
作者 | Apache SeaTunnel(Incubating) Contributor 范佳
整理 | 测试工程师 冯秀兰
对于百亿级批数据的导入,传统的 JDBC 方式在一些海量数据同步场景下的表现并不尽如人意。为了提供更快的写入速度,Apache SeaTunnel(Incubating) 在刚刚发布的 2.1.1 版本中提供了 ClickhouseFile-Connector 的支持,以实现 Bulk load 数据写入。
Bulk load 指把海量数据同步到目标 DB 中,目前 SeaTunnel 已实现数据同步到 ClickHouse 中。
在 Apache SeaTunnel(Incubating) 4 月 Meetup 上,Apache SeaTunnel(Incubating) Contributor 范佳分享了《基于 SeaTunnel 的 ClickHouse bulk load 实现》,详细讲解了 ClickHouseFile 高效处理海量数据的具体实现原理和流程。
感谢本文整理志愿者 测试工程师 冯秀兰 对 Apache SeaTunnel(Incubating) 项目的支持!
本次演讲主要包含七个部分:
- ClickHouse Sink 现状
- ClickHouse Sink 弱场景
- ClickHouseFile 插件介绍
- ClickHouseFile 核心技术点
- ClickHouseFile 插件的实现解析
- 插件能力对比
- 后期优化方向

范 佳白鲸开源 高级工程师
01 ClickHouse Sink 现状
现阶段,SeaTunnel 把数据同步到 ClickHouse 的流程是:只要是 SeaTunnel 支持的数据源,都可以把数据抽取出来,抽取出来之后,经过转换(也可以不转换),直接把源数据写入 ClickHouse sink connector 中,再通过 JDBC 写入到 ClickHouse 的服务器中。
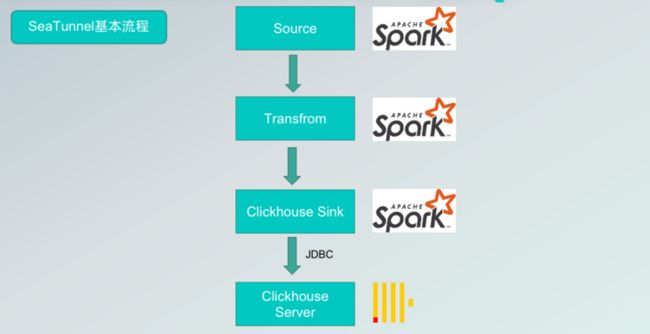
但是,通过传统的 JDBC 写入到 ClickHouse 服务器中会存在一些问题。
首先,现阶段使用的工具是 ClickHouse 提供的驱动,实现方式是通过 HTTP,然而 HTTP 在某些场景下,实现效率不高。其次是海量数据,如果有重复数据或者一次性写入大量数据,使用传统的方式是生成对应的插入语句,通过 HTTP 发送到 ClickHouse 服务器端,在服务器端来进行逐条或分批次解析、执行,无法实现数据压缩。
最后就是我们通常会遇到的问题,数据量过大可能导致 SeaTunnel 端 OOM,或者服务器端因为写入数据量过大,频率过高,导致服务器端挂掉。
于是我们思考,是否有比 HTTP 更快的发送方式?如果可以在 SeaTunnel 端做数据预处理或数据压缩,那么网络带宽压力会降低,传输速率也会提高。
02 ClickHouse Sink 的弱场景
如果使用 HTTP 传输协议,当数据量过大,批处理以微批的形式发送请求,HTTP 可能处理不过来;
太多的 insert 请求,服务器压力大。假设带宽可以承受大量的请求,但服务器端不一定能承载。线上的服务器不仅需要数据插入,更重要的是查询数据为其他业务团队使用。若因为插入数据过多导致服务器集群宕机,是得不偿失的。
03 ClickHouse File 核心技术点
针对这些 ClickHouse 的弱场景,我们想,有没有一种方式,既能在 Spark 端就能完成数据压缩,还可以在数据写入时不增加 Server 的资源负载,并且能快速写入海量数据?于是我们开发了 ClickHouseFile 插件来满足这些需求。
