2019年同一天的GMV数据相减,得到同天GMV的差值,进而得到上涨还是下跌的结论。
3.代码设计:将date列中的月和日分组,分组后同一日有两个年度的两条数据,再对这两条数据求差值,得到结果。
通用方法:将需求用文字表达,一个逻辑一个节点,然后再对每个节点进行拆分并对应到代码上。
4.代码实施:
(1)用df.astype({‘date’: ‘datetime64[ns]’})完成时间类型转换,再用.dt时间选择器进行操作。接着,根据业务意义,也方便groupby操作,将date设置为索引。
(
df.astype({'date': 'datetime64[ns]'})
.set_index('date')
)

(2)按月、日进行分组。由于分组后产生一个分组对象无法看到数据内容,使用apply将gmv输出。
(
df.astype({'date': 'datetime64[ns]'})
.set_index('date')
.groupby([lambda x: x.month, lambda x: x.day])
.apply(lambda x : x.gmv)
)

(3)除了11月5日没有2019年数据外,其他日期都有两个年度对应的数据。利用diff对两个年度的数据求差值:
(
df.astype({'date': 'datetime64[ns]'})
.set_index('date')
.groupby([lambda x: x.month, lambda x: x.day])
.apply(lambda x : x.diff(-1))
)

(4)最后去除产生的2019年的缺失值,利用loc进行筛选:
(
df.groupby([lambda x: x.month, lambda x: x.day])
.apply(lambda x : x.diff(-1))
.loc[lambda x: x.index.year==2020]
)

5.得出结论:通过代码实施后的结果数据,按照确定数据分析方案时设定的指标和判定标准得出数据分析结论。
(
df.astype({'date': 'datetime64[ns]'})
.set_index('date')
.groupby([lambda x: x.month, lambda x: x.day])
.apply(lambda x : x.diff(-1))
.loc[lambda x: x.index.year==2020]
.plot()
)
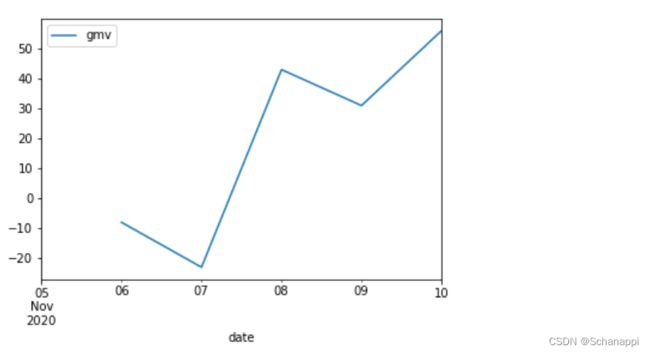
6.复盘迭代:完成数据分析项目后,需要复盘,查缺补漏,探索更加优秀的数据分析方案。
17.1.3 分析方法
1.描述统计:对总体中的所有数据内容进行统计性的描述。
2.相关分析:探索多组数据之间的关联关系。
3.对比分析
4.漏斗方法:如果数据产生在业务上有一定顺序,就适合漏洞方法。例如一个整体行为需要多个子行为按多条路径依次完成,或者其中部分路径依次完成,得出最终数据。在排查原因时,可以建立一个漏斗模型进行分析,看在哪个节点出现问题。
5.假设
6.机器学习:从无序的数据中提取出有用的信息,通过各种算法建立数据模型来探究原因和进行数据预测。
17.1.4 分析流程
17.1.5 分析工具
数据仓库的建设按照大数据分层理论逐层聚合,形成不同层级的数据库,每个库包含不同主题的数据表,这些数据表需要接入自动化数据分析平台,数据分析师会对这些库表利用SQL进行查询来获得数据集。
1.分层方法
操作数据层(ODS):这层原封不动地承接业务流转过来的原始数据,包括从业务库同步过来的业务数据,从外部采集的数据。当然,不会将业务库中的所有字段同步,会根据实际业务需求进行选择,还会对数据做脱敏处理。
数据明细层(DWD):这层解决数据质量问题,对ODS中不同的表进行加工清洗,建立一个稳定的业务最小粒度的明细数据。
数据服务层(DWS):对DWD层进行聚合,得到更多的同维度信息,大大减少了一个主题的数据量。
数据集市层(DM):本层面向应用,表和表之间不存在依赖,可进行最终的数据分析。
2.分析工具
SQL、HQL:必备,用于数据集的提取、简单分析。
Excel:必备,用于数据整理、分析。
Python或R:用于数据采集、清洗整理、分析、建模。
SPSS、Tableau、Power BI、Datahunter、Quick BI:数据处理、数据探索、数据可视化工具。
PPT、Keynote:数据展示、报告。
17.2 数据处理案例
17.2.1剧组表格道具:伪数据生成
实例:某剧组需要道具组产出一个假的数据表格。
思路:Pandas可以构造一个DataFrame,然后输出为Excel。
1.其中假数据的生成,使用faker第三方库。
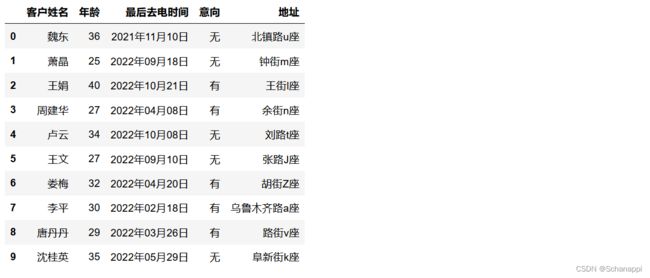
(1)pd.DataFrame在生成DataFrame的时候,可以通过字典的形式传入数据的功能,键为列名,值是一个序列,作为此列的值。
import faker
f = faker.Faker('zh-cn')
df = pd.DataFrame({
'客户姓名': [f.name() for i in range(10)],
'年龄': [f.random_int(25, 40) for i in range(10)],
'最后去电时间': [f.date_between(start_date='-1y', end_date='today')
.strftime('%Y年%m月%d日') for i in range(10)],
'意向': [f.random_element(('有', '无')) for i in range(10)],
'地址': [f.street_address() for i in range(10)]
})
(2)使用assign一列列添加:
(
pd.DataFrame()
.assign(客户姓名=[f.name() for i in range(10)])
.assign(年龄=[f.random_int(25, 40) for i in range(10)])
.assign(最后去电时间=[f.date_between(start_date='-1y', end_date='today')
.strftime('%Y年%m月%d日') for i in range(10)])
.assign(意向=[f.random_element(('有', '无')) for i in range(10)])
.assign(地址=[f.street_address() for i in range(10)])
)
2.导出Excel文件:
df.to_excel('客户资料表.xlsx', index=None)
可以查阅文档,faker库有很多用法。
关于python如何构造测试数据
17.2.2 当月最后一个星期三
实例:给出一个日期,得到这个日期所在月份的最后一个星期三。
思路:首先要用到时序相关操作,给出一个日期后需要得到这个月的所有日期,然后再得到每个日期是星期几,筛选出星期三的日期,找到最后一个即可。
1.先指定一个日期,然后使用时间的replace方法将日期定位到这个月的1日,方面后面使用时间偏移:
t = pd.Timestamp('2020-11-11')
t = t.replace(day=1)
# Timestamp('2020-11-01 00:00:00')
2.使用pd.date_range构造出这个月的所有日期,结束时间取这个月的月底:
index = pd.date_range(start=t,
end=(t + pd.offsets.MonthEnd())
)
 3.将所有日期作为索引,增加一个日期对应星期几的列,由于星期一对应0,为了方便识别,对星期加1,这样星期一就对应1:
3.将所有日期作为索引,增加一个日期对应星期几的列,由于星期一对应0,为了方便识别,对星期加1,这样星期一就对应1:
(
pd.DataFrame(index.weekday+1, index=index.date, columns=['weekday'])
.head(10)
)

