她不讲"武德",北航博士竟然把60年来的文本分类综述都整理了!!!
来自:AI算法之心
本文主要总结自然语言处理(NLP)中文本分类任务的资料。内容主要来自文本分类综述论文《A Survey on Text Classification: From Shallow to Deep Learning》
更多查看:https://github.com/xiaoqian19940510/text-classification-surveys
内容目录
综述
深度学习模型
浅层学习模型
数据集
评价指标
未来研究挑战
工具和算法库
综述
A Survey on Text Classification: From Shallow to Deep Learning,2020 by Qian Li, Hao Peng, Jianxin Li, Congying Xia, Renyu Yang, Lichao Sun, Philip S. Yu, Lifang He
深度学习模型
2020年
Spanbert: Improving pre-training by representing and predicting spans --- SpanBERT--- by Mandar Joshi, Danqi Chen, Yinhan Liu, Daniel S. Weld, Luke Zettlemoyer, Omer Levy (Github)
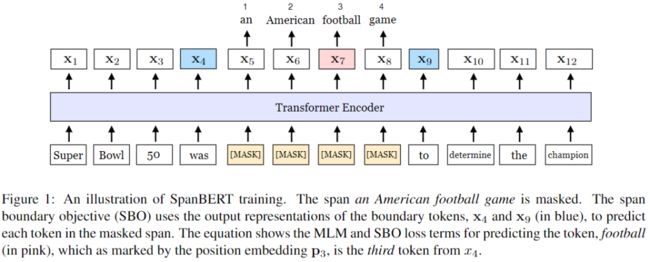
主要贡献:Span Mask机制,不再对随机的单个token添加mask,随机对邻接分词添加mask;Span Boundary Objective(SBO)训练,使用分词边界表示预测被添加mask分词的内容;一个句子的训练效果更好。
本文提出了一种名为SpanBERT的预训练方法,旨在更好地表示和预测文本范围。本文的方法通过在BERT模型上进行了以下改进:(1)在进行掩膜操作(masking)时,对随机的一定范围内的词语进行掩膜覆盖,而不是单个随机的词语。(2)训练掩膜边界表征来预测掩膜覆盖的整个内容,而不依赖于其中的单个词语表示。SpanBERT的表现始终优于BERT和本文优化后的基线方法,并且在范围选择任务(如问题回答和指代消解)上取得了实质性的进展。特别地,在训练数据和模型尺寸与BERT- large相同的情况下,本文的单模型在SQuAD 1.1和2.0上分别取得了94.6%和88.7%地F1分数。此外还达到了OntoNotes指代消解任务(79.6% F1)的最优效果,同时在TACRED关系提取基准测试上的展现了强大的性能,并且在GLUE数据集上也取得了性能提升。
ALBERT: A lite BERT for self-supervised learning of language representations --- ALBERT--- by Zhenzhong Lan, Mingda Chen, Sebastian Goodman, Kevin Gimpel, Piyush Sharma, Radu Soricut (Github)
论文主要贡献:瘦身版BERT,全新的参数共享机制。对embedding因式分解,隐层embedding带有上线文信息;跨层参数共享,全连接和attention层都进行参数共享,效果下降,参数减少,训练时间缩短;句间连贯
在对自然语言表示进行预训练时增加模型大小通常会提高下游任务的性能。然而,在某种程度上由于GPU/TPU的内存限制和训练时间的增长,进一步的提升模型规模变得更加困难。为了解决这些问题,本文提出了两种参数缩减技术来降低内存消耗,并提高BERT的训练速度。全面的实验表明,本文的方法能够让模型在规模可伸缩性方面远优于BERT。本文还使用了一种对句子间连贯性进行建模的自监督损失函数,并证明这种方法对多句子输入的下游任务确实有帮助。本文的最佳模型在GLUE, RACE和SQuAD数据集上取得了新的最佳效果,并且参数量低于BERT-large。代码和预训练模型已经开源到github:https://github.com/google-research/ALBERT.
2019年
Roberta: A robustly optimized BERT pretraining approach --- Roberta--- by Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, Veselin Stoyanov (Github)
主要贡献:更多训练数据、更大batch size、训练时间更长;去掉NSP;训练序列更长;动态调整Masking机制,数据拷贝十份,每句话会有十种不同的mask方式。
语言模型的预训练能带来显著的性能提升,但详细比较不同的预训练方法仍然具有挑战性,这是因为训练的计算开销很大,并且通常是在不同大小的非公开数据集上进行的,此外正如本文将说明的,超参数的选择对最终结果有很大的影响。本文提出了一项针对BERT预训练的复制研究,该研究仔细测试了许多关键超参数和训练集大小对预训练性能的影响。实验发现BERT明显训练不足,并且在经过预训练后可以达到甚至超过其后发布的每个模型的性能。本文最好的模型在GLUE,RACE和SQuAD数据集上达到了SOTA效果。这些结果突出了以前被忽略的设计选择的重要性,并对最近一些其他文献所提出的性能增长提出了质疑。模型和代码已经开源到github。
Xlnet: Generalized autoregressive pretraining for language understanding --- Xlnet--- by Zhilin Yang, Zihang Dai, Yiming Yang, Jaime Carbonell, Russ R. Salakhutdinov, Quoc V. Le (Github)

主要贡献:采用自回归(AR)模型替代自编码(AE)模型,解决mask带来的负面影响;双流自注意力机制;引入transformer-xl,解决超长序列的依赖问题;采用相对位置编码
凭借对双向上下文进行建模的能力,与基于自回归语言模型的预训练方法(GPT)相比,基于像BERT这种去噪自编码的预训练方法能够达到更好的性能。然而,由于依赖于使用掩码(masks)去改变输入,BERT忽略了屏蔽位置之间的依赖性并且受到预训练与微调之间差异的影响。结合这些优缺点,本文提出了XLNet,这是一种通用的自回归预训练方法,其具有以下优势:(1)通过最大化因式分解次序的概率期望来学习双向上下文,(2)由于其自回归公式,克服了BERT的局限性。此外,XLNet将最先进的自回归模型Transformer-XL的创意整合到预训练中。根据经验性测试,XLNet在20个任务上的表现优于BERT,并且往往有大幅度提升,并在18个任务中实现最先进的结果,包括问答,自然语言推理,情感分析和文档排序。
Multi-task deep neural networks for natural language understanding --- MT-DNN--- by Xiaodong Liu, Pengcheng He, Weizhu Chen, Jianfeng Gao (Github)
