探究语法结构对基于句法距离的语言模型影响
⬆⬆⬆ 点击蓝字
关注我们
AI TIME欢迎每一位AI爱好者的加入!

杜文宇,西湖大学科研助理,导师张岳副教授,目前主要研究方向为自然语言处理中的传统自回归语言模型,以及大规模预训练模型,和对相关模型的语言学分析,共指消解等,已在ACL,AAAI,WWW等发表多篇一作文章。
一、相关背景:
句法信息相关的研究一直是研究热点,一部分学者主要关注在句法解析树的效果提升上,另外一部分学者关注在利用句法信息提升NLP其他任务效果。本文主要是探究语法结构对基于句法距离的语言模型影响。
论文的核心思想核心思想主要有两方面,一方面通过加入基于句法距离的句法结构确实能够提升语言模型的性能,另一方面在模型性能提升的基础上,通过加入有监督信号的句法距离,成功使语言模型生成的结构更符合人的先验,比如语言的右倾性特点。
1.1
研究动机
利用句法信息进行语言建模是20世纪90年代以来的一个热门研究课题。早期的尝试包括各种合并浅层语法信息的方法,如POS标签,以及更完整的句法数结构。随着神经网络方法的兴起,连续的、大规模的神经语言模型已经被证明大大优于传统的语言模型。
早期的工作(tree-structured的递归网络)在语言建模的上下文中结合了句法结构,但是没有解决如何从观测数据中推导结构化信息的问题。另有工作(PRPN)尝试通过解决语言建模任务来执行解析并构建语言模型,并引入了句法距离的概念,但是,使用PRPN模型复杂度较高,实践中难以操作。另有研究方向通过使用具有不同scale的递归模型获取层次结构(Clockwork RNN,ect.),通过在不同的scale上进行更新来分割RNN的隐藏状态。但是这些工作都为hidden的表示施加了预定义的层次结构。
现如今最先进的神经语言模型也不能捕捉文本中较长的句法依赖。因此,研究语言模型和句法之间的关系,以及是否可以将句法结构用来增强语言模型的效果是一个非常有趣的问题。
1.2
研究方法
为此,主要有两种研究思路,即基于转移的方法和基于距离的方法。前一部分工作试图将句法解析任务与语言模型结合。例如,RNNG通过自上而下的神经网络来建模单词和树的联合概率。随后的工作基于期望最大化算法开发了RNNG的无监督变体用作语言模型。第二部分工作设使用句法距离约束句法成分,构建语言模型,其中距离是连续单词之间的scale序列。使用该距离可以很好地契合语言模型的顺序性质,同时可以将句法距离转换为具有简单原理的句法树结构。
作者们提出了一种基于语法距离有监督的建模方法,并且扩充了多任务作为训练目标,这是成功将句法树纳入基于句法距离的语言模型的第一项工作。选择有序神经元LSTM(ON-LSTM)作为我们的基线模型,该模型在基于距离的模型中可提供最佳结果。
二、模型介绍:
首先介绍句法树和句法距离转换的方法,然后介绍前人提出的Ordered Neuron LSTM模型,接着介绍作者们提出的创新模型。
2.1
句法距离和句法树的转换方法:
论文Straight to the Tree: Constituency Parsing with Neural Syntactic Distanc(ACL 2018)提出了一种新的概念叫做“syntactic distance”,以下称作句法距离,本文将其用在了句法分析中。主要思想是这样的:对于一棵二叉树,它的中序遍历的split序列和二叉树是唯一对应的,所以只需要预测这个split序列就行了,而每个split就是用句法距离来表示。
举个例子说明如何将句法树映射到句法距离:He loves watching movies.对应的语法树和距离如下图所示:
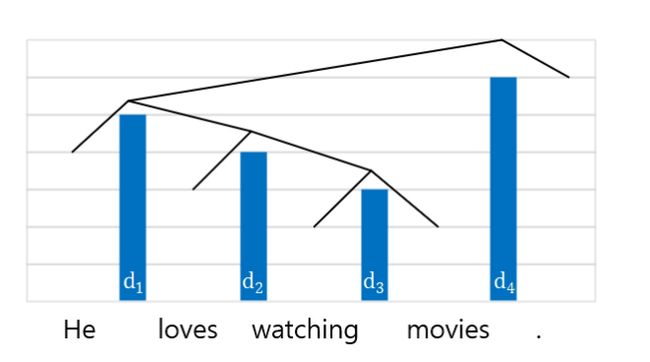
杆的高度表示距离的值, 为了将这棵树转换为句法距离,我们首先为所有单词分配初始值1,然后为非叶节点分配距离d3 - d2 - d1 - d4,另一方面,给定了距离,通过按距离降序设置分割边界,可以在自顶向下的过程中恢复树(d4 - d1 - d2 - d3)。从句法上讲,一对单词之间的距离越短,表示距离两边的成分之间的关系越密切。
按照这个思路,从句法树和句法距离可以按照如下给定的算法转换。给定句法树获得句法距离如下图所示:

给定句法距离转换句法树的方法如下:

2.2
Ordered Neuron LSTM(ON-LSTM)
ON-LSTM 来自文章 Ordered Neurons: Integrating Tree Structures into Recurrent Neural Networks(ICLR 2019 best paper),顾名思义,将神经元经过特定排序是为了将层级结构整合到 LSTM 中去,从而允许 LSTM 能自动学习到层级结构信息。
LSTM 以及普通的神经网络都没有用到神经元的序信息,ON-LSTM 则试图把这些神经元排个序,并且用这个序来表示一些特定的结构,从而把神经元的序信息利用起来。
ON-LSTM 的思考对象是自然语言。一个自然句子通常能表示为一些层级结构,这些结构如果人为地抽象出来,就是我们所说的语法信息,而 ON-LSTM 希望能够模型在训练的过程中自然地学习到这种层级结构,并且训练完成后还能把它解析出来(可视化),这就利用到了前面说的神经元的序信息。
ON-LSTM 是建立在一个普通的LSTM模型上的,多了两个额外的门,是master input gate 和 master forget gate。具体公式如下:
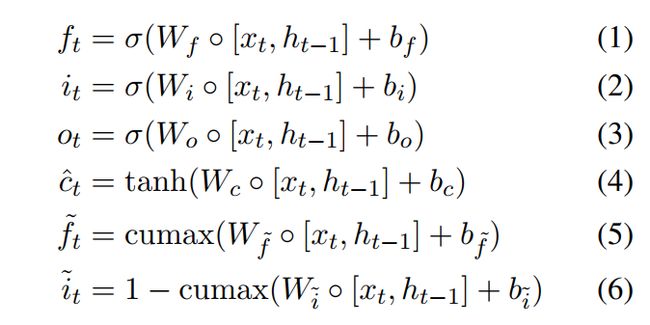
cumax函数通过强制主忘记门![]() 中的单元从0到1单调增加,以及主输入门
中的单元从0到1单调增加,以及主输入门![]() 中的元素从1到0单调减小,提供了归纳偏置来建模层次结构。在原始输入门和遗忘门上应用这两个门如下:
中的元素从1到0单调减小,提供了归纳偏置来建模层次结构。在原始输入门和遗忘门上应用这两个门如下:
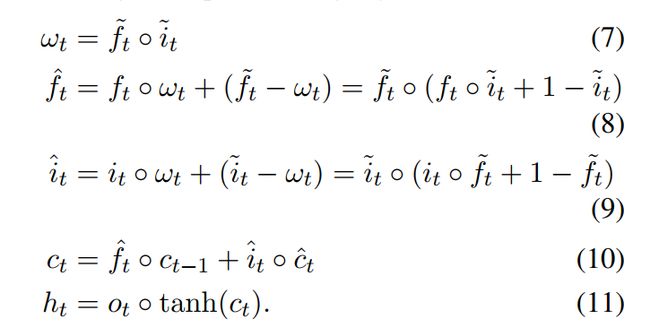
ON-LSTM可以通过句法距离来以无监督的方式学习二叉树形式的语言的隐式结构,其计算公式如下:

2.3
Split-head approach and learning-to-rank loss
本文通过将语法树分解成标签序列,并将基于距离的语言模型扩展到包括一个多任务目标的方法中,将语法树监督损失与语言模型损失结合。多任务架构模型图如下所示:

文章使用附加的主忘记门 ,使得模型具有两组不同的预测。第一组是ONLSTM的语言模型输出,可预测接下来的单词。第二组利用句法距离距离的监督目标。为了对齐句法距离,提出了一种新的loss函数
,使得模型具有两组不同的预测。第一组是ONLSTM的语言模型输出,可预测接下来的单词。第二组利用句法距离距离的监督目标。为了对齐句法距离,提出了一种新的loss函数 。
。
损失函数如下:
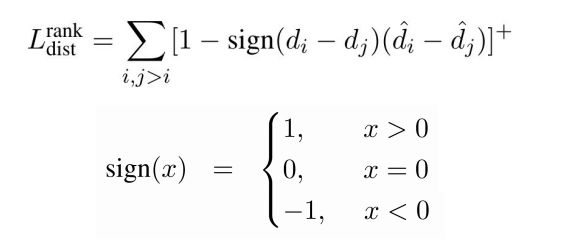
语言模型部分的负对数似然损失表示为![]() ,多任务联合学习损失函数如下:
,多任务联合学习损失函数如下:

三、实验结果
评估了句法监督对基于距离的语言模型的影响,尤其是在语言建模性能方面。进行了消融实验,以了解句法监督如何影响语言模型。
在PTB-Concat的验证和测试集上评估了各种语言模型。作者们提出的模型称为ONLSTM-SYD ,它在训练过程中结合句法树结构。结果如下表所示:

由上表可以看出在将结构信号添加到模型后,模型ONLSTM-SYD的性能显著优于原来的ON-LSTM模型(p-value < 0.05),表明合并带有语言学标记的解析树可以积极促进语言建模。
消融实验如下表所示:
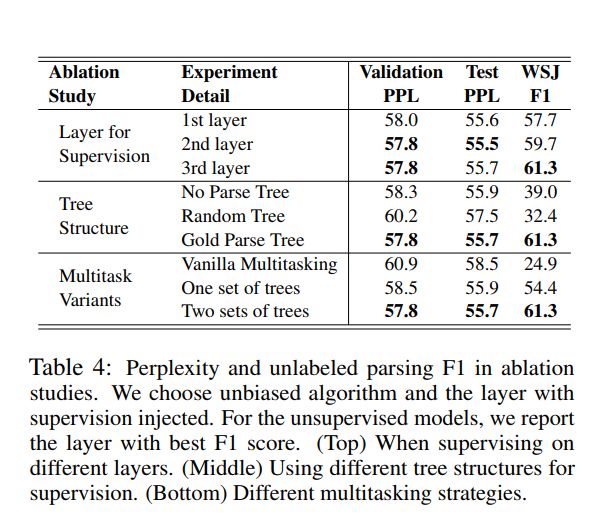
Layer used for supervision:从上表显示了监督信号注入到不同层中的性能。尽管将语法注入最后一层可以提供语法归纳的最佳语法距离的,它无法实现类似的困惑改善。这表明,一个更好的句法结构可能并不总是导致一个更好的语言模型,这一观察结果与先前的研究一致。
Tree structure :研究了不同类型的监督树对模型的影响。除了使用ground truth解析树之外,我们还尝试使用随机树以及不使用树来训练模型,在这种情况下,它会退化为普通的ON-LSTM。从表我们可以发现,如果没有来自ground truth解析树的监督信号,该模型的性能要比整个模型差。随机树给模型引入了噪声,降低了解析和LM性能,这说明了注入有意义语法的重要性。
Multitask variants :我们还探索了在不同级别上注入监督的语法信息。一个直截了当的基准是在ON-LSTM中直接在句法距离上添加监督信号,使用一组树来指导LM和解析。尽管注入了更强的句法信号,但是这种直接方法并不能改善语言模型的困惑。这也反映了这样一个事实,即最适合语言建模的句法结构不一定符合人类标记的语法。另外,我们还使用ON-LSTM隐藏状态进行监督的语法距离预测,由于相同的原因,该方法无法胜过其ON-LSTM基准。总而言之,尽管诱导和监督句法信息不完全重叠,但它们之间有共同的好处。
四、总结
该工作把句法树映射成句法距离,利用句法距离提出一种有监督多任务的方式作用在语言建模中,优化了语言模型,在若干数据集上取得了优秀的效果。对于句法树的距离映射方法,语言模型使用句法信息的方式都是值得思考和研究的课题,语法结构对语言模型的影响也是值得探究的。
整理:李健铨
审稿:杜文宇
AI Time欢迎AI领域学者投稿,期待大家剖析学科历史发展和前沿技术。针对热门话题,我们将邀请专家一起论道。同时,我们也长期招募优质的撰稿人,顶级的平台需要顶级的你,请将简历等信息发至[email protected]!
微信联系:AITIME_HY

AI Time是清华大学计算机系一群关注人工智能发展,并有思想情怀的青年学者们创办的圈子,旨在发扬科学思辨精神,邀请各界人士对人工智能理论、算法、场景、应用的本质问题进行探索,加强思想碰撞,打造一个知识分享的聚集地。

更多资讯请扫码关注
(点击“阅读原文”下载本次报告ppt)
(直播回放:https://b23.tv/nJms4f)