4.筛选出星期为3的列,再取最后一个值:
(
pd.DataFrame(index.weekday+1, index=index.date, columns=['weekday'])
.query('weekday==3')
.tail(1)
.index[0]
)
# datetime.date(2020, 11, 25)
17.2.3 同组数据转为同一行
实例:将A、B两列组合进行分组,同组内的数据显示在同一行,有多少条数据就放多少列。
# 原数据
"""
A B C D
a b1 c 2001
a b1 c 2003
a b1 c 2005
a b2 c 2001
a b2 c 2002
a b2 c 2003
a b2 c 2004
"""
# 转换后
"""
A B C D
a b1 c 2001 2003 2005 None
b2 c 2001 2002 2003 2004
思路1:需求中的数据变化符合数据透视的规则。
df.pivot(index=['A', 'B', 'C'], columns='D', values='D')

思路2:数据透视基本实现了需求,不过还需要进一步处理。可以更换一下思路,先按[‘A’, ‘B’, ‘C’]进行groupby分组,再将分组后的数据用逗号隔开,再将逗号隔开的字符用.str.split()展示。
(
df.groupby(['A', 'B', 'C'])
.apply(lambda x: ','.join(x.D.astype(str)))
)

(
df.groupby(['A', 'B', 'C'])
.apply(lambda x: ','.join(x.D.astype(str)))
.str.split(',', expand=True)
)
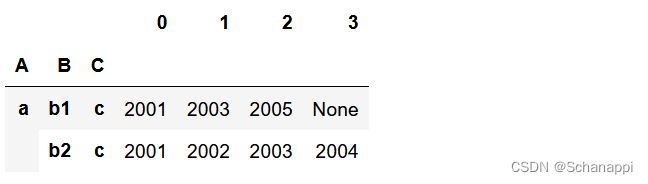
17.2.4 相关性最强的两个变量
实例:找出以下数据集中A、B、C三列中相关性最强的两列。
df = pd.DataFrame({
'A': [1, 2, 4, 5, 6],
'B': [2, 4, 6, 9, 10],
'C': [2, 1, 7, 2, 1]
})

1.使用df.corr() 可以得到这三列的相关性矩阵。相关性系数从-1到1表示相关程度。
df.corr()

2.从左上到右下对角线上的值全为1,这些值是列和自己的相关性,需要先去掉,然后找到去掉这些值后,相关性系数最大的两列。利用stack() 堆叠数据,转为一列,行和列上的轴标签形成两层索引,然后对值从大到小排序:
(
df.corr()
.stack() # 堆叠,转为一列
.sort_values(ascending=False) # 排序,最大值在前
.loc[lambda x:x<1] # 去掉值为1的数据
)

3.现在发现最大值为0.987069,它的标签是B和A,需求是知道标签而不是最大值是多少,因此可以用idxmax(),得到最大值的索引:
(
df.corr()
.stack() # 堆叠,转为一列
.sort_values(ascending=False) # 排序,最大值在前
.loc[lambda x:x<1] # 去掉值为1的数据
.idxmax()
)
# ('B', 'A')
17.2.5 全表最大值的位置
实例:找到DataFrame中最大值的标签
df = pd.DataFrame({
'A': [1, 2, 4, 5, -6],
'B': [2, -1, 8, 2, 1],
'C': [2, -1, 8, 2, 1]
},
index=['x', 'y', 'z', 'h', 'i']
)

1.找到DataFrame中的最大值:
df.max().max() # 得到全局最大值
# 8
2.查出最大值,返回的DataFrame中非最大值的值都显示为NaN:
df[df==df.max().max()]

3.删除全为空的行和列:
(
df[df==df.max().max()]
.dropna(how='all') # 删除全为空的行
.dropna(how='all', axis=1) # 删除全为空的列
)

4.发现有两个最大值,在同一行的两列中,最后用axes得到轴信息:
(
df[df==df.max().max()]
.dropna(how='all') # 删除全为空的行
.dropna(how='all', axis=1) # 删除全为空的列
.axes
)
# [Index(['z'], dtype='object'), Index(['B', 'C'], dtype='object')]
17.2.6 编写年会抽奖程序
实例:某公司年会设置有抽奖环节,奖品设有三个等级:一等奖一名,二等奖两名,三等奖三名。要求一个人只能中一次奖。
1.构造50个员工的名单:
# 构造数据
f = faker.Faker('zh-cn')
df = pd.DataFrame([f.name() for i in range(50)], columns=['name'])
# 增加一列用于存储结果
df['等级']= ''

2.抽奖,筛选器filter每次用sample匹配出得奖的人,这些得奖的人从无等级的人中产生,接着用loc查出这些人,将等级写入,最后再用loc将本次抽奖结果筛选出来:
# 配置信息,第一位为抽奖人数,第二位为奖项等级
win_info = (3, '三等奖')
# 创建一个筛选器变量
filter = df.index.isin(df.sample(win_info[0]).index) & ~(df.等级.isnull())
# 执行抽奖,将等级写入
df.loc[filter, '等级'] = win_info[1]
# 显示本次抽奖结果
df.loc[df.等级==win_info[1]]
3.经过几次抽奖,显示得奖结果:
df[~(df.等级=='')].groupby(['等级', 'name']).max()

17.2.7 北京各区无新增新冠肺炎确诊病例天数
实例:2020年新冠肺炎期间,“北京发布”微信公众号每天会发布北京市上一日疫情数据,其中会介绍全市16区无报告病例天数情况。
原始数据:
df = pd.DataFrame({
'地区': ['顺义区', '平谷区', '昌平区', '大兴区',
'密云区', '石景山区', '海淀区', '东城区',
'门头沟区', '房山区', '延庆区', '怀柔区',
'朝阳区', '西城区', '通州区', '丰台区'],
'最后一例确诊日期': ['2020-02-08', np.nan, '2020-08-06', '2020-06-30',
'2020-02-11', '2020-06-14', '2020-06-25',
'2020-06-16', '2020-06-15', '2020-06-15',
'2020-01-23', '2020-02-06', '2020-06-21',
'2020-06-22', '2020-06-20', '2020-07-05']
})

