道路场景语义分割综述_王飞龙
挖坑:暂时还没有理解的定义或者方法,但因为暂时不重要留到后面看
论文结构
一、引言
1、道路场景语义分割定义
针对道路场景进行语义分割是对采集到的道路场景图像中的每个像素都划分到对应的类别,实现道路场景图像在像素级别上的分类。
2、道路场景语义分割面临的挑战
- 精确性
首先要克服不同目标对象的相异性和相似目标对象的相似性;其次还要注意分割对象所处场景的复
杂性; 最后一些外界因素如光照,拍摄条件、 拍摄设备和拍摄距离的不同也会使得目标物体与图片上差异较
大,进而影响分割的效果
- 实时性
二、图像语义分割发展历史
语义分割发展总历史:
- 传统语义分割:主要依靠图像纹理、颜色以及其他一些简易的表层特征和外部结构特征进行图像分割。以此方式得到的分割结果相对粗陋,精度较低,且无相关标注,即只是将图像分割成了若干块,但每一块是什么不知道,需要人工指定。
- 传统方法与深度学习相结合的语义分割:首先使用传统方法对图像进行初步处理, 得到目标区域。而后使用卷积神经网络(CNN)对目标特征进行学习,形成合理的分类器,实现目标的自动标注。此时算法已经能够将图像分成若干个部分,并标注出每一个部分是什么。
- 基于深度学习的语义分割:取得的效果较前两种方法好
2.1传统图像语义分割算法
基于阈值的语义分割
基于边缘的语义分割
基于聚类的语义分割
基于图论的语义分割
- N-cut(Normalized cut)算法
- Grab cut 算法
基于区域的语义分割
2.1.1N-cut算法
算法参考文献:
Yang Yupeng, Zhao Weidong, Wang Zhicheng, et al. Research on image-based imagesegmentation[J].Computer and Modernization,2010(1):113-116.
杨宇鹏, 赵卫东, 王志成等.基于图论的Normalized Cut图像分割方法研究[J]. 计算机与现代化,2010(1):113-116
算法思路:
该分割方法以图片为单位,将其定义为“图”并作为分割图像的依据。以图为单位,然后计算权重图(weighted graph),然后将其分割成一些具有相同特征的区域。其中最小分割算法(Min-cut algorithm)作为其中的一个重要的方法。
最小化切割算法:
如下式一个图的权重图,我们要把他分成两部分,则沿着两条权重最小的0.1的边进行切割就是最小化切割。
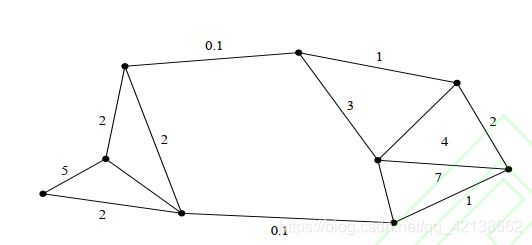
算法缺点:
最小化切割也存在边缘角元素缺失等缺陷。
2.1.2Grab cut算法
参考文献:
Qiuhua Zheng,Wenqing Li, et al. An Interactive Image Segmentation Algorithm Based on Graph Cut[J].Procedia Engineering,2012,29
Han Xu. Research on Grabcut based Automatic Image segmentation algorithm [D]. Beijing: Beijing PrintingInstitute, 2018: 8-9
Liu Lei, Shi Zhiguo, Su Haoru, et al. Image segmentation based on high order Markov random fields [J].Computer research and development, 2013,50 (9): 1933-1942.
刘 磊 , 石 志 国 , 宿 浩 茹 等 . 基 于 高 阶 马 尔 可 夫 随 机 场 的 图 像 分 割 [J]. 计 算 机 研 究 与 发展,2013,50(9):1933-1942
算法思路:
利用到混合高斯模型以及吉尔斯能量方程, 基于RGB对图像进行建模,在求得方程最优解过程中采用迭代方式,最终获取高斯模型的最优参数解。从而实现图像分割。
算法缺点:
需要较好的算法初始化数值
2.1.3最新的传统语义分割算法
1)轮廓检测法
- 参考论文:
Pablo Arbeláez, Maire M , Fowlkes C , et al. Contour Detection and Hierarchical Image Segmentation[J].IEEE Transactions on Pattern Analysis & Machine Intelligence, 2011, 33(5):898-916.