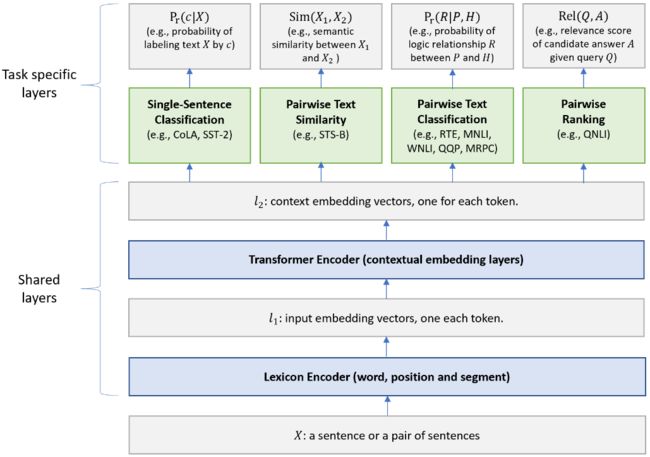
主要贡献:多任务学习机制训练模型,提高模型的泛化性能。
本文提出了一种多任务深度神经网络 (MT-DNN) ,用于跨多种自然语言理解任务(NLU)的学习表示。MT-DNN 不仅利用大量跨任务数据,而且得益于一种正则化效果,这种效果可以帮助产生更通用的表示,从而有助于扩展到新的任务和领域。MT-DNN 扩展引入了一个预先训练的双向转换语言模型BERT。MT-DNN在十个自然语言处理任务上取得了SOTA的成果,包括SNLI、SciTail和九个GLUE任务中的八个,将GLUE的baseline提高到了82.7 % (2.2 %的绝对改进)。在SNLI和Sc-iTail数据集上的实验证明,与预先训练的BERT表示相比,MT-DNN学习到的表示可以在域内标签数据较少的情况下展现更好的领域适应性。代码和预先训练好的模型将进行开源。
BERT: pre-training of deep bidirectional transformers for language understanding --- BERT--- by Jacob Devlin, Ming-Wei Chang, Kenton Lee, Kristina Toutanova (Github)
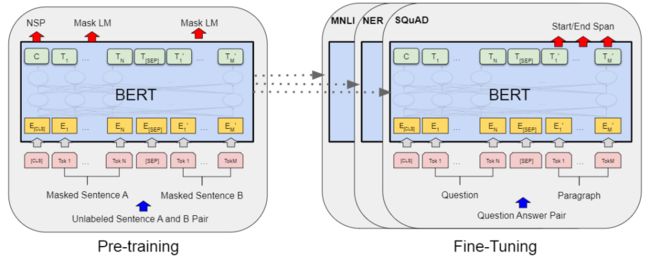
主要贡献:BERT是双向的Transformer block连接,增加词向量模型泛化能力,充分描述字符级、词级、句子级关系特征。真正的双向encoding,Masked LM类似完形填空;transformer做encoder实现上下文相关,而不是bi-LSTM,模型更深,并行性更好;学习句子关系表示,句子级负采样
本文介绍了一种新的语言表示模型BERT,它表示Transformers的双向编码器表示。与最近的语言表示模型不同(Peters et al., 2018; Radford et al., 2018),BERT通过在所有层的上下文联合调节来预训练深层双向表示。因此,只需一个额外的输出层就可以对预先训练好的BERT表示进行微调,以便为各种任务创建最先进的模型,例如问答和语言推断,而无需基本的任务特定架构修改。BERT概念简单,经验丰富。它在11项自然语言处理任务中获得了最新的技术成果,包括将GLUE的基准值提高到80.4%(7.6%的绝对改进)、多项准确率提高到86.7%(5.6%的绝对改进)、将SQuAD v1.1的问答测试F1基准值提高到93.2(1.5的绝对改进),以及将SQuAD v2.0测试的F1基准值提高到83.1(5.1的绝对改进)
Graph convolutional networks for text classification --- TextGCN--- by Liang Yao, Chengsheng Mao, Yuan Luo (Github)

主要贡献:构建基于文本和词的异构图,在GCN上进行半监督文本分类,包含文本节点和词节点,document-word边的权重是TF-IDF,word-word边的权重是PMI,即词的共现频率。
文本分类是自然语言处理中的一个重要而经典的问题。已经有很多研究将卷积神经网络 (规则网格上的卷积,例如序列) 应用于分类。然而,只有个别研究探索了将更灵活的图卷积神经网络(在非网格上卷积,如任意图)应用到该任务上。在这项工作中,本文提出使用图卷积网络(GCN)来进行文本分类。基于词的共现关系和文档词的关系,本文为整个语料库构建单个文本图,然后学习用于语料库的文本图卷积网络(text GCN)。本文的text-GCN首先对词语和文本使用one-hot编码进行初始化,然后在已知文档类标签的监督下联合学习单词和文本的嵌入(通过GCN网络传播)。我们的模型在多个基准数据集上的实验结果表明,一个没有任何外部词或知识嵌入的普通text-GCN在性能上优于最先进的文本分类方法。另一方面,Text -GCN也学习词的预测和文档嵌入。实验结果表明,当降低训练数据的百分比时,文本GCN相对于现有比较方法的改进更加显著,说明在文本分类中,文本GCN对较少的训练数据具有鲁棒性。
2018年
Multi-grained attention network for aspect-level sentiment classification --- MGAN --- by Feifan Fan, Yansong Feng, Dongyan Zhao (Github)
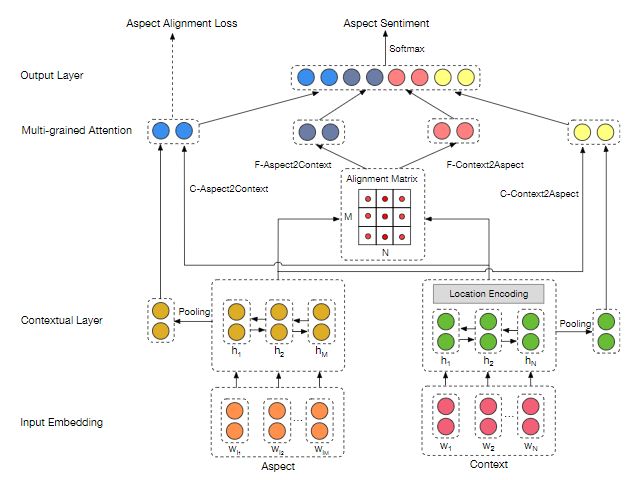
主要贡献:多粒度注意力网络,结合粗粒度和细粒度注意力来捕捉aspect和上下文在词级别上的交互;aspect对齐损失来描述拥有共同上下文的aspect之间的aspect级别上的相互影响。\ 本文提出了一种新颖的多粒度注意力网络模型,用于方面级(aspect-level)情感分类。现有的方法多采用粗粒度注意机制,如果有多个词或较大的上下文,可能会造成信息丢失。因此作者提出了一种精细的注意力机制,可以捕捉到方面和上下文之间的字级交互。然后利用细粒度和粗粒度的注意机制来组成MGAN框架。此外,与之前用上下文分别训练每个方面的工作不同,作者设计了一个方面级对齐损失来描述具有相同上下文的方面之间的方面级交互。作者在三个数据集上评估提出的方法:SemEval 2014包含笔记本销售评价和餐厅评价,以及 twitter数据集。实验结果表明,在这三个数据集上,多粒度注意力网络的性能始终优于现有的方法。本文还进行了实验来评估方面对齐丢失的有效性,表明方面级交互可以带来额外的有用信息,并进一步提高性能。
Investigating capsule networks with dynamic routing for text classification --- TextCapsule --- by Min Yang, Wei Zhao, Jianbo Ye, Zeyang Lei, Zhou Zhao, Soufei Zhang (Github)
在这项研究中,本文探索了用于文本分类,具有动态路由的胶囊网络。本文提出了三种策略来稳定动态路由的过程,以减轻某些可能包含“背景”信息,或尚未成功训练的噪声胶囊的影响。作者在六个文本分类基准数据集上对胶囊网络进行了一系列实验。胶囊网络在6个数据集中的4个上达到了SOTA效果,这表明了胶囊网络在文本分类任务中的有效性。本文还展示了当通过强基线方法将单标签文本分类转换为多标签文本分类时,胶囊网络表现出显着的性能提升。据作者所知,这项工作是第一次经过经验研究将胶囊网络用于文本建模任务。
Constructing narrative event evolutionary graph for script event prediction --- SGNN --- by Zhongyang Li, Xiao Ding, Ting Liu (Github)