增加一列统计天数,先将确诊日期转换为时间类型,进行缺失值处理,接着与当天时间相减计算出天数:
(
df.replace('Nan', pd.NaT) # 将缺失值转为空时间
# 将确诊日期转为时间格式
.assign(最后一例确诊日期=lambda x: x['最后一例确诊日期'].astype('datetime64[ns]'))
# 增加无报告病例天数列,当日与确诊日期相减
.assign(无报告病例天数=lambda x: pd.Timestamp('2020-11-16') - x['最后一例确诊日期'])
# 计算出天数
.assign(无报告病例天数=lambda x: x['无报告病例天数'].dt.days)
# 排序,空值在前,重排索引
.sort_values('无报告病例天数', ascending=False, na_position='first')
)
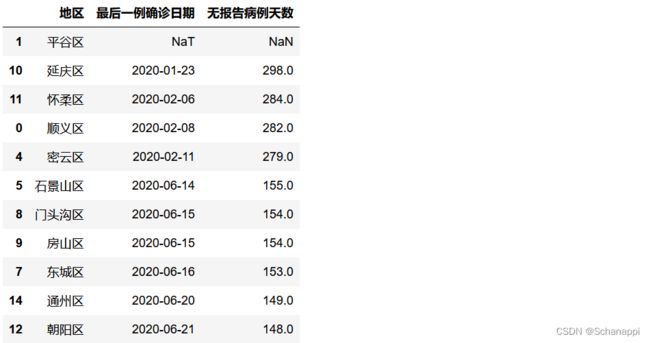
17.2.8 生成SQL
实例:现有以下2020年节假日的数据,需要将其插入数据库的holiday表里,holiday除了以下散三列,还有一个年份字段year。

1.数据:
df = pd.DataFrame({
'节日': ['元旦', '除夕', '清明节', '劳动节', '端午节', '国庆节'],
'开始日期': ['2020-01-01', '2020-01-24', '2020-04-04', '2020-05-01', '2020-06-25', '2020-10-01'],
'结束日期': ['2020-01-01', '2020-01-24', '2020-04-04', '2020-05-01', '2020-06-25', '2020-10-01']
})
2.对DataFrame进行迭代,生成insert SQL语句:
sql = ''
for i, r in df.iterrows():
r_sql = f"INSERT INTO 'holiday' ('holiday', 'year', 'start_date', 'end_date') VALUES ('{r['节日']}', '{r['结束日期'][:4]}', '{r['开始日期'][:4]}')"
sql = sql + r_sql + '\n'

17.2.9 圣诞节的星期分布
实例:想知道圣诞节在星期几多一些。
思路:抽样近100年的圣诞节进行分析。
- 用pd.date_range生成100年日期数据;
- 筛选出12月25日的所有日期;
- 将日期转换为所在星期几的数字;
- 统计数字重复值的数量;
- 绘图观察并得出结论。
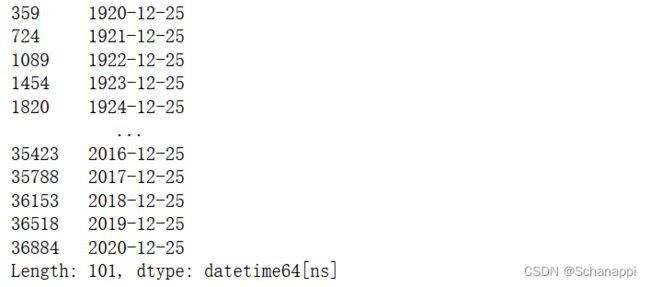
1.找到所有的圣诞节日期:
# 近100年的圣诞节日期
(
# 生成100年时间序列
pd.Series(pd.date_range('1920', '2021'))
# 筛选12月25日的所有日期
.loc[lambda s: (s.dt.month==12) & (s.dt.day==25)]
)
 2.计算出圣诞节分别为星期一 ~ 星期日的天数:
2.计算出圣诞节分别为星期一 ~ 星期日的天数:
# 圣诞节在各日的数量
(
# 生成100年时间序列
pd.Series(pd.date_range('1920', '2021'))
# 筛选12月25日的所有日期
.loc[lambda s: (s.dt.month==12) & (s.dt.day==25)]
.dt.weekday # 转为星期数
.add(1) # 由于0代表周一,对序列加一,符合日常认知
.value_counts() # 重复值计数
)

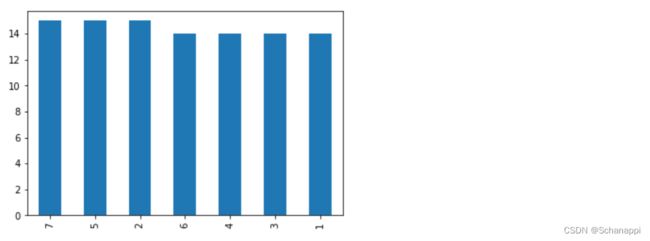
3.绘制柱形图:
# 圣诞节在各日的数量
(
# 生成100年时间序列
pd.Series(pd.date_range('1920', '2021'))
# 筛选12月25日的所有日期
.loc[lambda s: (s.dt.month==12) & (s.dt.day==25)]
.dt.weekday # 转为星期数
.add(1) # 由于0代表周一,对序列加一,符合日常认知
.value_counts() # 重复值计数
.plot
.bar() # 绘制柱形图
)
17.2.10 试验三天中恰有两天下雨的概率
实例:天气预报说,在今后的三天中,每一天下雨的概率均为40%,请问这三天中恰有两天下雨的概率。
思路:可以用代码随机生成0~9之间的整数随机数,用1 ~ 4代表下雨,5 ~ 9代表不下雨。由于以三天为一组,所以每次生成一个三位的数字串。
用Numpy生成随机值(控制在三位数字),由于百位以内不够三位,用zfill在前面补0,实现了一次生成三天的情况。然后计算这些数字字符中1 ~ 4 (下雨)的数量,筛选值为2(两天下雨)的数据,最后与总数据量(天数)相比得到结果。
rng = np.random.default_rng() # 定义随机对象
days = 100000 # 随机天数
arr = rng.integers(0, 1000, days) # 生成随机数字
(
pd.DataFrame()
.assign(x=arr) # 将随机数字增加到列
.astype(str)
.assign(x = lambda d: d.x.str.zfill(3)) # 不足3位数字的前面补0
.assign(a = lambda d: d.x.str.count(r'1|2|3|4')) # 统计数字串中1~4的个数
.query('a==2') # 筛选出两天下雨的数据
)

# 两天下雨的天数除以总天数
len(_) / days # 下划线表示取上文最后的值
# 0.28512
17.2.11 计算平均打卡上班时间
实例:某员工一段时间打卡的时间记录如下,需要计算他在这期间内的平均打卡时间。
# 一周打卡时间记录
ts = '''
2020-10-28 09:55:44
2020-10-29 10:01:32
2020-10-30 10:04:27
2020-11-02 09:55:43
2020-11-03 10:05:03
2020-11-04 09:44:34
2020-11-05 10:10:32
2020-11-06 10:02:37
'''
1.读取数据,并将数据类型转为时间类型,然后计算时间序列的平均值。StringIO将字符串读入内存的缓冲区,read_csv的parse_dates参数传入需要转换时间类型的列名:
from io import StringIO
df = pd.read_csv(StringIO(ts), names=['time'], parse_dates=['time'])

