今天不写代码,聊聊热门的知识图谱
哈喽大家好啊,我是恶霸。
前一段时间,boss交给我个任务,让我调研一下知识图谱技术。虽说有点NLP的底子,不过研究起这个来还是满头的包,终于还是在搜集了不少资料后划拉出来50多页的PPT,那么今天就浅浅的给大家分享一下知识图谱的相关知识。
概述
诞生
知识图谱的概念诞生于2012年,由谷歌公司首先提出。大家都知道,谷歌是做搜索引擎的,所以他们最早提出了Google Knowledge Graph后,首先利用知识图谱技术改善了搜索引擎核心。
注意上面的说法,虽然知识图谱诞生于2012年,但其实在更早的时间它还有另外一个名字,那就是语义。那么语义又是什么呢?引用《统计自然语言处理基础》中的两句话来解答这个问题:
语义可以分成两部分,研究单个词的语义(即词义)以及单个词的含义是怎么联合起来组成句子(或者更大的单位)的含义。
语义研究的是词语的含义、结构和说话的方式。
那么,知识图谱究竟是个什么东西呢?
你可以将它理解为是在自然界建立实体关系的知识数据库,它的提出是为了准确地阐述人、事、物之间的关系。
目前在学术界还没有给知识图谱一个统一的定义,但是在谷歌发布的文档中有明确的描述:“知识图谱是一种用图模型来描述知识和建模世界万物之间关联关系的技术方法”。
演进
谷歌的Singhal博士用三个词点出了知识图谱加入之后搜索发生的变化:
“Things,not string.”
这寥寥的几个单词,点出了知识图谱的核心。以前的搜索,都是将要搜索的内容看作字符串,结果是和字符串进行匹配,将匹配程度高的排在前面,后面按照匹配度依次显示。而利用知识图谱之后,将搜索的内容不再看作字符串,而是看作客观世界的事物,也就是一个个的个体。
举个例子,当我们在搜索比尔盖茨的时候,搜索引擎不是搜索“比尔盖茨”这个字符串,而是搜索比尔盖茨这个人,围绕比尔盖茨这个人,展示与他相关的人和事。

在上面的图中,左侧百科会把比尔盖茨的主要情况列举出来,右侧显示比尔盖茨的微软产品和与他类似的人,主要是一些IT行业的创始人。这样,一个搜索结果页面就把和比尔盖茨的基本情况和他的主要关系都列出来了,搜索的人很容易找到自己感兴趣的结果。
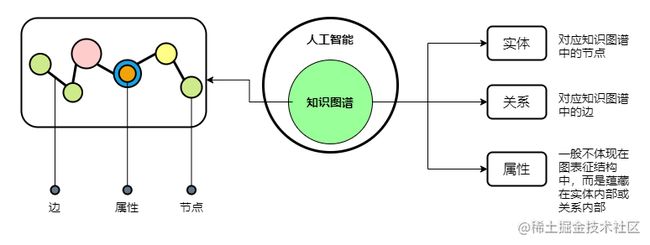
三要素
在知识图谱中,通过三元组 <实体 × 关系 × 属性> 集合的形式来描述事物之间的关系:
- 实体:又叫作本体,指客观存在并可相互区别的事物,可以是具体的人、事、物,也可以是抽象的概念或联系,实体是知识图谱中最基本的元素
- 关系:在知识图谱中,边表示知识图谱中的关系,用来表示不同实体间的某种联系
- 属性:知识图谱中的实体和关系都可以有各自的属性
这里所说的实体和普通意义上的实体略有不同,借用NLP中本体的概念来理解它会比较好:
本体定义了组成主题领域的词汇表的基本术语及其关系,以及结合这些术语和关系来定义词汇表外延的规则。
