知识图谱数据管理:存储与检索
目录
1 知识图谱大数据
2 知识图谱数据模型
3 知识图谱数据的检索
3.1 RDF图查询语言
4 Neo4j使用简介
1 知识图谱大数据
1 知识图谱是一种有向图结构,描述了现实世界中存在的实体、事件或者概念以及它们之间的相关
关系。
2.知识图谱中的知识是通过RDF的结构进行表示的,其基本构成单元是事实三元组:
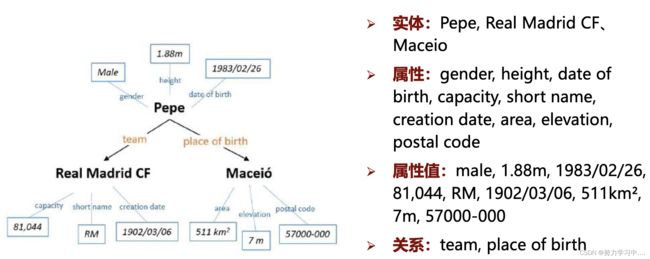
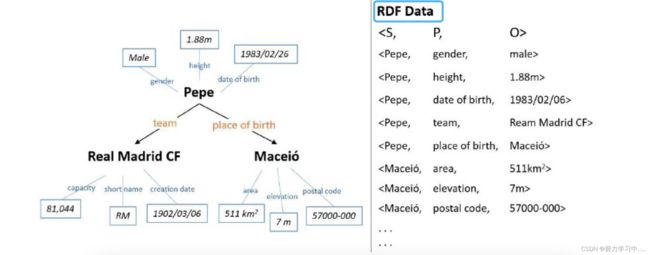
3. 知识图谱:图数据,属性:自身数据;拓扑结构:相互关系
4. 应用方向:社交网络:人立方关系搜索,博客分析,论坛观点挖掘,网络舆情监控;
路径规划:高德地图;
生物学:基因调控网络(基因之间的相互作用关系所形成的网络); 蛋白质PPI(蛋白质相互作用网络)
有机化学;
软件剽窃检测:目前软件剽窃检测的新方法是基于图模式匹配,将代码先转化为程序依赖图,然后再通过图匹配方法进行检测;
健康医疗大数据
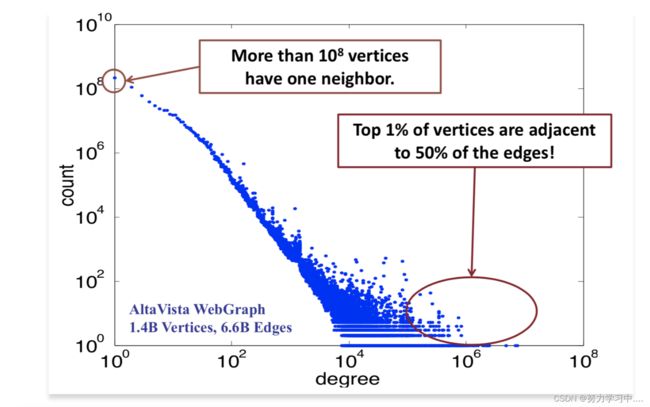
5. 大规模图数据特点:规模浩大(volume), 生成快速(velocity), 种类繁多(Variety), 可靠性(veracity);
倾斜的度分布
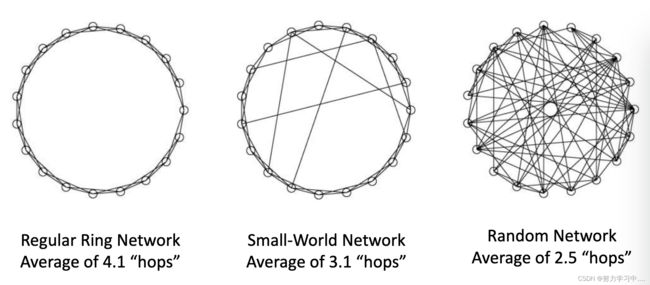
小世界现象
不清晰的社区结构
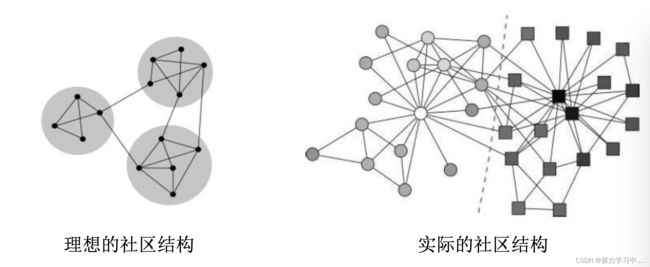
6. 大规模知识图谱数据的发布
百万顶点和上亿条边;1,301个知识图谱(2021-5-5)
https://lod-cloud.net/ https://lod-cloud.net/7. 知识图谱数据管理:知识图谱的目标是构建一个能够刻画现实世界的知识库,为自动问答、信息检索等应用提供支撑。因此,对知识的持久化存储并提供对目标知识的高效检索是合格的知识图谱(系统)必须具备的基本功能