2.将日期归到同一天,再求平均时间。时间的replace方法可以实现这个功能,结合函数的调用方法,有以下三种办法可以实现同样的效果:
df.time.apply(lambda s: s.replace(year=2020, month=1, day=1)).mean()
df.time.apply(pd.Timestamp.replace, year=2020, month=1, day=1).mean()
df.time.agg(pd.Timestamp.replace, year=2020, month=1, day=1).mean()
# Timestamp('2020-01-01 10:00:01.500000')
17.3 综合案例
本节将介绍Pandas在数据分析中的综合应用,并分享一些数据采集爬虫的操作技巧。
数据集:gairuo.com/p/pandas
17.3.1 中国经济发展分析
实例:对中国GDP的相关数据做分析,看看中国GDP的发展变化情况及各个产业的占比变化。
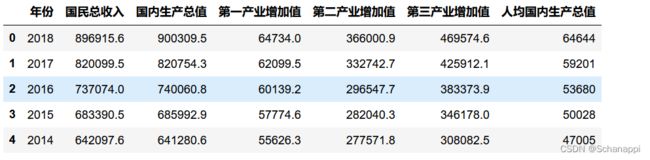
1.导入数据集:
import matplotlib.pyplot as plt
plt.rcParams['figure.figsize'] = (7.0, 5.0) # 固定显示大小
plt.rcParams['font.family'] = ['sans-serif'] # 设置中文字体
plt.rcParams['font.sans-serif'] = ['SimHei'] # 设置中文字体
df = pd.read_csv('https://www.gairuo.com/file/data/dataset/GDP-China.csv')
df.head()
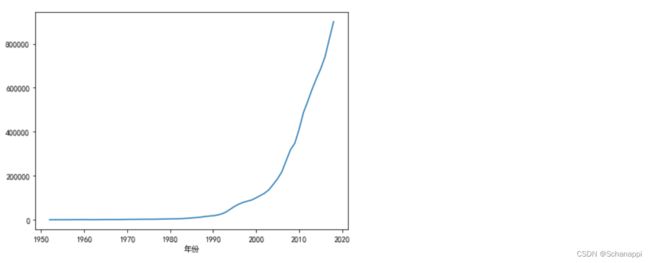
2.查看中国GDP发展趋势:
(
df.set_index('年份')
.国内生产总值
.plot()
)
3.查看第一产业占比趋势,持续走低:
(
df.assign(rate=df.第一产业增加值/df.国内生产总值)
.set_index('年份')
.rate
.plot()
)

4.查看2000年前后新增GDP总量方面,可以发现绝大部分GDP是在2000年以后产生的:
(
df.groupby(df.年份>=2000)
.sum()
.rename(index={True: "2000年以后", False: "2000年以前",})
.国内生产总值
.plot
.pie()
)

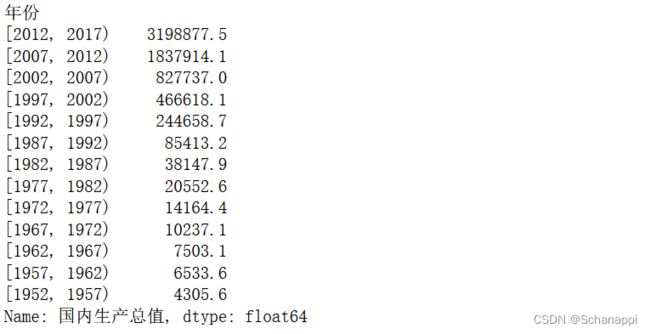
5.计算每五年的GDP之和:
(
df.groupby(pd.cut(df.年份,
bins=[i for i in range(1952, 2018, 5)],
right=False))
.sum()
.国内生产总值
.sort_values(ascending=False)
)
17.3.2 新冠肺炎疫情分析
实例:对2020年新冠肺炎疫情快速发展期进行分析,了解发展变化情况。
1.数据集:
import matplotlib.pyplot as plt
plt.rcParams['figure.figsize'] = (10.0, 6.0) # 固定显示大小
plt.rcParams['font.family'] = ['sans-serif'] # 设置中文字体
plt.rcParams['font.sans-serif'] = ['SimHei'] # 设置中文字体
df = pd.read_csv('https://www.gairuo.com/file/data/dataset/countries-aggregated.csv')
df.tail(5)

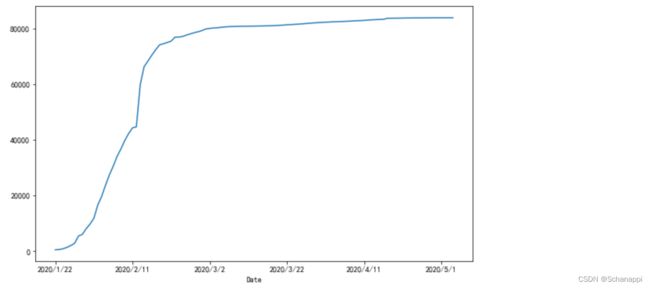
1.查看中国累计确诊人数趋势,爆发之初快速上升:
(
df.loc[df.Country == 'China']
.set_index('Date') # 日期为索引
.Confirmed # 确诊
.plot()
)
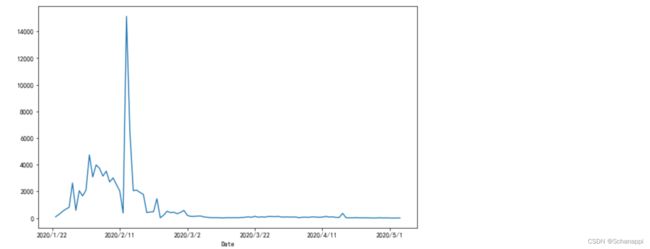
2.查看中国新增确诊趋势,在2020年2月初有一个确诊高峰:
(
df.loc[df.Country == 'China']
.set_index('Date') # 日期为索引
.assign(new=lambda x: x.Confirmed.diff()) # 增加每日新增数量列
.new
.plot()
)
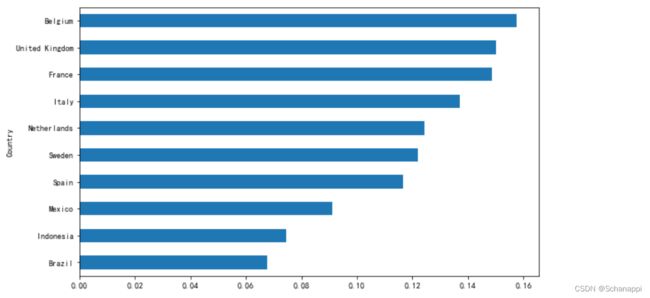
3.找出确诊病例在1万以上的国家中死亡率排名前十的国家:
(
df.loc[df.Date == df.Date.max()] # 由于是确诊病例,需要看最新的
.loc[df.Confirmed > 10000]
.assign(rate=lambda x: x.Deaths/x.Confirmed) # 增加死亡率列
.sort_values('rate', ascending=False) # 按死亡率最高排序
.set_index('Country') # 国家为索引
.head(10)
.rate # 选取死亡率
.sort_values(ascending=True) # 降序排序
.plot
.barh()
)
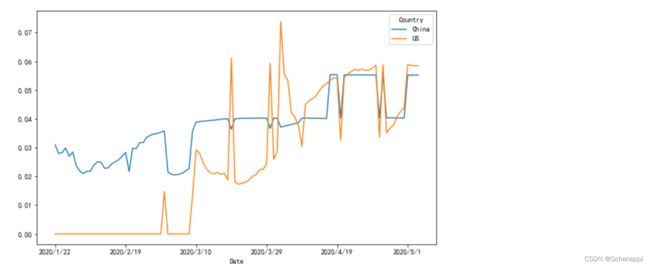
4.中美两国新冠肺炎确诊病例数量趋势:
(
df.loc[df.Country.isin(['China', 'US']), ['Country', 'Date', 'Confirmed']]
.groupby(['Country', 'Date'])
.max() # 聚合
.unstack()
.T
.droplevel(0) # 删除一级索引(Confirmed)
.plot()
)