脚本事件预测需要模型在已知现有事件的上下文信息的情况下,预测对应的上下文事件。以往的模型主要基于事件对或事件链,这种模式无法充分利用事件之间的密集连接,在某种程度上这会限制模型对事件的预测能力。为了解决这个问题,本文提出构造一个事件图来更好地利用事件网络信息进行脚本事件预测。特别是,首先从大量新闻语料库中提取叙事事件链,然后根据提取的事件链来构建一个叙事事件进化图(narrative event evolutionary graph ,NEEG)。NEEG可以看作是描述事件进化原理和模式的知识库。为了解决NEEG上的推理问题,本文提出了可放缩图神经网络(SGNN)来对事件之间的交互进行建模,并更好地学习事件的潜在表示。SGNN每次都只处理相关的节点,而不是在整个图的基础上计算特征信息,这使本文提出的模型能在大规模图上进行计算。通过比较输入上下文事件的特征表示与候选事件特征表示之间的相似性,模型可以选择最合理的后续事件。在广泛使用的《纽约时报》语料库上的实验结果表明,通过使用标准的多选叙述性完形填空评估,本文的模型明显优于最新的基准方法。
SGM: sequence generation model for multi-label classification --- SGM --- by Pengcheng Yang, Xu Sun, Wei Li, Shuming Ma, Wei Wu, Houfeng Wang (Github)
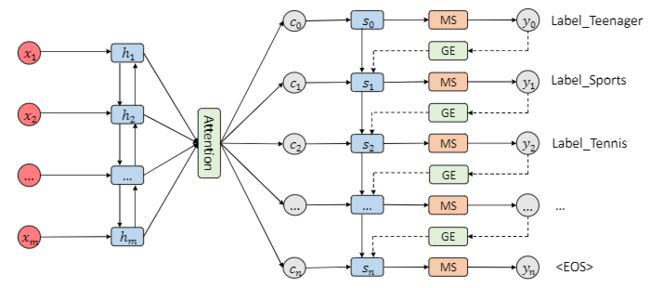
多标签分类是NLP任务中一项重要而又具有挑战性的任务。相较于单标签分类,由于多个标签之间趋于相关,因而更加复杂。现有方法倾向于忽略标签之间的相关性。此外,文本的不同部分对于预测不同的标签可能有不同的贡献,然而现有模型并未考虑这一点。在本文中,作者提出将多标签分类任务视为序列生成问题,并用具有新颖解码器结构的序列生成模型来解决该问题。大量的实验结果表明,本文提出的方法在很大程度上优于以前的工作。对实验结果的进一步分析表明,本文的方法不仅可以捕获标签之间的相关性,而且可以在预测不同标签时自动选择具有最多信息的单词。
Joint embedding of words and labelsfor text classification --- LEAM --- by Guoyin Wang, Chunyuan Li, Wenlin Wang, Yizhe Zhang, Dinghan Shen, Xinyuan Zhang, Ricardo Henao, Lawrence Carin (Github)

在对文本序列进行表征学习时,单词嵌入是捕获单词之间语义规律的有效中间表示。在本文中,作者提出将文本分类视为标签与单词的联合嵌入问题:每个标签与单词向量一起嵌入同一向量空间。本文引入了一个注意力框架,该框架可测量文本序列和标签之间嵌入的兼容性。该注意力框架在带有标签标记的数据集上进行训练,以确保在给定文本序列的情况下,相关单词的权重高于不相关单词的权重。本文的方法保持了单词嵌入的可解释性,并且还具有内置的能力来利用替代信息源,来作为输入文本序列信息的补充。在几个大型文本数据集上的大量实验结果表明,本文所提出的框架在准确性和速度上都大大优于目前的SOTA方法。
Universal language model fine-tuning for text classification --- ULMFiT --- by Jeremy Howard, Sebastian Ruder (Github)
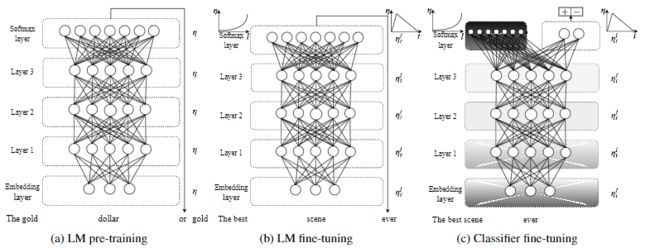
归纳迁移学习在CV领域大放异彩,但并未广泛应用于NLP领域,NLP领域的现有方法仍然需要针对特定任务进行模型修改并从头开始训练。因此本文提出了通用语言模型微调(Universal Language Model Fine-tuning ,ULMFiT),一种可以应用于NLP中任何任务的高效率迁移学习方法,并介绍了对语言模型进行微调的关键技术。本文的方法在六个文本分类任务上的性能明显优于SOTA技术,在大多数数据集上的错误率降低了18-24%。此外,在只有100个带标签样本的情况下,本文的方法能于在100倍数据上从头训练的性能相匹配。相关的预先训练的模型和代码已开源。
Large-scale hierarchical text classification withrecursively regularized deep graph-cnn --- DGCNN --- by Hao Peng, Jianxin Li, Yu He, Yaopeng Liu, Mengjiao Bao, Lihong Wang, Yangqiu Song, Qiang Yang (Github)
将文本分类按主题进行层次分类是一个常见且实际的问题。传统方法仅使用单词袋(bag-of-words)并取得了良好的效果。但是,当有许多具有不同的主题粒度标签时,词袋的表征能力可能不足。鉴于深度学习模型已被证明可以有效地自动学习图像数据的不同表示形式,因此值得研究哪种方法是文本表征学习的最佳方法。在本文中,作者提出了一种基于graph-CNN的深度学习模型,该模型首先将文本转换为单词图,然后使用图卷积运算对词图进行卷积。将文本表示为图具有捕获非连续和长距离语义信息的优势。CNN模型的优势在于可以学习不同级别的语义信息。为了进一步利用标签的层次结构,本文使用标签之间的依赖性来对深度网络结构进行正则化。在RCV1和NYTimes数据集上的结果表明,与传统的分层文本分类和现有的深度模型相比,本文的方法在大规模的分层文本分类任务上有显著提升。
Deep contextualized word rep-resentations --- ELMo --- by Matthew Peters, Mark Neumann, Mohit Iyyer, Matt Gardner, Christopher Clark, Kenton Lee, Luke Zettlemoyer (Github)
本文介绍了一种新型的深层上下文词表示形式,该模型既可以对以下信息进行建模(1)单词使用方法的复杂特征(例如语法和语义) (2)这些用法在语言上下文之间的变化方式(即建模多义性)。本文的词向量是深度双向语言模型(biLM)内部状态的学习函数,双向语言模型已在大型文本语料库上进行了预训练。实验证明了可以很容易地将这些表示形式添加到现有模型中,并在六个具有挑战性的NLP问题上(包括问题回答,文本蕴含和情感分析)显著改善目前的SOTA。本文还进行了一项分析,该分析表明探索预训练网络的深层内部信息至关重要,这有助于下游模型混合不同类型的半监督信号。
2017年
Recurrent Attention Network on Memory for Aspect Sentiment Analysis --- RAM --- by Peng Chen, Zhongqian Sun, Lidong Bing, Wei Yang (Github)

