Elasticsearch配置及Python操作
一、相关软件介绍
1. Elasticsearch
Elasticsearch,简称为ES,是一个分布式、高扩展、高实时的搜索与数据分析引擎。它能很方便的使大量数据具有搜索、分析和探索的能力。无论是结构化或非结构化文本、数字数据还是地理空间数据,Elasticsearch 都能以支持快速搜索的方式高效地存储和索引它。
本文在linux环境使用Elasticsearch-7.14.0版本进行配置及操作。
2. Kibana(辅助工具)
Kibana 是一个开源的分析与可视化平台,可实现以交互方式探索、可视化和分享对数据的见解,并管理和监控堆栈。它和Elasticsearch一起使用,用于搜索、查看存放在Elasticsearch中的数据。
3. elasticsearch-head(辅助工具)
elasticsearch-head 是用于监控 Elasticsearch 状态的客户端插件,包括数据可视化、执行增删改查操作等。
4. elasticsearch-py
elasticsearch-py是官方提供的Elasticsearch python客户端库,它只是对Elasticsearch的rest API接口做了一层简单的封装。
二、环境搭建
1. Elasticsearch部署
下载
Elasticsearch 7.14.0
解压
tar -zxvf elasticsearch-7.14.0-linux-x86_64.tar.gz安装ES不用使用root用户,创建普通用户work
修改配置文件config/elasticsearch.yml,配置项如下:
cluster.name: es-cluster
node.name: es-node
node.master: true
node.data: true
node.max_local_storage_nodes: 1
path.data: /data/elasticsearch/data
path.logs: /data/elasticsearch/logs
network.host: 0.0.0.0
http.port: 9200
transport.tcp.port: 9300
transport.tcp.compress: true
discovery.seed_hosts: ["192.168.1.90:9300"]
cluster.initial_master_nodes: ["es-node"]
http.cors.enabled: true
http.cors.allow-origin: "*"启动ES
./bin/elasticsearch
elasticsearch启动成功样例图
后台方式启动ES:
./bin/elasticsearch -d可能出现的错误及解决方法
(1)错误1
max file descriptors [4096] for elasticsearch process is too low, increase to at least [65535]解决方法:
sudo vim /etc/security/limits.conf追加以下内容:
* soft nofile 65536
* hard nofile 65536
* soft nproc 4096
* hard nproc 4096(2)错误2
max number of threads [3802] for user [work] is too low, increase to at least [4096]解决方法:
sudo vim /etc/security/limits.d/20-nproc.conf修改为:
* soft nproc 4096(3)错误3
max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]解决方法:
sudo vim /etc/sysctl.conf修改为:
vm.max_map_count=262144执行以下命令生效:
sysctl -p2. Kibana
下载
Kibana 7.14.0 | Elastic
解压
tar -zxvf kibana-7.14.0-linux-x86_64.tar.gz修改配置文件config/kibana.yml,配置项如下:
server.host: "192.168.1.90"
server.shutdownTimeout: "5s"
elasticsearch.hosts: ["http://192.168.1.90:9200"]
monitoring.ui.container.elasticsearch.enabled: true
server.port: 5601
kibana.index: ".kibana"
i18n.locale: "zh-CN启动kibana
./bin/kibana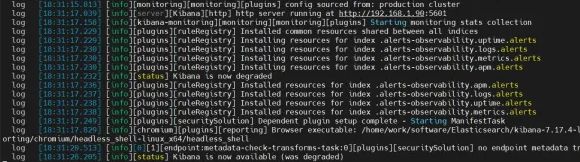
kibana启动成功样例图
浏览器打开kibana开发工具
http://192.168.1.90:5601
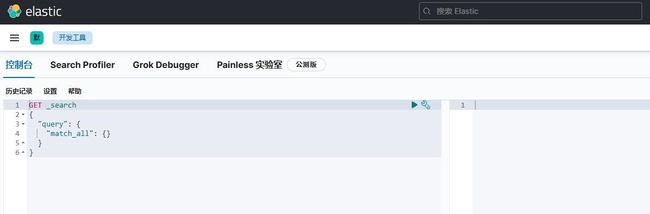
kibana开发工具界面图
3. elasticsearch-head
