聚类分析(二)k-means及matlab程序
1.介绍
k-means是一种常见的基于划分的聚类算法。划分方法的基本思想是:给定一个有N个元组或者记录的数据集,将数据集依据样本之间的距离进行迭代分裂,划分为K个簇,其中每个簇至少包含一条实验数据。
2.k-means原理分析
2.1工作原理
(1)首先,k-means方法从数据集中随机选择K个数据中心点,每个点代表初始的聚类中心
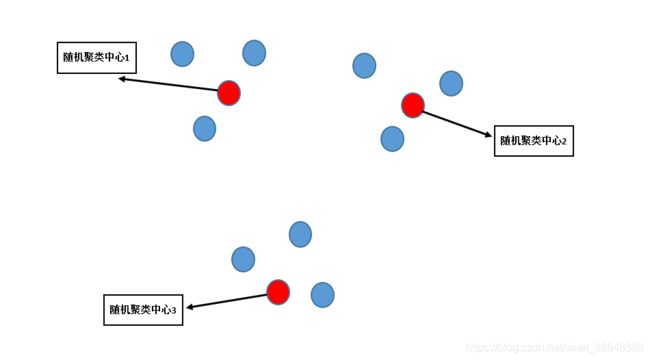
(2)计算剩余各个样本到每个聚类中心的距离,将每个样本距离第i个聚类中心的较近的值赋给聚类中心i

分别计算器距离,容易得出随机聚类中心1离1、2、3最近,随机聚类中心2离4、5、6最近,随机聚类中心3离7、8、9最近
(3)重新计算每个聚类中心的值,对K个聚类中心的每个值进行均值划分,更新K个聚类中心的坐标位置
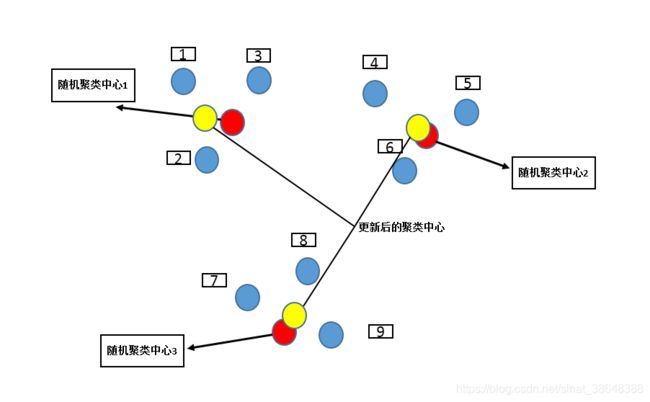
(4)直至K个聚类中心不再变化
示意图:
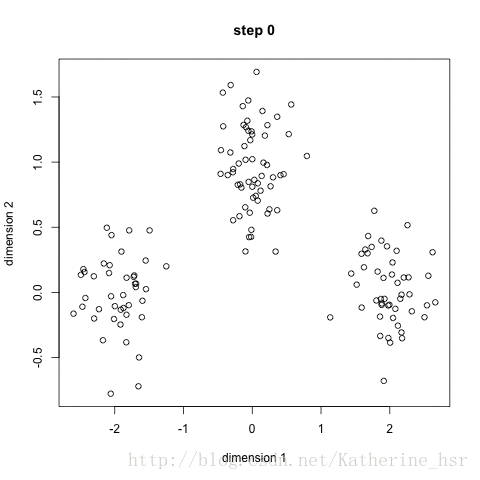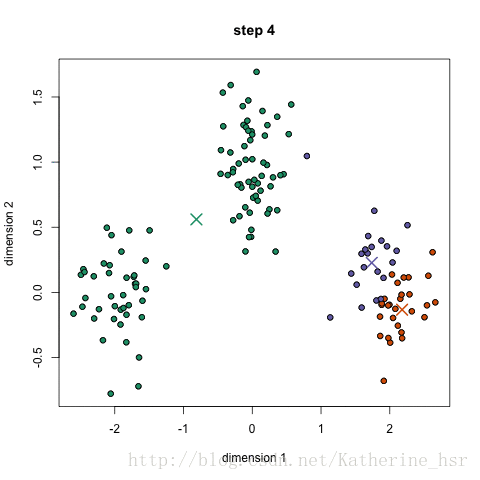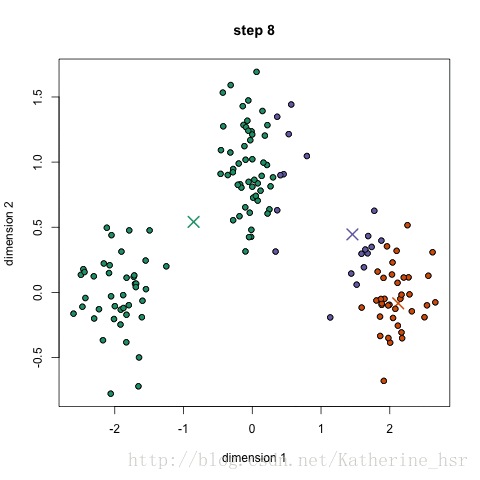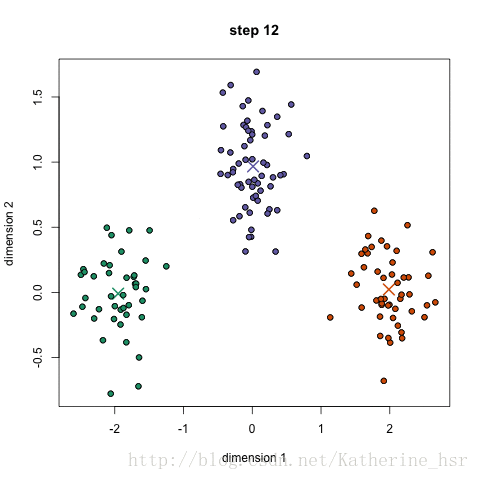
本图转自:https://blog.csdn.net/Katherine_hsr/article/details/79382249
2.2 K-means算法设计
输入:聚类的个数K,数据集,样本距离计算依据
输出:K个聚类
算法处理流程同上工作原理
3.matlab程序 (参考至机器学习周志华第9章)
数据集下载地址:https://download.csdn.net/download/sinat_38648388/10745809
3.1 matlab自主k-means编程
%% K-mens方法的matlab实现
%% 数据准备和初始化
clc
clear
x=[0 0; 1 0; 0 1;1 1;2 1; 1 2; 2 2;3 2;6 6;7 6;8 6;6 7; 7 7;8 7;9 7;7 8;8 8;9 8;8 9;9 9];
z=zeros(2,2);
z1=zeros(2,2);
z=x(1:2,1:2);
%% 寻找聚类中心
while 1
count=zeros(2,1);
allsum=zeros(2,2);
for i=1:20 %对每一个样本i,计算到2个聚类中心的距离
temp1=sqrt((z(1,1)-x(i,1)).^2+(z(1,2)-x(i,2)).^2);
temp2=sqrt((z(2,1)-x(i,1)).^2+(z(2,2)-x(i,2)).^2);
if(temp13.2matlab k-means集成函数编程
matlan中kmeans中的集成函数为kidxs=kmeans(bonds,numClust,‘distance’,dist_k);
其中bonds表示输入的数据集,numClust表示输入的类,distance表示选择样本聚类依据,类型有
: % methods = {‘euclidean’; ‘seuclidean’; ‘cityblock’; ‘chebychev’; …
% ‘mahalanobis’; ‘minkowski’; ‘cosine’; ‘correlation’; …