5.对比中美两国新冠肺炎病例的死亡率:
(
df.loc[(df.Country.isin(['China', 'US'])) & (df.Date == df.Date.max())]
.assign(rate=df.Deaths/df.Confirmed) # 增加死亡率
.set_index('Country')
.rate
.plot
.bar()
)
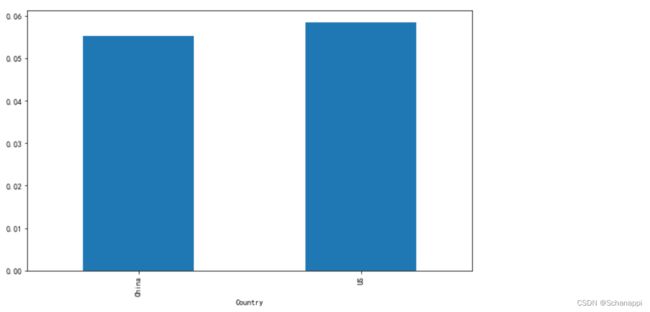
6.对比中美两国新冠肺炎病例每日死亡率变化:
(
df.loc[(df.Country.isin(['China', 'US']))]
.assign(rate=df.Deaths/df.Confirmed)
.groupby(['Country', 'Date'])
.max()
.rate
.unstack()
.T
.plot()
)
17.3.3 利用爬虫获取房价
1.利用requests库获取单个小区的平均价格,这里使用了将目标信息两边的信息进行切片、形成列表再读取的方法。
import requests
# 创建一个Session
s = requests.Session()
# 访问小区页面
xq = s.get('https://bj.lianjia.com/xiaoqu/1111027382589/')
# 查看页面源码
xq.text
# 找到价格位置附近的源码
# <span class="xiaoquUnitPrice">111823</span>
# 切分与解析
xq.text.split('xiaoquUnitPrice">')[1].split('')[0] # 1、0代表切片选择
# '111823'
2.构建获取小区名称和平均房价的函数:
# 获取小区名称的函数
def pa_name(x):
xq = s.get(f'https://bj.lianjia.com/xiaoqu/{x}/')
name = xq.text.split('detailTitle">')[1].split('')[0]
return name
# 获取平均房价的函数
def pa_price(x):
xq = s.get(f'https://bj.lianjia.com/xiaoqu/{x}/')
price = xq.text.split('xiaoquUnitPrice">')[1].split('')[0]
return price
3.执行爬虫获取信息:
# 小区列表
xqs = [1111027377595, 1111027382589,
1111027378611, 1111027374569,
1111027378069, 1111027374228,
116964627385853]
# 构造数据
df = pd.DataFrame(xqs, columns=['小区'])
# 爬取小区名
df['小区名'] = df.小区.apply(lambda x: pa_name(x))
# 爬取房价
df['房价'] = df.小区.apply(lambda x: pa_price(x))

4.可以先用Python的类改造函数,再用链式方法调用。
# 爬虫类
class PaChong(object):
def __init__(self, x):
self.s = requests.session()
self.xq = self.s.get(f'https://bj.lianjia.com/xiaoqu/{x}/')
self.name = self.xq.text.split('detailTitle">')[1].split('')[0]
self.price = self.xq.text.split('xiaoquUnitPrice">')[1].split('')[0]
# 爬取数据
(
df
.assign(小区名 = df.小区.apply(lambda x: pa_name(x)))
.assign(房价 = df.小区.apply(lambda x: pa_price(x)))
)
17.3.4 全国城市房价分析
中国主要城市的房价可以从https://www.creprice.cn/rank/index.html获取。该网页会显示上一个月的房价排行情况。
1.先复制前10个城市的数据,然后通过pd.read_clipboard() 获取。
import matplotlib.pyplot as plt
plt.rcParams['figure.figsize'] = (10.0, 6.0) # 固定显示大小
plt.rcParams['font.family'] = ['sans-serif'] # 设置中文字体
plt.rcParams['font.sans-serif'] = ['SimHei'] # 设置中文字体
plt.rcParams['axes.unicode_minus'] = False # 显示负号
dfr = pd.read_clipboard()