本文提出了一种基于神经网络的新框架,以识别评论中意见目标的情绪。本文的框架采用多注意机制来捕获相距较远的情感特征,因此对于不相关的信息鲁棒性更高。多重注意力的结果与循环神经网络(RNN)进行非线性组合,从而增强了模型在处理更多并发情况时的表达能力。加权内存机制不仅避免了工作量大的特征工程工作,而且还为句子的不同意见目标提供了对应的记忆特征。在四个数据集上的实验验证了模型的优点:两个来自SemEval2014,该数据集包含了例如餐馆和笔记本电脑的评论信息; 一个Twitter数据集,用于测试其在社交媒体数据上的效果;以及一个中文新闻评论数据集,用于测试其语言敏感性。实验结果表明,本文的模型在不同类型的数据上始终优于SOTA方法。
Using millions of emoji occurrences to learn any-domain representations for detecting sentiment, emotion and sarcasm --- DeepMoji --- by Bjarke Felbo, Alan Mislove, Anders Søgaard, Iyad Rahwan, Sune Lehmann (Github)

NLP任务通常受到缺乏人工标注数据的限制。因此,在社交媒体情绪分析和相关任务中,研究人员已使用二值化表情符号和特定的主题标签作为远程监督的形式。本文的研究表明,通过将远程监督扩展到更多种类的嘈杂标签,可以让模型学习到更丰富的特征表示。通过对包含64种常见表情符号之一的12.46亿条推文数据集进行表情符号预测,可以使用单个预训练模型在情绪,情感和嘲讽检测的8个基准数据集上获得最优效果。本文的分析进一步证明,与以前的远程监督方法相比,情感标签的多样性可以显著提高模型效果。
Interactive attention networks for aspect-level sentiment classification --- IAN --- by Dehong Ma, Sujian Li, Xiaodong Zhang, Houfeng Wang (Github)
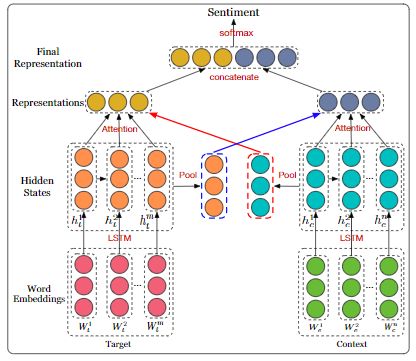
方面级别(aspect-level)的情感分类旨在识别特定目标在其上下文中的情感极性。先前的方法已经意识到情感目标在情感分类中的重要性,并开发了各种方法,目的是通过生成特定于目标的表示来对上下文进行精确建模。但是,这些研究始终忽略了目标的单独建模。在本文中,作者认为目标和上下文都应受到特殊对待,需要通过交互式学习来学习它们自己的特征表示。因此,作者提出了交互式注意力网络(interactive attention networks , IAN),以交互方式学习上下文和目标中的注意力信息,并分别生成目标和上下文的特征表示。通过这种设计,IAN模型可以很好地表示目标及其搭配上下文,这有助于情感分类。在SemEval 2014数据集上的实验结果证明了本文模型的有效性。
Deep pyramid convolutional neural networks for text categorization --- DPCNN --- by Rie Johnson, Tong Zhang (Github)
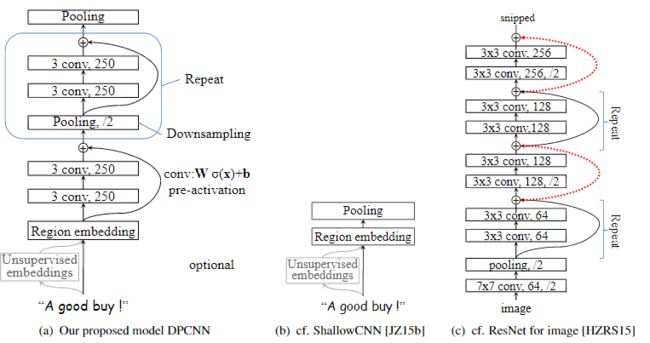
本文提出了一种用于文本分类的低复杂度的词语级深度卷积神经网络(CNN)架构,该架构可以有效地对文本中的远程关联进行建模。在以往的研究中,已经有多种复杂的深度神经网络已经被用于该任务,当然前提是可获得相对大量的训练数据。然而随着网络的深入,相关的计算复杂性也会增加,这对网络的实际应用提出了严峻的挑战。此外,最近的研究表明,即使在设置大量训练数据的情况下,较浅的单词级CNN也比诸如字符级CNN之类的深度网络更准确,且速度更快。受这些发现的启发,本文仔细研究了单词级CNN的深度化以捕获文本的整体表示,并找到了一种简单的网络体系结构,在该体系结构下,可以通过增加网络深度来获得最佳精度,且不会大量增加计算成本。相应的模型被称为深度金字塔CNN(pyramid-CNN)。在情感分类和主题分类任务的六个基准数据集上,本文提出的具有15个权重层的模型优于先前的SOTA模型。
Topicrnn: A recurrent neural network with long-range semantic dependency --- TopicRNN --- by Adji B. Dieng, Chong Wang, Jianfeng Gao, John Paisley (Github)
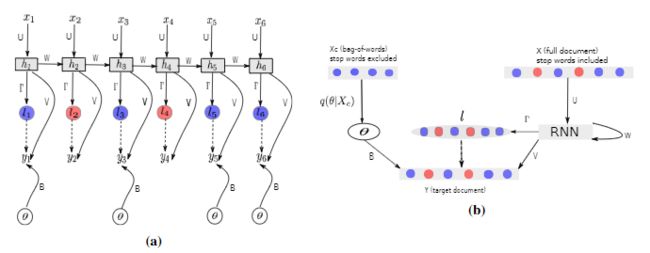
本文提出了TopicRNN,这是一个基于循环神经网络(RNN)的语言模型,旨在通过潜在主题直接捕获文档中与单词相关的全局语义。由于RNN的顺序结构特点,其擅长捕获单词序列的局部结构(包括语义和句法),但可能难以记住长期依赖关系。直观上,这些远程依赖关系具有语义性质。相反,潜在主题模型(latent topic models)能够捕获文档的全局基础语义结构,但不考虑单词顺序。因此本文提出的TopicRNN模型整合了RNN和潜在主题模型的优点:它使用RNN捕获局部(语法)依赖关系,并使用潜在主题捕获全局(语义)依赖关系。与先前基于上下文RNN的语言建模工作不同,本文的模型是端到端模型。单词预测的经验性结果表明,TopicRNN优于现有的上下文RNN基线。此外,TopicRNN可以用作文档的无监督特征提取器。本文以情感分析任务为例在IMDB电影评论数据集上测试,错误率为6.28%,这可与半监督方法产生的最优效果5.91%相媲美。最后,TopicRNN还提出了有探索意义的主题,使其成为诸如潜在Dirichlet分配之类的文档模型的有用替代方法。
Adversarial training methods for semi-supervised text classification --- Miyato et al. --- by Takeru Miyato, Andrew M. Dai, Ian Goodfellow (Github)

对抗训练提供了一种对有监督学习算法进行正则化的方法,而虚拟对抗训练能够将监督学习算法扩展到半监督条件下。但是,这两种方法都需要对输入向量的众多条目进行较小的扰动,这对于稀疏的高维输入(例如:独一热单词编码)是不合适的。通过对循环神经网络中的单词嵌入(而不是原始输入本身)进行扰动,本文将对抗性和虚拟对抗性训练扩展到文本域。本文所提出的方法在多个基准半监督任务和纯监督任务上均达到了SOTA效果。可视化和分析结果表明,学习的单词嵌入的质量有所提高,并且在模型在训练过程中更加不容易过拟合。
Bag of tricks for efficient text classification --- FastText --- by Armand Joulin, Edouard Grave, Piotr Bojanowski, Tomas Mikolov (Github)

本文探讨了一种简单有效的文本分类基准。实验表明,本文的快速文本分类器fastText在准确性方面可以与深度学习分类器相提并论,而训练和预测速度要快多个数量级。可以使用标准的多核CPU在不到十分钟的时间内在超过十亿个单词的数据集上训练fastText,并在一分钟之内对属于312K个类别的50万个句子进行分类。
