【医学影像】超声(UltraSound)影像的增强与目标检测
文章目录
- 1 综述
-
- 1.1 超声发展简史
- 1.2 超声类型
- 2 超声影像的去噪与增强
-
- 2.1 各向异性扩散去噪模型
- 2.2 色彩恢复的视网膜增强算法SSR和MSR
- 2.3 MSRCR增强算法(基于MSR算法改进版)
- 2.4 参考文献
- 3 超声影像的目标识别
-
- 3.1 基于跨模态数据迁移进行DL训练
- 3.2 参考文献
1 综述
因工作需要,最近调研了超声(UltraSound)影像的相关资料文献(公开的图书,论文等),包含超声类型、超声影像的去噪和增强,基于超声目标检测,与CT / MRI 多模态融合配准等,并对其进行了梳理整合,欢迎各位进行交流学习。【人肉整理,转载请注明出处】
本人另一博文调研了超声(UltraSound)影像与 CT/MRI 多模态融合配准,欢迎大家讨论交流哈…
超声医学使用领域广泛,技术发展迅速,是现代临床医学的重要组成部分。现今的腹部超声诊断,可以提供脏器切面的形态结构、某些生理功能血流动力学等信息,有助于了解器官组织的血流灌注情况(如肾衰患者双肾大小改变、血流灌注分布情况);与X线、CT、MRI、核医学成像共同构成了现代医学影像技术,并以其所具有的显著特点(价格低廉、动态实时等),逐步得到广泛应用。
1.1 超声发展简史
超声医学(ultrasonic medicine)是利用超声波的物理特性与人体器官、组织的声学特性相互作用后得到诊断或治疗效果的一门学科。向人体发射超声,并利用其在人体器官、组织中传播过程中,由于声的透射、反射、折射、衍射、衰减、吸收而产生各种信息,将其接收、放大和信息处理形成波型、曲线、图像或频谱,籍此进行疾病诊断的方法学,称为声诊断学(ultrasonic diagnostics)超利用超声波的能量(热学机制、机械机制、空化机制等),作用于人体器官、组织的病变部位,以达到治疗疾病和促进机体康复的目的方法学,称为超声治疗学(ultrasonic therapeutics)。
超声治疗(ultrasonic therapy)的应用早于超声诊断,1922年德国就有了首例超声治疗机的发明专利,超声诊断到1942年才有德国Dussik应用于脑肿瘤诊断的报告。但超声诊断发展较快,20世纪50年代国内外采用A型超声仪,以及继之问世的B型超声仪开展了广泛的临床应用,至20世纪70年代中下期灰阶实时(grey scale real time)超声的出现,获得了解剖结构层次清晰的人体组织器官的断层声像图,并能动态显示心脏、大血管等许多器官的动态图像,是超声诊断技术的一次重大突破,与此同时一种利用多普勒(Doppler)原理的超声多普勒检测技术迅速发展,从多普勒频谱曲线能计测多项血流动力学参数。20世纪80年代初期彩色多普勒血流显示(Color Doppler flow imaging, CDFI)的出现,并把彩色血流信号叠加于二维声像图上,不仅能直观地显示心脏和血管内的血流方向和速度,并使多普勒频谱的取样成为快速便捷,80 ~ 90年代以来超声造影、二次谐波和三维超声的相继问世,更使超声诊断锦上添花。
1.2 超声类型
A型超声仪是用幅度调制型进行诊断的方法,由于幅度(amplitude)一词的英文单词第一个字母为A,故A型超声诊断。以回声振幅的高低和波数的流密显示。纵坐标代表回声信号的强弱,横坐横代表回声的时间(距离)。常用A型越声诊断仪测量组织界面距离,脏器大小,鉴别病变的声学性质,结果比较准确。