2.查看数据类型:
dfr.dtypes

3.数据都是object类型,需要对数据进行提取和类型转换:
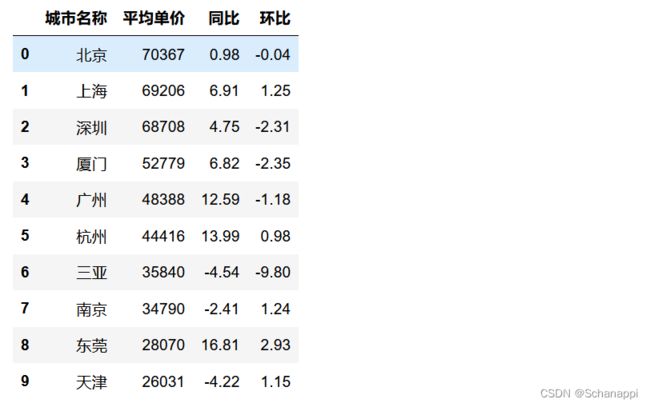
由于直接在网页中复制粘贴,导致多了许多莫名的空格,因为有些处理与原文不太一致(比如环比和城市名称后面都带了空格)。
df = (
# 去掉千分位符并转为整型
dfr.assign(平均单价=dfr['平均单价(元/㎡) '].str.replace(',', '').astype(int))
.assign(同比=dfr.同比.str[:-1].astype(float)) # 去掉百分号并转为浮点数
.assign(环比=dfr['环比 '].str[:-2].astype(float)) # 去掉百分号并转为浮点数
.assign(城市名称=dfr['城市名称 '])
.loc[:, ['城市名称', '平均单价', '同比', '环比']] # 重命名列
)
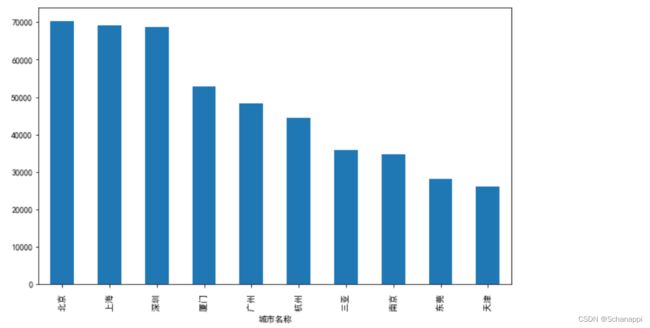
4.分析整理好的数据。查看各城市的均价差异:
(
df.set_index('城市名称')
.平均单价
.plot
.bar()
)
5.查看各城市平均房价同比与环比情况:
(
df.set_index('城市名称')
.loc[:, '同比':'环比']
.plot
.bar()
)
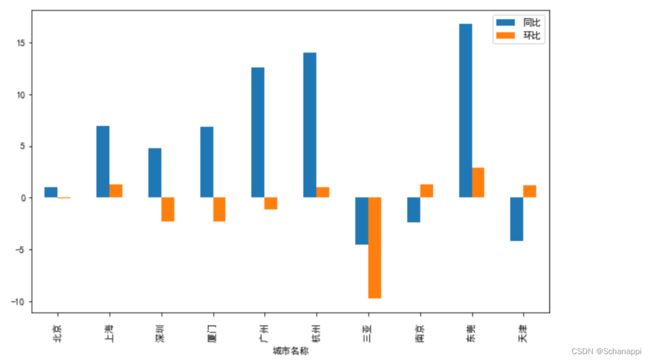
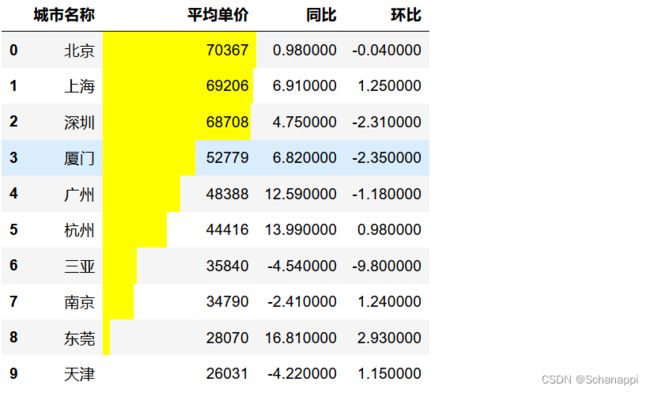
6.将同比与环比的极值用样式标注,可见东莞异常突出,房价同比、环比大幅度上升。
(
df.style
.highlight_max(color='red', subset=['同比', '环比'])
.highlight_min(subset=['同比', '环比'])
.format({'平均单价':"{:,.0f}"})
.format({'同比':"{:.2f}%", '环比':"{:.2f}%"})
)

7.绘制各城市平均单价条形图:
(
df.style
.bar(subset=['平均单价'], color='yellow')
)
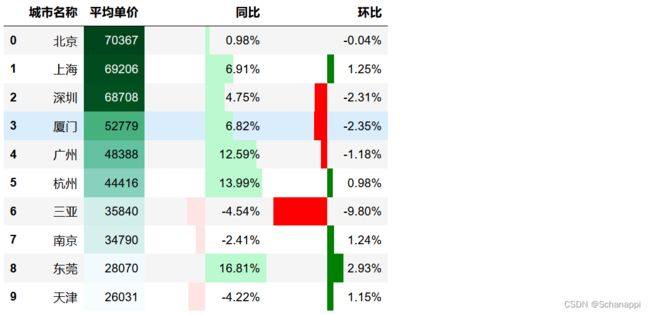
8.将数据样式进行综合可视化:将平均单价背景设为渐变,并指定色系BuGn;同比、环比条形图使用不同色系,且以0为中点,体现正负;为比值加百分号:
(
df.style
.background_gradient(subset=['平均单价'], cmap='BuGn')
.format({'同比':"{:.2f}%", '环比':"{:.2f}%"})
.bar(subset=['同比'],
color=['#ffe4e4', '#bbf9ce'], # 上涨、下降的颜色
vmin=0, vmax=15, # 范围定为以0为基准的上下15
align='zero'
)
.bar(subset=['环比'],
color=['red', 'green'],
vmin=0, vmax=11,
align='zero'
)
)
17.3.5 客服对话文本分析
实例:以下是客服999与用户李庆辉的对话记录:
其中,聊天内容前有一个tab符,首尾两句是系统自动提示,用“>>”标识,客服名称开头有“客服”字样,现在需要知道首次响应时长和平均时长。
data = '''
对话开始 >>
李庆辉 2020-05-15 12:33:50
你好,可以退货吗
客服999 2020-05-15 12:33:55 >>
工号999很高兴为您服务~。
客服999 2020-05-15 12:33:53
您好
客服999 2020-05-15 12:34:04
您可以自己操作申请取消订单的。
李庆辉 2020-05-15 12:34:04
退款多久到账呢?
客服999 2020-05-15 12:34:28
一般1-7个工作日
李庆辉 2020-05-15 12:35:01
OMG! 好久呢
李庆辉 2020-05-15 12:40:55
能不能快点
客服999 2020-05-15 12:42:23
一般情况下很快就会到账的。
李庆辉 2020-05-15 12:43:04
OMG! 好久呢
客服999 2020-05-15 12:44:01
一般情况下很快就会到账的。
对话结束 >>
长时间未回复,对话结束
'''
1.计算首次响应时长,指的是用户发出第一句到人工客服回复第一句的时间长度。首先将数据载入DataFrame,用StringIO将字符读入内存的缓冲区,以便Pandas读取:
df = pd.read_csv(StringIO(data), names=['chats'], dtype='string')