2016年
Long short-term memory-networks for machine reading --- LSTMN --- by Jianpeng Cheng, Li Dong, Mirella Lapata (Github)
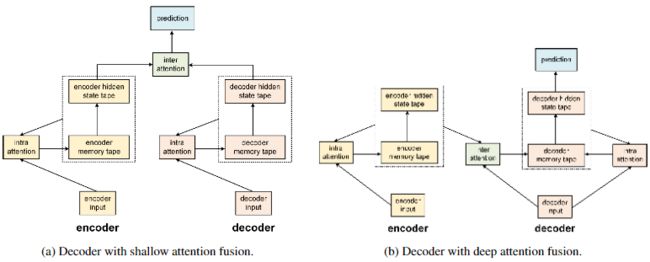
在本文中,作者解决了如何在处理结构化输入时更好地呈现序列网络的问题。本文提出了一种机器阅读模拟器,该模拟器可以从左到右递增地处理文本,并通过记忆和注意力进行浅层推理。阅读器使用存储网络代替单个存储单元来对LSTM结构进行扩展。这可以在神经注意力循环计算时启用自适应内存使用,从而提供一种弱化token之间关系的方法。该系统最初设计为处理单个序列,但本文还将演示如何将其与编码器-解码器体系结构集成。在语言建模,情感分析和自然语言推理任务上的实验表明,本文的模型与SOTA相媲美,甚至优于目前的SOTA。
Recurrent neural network for text classification with multi-task learning --- Multi-Task --- by Pengfei Liu, Xipeng Qiu, Xuanjing Huang (Github)
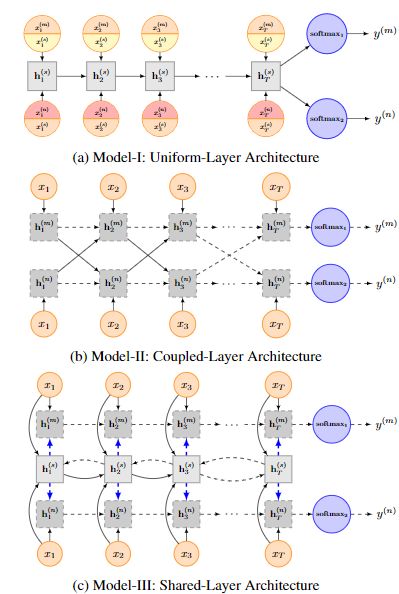
基于神经网络的方法已经在各种自然语言处理任务上取得了长足的进步。然而在以往的大多数工作中,都是基于有监督的单任务目标进行模型训练,而这些目标通常会受训练数据不足的困扰。在本文中,作者使用多任务学习框架来共同学习多个相关任务(相对于多个任务的训练数据可以共享)。本文提出了三种不同的基于递归神经网络的信息共享机制,以针对特定任务和共享层对文本进行建模。整个网络在这些任务上进行联合训练。在四个基准文本分类任务的实验表明,模型在某一任务下的性能可以在其他任务的帮助下得到提升。
Hierarchical attention networks for document classification --- HAN --- by Zichao Yang, Diyi Yang, Chris Dyer, Xiaodong He, Alex Smola, Eduard Hovy (Github)

本文提出了一种用于文档分类的层次注意力网络。该模型具有两个鲜明的特征:(1)具有分层模型结构,能反应对应层次的文档结构;(2)它在单词和句子级别上应用了两个级别的注意机制,使它在构建文档表征时可以有区别地对待或多或少的重要内容。在六个大型文本分类任务上进行的实验表明,本文所提出的分层体系结构在很大程度上优于先前的方法。此外,注意力层的可视化说明该模型定性地选择了富有主要信息的词和句子。
2015年
Character-level convolutional networks for text classification --- CharCNN --- by Xiang Zhang, Junbo Zhao, Yann LeCun (Github)
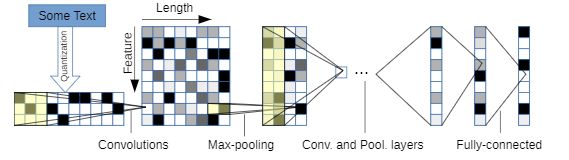
本文提出了通过字符级卷积网络(ConvNets)进行文本分类的实证研究。本文构建了几个大型数据集,以证明字符级卷积网络可以达到SOTA结果或者得到具有竞争力的结果。可以与传统模型(例如bag of words,n-grams 及其 TFIDF变体)以及深度学习模型(例如基于单词的ConvNets和RNN)进行比较。
Improved semantic representations from tree-structured long short-term memory networks --- Tree-LSTM --- by Kai Sheng Tai, Richard Socher, Christopher D. Manning (Github)
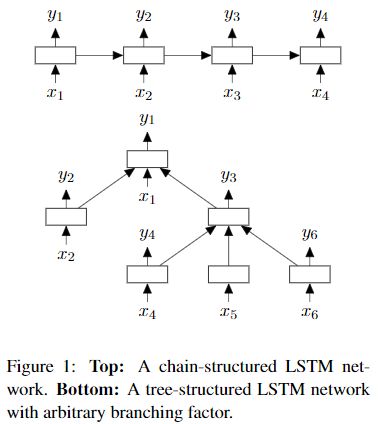
由于具有较强的序列长期依赖保存能力,具有更复杂的计算单元的长短时记忆网络(LSTM)在各种序列建模任务上都取得了出色的结果。然而,现有研究探索过的唯一底层LSTM结构是线性链。由于自然语言具有句法属性, 因此可以自然地将单词与短语结合起来。本文提出了Tree-LSTM,它是LSTM在树形拓扑网络结构上的扩展。Tree-LSTM在下面两个任务上的表现优于所有现有模型以及强大的LSTM基准方法:预测两个句子的语义相关性(SemEval 2014,任务1)和情感分类(Stanford情感树库)。
Deep unordered composition rivals syntactic methods for text classification --- DAN --- by Mohit Iyyer, Varun Manjunatha, Jordan Boyd-Graber, Hal Daumé III (Github)

现有的许多用于自然语言处理任务的深度学习模型都专注于学习不同输入的语义合成性, 然而这需要许多昂贵的计算。本文提出了一个简单的深度神经网络,它在情感分析和事实类问题解答任务上可以媲美,并且在某些情况下甚至胜过此类模型,并且只需要少部分训练事件。尽管本文的模型对语法并不敏感, 但通过加深网络并使用一种新型的辍学变量,模型相较于以前的单词袋模型上表现出显著的改进。此外,本文的模型在具有高句法差异的数据集上的表现要比句法模型更好。实验表明,本文的模型与语法感知模型存在相似的错误,表明在本文所考虑的任务中,非线性转换输入比定制网络以合并单词顺序和语法更重要。
Recurrent convolutional neural networks for text classification --- TextRCNN --- by Siwei Lai, Liheng Xu, Kang Liu, Jun Zhao (Github)
文本分类是众多NLP应用中的一项基本任务。传统的文本分类器通常依赖于许多人工设计的特征工程,例如字典,知识库和特殊的树形内核。与传统方法相比,本文引入了循环卷积神经网络来进行文本分类,而无需手工设计的特征或方法。在本文的模型中,当学习单词表示时,本文应用递归结构来尽可能地捕获上下文信息,相较于传统的基于窗口的神经网络,这种方法带来的噪声更少。本文还采用了一个最大池化层,该层可以自动判断哪些单词在文本分类中起关键作用,以捕获文本中的关键组成部分。本文在四个常用数据集进行了实验, 实验结果表明,本文所提出的模型在多个数据集上,特别是在文档级数据集上,优于最新方法。
2014年
Distributed representations of sentences and documents --- Paragraph-Vec --- by Quoc Le, Tomas Mikolov (Github)