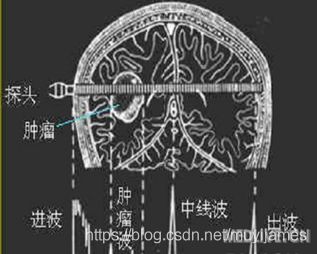
B型超声诊断是辉度调制型,因brightness modulation词组的第一个字母为B,故B型超声诊断。以点状回声的亮度强弱显示病变。回声强则亮,回声弱则暗。当探头声束按次序移动时,示波屏上的点状回声与之同步移动。由于扫描形成与声束方向一致的切面回声图,故属于二维图象,具有真实性强、直观性好、容易掌握和诊断方便等优点。
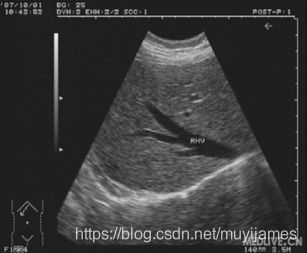
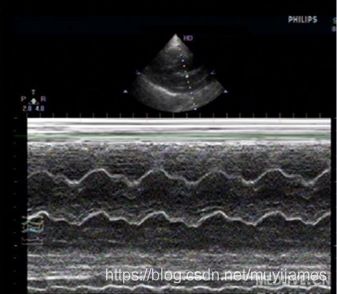
M型超声诊断仪是一种单轴测量距离随着时间变化的曲线,用于心脏检查为单声束超声心动图。它把心脏各层结构的反射信号以点状回声显示在屏幕上。当心脏跳动时,这些点状回声作上下移动。此时,在示波管水平偏转板上加入一对代表时间的慢扫描锯齿波,使这列点状回声沿水平方向缓慢扫描,显示心脏各层的运动回波曲线。图象垂直方向代表人体深度,水平方向代表时间。由于探头位置固定,心脏有规律地收缩和舒张,心脏各层组织和探头间的距离便发生节律改改变。因而,反回的超声信号也同样发生改变。随着水平方向的慢扫描,便把心脏各层组织的回声显示成运动的曲线,即为M型超声心动图。
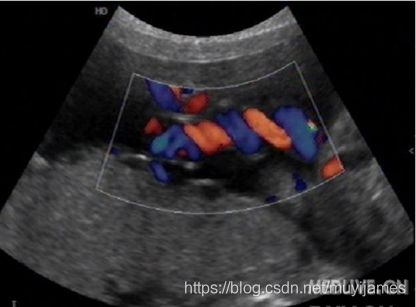
彩色多普勒血流成像(CDFI),又称为彩色血流图(CFM)既大家所说的彩超。系在多普勒二维显像的基础上,以实时彩色编码显示血流的方法,即在显示屏上以不同彩色显示不同的血流方向和流速。彩超仪统一编为近超声探头来的为红色;离开探头的血流为兰色。湍流与分流为多色镶嵌。
D型超声多普勒诊断仪,这类诊断仪是利用多普勒效应原理,对运动的脏器和血流进行检测的仪器。按超声源在时域的工作状态,可以将多普勒系统分为连续波多普勒和脉冲波多普勒。和CDFI不同的是,D型超声多普勒诊断是用血流频谱显示运动的脏器和血流的多普勒频移差异的。
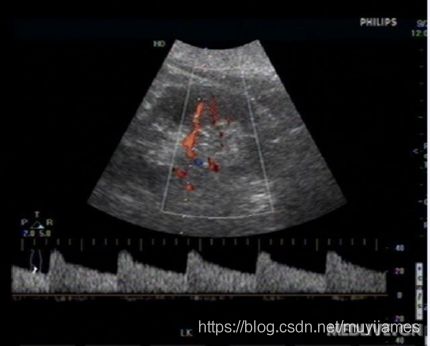
2 超声影像的去噪与增强
不同场景的图像有不同的成像特性,在超声成像过程中,由于人体组织的不均匀特性,叠加的散射回波产生散斑噪声,严重影响超声图像的质量和分辨率,不利于后续提取和分析病灶区中目标的特征。因此有必要对图像进行预处理工作,消除图像中存在的噪声等与图像无关的信息,增强细节等有效信息的可检测性。目前常用的去噪方法有:小波、奇异值分解、傅里叶变换等
2.1 各向异性扩散去噪模型
该方法不仅对超声图像降噪且能够保留细节信息,为后续图像特征提取提供有效信息。 各向异性扩散模型是Malik和Perona 提出并作为图像预处理的工具,主要原理就是以时间t作高斯核G的方差与噪声图像做卷积,以待处理图像I0为媒介,图像以可变速率扩散,得到增强后的平滑图像。热扩散方程如公式所示。
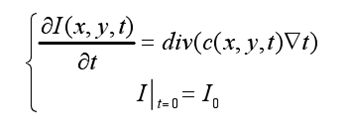
其中I ( x, y, t ) 表示原始图像,变量t表示顺序参数,扩散过程会随着时间演化,即迭代次数,c(x, y, t)、和div分别代表代表扩散系数、梯度算子和散度算子,大小取决于梯度的强度,一般取I ( x, y, t ) = g ( I ( x, y, t ) )。