ClickHouseFile 插件的关键技术是 ClickHouse -local。ClickHouse-local 模式可以让用户能够对本地文件执行快速处理,而无需部署和配置 ClickHouse 服务器。ClickHouse-local 使用与 ClickHouse Server 相同的核心,因此它支持大多数功能以及相同的格式和表引擎。
因为有这 2 个特点,这意味着用户可以直接处理本地文件,而无需在 ClickHouse 服务器端做处理。由于是相同的格式,我们在远端或者 SeaTunnel 端进行的操作所产生的数据和服务器端是无缝兼容的,可以使用 ClickHouse local 来进行数据写入。ClickHouse local 是实现 ClickHouseFile 的核心技术点,因为有了这个插件,现阶段才能够实现 ClickHouse file 连接器。
ClickHouse local 核心使用方式:

第一行:将数据通过 Linux 管道传递给 ClickHouse-local 程序的 test_table 表。
第二至五行:创建一个 result_table 表用于接收数据。
第六行:将数据从 test\_table 到 result\_table 表。
第七行:定义数据处理的磁盘路径。
通过调用 Clickhouse-local 组件,实现在 Apache SeaTunnel(Incubating) 端完成数据文件的生成,以及数据压缩等一系列操作。再通过和 Server 进行通信,将生成的数据直接发送到 Clickhouse 的不同节点,再将数据文件提供给节点查询。
原阶段和现阶段实现方式对比:
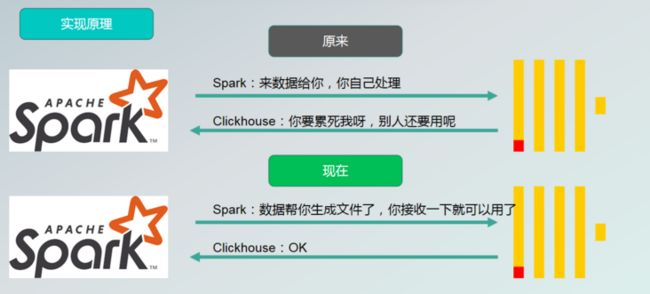
原来是 Spark 把数据包括 insert 语句,发送给服务器端,服务器端做 SQL 的解析,表的数据文件生成、压缩,生成对应的文件、建立对应索引。若使用 ClickHouse local 技术,则由 SeaTunnel 端做数据文件的生成、文件压缩,以及索引的创建,最终产出就是给服务器端使用的文件或文件夹,同步给服务器后,服务器就只需对数据查询,不需要做额外的操作。
04 核心技术点

以上流程可以促使数据同步更加高效,得益于我们对其中的三点优化。
第一,数据实际上师从管道传输到 ClickHouseFile,在长度和内存上会有限制。为此,我们将 ClickHouse connector,也就是 sink 端收到的数据通过 MMAP 技术写入临时文件,再由 ClickHouse local 读取临时文件的数据,生成我们的目标 local file,以达到增量读取数据的效果,解决 OM 的问题。
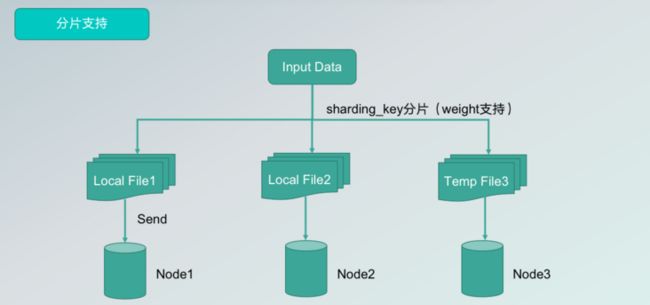
第二,支持分片。因为如果在集群中使用,如果只生成一个文件或文件夹,实际上文件只分发到一个节点上,会大大降低查询的性能。因此,我们进行了分片支持,用户可以在配置文件夹中设置分片的 key,算法会将数据分为多个 log file,写入到不同的集群节点中,大幅提升读取性能。
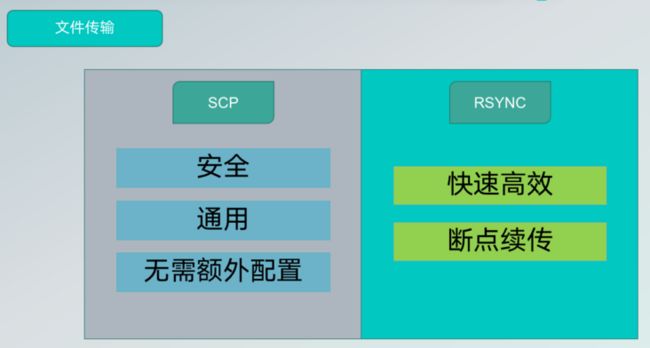
第三个重要的优化是文件传输,目前 SeaTunnel 支持两种文件传输方式,一种是 SCP,其特点是安全、通用、无需额外配置;另一种是 RSYNC,其有点事快速高效,支持断点续传,但需要额外配置,用户可以根据需要选择适合自己的方式。
05 插件实现解析
概括而言,ClickHouseFile 的总体实现流程如下:

- 缓存数据,缓存到 ClickHouse sink 端;