此处提供编译好的版本,解压后运行npm run start即可启动
链接:https://pan.baidu.com/s/19F8zMdN94QhgqYP9vkPHHA
提取码:a99y自行下载编译
https://github.com/mobz/elasticsearch-head
cd elasticsearch-head
npm install
npm run start
elasticsearch-head启动成功样例图
浏览器打开elasticsearch-head,查看ES状态

elasticsearch-head界面图
集群健康值
green: 所有主要分片和复制分片都可用
yellow: 所有主要分片可用,但不是所有复制分片都可用
red: 不是所有的主要分片都可用当集群状态为red,它仍然正常提供服务,它会在现有存活分片中执行请求,此时需要尽快修复故障分片,防止查询数据的丢失。
4. elasticsearch-py
(1)官方文档
Python Elasticsearch Client
(2)安装库
pip install elasticsearch==7.14.0三、核心概念
索引(Index)
索引就是一类文档的集合,类似于关系型数据库中的表。索引由其名称进行标识,每个索引名称必须是小写。
文档(Document)
Index中单条记录称为文档,等同于关系型数据库表中的行。
字段(Field)
json结构的字段,等同于关系型数据库表中的列。
映射(Mapping)
Mapping是处理数据的方式和规则方面做一些限制,如:某个字段的数据类型、默认值、分析器、是否被索引等等,都是映射里可以设置的。
分片(Shards)
一个索引可以存储超过单个节点硬件限制的大量数据,相当于分表的概念。ES提供了将索引划分成多份的能力,每一份称之为分片。当创建一个索引的时候,可以指定想要的分片数量。允许水平分割/扩展内容容量;允许在分片之上进行分布式的、并行的操作,进而提高性能/吞吐量。
副本(Replicas)
在分片/节点失败的情况下,提供了高可用性。复制分片从不与原/主要分片置于同一节点上是非常重要的。扩展搜索量/吞吐量,因为搜索可以在所有副本上并行运行。
四、python操作ES
1. 连接ES
from elasticsearch import Elasticsearch
def main():
# 连接ES
es=Elasticsearch(["192.168.1.90:9200"],
sniff_on_start=True,# 连接前测试
sniff_on_connection_fail=True,# 节点无响应时刷新节点
sniffer_timeout=60# 设置超时时间)
if__name__=='__main__':
main()2. 增
创建索引
# 定义mapping body
body_index = {
'mappings': {
'properties': {
'name': {
'type': 'keyword'
},
'age': {
'type': 'long'
},
'tags': {
'type': 'text'
}
}
},
'settings': {
'index': {
'number_of_shards': '3',
'number_of_replicas': '0'
}
}
}
# 创建index
res = es.indices.create(index=index_name, body=body_index, ignore=400)插入单个数据
person1 = {
'name': '张三',
'age': 18,
'tags': '勤奋学习十载寒窗,凿壁借光,囊萤映雪,手不释卷,有良好的表达能力。有耐心心态好,善于维系客户关系。果断热情勇敢孤僻活力,思想成熟能够独立工作。'
}
res = es.index(index=index_name, body=person1)批量插入数据
from elasticsearch import helpers
insert_infos = []
person2 = {
'_index': index_name,
'name': '李四',
'age': 20,
'tags': '有极强的领导艺术,公正严明铁面无私,公私分明。关心他人无微不至,体贴入微。精力充沛,并有很强的事业心。气吞山河正气凛然,善于同各种人员打交道。'
}
person3 = {
'_index': index_name,
'name': '王五',
'age': 19,
'tags': '尊敬师长团结同学,乐于助人学习勤奋,用心向上,用心参加班级学校组织的各种课内外活动。用心开展批评与自我批评。'
}
insert_infos.append(person2)
insert_infos.append(person3)
helpers.bulk(client=es, actions=insert_infos)
elasticsearch-head数据浏览界面
3. 删
删除索引
# 删除index
res = es.indices.delete(index=index_name, ignore=[400])按id删除文档