2.2 色彩恢复的视网膜增强算法SSR和MSR
该方法在彩色图像增强和恢复方面效果不错,可以平衡色彩颜色和边缘增强这两个因素,因此相比其他增强算法,该方法自适应增强不同类型的图像。
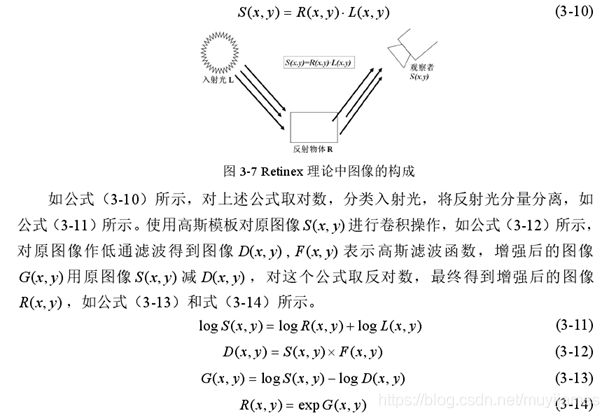

2.3 MSRCR增强算法(基于MSR算法改进版)
该方法首先是利用公式(3-16)计算色度,其中K是光谱通道的数量,通常RGB颜色空间的K为3。对上述公式进行颜色空间的映射,得到公式(3-17),将式中的右半部分变换为公式(3-18),其中( , )iS x y表示第i个通道的图像,Ci调节3个通道颜色的比例,代表第i个通道的彩色恢复因子,f()表示颜色空间的映射函数,β和α分别代表增益常数和受控制的非线性强度,最后得到MSRCR公式,如式(3-19)所示:
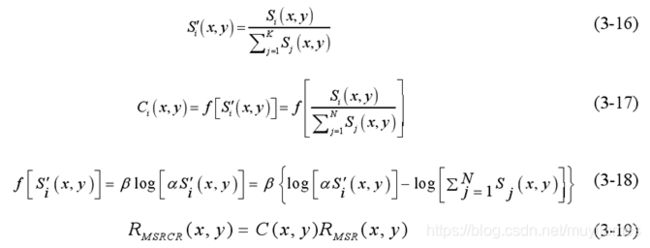
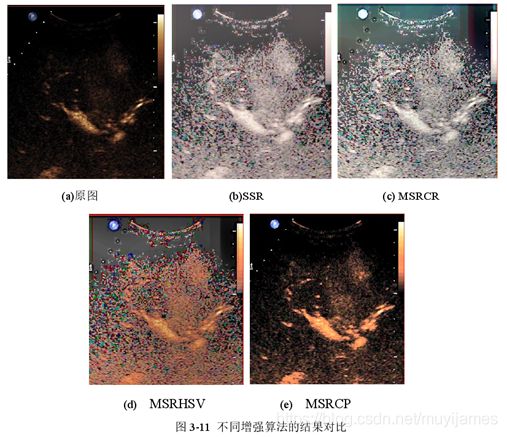
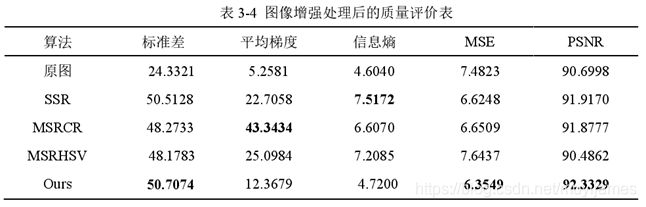
MSRHSV方法:是在MSRCR算法的基础上以HSV颜色通道进行增强;
MSRCP方法:是在MSRCR算法的基础上进行了彩色平衡
2.4 参考文献
【1】付树军, 阮秋琦, 李玉等. 基于各向异性扩散方程的超声图像去噪与边缘增强[J]. 电子学报, 2005, 33(7): 1191-1195
【2】Land EH. Recent Advances in Retinex Theory.[J]. Vision Research, 1986, 26(1):7-21
【3】obson DJ, Rahman Z, Woodell GA. A Multiscale Retinex for Bridging the Gap between Color Images and the Human Observation of Scenes[J]. IEEE Transactions Image Process, 1997, 6(7): 965-76.
3 超声影像的目标识别
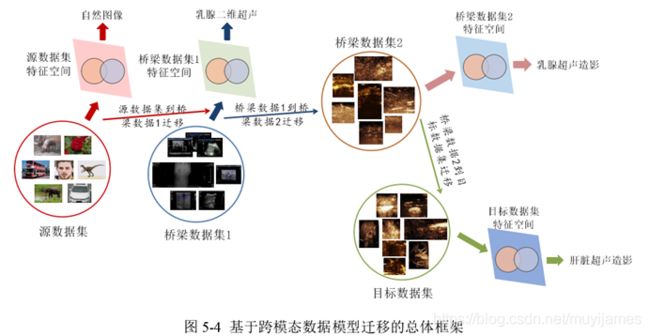
在医学领域已标注的数据集稀缺的情况下,根据超声影像数据与一些自然图像或不同医疗领域的影像数据之间的相关性,使其在有限的超声数据标注的条件下,进行跨影像学、跨模态的数据类型迁移,让从其他领域学习到的知识指导深度。
3.1 基于跨模态数据迁移进行DL训练
通过医学影像不同模态的特征迁移,最后实现超声影像上的特征提取和识别。本文源数据库 xS 为自然图像,跨模态数据 xB 为乳腺超声灰阶图像,目标数据库 xT 为肝脏超声造影图像。为从自然图像 xS 过渡到目标数据集 xT 中,源数据库需包含大量的自然图像,通过预训练,然后从自然图像学到的知识 xS,转移到跨模态数据库 xB,即本文中的乳腺超声灰阶图像数据集。
由于不同器官的疾病和不同模态的医学影像之间可能具有较大的差异性,因此先将乳腺超声灰阶模型迁移到乳腺超声造影数据集上,最后在迁移到肝脏超声造影图像上。
3.2 参考文献
【1】《超声造影病灶区目标跟踪方法的研究》2018硕士论文;
有错误之处请多多指教哈!!