2.处理数据,剔除系统自动提示内容,提取双方昵称、是否客服、发送时间等字段,方便计算:
(
# 排除系统自动提示内容,并提取包含时间字段
df.loc[~(df.chats.str.endswith('>>')) & (df.chats.str.contains('2020'))]
.assign(name=lambda x: x.chats.str.split().str[0])
# 判断是否客服
.assign(staff=lambda x: x.name.str.contains('客服'))
.assign(time=lambda x: pd.to_datetime(x.chats.str[-20:]))
.sort_values('time') # 按时间先后排期
)
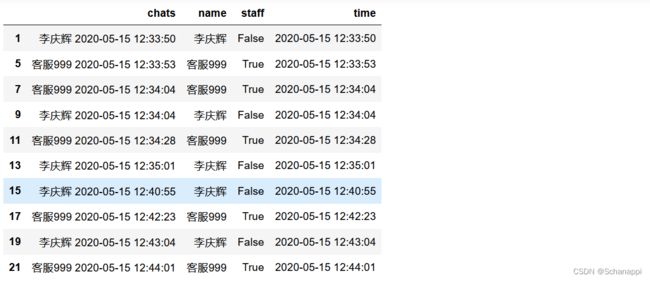
3.获取人工客服回复第一句的时间和用户发出第一句的时间并相减,得到首次响应时长:
(
df.loc[~(df.chats.str.endswith('>>')) & (df.chats.str.contains('2020'))]
# 排除系统自动提示内容
.assign(name=lambda x: x.chats.str.split().str[0])
# 判断是否客服
.assign(staff=lambda x: x.name.str.contains('客服'))
.assign(time=lambda x: pd.to_datetime(x.chats.str[-20:]))
.sort_values('time') # 按时间先后排期
.assign(first=lambda x: x[x.staff==True].time.min() - x[x.staff==False].time.min()) # 首次响应时长
)
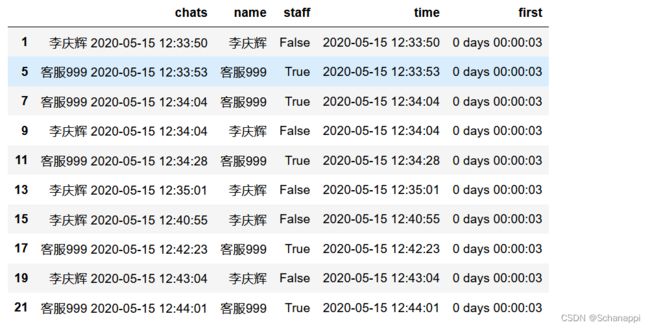
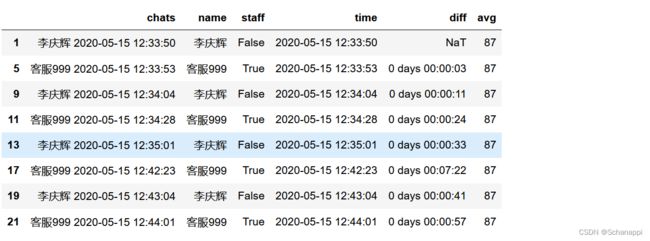
4.计算平均响应时长,平均响应时长的算法指的是用户发出信息后(不管接连发了几条),客户回应时间的间隔(不管接连回了几条)的间隔,总是一方一个时间,对这些间隔求平均。
思路是,将用户名下移后再判断是否还是原用户名,如果是则剔除,然后再对上下条消息的发出时间求差值,最后再算平均值,单位取秒。
(
df.loc[~(df.chats.str.endswith('>>')) & (df.chats.str.contains('2020'))]
# 排除系统自动提示内容
.assign(name=lambda x: x.chats.str.split().str[0])
# 判断是否客服
.assign(staff=lambda x: x.name.str.contains('客服'))
.assign(time=lambda x: pd.to_datetime(x.chats.str[-20:]))
.sort_values('time') # 按时间先后排期
# 求平均时长,保留一方连续发言情况中的第一条
.loc[lambda x: (x[['name']].shift() != x[['name']]).any(axis=1)]
.assign(diff=lambda x: x.time.diff()) # 求前后对话的时间差
.assign(avg=lambda x: x['diff'].mean().seconds) # 对所有时间差求平均
)
17.3.6 RFM用户分层
RFM是典型的用户分层方法,是评估用户消费能力、衡量用户贡献价值的重要工具。RFM代表的是最近一次消费时间间隔(Recency)、消费频率(Frequency)、消费金额(Monetary)。
1.构造数据集:
import faker
f = faker.Faker('zh-cn')
df = pd.DataFrame({
'用户': [f.name() for i in range(20000)],
'购买日期': [f.date_between(start_date='-1y',
end_date='today') for i in range(20000)],
'金额': [f.random_int(10, 100) for i in range(20000)]
})

2.查看数据类型:
# 数据类型转换
df = df.astype({'购买日期': 'datetime64[ns]'})
# 数据类型
df.dtypes

3.计算R值,R为最后一次购买时间距今的天数,R值越大代表用户越有可能处于沉睡状态,流失风险越大:
# r为购买间隔天数
r = (
df.groupby('用户')
.apply(lambda x: (pd.Timestamp('today') - x['购买日期'].max()))
.dt
.days
)
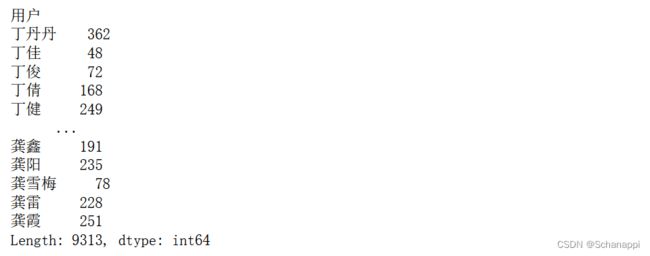
4.计算F值,F值是消费频率,消费频次越高代表用户粘性越强。我们将同一天购买多次的情况算作一次:
f = (
df.groupby(['用户'])
.apply(lambda x: x['购买日期'].nunique())
)
f.sort_values()

5.计算M值,M值代表金额,这里计算用户每次购买的平均金额,即用户总金额/用户购买次数。由于前面已经算出购买次数,因此在合并数据时再计算M值。
①首先计算每个用户的总金额:
df.groupby(['用户']).sum()['金额']

②将RFM数据合并,由于我们之前在计算R值和F值后都是以用户名称为索引的,因此直接用两个Series构造DataFrame,同时算出M值:
(
pd.DataFrame({'r': r, 'f': f})
.assign(m=lambda x: df.groupby(['用户']).sum()['金额']/x.f)
)
c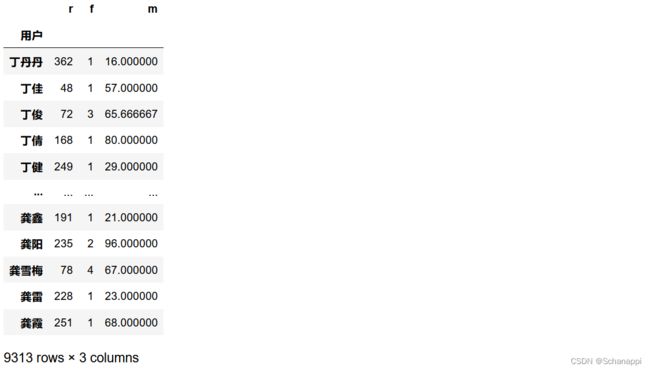
③给RFM打分,将RFM分为三个等级。R值使用pd.qcut()平均分为三段,R越大代表间隔时间越长,对间隔近的打一分,次之打两分,最远的打一分。F值和M值越大越好。
(
pd.DataFrame({'r': r, 'f': f})
.assign(m=lambda x: df.groupby(['用户']).sum()['金额']/x.f)
.assign(r_s=lambda x: pd.qcut(x.r, q=3, labels=[3, 2, 1]))
.assign(f_s=lambda x: pd.cut(x.f, bins=[0, 2, 5, float('inf')], right=False))
.assign(m_s=lambda x: pd.cut(x.m, bins=[0, 30, 60, float('inf')], right=False))
)