- 算法思路:
首先利用 GPB 方法对任一像素作边缘的实际概率进行合理测算,而后基于该测算结果形成不同的闭合区域,随后利用 UCM 法使不同的闭合区间进行转化,形成层次分明的树状结构。
2)随机决策森林分割法
- 算法论文:
Zhang C , Xue Z , Zhu X , et al. Boosted random contextual semantic space based representation for visual recognition[J]. Information ences, 2016, 369:160-170
- 算法思路:
整体此路与轮廓法相似,但与轮廓法不同的是,该检测法主要由不同的决策树进行组合形成分类器对闭合区域进行分类。
3)MCG分割法
- 算法论文:
Pont-Tuset Jordi, Arbelaez Pablo, et al Multiscale Combinatorial Grouping for Image Segmentation and Object Proposal Generation.[J]. IEEE transactions on pattern analysis and machine intelligence,2017, 39(1):128-140
- 算法思路:
首先使用 GPB-UCM 法对图像轮廓进行分割处理,得到不同的块状结构,而后使用随机法形成的分类器做进一步的分割处理。
2.2传统方法与深度学习相结合的图像语义分割方法
算法思路:首先使用传统方法对图像进行初步处理, 得到目标区域。而后使用卷积神经网络(CNN)对目标特征进行学习,形成合理的分类器,实现目标的自动标注。
三、基于深度学习的语义分割算法
相较于传统语义分割的优点:基于深度学习的语义分割方法更能获取更多,更高级的语义信息来表达图像中的信息
研究重点:提高语义分割精度
重大技术转折点:FCN(全卷积)模型初步实现像素级语义分割
FCN论文及源码:
论文:Evan Shelhamer, Jonathan Long, Trevor Darrell. Fully Convolutional Networks for Semantic
Segmentation[M]. IEEE Computer Society, 2017, 39(4): 640-651.
源码:https://github.com/shelhamer/fcn.berkeleyvision.org
根据网络训练方式的分类:
| 分类 | 优点 | 缺点 |
| 强监督 | 对于与训练集相似的测试集分割精度高 | 依赖密集标注的训练集,迁移效果差,对于未知场景分割效果差 |
| 弱监督 | 只需要图像级标注数据即可完成训练 | 需要大量训练数据,分割精度低于强监督 |
| 无监督 | 不依赖于密集标注的训练集,而且对未知环境分割效果好 | 目前分割效果差 |
3.1强监督语义分割方法
概述:需要大量像素级的语义标注样本,是无人驾驶领域语义分割的算法;弱监督和无监督的分割效果较差,无人驾驶用不了。对样本进行人工标注可以体现出大量有用的局部数据和细节特征,能在一定程度上大幅提升训练效果,增强分割精度。可以说,强监督学习模型是当前应用程度最广的分割模型,也是效果最佳、影响范围最大的算法模型
代表算法:全卷积神经网络(FCN)算法
全卷积网络结构示意图:
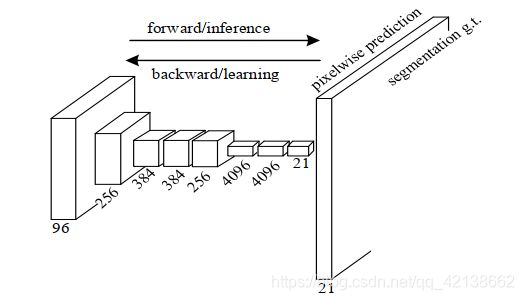
全卷积网络结构特点:
- 以一定数量其尺寸固定的卷积层,起到常规卷积网络中全连接层的作用;
- 全卷积网络(FCN)中包括的卷积层与采样层则分别涉及到上下、正反等多种类型,且上述层次在空间任意平移时保持结构不变
全卷积网络优点:
- 全卷积网络(FCN)中通过多个固定尺寸的卷积层承担传统结构中全连接层的任务,这种结构提升卷积神经网络的滑动灵活性,最终生成的预测图中包含稠密的输出图像,与神经网络在图片中的自由滑动密切相关。
原始全卷积网络缺点:
- 然而全卷积网络(FCN)仍然保留使用了卷积神经网络(CNN)中的池化层,池化层使得卷积神经网络增加了感受野并且进行了融合特征,但是连续的下采样,会导致细节丢失,极大地影响了分割的结果
- 较高的采样率会导致特征图大小和空间信息的损失
基于原始全卷积网络的发展:
共分为六类:基于扩大感受野的分割方法、基于概率图模型的分割方法、基于特征融合的分割方法、基于编码器-解码器的分割方法、基于循环神经网络的分割方法和基于生成对抗网络的分割方法。

3.1.1基于扩大感受野的方法
空洞卷积核扩张卷积似乎很像,但仍有一些区别?