- 调用本地的 ClickHouse-local 生成文件;
- 将数据发送到 ClickHouse 服务端;
- 执行 ATTACH 命令
通过以上四个步骤,生成的数据达到可查询的状态。
06 插件能力对比
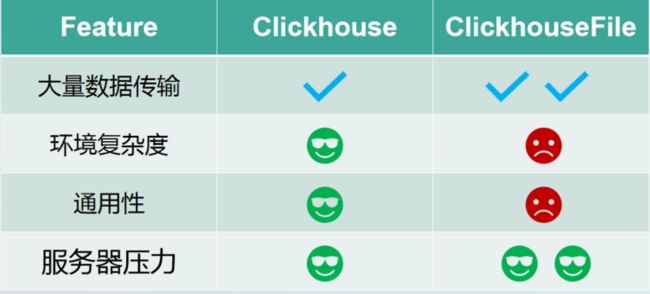
从数据传输角度来说,ClickHouseFile 更适用于海量数据,优势在于不需要额外的配置,通用性强,而 ClickHouseFile 配置比较复杂,目前支持的 engine 较少;
就环境复杂度来说,ClickHouse 更适合环境复杂度高的情况,不需要额外配置就能直接运行;
在通用性上,ClickHouse 由于是 SeaTunnel 官方支持的 JDBC diver,基本上支持所有的 engine 的数据写入,ClickHouseFile 支持的 engine 相对较少;从服务器压力方面来说,ClickHouseFile 的优势在海量数据传输时就体现出来了,不会对服务器造成太大的压力。
但这二者并不是竞争关系,需要根据使用场景来选择。
07 后续计划
目前虽然 SeaTunnel 支持 ClickHouseFile 插件,但是还有很多地方需要优化,主要包括:
- Rsync 支持;
- Exactly-Once 支持;
- 支持 Zero Copy 传输数据文件;
- 更多 Engine 的支持
08 参与贡献
欢迎感兴趣的小伙伴可以参与到这些后续计划的贡献中来,或者提供参考意见,谢谢大家!微信号 : Seatunnel
Apache SeaTunnel(Incubating) 是一个分布式、高性能、易扩展、用于海量数据(离线 &实时)同步和转化的数据集成平台。
仓库地址:https://github.com/apache/incubator-seatunnel
网址:https://seatunnel.apache.org/
Proposal:https://cwiki.apache.org/confluence/display/INCUBATOR/SeaTunnelProposal
Apache SeaTunnel(Incubating) 2.1.0 下载地址:https://seatunnel.apache.org/download衷心欢迎更多人加入!
能够进入 Apache 孵化器,SeaTunnel(原 Waterdrop) 新的路程才刚刚开始,但社区的发展壮大需要更多人的加入。我们相信,在「Community Over Code」(社区大于代码)、「Open and Cooperation」(开放协作)、「Meritocracy」(精英管理)、以及「多样性与共识决策」等 The Apache Way 的指引下,我们将迎来更加多元化和包容的社区生态,共建开源精神带来的技术进步!
我们诚邀各位有志于让本土开源立足全球的伙伴加入 SeaTunnel 贡献者大家庭,一起共建开源!
提交问题和建议:https://github.com/apache/incubator-seatunnel/issues
贡献代码:https://github.com/apache/incubator-seatunnel/pulls
订阅社区开发邮件列表 :[email protected]...
开发邮件列表:[email protected]
加入 Slack:https://join.slack.com/t/apacheseatunnel/shared\_invite/zt-123jmewxe-RjB\_DW3M3gV~xL91pZ0oVQ
关注 Twitter:https://twitter.com/ASFSeaTunnel