pytorch实践08(刘二大人)
今天跟着刘老师学习了第八讲加载数据集,主要是让数据训练时利用mini_batch进行训练,从而提高计算速度,主要区分三个词epoch,batch-size,iteration

在视频中刘老师给出了三个名词的定义:epoch表示所有的样本训练的轮数,batch-size表示训练一次前馈和反向传播的样本的数量,iteration表示所有样本数量/一个batch-size所包含的样本数量。
随后又讲了Dataset和Dataloader的作用,Dataset 是抽象类,不能实例,而Dataloader可以实例


刘老师所给出的源代码如下:
import torch
import matplotlib.pyplot as plt
import numpy as np
from torch.utils.data import Dataset,DataLoader
#准备数据集
class DiabetesDataSet(Dataset):
def __init__(self,filepath):
#filepath为文件路径,delimiter为数据分割符,dtype为数据的类型
xy = np.loadtxt(filepath,delimiter=',',dtype=np.float32)
#获得数据集长度
self.len = xy.shape[0]
self.x_data = torch.from_numpy(xy[:,:-1])
self.y_data = torch.from_numpy(xy[:,[-1]])
#完成索引方法
def __getitem__(self, index):
return self.x_data[index],self.y_data[index]
def __len__(self):
return self.len
#实例化
dataset = DiabetesDataSet('C:/Users/CZY/Desktop/pytorch实战/diabetes.csv.gz')
#将数据集设置成可min-batch训练
train_loder = DataLoader(dataset=dataset,
batch_size=32,
shuffle=True,
num_workers=2)
#构建模型
class Model(torch.nn.Module):
def __init__(self):
super(Model, self).__init__()
self.linear1 = torch.nn.Linear(8,6)
self.linear2 = torch.nn.Linear(6,4)
self.linear3 = torch.nn.Linear(4,1)
self.sigmoid = torch.nn.Sigmoid()
def forward(self,x):
x = self.sigmoid(self.linear1(x))
x = self.sigmoid(self.linear2(x))
x = self.sigmoid(self.linear3(x))
return x
model = Model()
#构造损失函数和优化器
Loss = torch.nn.BCELoss(size_average=False)
Optim = torch.optim.SGD(model.parameters(),lr = 0.01)
#训练循环
for epoch in range(1000):
for i,data in enumerate(train_loder,0):
#准备数据集
inputs,labels = data
#前馈传播
y_pred = model(inputs)
loss = Loss(y_pred,labels)
print('epoch',epoch,'loss',loss.item())
#反向传播
Optim.zero_grad()
loss.backward()
#更新
Optim.step()运行后会报如下的错误:

我从网上查找出错的原因,有人说是windows下无法进行并行运算导致的,所以我就将代码稍作修改:
import torch
import matplotlib.pyplot as plt
import numpy as np
from torch.utils.data import Dataset,DataLoader
#准备数据集
class DiabetesDataSet(Dataset):
def __init__(self,filepath):
#filepath为文件路径,delimiter为数据分割符,dtype为数据的类型
xy = np.loadtxt(filepath,delimiter=',',dtype=np.float32)
#获得数据集长度
self.len = xy.shape[0]
self.x_data = torch.from_numpy(xy[:,:-1])
self.y_data = torch.from_numpy(xy[:,[-1]])
#完成索引方法
def __getitem__(self, index):
return self.x_data[index],self.y_data[index]
def __len__(self):
return self.len
#实例化
dataset = DiabetesDataSet('C:/Users/CZY/Desktop/pytorch实战/diabetes.csv.gz')
#将数据集设置成可min-batch训练
train_loder = DataLoader(dataset=dataset,
batch_size=32,
shuffle=True)
#构建模型
class Model(torch.nn.Module):
def __init__(self):
super(Model, self).__init__()
self.linear1 = torch.nn.Linear(8,6)
self.linear2 = torch.nn.Linear(6,4)
self.linear3 = torch.nn.Linear(4,1)
self.sigmoid = torch.nn.Sigmoid()
def forward(self,x):
x = self.sigmoid(self.linear1(x))
x = self.sigmoid(self.linear2(x))
x = self.sigmoid(self.linear3(x))
return x
model = Model()
#构造损失函数和优化器
Loss = torch.nn.BCELoss(size_average=False)
Optim = torch.optim.SGD(model.parameters(),lr = 0.01)
#训练循环
loss_list = []
for epoch in range(1000):
for i,data in enumerate(train_loder,0):
#准备数据集
inputs,labels = data
#前馈传播
y_pred = model(inputs)
loss = Loss(y_pred,labels)
print('epoch',epoch,'loss',loss.item())
#反向传播
Optim.zero_grad()
loss.backward()
#更新
Optim.step()
loss_list.append(loss.item())
plt.plot(loss_list,color = (0,0.5,0.5))
plt.xlabel('epoch')
plt.ylabel('loss')
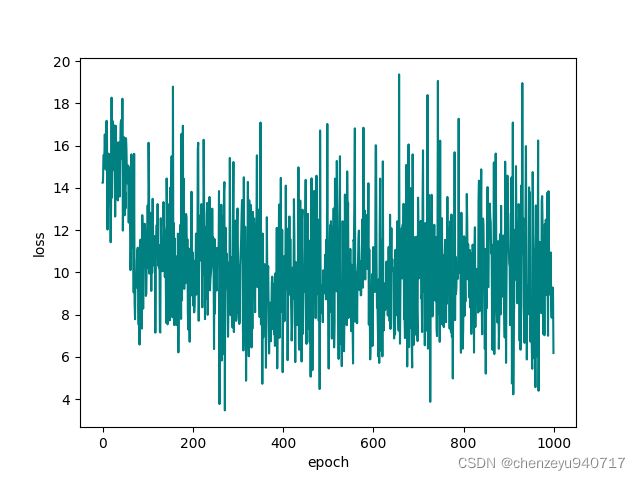
plt.show()运行后没有报错,得到的可视化结果如下:
刘老师在课后留了联系,等我完成后会将代码上传!