1)空洞卷积(扩张卷积):运用卷积神经网络对图像进行语义分割,其中的池化操作过程将会不断增大感受野的有效范围,并融合背
景信息。但该过程同样会使图像分辨率持续不断的下降,会造成部分空间信息遗失。空洞卷积(扩张卷积)在保证图像分辨率属性的前提下,在不减小覆盖范围的同时提升感受野,且保留特定像素的位置信息。
Yu Fisher, Koltun Vladlen. Multi-scale context aggregation by dilated convolutions[J]. arXiv preprint arXiv:
1511. 07122, 2015
2)扩张卷积原理:使用不同扩张率的扩张卷积,可以看出进行卷积操作时,扩张率越高,其感受野越大。
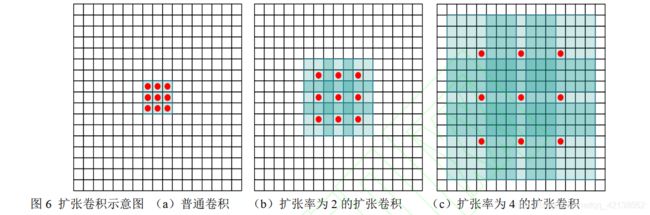
3)代表网络:
- DeepLab v1:将空洞卷积应用到 VGG16网络,通过将 VGG16 的全连接层转换为卷积层,并将 VGG 模型第四个和第五个池化层之后的所有卷积层分别调整为不同扩张率的空洞卷积,恢复感受野至原图像大小,提升了模型分割的准确率。
Chen L C, Papandreou G, Kokkinos I, et al. Semantic image segmentation with deep convolutional nets and
fully connected CRFs[J].International Conference on Learning Representations, 2014(4):357-361
- ENet:运用了 bottleneck 模块思维方式,对多个空洞卷积进行串行操作,以此调整感受野的实际区域大小,有效破解了特征分辨率持续下降等不良问题。参数少,实时性高。
Paszke Adam, Chaurasia Abhishek, et al. ENet: a deep neural network architecture for real-time semantic
segmentation[J] .arXiv preprint arXiv: 1606. 02147.
- DRN:立足 ResNet 网络基础,由两个不同扩张率的空洞卷积,对 ResNet 的末尾卷积层进行替换操作,以此不断增强空间有效信息。为了避免空洞卷积的循环利用引发的棋盘效应,需要借助移除残差和最大池化层等方法进行操作处理。最后通过全卷积等方法实现像素的输出操作。
Yu Fisher, Koltun Vladlen, Funkhouser Thomas. Dilated residual networks[C] / / IEEE Conference on
Computer Vision and Pattern Recognition(CVPR) , 2017: 636-644
4)扩张卷积的缺点及发展
缺点:在进行卷积操作处理时,容易形成一定的空间漏洞,以至于出现数据遗失、消息丢失等不良问题。在一个网络结构中循环反复利用空洞卷积势必会产生棋盘效应,也会使部分特征遗失,占用大量的运行空间,消耗大量的内存。
发展:
- 混合扩展卷积HDC:能够进一步扩大感受野,同时维持局部信息有关特征。但是由于卷积核的形状相对固定,模拟几何变换的处理能力相对较弱,适应图形变化的能力较差,提取不规则形状物体特征的能力也较差。
Fang, Y, Li, Y, et al, Face completion with Hybrid Dilated Convolution. Signal Processing-Image Communication, 80,2020:115664
- 可变形卷积:在进行卷积处理过程中,运用了有一定偏移量的采样操作,引入了可学习的一个偏移量,最终调整卷积核的形状,使其具有可变性。该种卷积模式能有效扩大感受野,增大图像区域,提高语义分割对图形变换的自适应能力,不断提高分割的精度和准确度。
Dai J, Qi H, Xiong Y, Li Y, Zhang G, Hu H, Wei Y. Deformable convolutional networks. In: Proc. of the IEEE Int’l Conf. on Computer Vision. 2017. 764-773
3.1.2基于概率图模型的分割方法
1)概率图模型(Probabilistic Graphical, PGM):用于 CNN 的后期处理,以结构化预测的方式有效地优化物体边界,捕获图像上下文信息,使得局部特征与全局特征的利用率能得以平衡.
