python三种编码OneHotEncoder,LabelEncoder,OrdinalEncoder对比
from sklearn.preprocessing import OneHotEncoder,LabelEncoder,OrdinalEncoder1.LabelEncoder
# LabelEncoder:Encode target labels with value between 0 and n_classes-1
# This transformer should be used to encode target values *i.e.* `y`, and not the input `X`.
#1.LabelEncoder用来给label编码(而不是特征),编码后的值为 0 and n_classes-1
#2.如果transform的时候出现了fit的时候未出现过的值,那么会报错(OrdinalEncoder可以通过参数解决)
#3.此编码不考虑等级顺序
注意,本案例使用特征(而不是标签)做测试,实际使用中,LabelEncoder多用于对标签进行编码,特征编码可以使用OrdinalEncoder。
# LabelEncoder:Encode target labels with value between 0 and n_classes-1
# This transformer should be used to encode target values *i.e.* `y`, and not the input `X`.
#1.LabelEncoder用来给label编码(而不是特征),编码后的值为 0 and n_classes-1
#2.如果transform的时候出现了fit的时候未出现过的值,那么会报错(OrdinalEncoder可以通过参数解决)
#3.此编码不考虑等级顺序
lab=LabelEncoder()
for col in discrete_cols:
col_name='LabelEncoder_'+col
lab.fit(df_combine[col])
df_train[col_name]=lab.transform(df_train[col]) #lab.transform的参数和返回值都是array-like of shape (n_samples,)
df_test[col_name]=lab.transform(df_test[col]) #lab.transform的参数和返回值都是array-like of shape (n_samples,)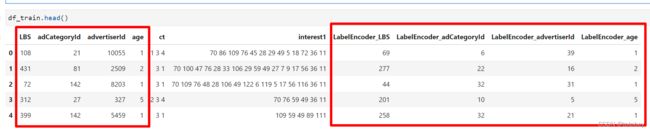
2.OrdinalEncoder
# OrdinalEncoder:Encode categorical features as an integer array(0 to n_categories - 1)
#Reshape your data either using array.reshape(-1, 1) if your data has a single feature or array.reshape(1, -1) if it contains a single sample.
#1.用来对特征进行序数编码(0 to n_categories - 1)——适用于本身有顺序的类别特征(比如年龄分层、学历等)
#2.可以通过参数categories指定需要保留的取值(指定后可以通过ohe.categories_查看)
#3.可以通过参数handle_unknown和unknown_value提前规定fit中未出现但是transform中出现的值如何编码
#4.可以通过orde.categories_查看各类别的编码顺序(展示的是原值,对应 0 to n_categories - 1)
#5.无稀疏矩阵sparse
#更多信息参见orde?
# OrdinalEncoder:Encode categorical features as an integer array(0 to n_categories - 1)
#Reshape your data either using array.reshape(-1, 1) if your data has a single feature or array.reshape(1, -1) if it contains a single sample.
#1.用来对特征进行序数编码(0 to n_categories - 1)——适用于本身有顺序的类别特征(比如年龄分层、学历等)
#2.可以通过参数categories指定编码的序数顺序(指定后可以通过orde.categories_查看)
#3.可以通过参数handle_unknown和unknown_value提前规定fit中未出现但是transform中出现的值如何编码
#4.可以通过orde.categories_查看各类别的编码顺序(展示的是原值,对应 0 to n_categories - 1)
#5.无稀疏矩阵sparse
#更多信息参见orde?
orde=OrdinalEncoder(dtype=np.int32,handle_unknown='use_encoded_value',unknown_value=-1)
for col in discrete_cols:
col_name='OrdinalEncoder_'+col
orde.fit(df_combine[col].values.reshape(-1,1)) #注意这里需要reshape
df_train[col_name]=orde.transform(df_train[col].values.reshape(-1,1))
df_test[col_name]=orde.transform(df_test[col].values.reshape(-1,1)) 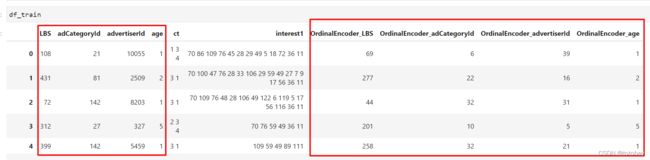
代码中间加print(orde.categories_)

3.OneHotEncoder
# OneHotEncoder:Encode categorical features as a one-hot numeric array(aka 'one-of-K' or 'dummy')
#a one-hot encoding of y labels should use a LabelBinarizer instead
#Reshape your data either using array.reshape(-1, 1) if your data has a single feature or array.reshape(1, -1) if it contains a single sample.