许多机器学习算法要求将输入表示为固定长度的特征向量。当涉及到文本时,词袋模型是最常见的表示形式之一。尽管非常流行,但词袋模型有两个主要缺点:丢失了单词的顺序信息,并且也忽略了单词的语义含义。例如在词袋中,“powerful”,“strong”和“Paris”的距离相等(但根据语义含义,显然“powerful”和”strong”的距离应该更近)。因此在本文中,作者提出了一种无监督算法,用于学习句子和文本文档的向量表示。该算法用一个密集矢量来表示每个文档,经过训练后该向量可以预测文档中的单词。它的构造使本文的算法可以克服单词袋模型的缺点。实验结果表明,本文的技术优于词袋模型以及其他用于文本表示的技术。最后,本文在几个文本分类和情感分析任务上获得了SOTA效果。
A convolutional neural network for modelling sentences --- DCNN --- by Nal Kalchbrenner, Edward Grefenstette, Phil Blunsom (Github)
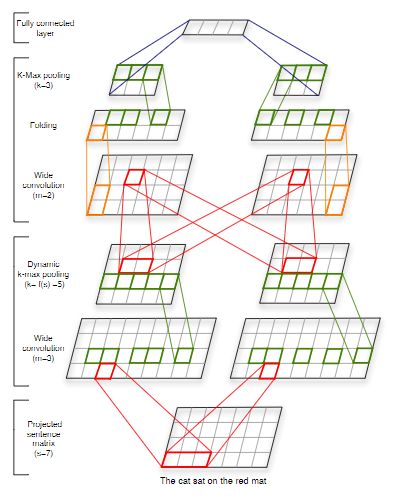
准确的句子表征能力对于理解语言至关重要。本文提出了一种被称为动态卷积神经网络(Dynamic Convolutional Neural Network , DCNN)的卷积体系结构,用来对句子的语义建模。网络使用一种线性序列上的全局池化操作,称为动态k-Max池化。网络处理长度可变的输入句子,并通过句子来生成特征图, 该特征图能够显式捕获句中的短期和长期关系。该网络不依赖于语法分析树,并且很容易适用于任何语言。本文在四个实验中测试了DCNN:小规模的二类和多类别情感预测,六向问题分类以及通过远程监督的Twitter情感预测。相对于目前效果最好的基准工作,本文的网络在前三个任务中标系出色的性能,并且在最后一个任务中将错误率减少了25%以上。
Convolutional Neural Networks for Sentence Classification --- TextCNN --- by Yoon Kim (Github)

本文研究了在卷积神经网络(CNN)上进行的一系列实验,这些卷积神经网络在针对句子级别分类任务的预训练单词向量的基础上进行了训练。实验证明,几乎没有超参数调整和静态矢量的简单CNN在多个基准上均能实现出色的结果。通过微调来学习针对特定任务的单词向量可进一步提高性能。此外,本文还提出了对体系结构进行简单的修改,以让模型能同时使用针对特定任务的单词向量和静态向量。本文讨论的CNN模型在7个任务中的4个上超过了现有的SOTA效果,其中包括情感分析和问题分类。
2013年
Recursive deep models for semantic compositionality over a sentiment treebank --- RNTN --- by Richard Socher, Alex Perelygin, Jean Wu, Jason Chuang, Christopher D. Manning, Andrew Ng, Christopher Potts (Github)
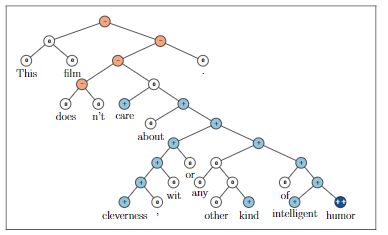
尽管语义词空间在语义表征方面效果很好,但却不能从原理上表达较长短语的含义。在诸如情绪检测等任务中的词语组合性理解方向的改进需要更丰富的监督训练和评估资源, 以及更强大的合成模型。为了解决这个问题,本文引入了一个情感树库。它在11,855个句子的语法分析树中包含215,154个短语的细粒度情感标签,并在情感组成性方面提出了新挑战。为了解决这些问题,本文引入了递归神经张量网络。在新的树库上进行训练后,该模型在多个评价指标上效果优于之前的所有方法。它使单句正/负分类的最新技术水平从80%上升到85.4%。预测所有短语的细粒度情感标签的准确性达到80.7%,相较于基准工作提高了9.7%。此外,它也是是唯一一个可以在正面和负面短语的各个树级别准确捕获消极影响及其范围的模型。
2012年
Semantic compositionality through recursive matrix-vector spaces --- MV-RNN --- by Richard Socher, Brody Huval, Christopher D. Manning, Andrew Y. Ng (Github)
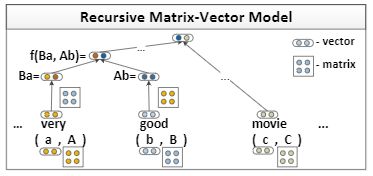
基于单个词的向量空间模型在学习词汇信息方面非常成功。但是,它们无法捕获较长短语的组成含义,从而阻止了它们更深入理解地理解语言。本文介绍了一种循环神经网络(RNN)模型,该模型学习任意句法类型和长度的短语或句子的成分向量表示。本文的模型为解析树中的每个节点分配一个向量和一个矩阵:其中向量捕获成分的固有含义,而矩阵捕获其如何改变相邻单词或短语的含义。该矩阵-向量RNN可以学习命题逻辑和自然语言中算子的含义。该模型在三种不同的实验中均获得了SOTA效果:预测副词-形容词对的细粒度情绪分布;对电影评论的情感标签进行分类,并使用名词之间的句法路径对名词之间的因果关系或主题消息等语义关系进行分类。
2011年
Semi-supervised recursive autoencoders forpredicting sentiment distributions --- RAE --- by Richard Socher, Jeffrey Pennington, Eric H. Huang, Andrew Y. Ng, Christopher D. Manning (Github)
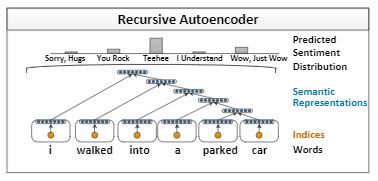
本文介绍了一种新颖地基于递归自动编码器机器学习框架,用于句子级地情感标签分布预测。本文的方法学习多词短语的向量空间表示。在情感预测任务中,这些表示优于常规数据集(例如电影评论)上的其他最新方法,而无需使用任何预定义的情感词典或极性转换规则。本文还将根据经验项目上的效果来评估模型在新数据集上预测情绪分布的能力。数据集由带有多个标签的个人用户故事组成,这些标签汇总后形成捕获情感反应的多项分布。与其他几个具有竞争力的baseline相比,本文提出的算法可以更准确地预测此类标签的分布。
浅层学习模型
2017年
Lightgbm: A highly efficient gradient boosting decision tree --- LightGBM --- by Guolin Ke, Qi Meng, Thomas Finley, Taifeng Wang, Wei Chen, Weidong Ma, Qiwei Ye, Tie-Yan Liu (Github)