2)概率图模型缺点:计算量过大,训练时间长,消耗大量内存等方面的问题
3)两种代表性的概率图分割模型:
- SegModel网络模型
Shen F, Gan R, Yan S, et al. Semantic segmentation via structured patch prediction, context CRF and guidance CRF[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition( CVPR) .2017: 5178-5186
- DFCN-DCRF网络模型
Jiang J, Zhang Z, Huang Y, et al. Incorporating depth into both CNN and CRF for indoor semantic segmentation[C]//2017 8th IEEE International Conference on Software Engineering and Service Science (ICSESS). IEEE, 2017: 525-530.
3.1.3基于特征融合的分割方法
1)特征融合:将提取出的特征图进行相加或拼接融合。
2)特征融合优点:
- 在特征提取阶段,通过融合多尺度的特征信息,丰富特征图的语义信息
- 特征的利用阶段,通过融合不同层级的特征更好地利用全局有效信息,提高分割精度
- 通过融合不同层次、不同区域特征来捕获图像中隐含的上下文信息,能有效提高分割速率和分割效能,也能大幅度降低运行消耗
3)代表网络
- 特征金字塔网络:该网络通过调整高层特征、低层特征的连接形式,丰富各尺度下特征的语义信息
3.1.4基于编码-解码器的方法
1)编码-解码器:编码器通过由一系列卷积-池化操作,提取图像的主要特征信息。再通过解码器的上采样-转置卷积结构,逐步恢复图像的空间维度。依托编码器-解码器的基本方法,可以对低分辨率的图形进行特征处理和上采样操作,以此形式可有效解决分辨率不断下降的问题,可以高度还原像素的时空信息和图形的维度数据。
2)代表网络:
- SegNet:采用 VGG-16 网络,利用该网络输出稠密的特征图,通过对稀疏图像的卷积计算实现对稠密图的恢复
A. Krizhevsky, I. Sutskever, G.E. Hinton. ImageNet classification with deep convolutional neural networks[C]. Advances in neural information processing systems, 2012, 1097-1105
- U-net:该网络的编码解码结构作用不同且相互配合,起到完善细节恢复效果的作用。但只能处理2D图像。在此基础上提出的V-Net可以处理3D场景。
Ronneberger O, Fischer P, Brox T. U-net: Convolutional networks for biomedical image segmentation[C]//International Conference on Medical image computing and computer-assisted intervention. Springer, Cham,2015: 234-241.
3)改进方向
- 提高语义分割实际速度:ENet,LEDNet
- 对多个分辨率特征进行融合:DUpsamling
- 扩展感受野的有效范围:GCN
- 对多尺度多层级信息进行捕获:SDN
3.1.5基于循环神经网络(RNN)的方法
1)循环神经网络(RNN):该种模型的主要优势特征在于,学习当前信息之外。能够实现对历史数据和历史记忆的递归处理,能够对图像内的序列信息进行提取操作,同时也能对图像语义关系合理建模获取有关数据信息。与此同时,该网络模式能与卷积层深入结合,并融入到神经网络结构中,以此形式对卷积层空间特征进行有效提取,也能实现对像素特征的深度提取。
Yang Li, Wu Yuxi, Wang Junli, Liu Yili. Review of cyclic neural networks [J]. Computer applications,2018,38 (S2): 1-6 + 26.
杨丽,吴雨茜,王俊丽,刘义理.循环神经网络研究综述[J].计算机应用,2018,38(S2):1-6+26.
3.1.6基于生成对抗网络(GAN)的方法
1)GAN网络:图形分割过程中,运用判别器对分割对象的局部属性、全局结构特点进行深入学习,以此获取不同像素间的有效空间关系
Wang Kunfeng, Gou Chao, Duan Yanjie, et al. Research progress and Prospect of generative countermeasure network Gan [J]. Acta automatica Sinica, 2017,43 (3): 321-332
王坤峰,苟超,段艳杰等.生成式对抗网络GAN的研究进展与展望[J].自动化学报,2017,43(3):321-332.