例如我们要描述大学这一领域时,对它来说教工、学生、课程就是相对比较重要的概念,并且教工和学生之间也存在一定的关联关系,此外对象之间还存在一定的约束关系,例如一个系的教职员工数量不能少于10人。
在了解了上面的三元组后,我们可以基于它构建下面这样的一个关系:

可以看到,女王和王储通过母子关系关联在一起,并且每个人拥有自己的属性。
当知识图谱中的节点逐渐增多后,它的表现形式就会类似于化学分子式的结构,一个知识图谱往往存在多种类型的实体与关系。
知识图谱将非线性世界中的知识信息进行加工,做到这样的结构化、可视化,从而辅助人类进行推理、预判、归类。
到这里,可以简单概括一下知识图谱的基本特征:
- 知识结构网络化
- 网络结构复杂
- 网络由三元组构成
- 数据主要由知识库承载
场景
搜索
前面提到过,以前的搜索引擎是从海量的关键词中找出与查询匹配度最高的内容,按照查询结果把排序分值最高的一些结果返回给用户。在整个过程中,搜索引擎可能并不需要知道用户输入的是什么,因为系统不具备推理能力,在精准搜索方面也略显不足。而基于知识图谱的搜索引擎,除了能够直接回答用户的问题外,还具有一定的语义推理能力,大大提高了搜索的精确度。
推荐
在传统的推荐系统中,存在两个典型问题:
- 数据稀疏问题:在实际应用场景中,用户和物品的交互信息往往是非常稀疏的,预测会产生过拟合风险
- 冷启动问题:对于新加入的用户或者物品,由于系统没有其历史交互信息,因此无法进行准确地建模和推荐
例如,在一个电影类网站中可能包含了上万部电影,然而一个用户打过分的电影可能平均只有几十部。使用如此少量的已观测数据来预测大量的未知信息,会极大地增加算法的过拟合风险。
因此在推荐算法中会额外引入一些辅助信息作为输入,这些辅助信息可以丰富对用户和物品的描述,从而有效地弥补交互信息的稀疏或缺失。在各种辅助信息中,知识图谱作为一种新兴类型的辅助信息,这几年的相关研究比较多。
下面就是一个基于知识图谱的推荐例子:
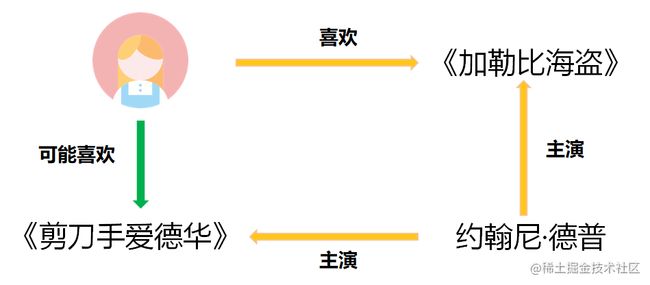
在将知识图谱引入推荐系统后,具有以下优势:
- 精确性:知识图谱为物品引入了更多的语义关系,可以深层次地发现用户兴趣
- 多样性:知识图谱提供了实体之间不同的关系连接种类,有利于推荐结果的发散,避免推荐结果局限于单一类型
- 可解释性:知识图谱可以连接用户的历史记录和推荐结果,从而提高用户对推荐结果的满意度和接受度,增强用户对推荐系统的信
此外,知识图谱技术还在问答与对话系统、语言理解、决策分析等多个领域被广泛应用,它被挂载在这些系统之后,充当背景知识库的角色。总的来说,在这些场景下的应用,可以概括整个AI的发展趋势,就是从感知到认知的一个过程。
架构
知识图谱的构建目前已有一套比较完善的架构体系,可以先来看一下下面这张图,然后我们再慢慢解释:

总的来说,整体过程可以分为下面5步:
- 1.数据获取:主要获取半结构化数据,为后续的实体与实体属性构建做准备。结构化数据则为数值属性做准备
- 2.知识获取:从文本数据集中自动识别出命名实体,包括抽取人名、地名、机构名等;从语料中抽取实体之间的关系,形成关系网络;从不同的信息源中采集特定的属性信息
- 3.知识融合:完成指示代词与先行词的合并;完成同一实体的歧义消除;将已识别的实体对象,无歧义地指向知识库中的目标实体
- 4.知识加工:构建知识概念模块,抽取本体;进行知识图谱推理,并对知识图谱的可信度进行量化评估,评估过关的知识图谱流入知识图谱库中存储,评估不过关的知识图谱返回一开始的数据环节进行调整,而后重复相同环节直到评估过关
- 5.知识存储与计算:存储是为了快速查询与运用知识,需支持底层数据描述与上层计算,有的主体计算包含在存储中
下面,我们拆解其中部分重要核心细节,来具体描述。
知识获取
数据是知识图谱的根基,直接关系到知识图谱构建的效率和质量。所以我们先从数据源进行分析它们的优势与劣势:
- 站内数据:优势在于类别明确,结构化好,易于获取;而劣势在于类型有限,已有数据并不是广义上的知识类型
- 垂直网站数据:优势在于类别明确;而劣势在于获取解析成本高,数据质量参差不齐
- 百科类网站数据:优势在于数据量大,内容丰富;而劣势在于没有分类信息,结构不完全固定
- 人工创建的数据:优势在于类别明确;而劣势在于类别明确
实体抽取
实体抽取,是指从数据中识别和抽取实体的属性与关系信息,这一过程还是针对不同结构的数据来看:
- 结构化数据:包括站内/垂直网站信息、部分百科网站信息,可以利用策略模式,将抽取的具体规则用groovy脚本来实现
- 半结构化数据:包括百科网站中的表格以及列表,可以利用基于监督学习的包装器归纳方法进行抽取
- 非结构化数据:包括百科网站中的文本以及站内文本,可以利用自然语言处理的手段处理
关系抽取
回顾一下我们前面提到过的知识图谱三要素,分别是实体、关系和属性。关系抽取我们同样可以用一个三元组表示的RDF graph:
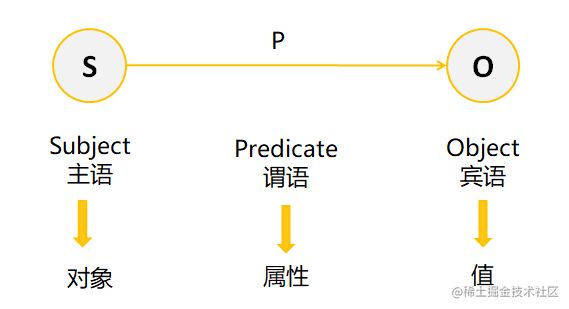
这样的一个(S,P,O)三元组,就可以将一份知识分解为主语、谓语、宾语。这样的SPO结构,在配合知识图谱进行存储时可以被用来当做存储单元。
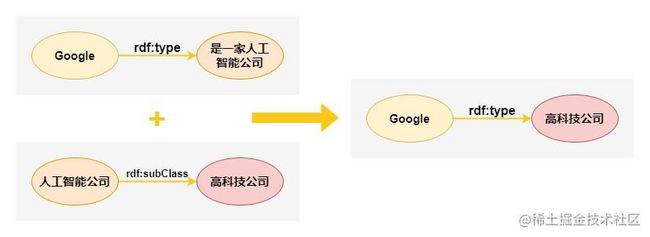
在RDF中可以声明一些规则,从一些关系推导出另一些关系,这些规则被称为RDF Schema。规则可以用一些词汇表示,如class、subClassOf、type、property、subPropertyOf、domain、range等。
下面这个例子中,节点到节点之间的关系就可以理解为前面提到的本体中的联系,而这一关联过程就可以被称为知识图谱中的推导或关联推理:
知识融合
知识融合这一过程中,主要包括指代消解、实体对齐、实体链接等过程,我们主要来看一下这个过程中比较重要的实体对齐(Object Alignment)。
完成实体抽取后,存在实体ID不同但代表真实世界中同一对象的情况。知识融合即是将这些实体合并成一个具有全局唯一标识的实体对象,添加到知识图谱中。
- 首先在索引中根据名字、别名等字段查询出若干个可能是相同实体的候选列表,这个步骤的目的是减少接下来流程的计算量
- 然后经过实体判别模型,根据模型得分识别出待合并对齐的原始实体
- 最后经过属性融合模型,将各原始实体的属性字段进行融合,生成最终的实体。
这一过程可以用下面的图来表示:
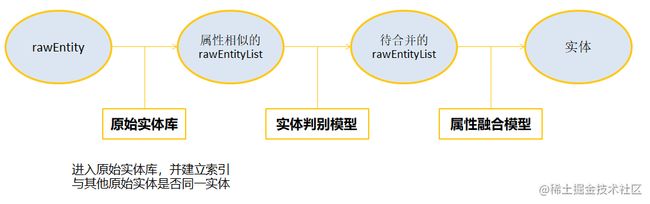
实际上,这个流程中的合并判断模型大家都比较熟悉,它就是通过机器学习训练生成的二分类器。
知识图谱构建与补全
知识图谱普遍存在不完备的问题,在这一步需要做的,就是基于图谱里已有的关系,去推理出缺失的关系。
在下面的这张知识图谱的实体网络中,黄色的箭头表示已经存在的关系,红色的虚线则是缺失的关系。我们可以根据实体之间的关系,来补全缺失的e3到e4之间的关系。

至于这一补全的过程,有很多现成的算法可以使用,例如基于路径查找的方法,基于强化学习的方法,基于推理规则的方法,基于元学习的方法等等。
知识存储
知识图谱的存储依赖于图数据库及其引擎,不同厂商的实现可能大有不同,例如可以选用的图数据库有RDF4j、Virtuoso、Neo4j等。例如爱奇艺的图数据库引擎选择了JanusGraph,借助云平台的Hbase和ES集群,搭建了自己的JanusGraph分布式图数据库引擎。
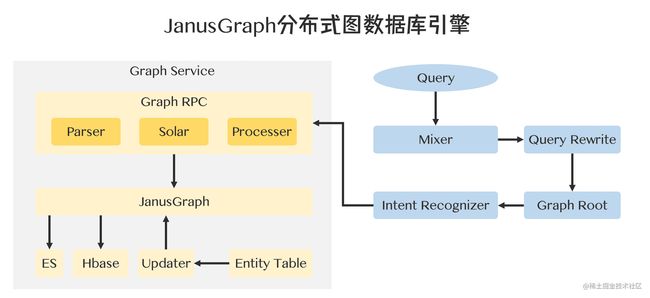
JanusGraph通过借助外部的存储系统与外部索引系统的支持,支撑了上游的在线查询服务。
补充
底层存储数据三元组的逻辑层次可以被称为数据层,通常通过本体库来管理数据层,本体库的概念相当于对象中“类”的概念。而建立在数据层之上的模式层,是知识图谱的核心,它借助本体库来管理公理、规则和约束条件,规范实体、关系、属性这些具体对象间的关系。
从不同的视角去审视知识图谱,可以更方便我们对其进行了解:
- 在Web视角下,知识图谱如同简单文本之间的超链接一样,通过建立数据之间的语义链接,支持语义搜索
- 在自然语言处理视角下,知识图谱就是从文本中抽取语义和结构化的数据
- 在知识表示视角下,知识图谱是采用计算机符号表示和处理知识的方法
- 在人工智能视角下,知识图谱是利用知识库来辅助理解人类语言的工具
- 在数据库视角下,知识图谱是利用图的方式去存储知识的方法
下面,就是一张构建完备后,比较易于我们理解的知识图谱举例:

看到这里,是不是感觉知识图谱的构建过程比较复杂,让我们难于上手?