梯度提升决策树(GBDT)是一种流行的机器学习算法,并且具有大量的高效实现(变体),例如XGBoost和pGBRT。尽管在这些实现中采用了许多工程优化方法,但是当特征维数较大且数据量较大时,模型效率和模型的可伸缩性仍不令人满意。一个主要原因是对于每个维度的特征,模型都需要扫描所有数据实例以估计所有可能的树分支点的信息增益, 这一步非常消耗事件。为了解决这个问题,本文提出了两种新颖的技术:基于梯度的单边采样 (GOSS)和Exclusive Feature Bundling (EFB)。使用GOSS,排除了大部分的小梯度数据样本,而仅使用其余部分来估计信息增益。作者证明,由于具有较大梯度的数据实例在信息增益的计算中起着更重要的作用,因此GOSS可以在数据量较小的情况下获得相当准确的信息增益估计。使用EFB来捆绑互斥的属性(即这两个属性很少同时采用非零值),以减少特征维度。实验证明,找到专有特征的最佳捆绑是NP难的,但是贪婪算法可以达到相当好的近似率(因此可以有效地减少特征维度,而不会严重损害树分支点的准确性)。本文将新的GBDT实施称为GOSS和EFB-LightGBM。在多个公共数据集上的实验表明,LightGBM将传统GBDT的训练过程加快了20倍以上,同时达到了几乎相同的准确性。
2016年
Xgboost: A scalable tree boosting system --- XGBoost --- by Tianqi Chen, Carlos Guestrin (Github)

提升树是一种高效且广泛使用的机器学习方法。本文描述了一种称为XGBoost的可扩展端到端提升树系统,该系统已被数据科学家广泛使用,以在许多机器学习竞赛中获得最优结果。本文为稀疏数据和加权分位数草图提出了一种新的稀疏感知算法,用来对树进行近似的学习。更重要的是,本文提供关于缓存访问模式,数据压缩和切片的研究,以构建可伸缩的提升树系统。结合以上这些方法,XGBoost可以使用比现有系统少得多的资源来对数十亿个样本进行建模。
2001年
--- Random Forests (RF) --- by Leo Breiman ({Github})
随机森林是多个决策树预测器的组合,其中每棵树都取决于独立采样的随机向量的值,并且森林中的所有树都具有相同的分布。森林的泛化误差收敛随着森林中树的数量的增加而达到极限。由决策树构成的随机森林的泛化误差取决于森林中各个树的强度以及它们之间的相关性。使用随机选择的功能来分割每个节点所产生的错误率可与Adaboost相比,但对噪声的鲁棒性更强。内在的估计监视误差,强度和相关性,同时也能反应出模型对特征数量增加的响应。内部估计也用于衡量变量的重要性。这些方法不仅适用于分类,同样也适用于回归。
1998年
Text categorization with Support Vector Machines: Learning with many relevant features (SVM) by JOACHIMS,T. ({Github})
本文探讨了使用支持向量机(SVM)从样本中学习文本分类器的方法。它分析了使用文本数据进行学习的特殊属性,并确定了SVM为什么适合此任务。实证结果证明了理论分析的正确性。SVM相较于当前效果最好的方法有巨大提升,并在各种不同的学习任务中表现出色。此外,该模型是全自动的,无需手动进行参数调整。
1993年
C4.5: Programs for Machine Learning (C4.5) by Steven L. Salzberg ({Github})
C4.5算法是由Ross Quinlan开发的用于产生决策树的算法,该算法是对Ross Quinlan之前开发的ID3算法的一个扩展。C4.5算法主要应用于统计分类中,主要是通过分析数据的信息熵建立和修剪决策树。
1984年
Classification and Regression Trees (CART) by Chyon-HwaYeh ({Github})
分类与回归树CART是由Loe Breiman等人在1984年提出的,自提出后被广泛的应用。CART既能用于分类也能用于回归,和决策树相比较,CART把选择最优特征的方法从信息增益(率)换成了基尼指数。
1967年
Nearest neighbor pattern classification (k-nearest neighbor classification,KNN) by M. E. Maron ({Github})
最近邻决策规则将待分类样本点的一组已分类样本点中的最近点的类别分配给该分类点。该规则与样本点及其类别的基础联合分布无关,因此,该规则的错误概率R必须至少与贝叶斯分类错误概率 一样大,即最小错误概率(一种在所有决策规则中都考虑了潜在的概率结构)。但是,在大量样本分析中,在在M类情况下()(应该是一个错误概率))对于所有适当平滑的基础分布,这些界限都可能是最严格的。因此,对于任何数量的类别,最近邻居规则的错误概率都以两倍的贝叶斯错误概率为界。从这个意义上讲,可以说无限样本集中分类信息的一半包含在最近的邻居中。
1961年
Automatic indexing: An experimental inquiry by M. E. Maron ({Github})
本文研究了一种根据文档的主题内容自动分类(索引)文档的技术。该技术本质上是让计算机读取文档,并根据所选线索词的出现频率来确定所讨论文档属于多个主题类别中的哪一个。本文介绍了如何设计,执行和评估相关的实验研究,以对自动索引统计技术进行实证检验。
数据集
Sentiment Analysis (SA) 情感分析
情感分析(Sentiment Analysis,SA)是在情感色彩中对主观文本进行分析和推理的过程。通过分析文本来判断作者是否支持特定观点的信息至关重要,这与分析文本客观内容的传统文本分类任务不同。SA可以是二分类也可以是多分类。Binary SA将文本分为两类,包括肯定和否定。多类SA将文本分类为多级或细粒度更高的不同标签。
Movie Review (MR) 电影评论数据集
Stanford Sentiment Treebank (SST) 斯坦福情感库
The Multi-Perspective Question Answering (MPQA)多视角问答数据集
IMDB reviews IMDB评论
Yelp reviews Yelp评论
Amazon Reviews (AM) 亚马逊评论数据集
News Classification (NC) 新闻分类数据集
新闻内容是最关键的信息来源之一,对人们的生活具有重要的影响。数控系统方便用户实时获取重要知识。新闻分类应用主要包括:识别新闻主题并根据用户兴趣推荐相关新闻。新闻分类数据集包括20NG,AG,R8,R52,Sogou等。在这里,我们详细介绍了一些主要数据集。
20 Newsgroups (20NG)
AG News (AG)
R8 and R52
Sogou News (Sogou) 搜狗新闻
Topic Labeling (TL) 话题标签
The topic analysis attempts to get the meaning of the text by defining thesophisticated text theme. The topic labeling is one of the essential components of the topic analysistechnique, intending to assign one or more subjects for each document to simplify the topic analysis.