2)GAN网络优点:GAN 模型还具有能够识别数据真假,并持续产生新数据的能力。该方法仍存在较大提升空间。
3)GAN网络缺点:GAN 模型在运用过程中存在一定的不稳定性,尤其针对大数据图像,该方法的解释性、可延伸性存在不足,仍有较大的提升空间。
3.2弱监督语义分割方法
不需要像素级的标注样本,只需要图像级的标准样本即可。根据不同类型的弱监督信息,将弱监督图像语义分割分为六类:基于边界框级标注方法、基于涂鸦级标注方法、基于点级标注方法、基于图像级标注方法、基于混合标注方法以及基于附加数据源方法。
主要目的:降低标注内容获取的人工成本。
弱监督语义分割方法分类:
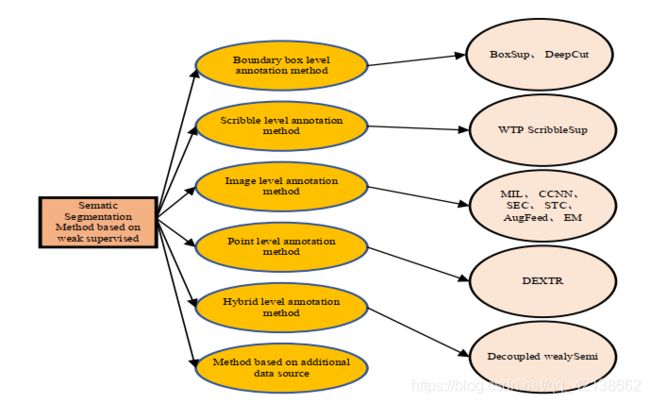
3.2.1基于边界框级标注方法
监督信息:包括整个物体的矩形区域
特点:该标注方法是众多标注方法(指在弱监督中)中较为复杂的一种,但是其包含了更多的语义信息,成本较低,分割性能较好。
代表网络:
- BoxSup网络模型
Dai J, He K, Sun J. BoxSup: Exploiting bounding boxes to supervise convolutional networks for semantic segmentation. IEEE, International Conference on Computer Vision(ICCV), 2015: 1635-1643.
3.2.2基于涂鸦级的标注方法
监督信息:包含涂鸦线条和涂鸦点的图像
基本原理:首先基于涂鸦点和涂鸦线条对图像进行标注处理,然后基于标注处理后的图片进行训练。
3.2.3基于点级标注方法
监督信息:标识位置信息,中心位置等
优点:同等预算,分割效果最优
3.2.4基于图像级标注
监督信息:这是一张包含xxx的图片?
优点:标注过程相对简单,不需要使用像素标注,样本获取相对容易,整体工作量相对较小
缺点:图像级标注的方法显得有些简单粗陋,很难取得良好的、符合预期的分割效果
3.2.5混合标注方法
监督信息:大部分弱监督图像和少量像素级标注图像
特点:实现了强监督和弱监督的优势互补
3.2.6基于附加数据源的方法
例如使用类标签作为关键词,以 web 库作为搜索源,运用全自动的检索方式获取有关视频资料。
3.3无监督语义分割方法
基本原理:无人工标注信息,通过分类器进行分类
无监督语义分割方法分类:

四、城市道路场景数据集
4.1常用数据集
4.1.1自动驾驶数据集
概述:PASCAL VOC 2012 数据集更多地应用于静态图像的测试; Cityscapes 和 CamVid 数据集更多地应用于动态场景和实时性较高的场景的测试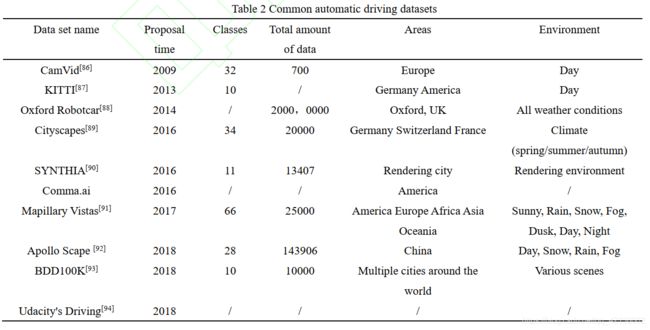