#1.对特征进行独热编码(可以是'one-of-K' or 'dummy'),适用于无序的类别特征。如果对标签进行编码则使用LabelBinarizer
#2.sparse : bool, default=True,默认为稀疏矩阵形式
#3.可以通过参数handle_unknown规定fit中未出现但是transform中出现的值进行'ignore'
#4.可以通过参数categories指定需要保留的取值(指定后可以通过ohe.categories_查看)
#5.灵活使用drop参数,控制如何drop掉多余的列
#更多信息参见ohe?
# OneHotEncoder:Encode categorical features as a one-hot numeric array(aka 'one-of-K' or 'dummy')
#a one-hot encoding of y labels should use a LabelBinarizer instead
#Reshape your data either using array.reshape(-1, 1) if your data has a single feature or array.reshape(1, -1) if it contains a single sample.
#1.对特征进行独热编码(可以是'one-of-K' or 'dummy'),适用于无序的类别特征。如果对标签进行编码则使用LabelBinarizer
#2.sparse : bool, default=True,默认为稀疏矩阵形式
#3.可以通过参数handle_unknown规定fit中未出现但是transform中出现的值进行'ignore'
#4.可以通过参数categories指定编码的顺序(指定后可以通过ohe.categories_查看)
#5.灵活使用drop参数,控制如何drop掉多余的列
#更多信息参见ohe?
#因为决定将oh结果存储为稀疏矩阵形式,所以后续拼接代码有所区别
train_sp=pd.DataFrame() #由于没有data,所以设置dtype=np.int64没用
test_sp=pd.DataFrame()
#`handle_unknown` must be 'error' when the drop parameter is specified, as both would create categories that are all zero.
ohe=OneHotEncoder(dtype=np.int8,handle_unknown='ignore')
for col in discrete_cols:
col_name='OneHotEncoder_'+col
ohe.fit(df_combine[col].values.reshape(-1,1)) #注意这里需要reshape
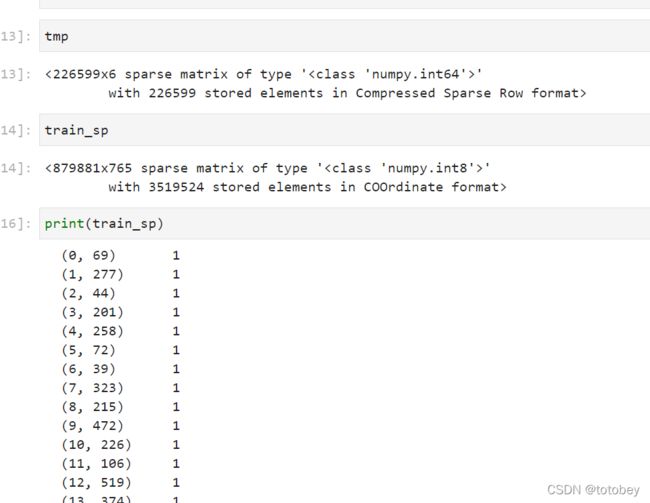
tmp=ohe.transform(df_train[col].values.reshape(-1,1)) #tmp in Compressed Sparse Row format
#hstack :将矩阵按照列进行拼接
train_sp=sparse.hstack((train_sp,tmp),dtype=np.int8) #注意,这里的顺序必须是(train_sp,tmp),不然会报错 #train_sp in COOrdinate format
tmp=ohe.transform(df_test[col].values.reshape(-1,1))
test_sp=sparse.hstack((test_sp,tmp),dtype=np.int8)