% ‘spearman’; ‘hamming’; ‘jaccard’};
%% 导入数据与数据预处理
clc,clear all,close all
load BondData
settle=floor(date);
%数据预处理
bondData.MaturityN=datenum(bondData.Maturity,'dd-mmm-yyyy');
bondData.settleN=settle * ones(height(bondData),1);
%筛选数据
corp=bondData(bondData.MaturityN > settle &...
bondData.Type =='Corp' &...
bondData.Rating >= 'CC'&...
bondData.YTM < 30 &...
bondData.YTM >= 0,:);
%设置随机数生成方式保证结果可重现
rng('default');
%% 探索数据
figure
gscatter(corp.Coupon,corp.YTM,corp.Rating)
set(gca,'linewidth',2);
xlabel('票面利率')
ylabel('到期收益率')
%选择聚类变量
corp.RatingNum=double(corp.Rating);
bonds=corp{:,{'Coupon','YTM','CurrentYield','RatingNum'}};
%设置类别数量
numClust=3;
%设置用于可视化聚类效果的变量
VX=[corp.Coupon,double(corp.Rating),corp.YTM];
%% k-means聚类
dist_k='cosine';
kidx=kmeans(bonds,numClust,'distance',dist_k);
%绘制聚类效果图
%z=VX(kidx(m,n));表示VX的第m个值,聚类出来的第n类
figure
%VX(kidx==m,n)代表VX中第m列,第n类
F1=plot3(VX(kidx==1,1),VX(kidx==1,2),VX(kidx==1,3),'r*',...
VX(kidx==2,1),VX(kidx==2,2),VX(kidx==2,3),'bo',...
VX(kidx==3,1),VX(kidx==3,2),VX(kidx==3,3),'kd' );
set(gca,'linewidth',2);
grid on;
set(F1,'linewidth',2,'MarkerSize',8);
xlabel('票面利率','fontsize',12);
ylabel('评级得分','fontsize',12);
zlabel('到期收益率','fontsize',12);
title('Kmeans方法聚类结果')
%% 评估各类的相关程度
dist_metric_k=pdist(bonds,dist_k);
dd_k=squareform(dist_metric_k);
[~,idx]=sort(kidx);
dd_k=dd_k(idx,idx);
figure
imagesc(dd_k)
set(gca,'linewidth',2);
xlabel('数据点','linewidth',2);
ylabel('数据点','fontsize',12);
title('K-means聚类结果相关程度图','fontsize',12)
ylabel(colorbar,['距离矩阵:',dist_k])
axis square