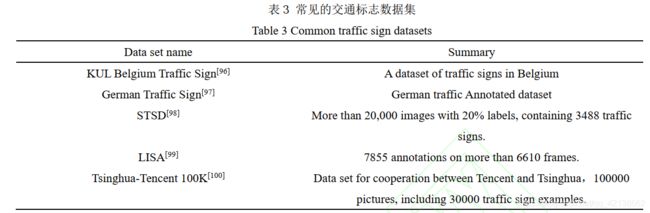
4.1.2交通标志
4.2性能评价指标
1)运行时间
2)准确度
- 像素准确度PA
- 平均准确率mPA
- 平均交并比mIoU(最受认可,应用最广的评价指标)
- 频率加权交并比FWIoU
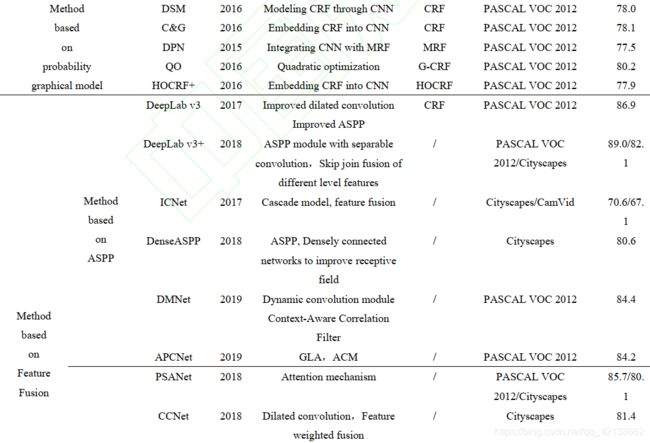
4.3强监督语义分割方法性能对比
4.3.1准确率
概述:针对道路场景语义分割,基于 CityScapes 数据集,DeepLab V3+、 DenseASPP、 DUC+HDC、 PSPNet、 PSANet、 CCNet 和 DANet 等算法的 mIoU 值均超过了80%,分割精度基本满足对街道场景图像语义分割的精度要求,然而这些算法实时性上有所欠缺。 ENet、ESPNet、 ICNet 和 BiSeNet 这四种算法虽然分割准确率不如上述算法,但由于尺寸小,计算成本轻等特点,这些算法具有实时性强的优势。


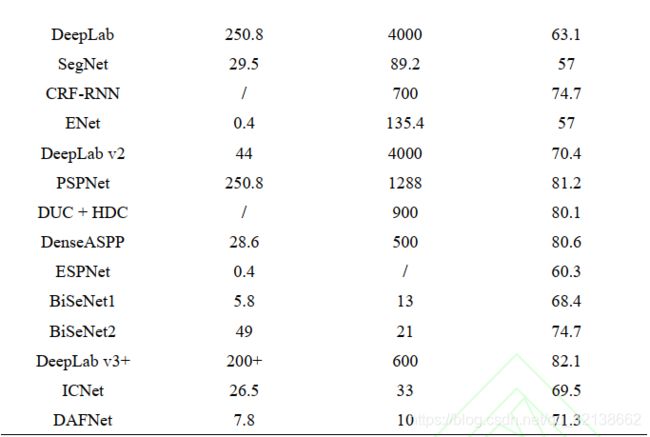
 4.3.2速度
4.3.2速度
在Cityscapes数据集上做实验:

4.3.3总结
BiSeNet 提出了用于高分辨率图像的浅层网络和快速下采样的深度网络,以在分类能力和感受野之间取得平衡,是目前在分割效率和准确性之间达到均衡最突出的算法之一,精度比DeepLab等高精度算法比低了5-10个百分点,但是速度是他们的几十倍。
Yu C, Wang J, Peng C, et al. Bisenet: Bilateral segmentation network for real-time semantic
segmentation[C]//Proceedings of the European Conference on Computer Vision (ECCV).2018: 325-341BiSeNet1代码已经开源:https://github.com/CoinCheung/BiSeNet
BiSeNet2代码即将开源:https://github.com/ycszen/BiSeNet
而 FCN、 和基于 FCN 的 DeepLab v1、 DeepLab v2 运行时间较长,无法满足实时图像分割的需求。而在 DeepLab 系列中, DeepLab v3+分割效果最好,主要是其吸取 DeepLab 系列方法的优点,并结合深度可分离卷积使模型得到简化,提高了分割效率,从而实现图像语义分割精度和速度的均衡。