其实近些年来,深度学习和相关自然语言处理技术的迅猛发展使得非结构化数据的自动知识抽取少人化、乃至无人化成为了可能,现在已经提出了一些前沿的知识图谱自动构建技术。
在深度学习的基础上,艾伦人工智能实验室和微软的研究人员结合自然语言处理领域较为成功的预训练语言模型,提出了自动知识图谱构建模型 COMET(COMmonsEnse Transformers)。
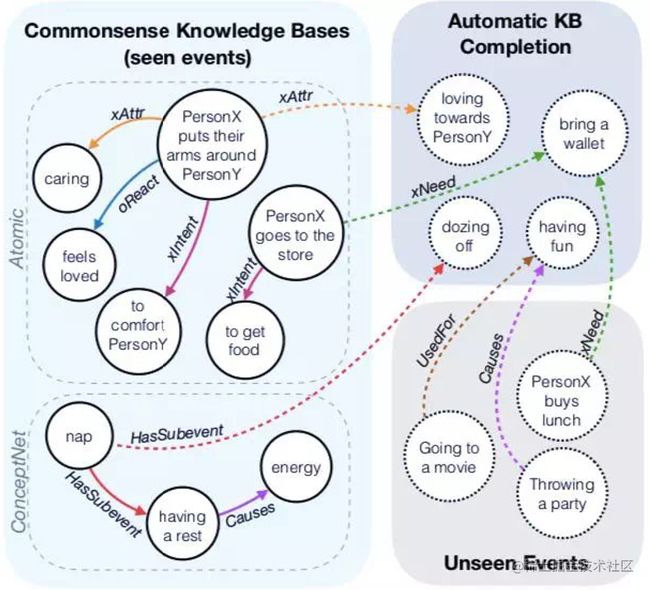
该模型可以根据已有常识库中的自然语言内容自动生成丰富多样的常识描述,在 Atomic 和 ConcepNet 两个经典常识图谱上都取得了接近人类表现的高精度,证明了此类方法在常识知识图谱自动构建和补全方面替代传统方法的可行性。
难点
数据治理困难
数据治理为知识图谱输送数据源,是知识图谱构建的前置环节与基础性工程。完备良好的数据治理不仅能确保知识图谱在搭建过程中获取真实可靠的数据原料,而且能从源头上改善信息质量,提升知识的准确度,建立符合人类认知体系的数据资源池。
但是,数据治理在知识图谱建设卡点中是一个老生常谈的问题。知识图谱应用始终要围绕数据标签、数据清洗、数据归一、数据销毁等数据治理环节展开,应用开发人员往往需要在前期的数据治理工作中投入大量时间和人力,以确保数据源的真实性、可靠性、可用性、正确性。
当前,数据标准不统一、数据噪声大、领域数据集缺失、数据可信度异常等数据治理难题依然困扰着知识图谱研发者,持续进行数据治理工程是业内参与者艰巨的使命与职责。
专家缺乏
目前知识图谱行业整体处于开发资源待完善的局面,行业与技术专家资源稀缺属于其中的一部分情况。
一方面,缺少具备深厚行业经验的专家。由于行业知识图谱与行业的关联度高,开发人员需要迅速了解业务与客户需求,在行业专家的指导下完成Schema构建,若涉及到文本抽取工作还需要行业专家进行数据标注,而各行各业中的行业专家往往仅有极少数。对此,供给方企业需要锁定行业业务的强项领域、提前招募培养行业专家、进行内外协作,以完成行业专家储备。
另一方面,缺少技术复合型专家。整个知识图谱应用生产流程不仅涉及知识图谱算法,生产流程的靠前环节还涉及到底层的图数据存储与数据治理、NLP文本抽取和语义转换,同时各环节都渗透着机器学习这一底层人工智能技术。这意味着整个生产流程需要多个技术领域的工程师协同合作,而对整套技术均有了解的技术专家数量稀缺。
底层存储
由于知识图谱是二维链接的图结构而非行或列的表结构,其需以图数据的形式描述并存储,该方式能直接反应知识图谱的内部结构,有利于知识查询,结合图计算算法进行知识的深度挖掘与推理。
满足这一存储要求的数据库为近几年兴起的图数据库。相比于传统的关系型数据库,图数据库的数据模型以节点和边来体现,可大大缩短关联关系的查询执行时间,支持半结构化数据存储,展示多维度的关联关系。高效便捷的新技术往往意味着更高的研发门槛。
流程与算法
在知识图谱的搭建过程中,仍然面临着各类算法难点,主要难点可归结为生产流程中的算法难点和算法性能上的难点。前者体现为知识获取受数据集限制、知识融合干扰因素较多、知识计算的数据集与算力不足等问题。
而后者体现为算法泛化能力不足、鲁棒性不足、缺乏统一测评指标等问题。算法上的难点有赖于供需双方、学术界、政府持续攻坚,而非一方努力即可收获成功。
最后的碎碎念
拖了好久没有更文,不知道大家有没有想念我~
其实我这里已经存了不少文章的选题了,不过最近工作上实在比较繁忙,下班时间基本上也都在配小肥羊玩,所以没有什么时间更文。就像这篇文章,也是我正在出差的高铁上,根据前几天汇报的PPT整理而成。

怎么样,沿途的风景,是不是还可以?
那么,这次的分享就到这里,我是恶霸,我们下篇再见。