# 按id删除
res = es.delete(index=index_name, id='bKTgXYUBfH4USN9RFMOh')按条件删除文档
# 按条件删除
body = {
'query': {
'match': {
'name': '张三'
}
}
}
res = es.delete_by_query(index=index_name, body=body, ignore=[400, 404])4. 改
index
body = {
'name': '王五',
'age': 19,
'tags': '尊敬师长团结同学,乐于助人学习勤奋,用心向上,用心参加班级学校组织的各种课内外活动。用心开展批评与自我批评。'
}
res = es.index(index=index_name, id='baTgXYUBfH4USN9RFMOh', body=body)index() 方法完成两个操作,如果数据不存在,那就执行插入操作,如果已经存在,那就执行更新操作。
index实现更新时,body中必须写入全部字段,否则未包含的字段会被置为空。
update
body = {
'doc': {
'name': '王五'
}
}
es.update(index=index_name, id='baTgXYUBfH4USN9RFMOh', body=body)5. 查
查看es中的索引
# 查看ES中索引的信息
index_info = es.indices.get('*')
# 查看索引的名称
index_names = index_info.keys()判断索引是否存在
index_name = 'es_index'
print(es.indices.exists(index_name))查询文档数量
doc_count = es.count(index=index_name)按id查询
body = {
'query': {
'match': {
'_id': 'baTgXYUBfH4USN9RFMOh'
}
}
}
res = es.search(index=index_name, body=body)按属性查询,结果过滤返回指定字段
body = {
'query': {
'match': {
'age': 20
}
},
'_source': ['name', 'tags']
}
res = es.search(index=index_name, body=body)按年龄排序
body = {
'sort': {
'age': {
'order': 'desc' # asc: 升序, desc: 降序
}
}
}
res = es.search(index=index_name, body=body)查询年龄大于18且小于等于20的文档
body = {
'query': {
'range': {
'age': {
'gt': 18,
'lte': 20
}
}
}
}
res = es.search(index=index_name, body=body)按年龄降序且分页查询
body = {
'sort': {
'age': {
'order': 'desc' # asc: 升序, desc: 降序
}
},
'from': 0,
'size': 1
}
res = es.search(index=index_name, body=body)精准查询
body = {
"query": {
"match_phrase": {
"tags": "耐心"
}
}
}
res = es.search(index=index_name, body=body)布尔查询:姓名为张三且tags中包含“耐心”
body = {
"query": {
"bool": {
"must": [
{
"match": {
"name": "张三"
}
},
{
"match_phrase": {
"tags": "耐心"
}
}
]
}
}
}
res = es.search(index=index_name, body=body)布尔查询:姓名为王五且tags中不包含“耐心”
body = {
"query": {
"bool": {
"must": [
{
"match": {
"name": "王五"
}
}
],
'must_not': [
{
"match_phrase": {
"tags": "耐心"
}
}
]
}
}
}
res = es.search(index=index_name, body=body)五、DSL语句
Query DSL是一个Java开源框架用于构建类型安全的SQL查询语句。在查询时,通常先在Kibana中使用DSL验证查询语句的正确性,再转到python中使用。
查询所有索引

DSL执行界面图
添加文档:id设为1
PUT /es_index/_doc/1
{
"name": "赵六"
}删除文档:id=1
DELETE /es_index/_doc/1查询
GET /es_index/_search
{
"query": {
"match": {
"age": 18
}
}
}先验证结果正确,将GET /es_index/_search后{}的内容转到python的body中即可。

智驱力-科技驱动生产力
www.aidrive-tech.com