④进行分值归一化,把高于平均水平的归为1,低于平均水平的归为0:
(
pd.DataFrame({'r': r, 'f': f})
.assign(m=lambda x: df.groupby(['用户']).sum()['金额']/x.f)
.assign(r_s=lambda x: pd.qcut(x.r, q=3, labels=[3, 2, 1]))
.assign(f_s=lambda x: pd.cut(x.f, bins=[0, 2, 5, float('inf')], labels=[1, 2, 3], right=False))
.assign(m_s=lambda x: pd.cut(x.m, bins=[0, 30, 60, float('inf')], labels=[1, 2, 3], right=False))
.assign(r_e=lambda x: (x.r > x.r.mean())*1)
.assign(f_e=lambda x: (x.f > x.f.mean())*1)
.assign(m_e=lambda x: (x.m > x.m.mean())*1)
)
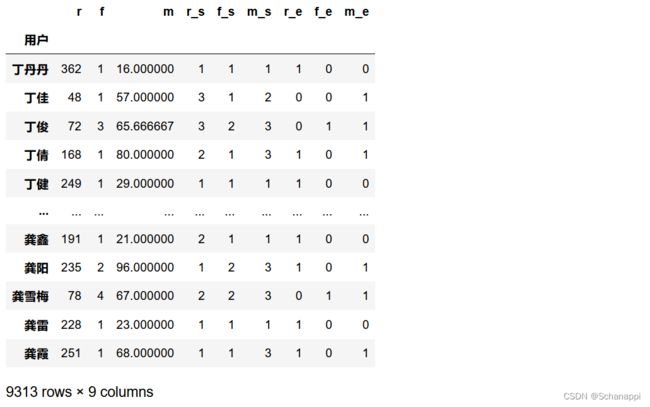
⑤最后将这些打分形成一个统一的标签,在打分设计时我们给正向的方面打了高分,再将分值的重要度R、F、M分别转化为数字,放在百位、十位和个位:
(
pd.DataFrame({'r': r, 'f': f})
.assign(m=lambda x: df.groupby(['用户']).sum()['金额']/x.f)
.assign(r_s=lambda x: pd.qcut(x.r, q=3, labels=[3, 2, 1]))
.assign(f_s=lambda x: pd.cut(x.f, bins=[0, 2, 5, float('inf')], labels=[1, 2, 3], right=False))
.assign(m_s=lambda x: pd.cut(x.m, bins=[0, 30, 60, float('inf')], labels=[1, 2, 3], right=False))
.assign(r_e=lambda x: (x.r > x.r.mean())*1)
.assign(f_e=lambda x: (x.f > x.f.mean())*1)
.assign(m_e=lambda x: (x.m > x.m.mean())*1)
.assign(label=lambda x: x.r_e*100+x.f_e*10+x.m_e*1)
)

⑥最后用map方法给数据打上中文标签:
label_names = {111: '重要价值客户',
110: '一般价值客户',
101: '重要发展客户',
100: '一般发展客户',
11: '重要保持客户',
10: '一般保持客户',
1: '重要挽留客户',
0: '一般挽留客户'
}
(
pd.DataFrame({'r': r, 'f': f})
.assign(m=lambda x: df.groupby(['用户']).sum()['金额']/x.f)
.assign(r_s=lambda x: pd.qcut(x.r, q=3, labels=[3, 2, 1]))
.assign(f_s=lambda x: pd.cut(x.f, bins=[0, 2, 5, float('inf')], labels=[1, 2, 3], right=False))
.assign(m_s=lambda x: pd.cut(x.m, bins=[0, 30, 60, float('inf')], labels=[1, 2, 3], right=False))
.assign(r_e=lambda x: (x.r > x.r.mean())*1)
.assign(f_e=lambda x: (x.f > x.f.mean())*1)
.assign(m_e=lambda x: (x.m > x.m.mean())*1)
.assign(label=lambda x: x.r_e*100+x.f_e*10+x.m_e*1)
.assign(label_names=lambda x: x.label.map(label_names))
.groupby('label').count().r.plot.bar()
)

17.3.7 自动邮件报表
实例:本案例将介绍如何搭建自动数据邮件系统,分为三个部分:发送邮件,使用Pandas构造邮件内容、以及实现自动化。
1.发送邮件
Python自带smtplib和email两个模块,smtplib模块主要负责发送邮件,email模块主要负责构造邮件。这里推荐一个第三方库drymail, 它将发送邮件功能进行了封装,使用起来更方便。
在发送邮件之前需要先用使用的邮箱等信息配置发件服务SMTPMailer。再用Message对象构造邮件内容,用Message.attach构造附件,最后用SMTPMailer.send将邮件内容发出。
2.构造邮件内容
一般发送的都是富文本形式的正文,将构造的正文内容传到Message对象的html参数中。
接下来,构造邮件正文,完成数据的处理后使用style完成样式的展示。由于HTML和CSS是独立的,会导致有些收件客户端因不兼容而丢失样式,可以使用Premailer库将其转换为内联样式。在邮件中不能直接引用图片,可以使用图片的base64编码。
3.实现自动化
将以上操作编写为Python脚本文件,在Windows系统中,可以鼠标右击“我的电脑”并选择“管理”选项,在弹出窗口中的“任务计划程序”设置中配置自动任务。
17.3.8 鸢尾花品种预测
实例:介绍Pandas配合sklearn使用经典的鸢尾花研究数据来做品种预测。
sklearn集成了iris数据集,共有4个属性列和一个种类列。4个属性是sepal length(萼片长度)、sepal width(萼片宽度)、petal length(花瓣长度)、petal width(花瓣宽度),单位都是厘米。3个种类是Setosa、Versicolour、Virginica,样本数量为150个,每类50个。
1.数据加载到DataFrame:
df = pd.DataFrame(load_iris().data,
columns=['萼片长度', '萼片宽度', '花瓣长度', '花瓣宽度'])
df = df.assign(种类=load_iris().target)

2.提取特征值和目标值,需要将数据结构转为array:
x_train = df[['萼片长度', '萼片宽度', '花瓣长度', '花瓣宽度']].to_numpy()
y_train = df['种类'].to_numpy()

3.切分数据集,将原数据分为两份,大部分用来做机器学习,小部分用于机器学习模型建立后的验证工作。将数据集随机划分成训练集和测试集,返回训练集特征值、测试集特征值、训练集目标值和测试集目标值:
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(x_train, y_train)
4.使用线性逻辑回归模型训练数据完成机器学习建模:
from sklearn.linear_model import LogisticRegression
lgr = LogisticRegression()
lgr.fit(x_train, y_train)
5.验证模型效果:
# 测试结果
lgr.predict(x_test)
# 实际
y_test
# 有多少准确的和不准确的
pd.Series((lgr.predict(x_test) == y_test)).value_counts(normalize=True)
"""
True 0.973684
False 0.026316
dtype: float64
"""
# 训练集上的准确度评分
lgr.score(x_train, y_train)
# 0.9821428571428571
# 测试集上的准确度评分
lgr.score(x_test, y_test)
# 0.9736842105263158
6.在原数据上的预测效果:
(
df.assign(预测种类=lgr.predict(df.loc[:, '萼片长度':'花瓣宽度'].to_numpy()))
.assign(是否正确=lambda x: x['种类']==x.预测种类)
.是否正确
.value_counts(normalize=True)
)
"""
True 0.98
False 0.02
Name: 是否正确, dtype: float64
"""