tensorflow 1.X版本 与2.X版本的区别 sparse_categorical_crossentropy损失函数踩雷
卷积神经网络
2.X版本的tensorflow是有Input层的
# Create the Student Model
student = keras.Sequential(
[
keras.Input(shape=(28,28,1)),
layers.Conv2D(16,(3,3),strides = (2,2),padding = "same"),
layers.LeakyReLU(alpha=0.2),
layers.MaxPooling2D(pool_size=(2,2),strides=(1,1),padding="same"),
layers.Conv2D(32,(3,3),strides=(2,2),padding="same"),
layers.Flatten(),
layers.Dense(10),
],
name = "student" # 加这一行可以打印模型结构的时候顺便打印模型名字
)
student.summary() # 打印当前模型的结构
1.X版本则会报错
TypeError: The added layer must be an instance of class Layer. Found: Tensor("input_3:0", shape=(?, 28, 28, 1), dtype=float32)
解决办法:把input放到第一个conv中,input会把变量变成tensor,影响后面的层
from keras import layers
student = keras.Sequential(
[
# keras.Input(shape=(28,28,1)), # 版本问题报错,输入改到conv中
layers.Conv2D(16,(3,3),input_shape=(28,28,1),strides = (2,2),padding = "same"),
layers.LeakyReLU(alpha=0.2),
layers.MaxPooling2D(pool_size=(2,2),strides=(1,1),padding="same"),
layers.Conv2D(32,(3,3),strides=(2,2),padding="same"),
layers.Flatten(),
layers.Dense(10),
],
name = "student"
)
student.summary() # 打印当前模型的结构
编译阶段
2.X版本的tensorflow
teacher.compile(
optimizer = keras.optimizers.Adam(),
loss = keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics = [keras.metrics.SparseCategoricalAccuracy()],
)
# train and evaluation
teacher.fit(x_train,y_train,epochs = 1) #实际情况会训练更多的轮数,如100或更多
teacher.evaluate(x_test,y_test)
在1.X版本中会报错
解决办法:
student.compile(
optimizer = keras.optimizers.Adam(),
loss='sparse_categorical_crossentropy',
metrics=['accuracy']
)
# train and evaluation
student.fit(x_train,y_train,epochs = 3)
student.evaluate(x_test,y_test)
但是注意!!!
如果只是简单的这么更改会使得训练根本无法提升acc:
![]()
可以看到不管训练多少轮acc都没有增加,loss没有下降。
但是用之前的loss = keras.losses.SparseCategoricalCrossentropy(from_logits=True)训练过程中就很正常:
![]()
acc轻轻松松上0.85
究其原因:原来问题出在logit=True这个参数上,logit=True相当于给输出加了一个softmax的输出,将Dense输出的数值映射到[0,1]范围内,如果直接把loss = keras.losses.SparseCategoricalCrossentropy(from_logits=True)替换成了loss='sparse_categorical_crossentropy'则需要收到在模型的Dense层后面加一个softmax激活函数:
from keras import layers
student = keras.Sequential(
[
# keras.Input(shape=(28,28,1)), # 版本问题报错,输入改到conv中
layers.Conv2D(16,(3,3),input_shape=(28,28,1),strides = (2,2),padding = "same"),
layers.LeakyReLU(alpha=0.2),
layers.MaxPooling2D(pool_size=(2,2),strides=(1,1),padding="same"),
layers.Conv2D(32,(3,3),strides=(2,2),padding="same"),
layers.Flatten(),
layers.Dense(10,activation="softmax"),
],
name = "student"
)
student.summary() # 打印当前模型的结构
这样就能正常训练了:
![]()
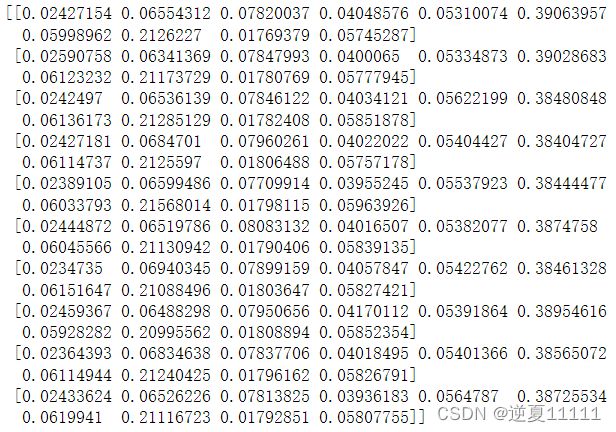
可以打印model的输出看一下,不加activation="softmax"的输出是怎么样的
y_pre = my_model.predict(np.reshape(x_train[:10],(-1,28,28,1))) # 最后dense层未加softmax,得到的是一个非常大范围的值,未映射到[0,1]之间
print(y_pre)

加了softmax之后的输出
y_pre = my_model.predict(np.reshape(x_train[:10],(-1,28,28,1)))
print(y_pre)