optuna-dashboard自动超参数优化和可视化利器
介绍
Optuna库是机器学习中提供自动化超参数优化的库,它和很多知名的机器学习库
(如sklearn,keras,tensorflow,xgboost,lightgbm,pytorch等)是兼容的。
dashboard是其中一个提供结果画图展示和可交互操作的功能,在当前的版本中已经被独立出来成为一个模块,下面将用一个简单的示例来展现它的效果。
示例
在使用之前,如果没有安装,可以使用以下命令进行安装。
conda install -c conda-forge optuna
或者
pip install optuna
安装好optuna库后,再安装optuna-dashboard。
conda install -c conda-forge optuna-dashboard
或者
pip install optuna-dashboard
安装完毕后先用optuna创建好我们要用的study,将它保存在数据库中,然后用dashboard导入即可,具体如下:
import optuna
import sklearn
def objective(trial):
Classifier_name = trial.suggest_categorical('classifier', ['GradientBoosting', 'RandomForest'])
if Classifier_name == 'GradientBoosting':
n_estimators = trial.suggest_int('n_estimators', 100, 500, log=True)
Classifier_obj = sklearn.ensemble.GradientBoostingClassifier(n_estimators=n_estimators)
else:
rf_max_depth = trial.suggest_int('rf_max_depth', 2, 20)
Classifier_obj = sklearn.ensemble.RandomForestClassifier(max_depth=rf_max_depth)
Classifier_obj.fit(x_train, y_train)
y_pred = Classifier_obj.predict(x_valid)
accuracy = sklearn.metrics.accuracy_score(y_valid, y_pred)
return accuracy
study = optuna.create_study(study_name='titanic2',direction="maximize",storage='sqlite:///db.sqlite3')
study.optimize(objective, n_trials=100)
用optuna第一步就是定义你要的目标函数,这里我们返回的是由sklearn函数定义的在验证集上的精准度,然后我们定义了两种分类器:GBDT和RF去训练,超参数分别为树的个数(100-500)和深度(2-20)。
定义完后创建会话时,study_name指定了你的会话名称,direction为maximize或者minimize,最大或者最小,默认是最小,这里我们要让精确度最大,所以用maximize,storage定义了你的存储方式,这里我们用sqlite3,也可以用mysql等。
开始优化后,会输出一系列优化日志如下:
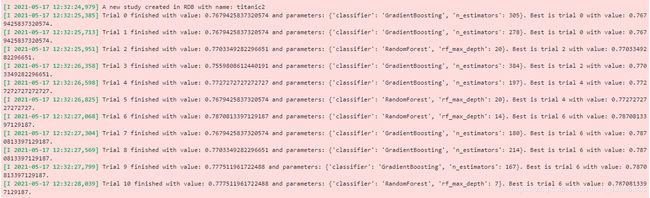
输出的是每次优化的结果,如果想要查看最佳的参数,可以使用如下代码:
print("Best value: {} (params: {})\n".format(study.best_value, study.best_params))
#返回最好的值和参数
#Best value: 0.8014354066985646 (params: {'classifier': 'RandomForest', 'rf_max_depth': 8})
以上日志默认的保存位置在你当前的工作目录,会生成一个db.sqlite3的文件,将它复制到C盘/用户/用户名目录下,比如我这里是:

再打开命令行或者anaconda-prompt,输入以下命令启动dashboard:
optuna-dashboard sqlite:///db.sqlite3

复制127.0.0.1:8080到你的浏览器里打开,就可以看到你的dashboard和study了:
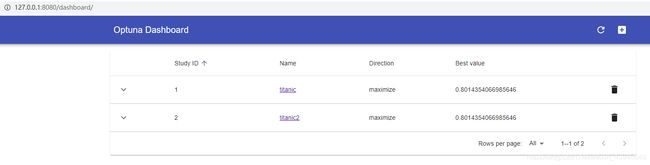
点进去就可以看到一系列图:
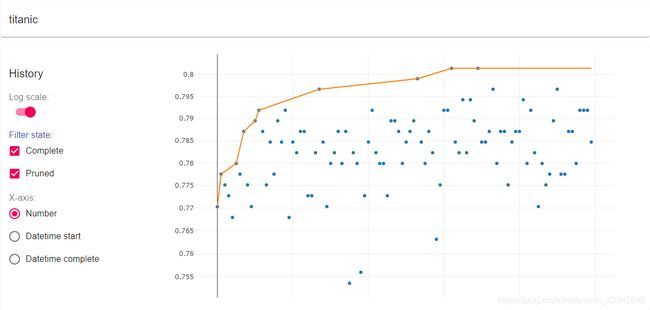
总体的优化图,可以看到准确率的上升趋势,我们这里用的训练集是Kaggle的泰坦尼克项目提供的整个训练集,验证集是Ground_truth也就是要预测的正确答案,所以到0.8几的时候几乎无法提升了。

分类器的比较图,从右往左看,可以看到RandomForest在该项目上的表现总体是要优于GradientBoosting的,GBDT最高在0.78左右,而RF可以到达0.8的准确率。
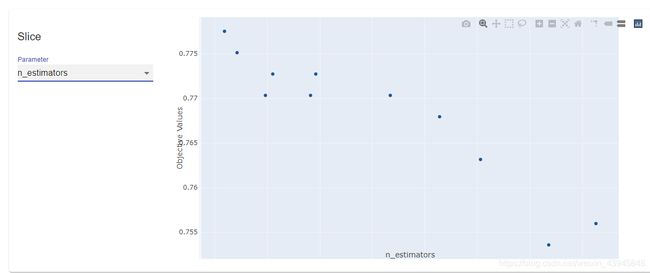
Slice图可以在左边交互选择你要查看的超参数和目标函数的变化,这里我们选择GBDT的树的个数,可以发现,在这个项目上,树的个数越多,也就是boosting的次数越多,泛化效果反而越差,降低了偏差,提高了方差。

页面最下方就是之前显示的输出日志了,可以具体查看每一步的值。
注意事项
在使用optuna-dashboard的时候关键就是找对你的会话保存的目录,如果你不确定自己的目录在哪的话,可以用everything搜索文件名,按修改日期排序,一目了然。