话题分析旨在通过定义复杂的文本主题来获取文本的含义。话题标记是话题分析技术的重要组成部分之一,旨在为每个文档分配一个或多个话题标签以简化话题分析。
DBpedia
Ohsumed
Yahoo answers (YahooA) 雅虎问答
Question Answering (QA) 问答
问答任务可以分为两种:抽取式问答(extractiveQA)和生成式问答(extractiveQA)。抽取式问答为每个问题提供了多个候选答案,以选择哪个是正确答案。因此,文本分类模型可以用于抽取式问答任务。QA系统可以使用文本分类模型来识别正确答案,并将其他答案设置为候选答案。问答数据集包括SQuAD,MS MARCO,TREC-QA,WikiQA和Quora [209]。这里我们详细介绍了几个主要数据集。
Stanford Question Answering Dataset (SQuAD) 斯坦福问答数据集
MS MARCO
TREC-QA
WikiQA
Natural Language Inference (NLI) 自然语言推理
NLI用于预测一个文本的含义是否可以从另一个文本推论得出。释义是NLI的一种广义形式。它使用测量句子对语义相似性的任务来确定一个句子是否是另一句子的解释。NLI数据集包括SNLI,MNLI,SICK,STS,RTE,SciTail,MSRP等。在这里,我们详细介绍了所有主要数据集。
The Stanford Natural Language Inference (SNLI)
Multi-Genre Natural Language Inference (MNLI)
Sentences Involving Compositional Knowledge (SICK)
Microsoft Research Paraphrase (MSRP)
Dialog Act Classification (DAC) 对话行为分类
对话行为基于语义,语用和句法标准来描述对话中的话语。DAC根据其含义类别标记一个对话框,并帮助理解讲话者的意图。它是根据对话框给标签。在这里,我们详细介绍了所有主要数据集,包括DSTC 4,MRDA和SwDA。
Dialog State Tracking Challenge 4 (DSTC 4)
ICSI Meeting Recorder Dialog Act (MRDA)
Switchboard Dialog Act (SwDA)
Multi-label datasets 多标签数据集
在多标签分类中,一个实例具有多个标签,并且每个la-bel只能采用多个类之一。有许多基于多标签文本分类的数据集。它包括路透社,Education,Patent,RCV1,RCV1-2K,AmazonCat-13K,BlurbGen-reCollection,WOS-11967,AAPD等。这里我们详细介绍了一些主要数据集。
Reuters news
Patent Dataset
Reuters Corpus Volume I (RCV1) and RCV1-2K
Web of Science (WOS-11967)
Arxiv Academic Paper Dataset (AAPD)
Others 其他
还有一些用于其他应用程序的数据集,比如Geonames toponyms、Twitter帖子等等。
评价指标
在评估文本分类模型方面,准确率和F1分数是评估文本分类方法最常用的指标。随着分类任务难度的增加或某些特定任务的存在,评估指标也得到了改进。例如P @ K和Micro-F1评估指标用于评估多标签文本分类性能,而MRR通常用于评估QA任务的性能。
Single-label metrics 单标签评价指标
单标签文本分类将文本划分为NLP任务(如QA,SA和对话系统)中最相似的类别之一。对于单标签文本分类,一个文本仅属于一个目录,这使得不考虑标签之间的关系成为可能。在这里,我们介绍一些用于单标签文本分类任务的评估指标。
准确性和错误率是文本分类模型的基本指标。准确度和错误率分别定义为:
无论标准类型和错误率如何,这些都是用于不平衡测试集的重要指标。例如,大多数测试样本都具有类别标签。F1是Precision和Recall的谐波平均值。准确性,召回率和F1分数定义为:
当准确率、F1和recall值达到1时,就可以得到预期的结果。相反,当值为0时,得到的结果最差。对于多类分类问题,可以分别计算各类的查准率和查全率,进而分析个体和整体的性能。
Exact Match (EM)
Mean Reciprocal Rank (MRR)
Hamming-loss (HL)
Multi-label metrics 多标签评价指标
与单标签文本分类相比,多标签文本分类将文本分为多个类别标签,并且类别标签的数量是可变的。然而上述的度量标准是为单标签文本分类设计的,不适用于多标签任务。因此,存在一些为多标签文本分类而设计的度量标准。
Micro−F1
Micro-F1是一种考虑所有标签的整体精确率和召回率的措施。Micro-F1定义为:
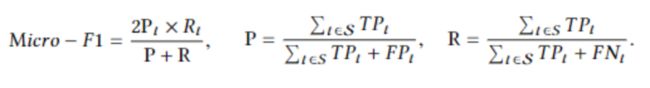
Macro−F1
Marco-F1计算所有标签的平均F1分数。与Micro-F1(每个示例都设置权重)不同,Macro-F1在平均过程中为所有标签设置相同的权重。形式上,Macro-F1定义为

除了上述评估指标外,还有一些针对极端多标签分类任务的基于排序的评估指标,包括P @ K和NDCG @ K。
其中P@K为排名第k处的准确率。P@K,每个文本有一组L个全局真标签Lt={l0,l1,l2...,lL−1}, 为了减少概率Pt=p0,p1,p2...,pQ−1。第k处的准确率为
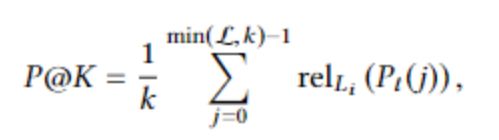
Normalized Discounted Cummulated Gains (NDCG@K)
排名第k处的NDCG值
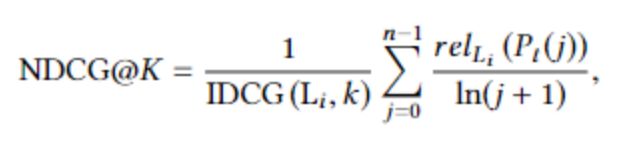
未来研究挑战
文本分类-作为有效的信息检索和挖掘技术-在管理文本数据中起着至关重要的作用。它使用NLP,数据挖掘,机器学习和其他技术来自动分类和发现不同的文本类型。文本分类将多种类型的文本作为输入,并且文本由预训练模型表示为矢量。然后将向量馈送到DNN中进行训练,直到达到终止条件为止,最后,下游任务验证了训练模型的性能。现有的模型已经显示出它们在文本分类中的有用性,但是仍有许多可能的改进需要探索。尽管一些新的文本分类模型反复擦写了大多数分类任务的准确性指标,但它无法指示模型是否像人类一样从语义层面“理解”文本。此外,随着噪声样本的出现,小的样本噪声可能导致决策置信度发生实质性变化,甚至导致决策逆转。因此,需要在实践中证明该模型的语义表示能力和鲁棒性。此外,由词向量表示的预训练语义表示模型通常可以提高下游NLP任务的性能。关于上下文无关单词向量的传输策略的现有研究仍是相对初步的。因此,我们从数据,模型和性能的角度得出结论,文本分类主要面临以下挑战:
数据层面
对于文本分类任务,无论是浅层学习还是深度学习方法,数据对于模型性能都是必不可少的。研究的文本数据主要包括多章,短文本,跨语言,多标签,少样本文本。对于这些数据的特征,现有的技术挑战如下:
Zero-shot/Few-shot learning
外部知识
多标签文本分类任务
具有许多术语词汇的特殊领域
模型层面
现有的浅层和深度学习模型的大部分结构都被尝试用于文本分类,包括集成方法。BERT学习了一种语言表示法,可以用来对许多NLP任务进行微调。主要的方法是增加数据,提高计算能力和设计训练程序,以获得更好的结果如何在数据和计算资源和预测性能之间权衡是值得研究的。
性能评估层面
浅层模型和深层模型可以在大多数文本分类任务中取得良好的性能,但是需要提高其结果的抗干扰能力。如何实现对深度模型的解释也是一个技术挑战。
模型的语义鲁棒性
近年来,研究人员设计了许多模型来增强文本分类模型的准确性。但是,如果数据集中有一些对抗性样本,则模型的性能会大大降低。因此,如何提高模型的鲁棒性是当前研究的热点和挑战。
模型的可解释性
DNN在特征提取和语义挖掘方面具有独特的优势,并且已经完成了出色的文本分类任务。但是,深度学习是一个黑盒模型,训练过程难以重现,隐式语义和输出可解释性很差。它对模型进行了改进和优化,丢失了明确的准则。此外,我们无法准确解释为什么该模型可以提高性能。
工具和算法库
NeuralClassifier (https://github.com/Tencent/NeuralNLP-NeuralClassifier)
baidu_nlp_project2 (https://github.com/nocater/baidu_nlp_project2)
Multi-label (https://github.com/TianWuYuJiangHenShou/textClassifier)
下载一:中文版!学习TensorFlow、PyTorch、机器学习、深度学习和数据结构五件套!
后台回复【五件套】
下载二:南大模式识别PPT
后台回复【南大模式识别】
说个正事哈
由于微信平台算法改版,公号内容将不再以时间排序展示,如果大家想第一时间看到我们的推送,强烈建议星标我们和给我们多点点【在看】。星标具体步骤为:
(1)点击页面最上方“深度学习自然语言处理”,进入公众号主页。
(2)点击右上角的小点点,在弹出页面点击“设为星标”,就可以啦。
感谢支持,比心 。
。
投稿或交流学习,备注:昵称-学校(公司)-方向,进入DL&NLP交流群。
方向有很多:机器学习、深度学习,python,情感分析、意见挖掘、句法分析、机器翻译、人机对话、知识图谱、语音识别等。

记得备注呦
推荐两个专辑给大家:
专辑 | 李宏毅人类语言处理2020笔记
专辑 | NLP论文解读
专辑 | 情感分析
整理不易,还望给个在看!