https://lod-cloud.net/7. 知识图谱数据管理:知识图谱的目标是构建一个能够刻画现实世界的知识库,为自动问答、信息检索等应用提供支撑。因此,对知识的持久化存储并提供对目标知识的高效检索是合格的知识图谱(系统)必须具备的基本功能
知识图谱数据模型: RDF模型;属性图模型;
知识图谱数据的存储:基于表结构的存储,基于图结构的存储;
知识图谱数据的检索:声明式查询语言;过程式查询语言
2 知识图谱数据模型
1. 数据模型中的数据结构主要描述数据的类型、内容、性质以及数据间的联系等。
2. 数据结构是数据模型的基础,数据操作和约束都建立在数据结构上。
3. 不同的数据结构具有不同的操作和约束。数据模型中数据操作主要描述在相应的数据结构上的操作类型和操作方式。
4. 数据模型中的数据约束主要描述数据结构内数据间的语法、词义联系、他们之间的制约和依存关系,以及数据动态变化的规则,以保证数据的正确、有效和相容。
3 知识图谱数据的检索
1 知识图谱查询语言
RDF图:SPARQL 声明式语言
属性图:Cypher 声明式语言, PGQL 声明式语言, G-CORE 声明式语言, Gremlin 过程式语言
2 语义网回顾:以Web数据的内容(即语义)为核心,用机器能够理解和处理的方式链接起来的海量分布式数据库
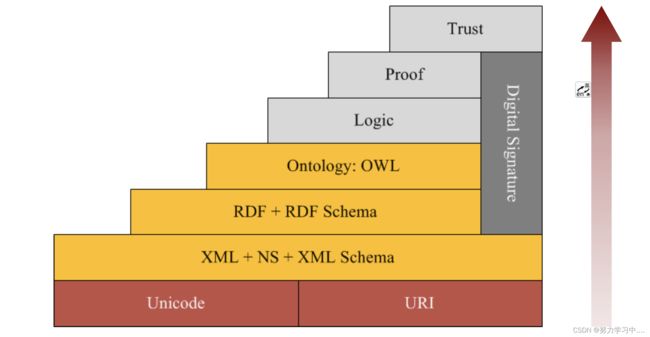
3. RDF回顾:RDF(Resource Description Framework,资源描述框架)是一种资源描述语言,其核心思想是利用Web标识符(URI)来标识事物,通过指定的属性和相应的值描述资源的性质或资源之间的关系。

图1
3.1 RDF图查询语言
1 SPARQL是Simple Protocol and RDF Query Language的缩写,是由W3C为RDF数据开发的一种查询语言和数据获取协议,是被图数据库广泛支持的查询语言。和SQL类似,SPARQL也是一种结构化的查询语言,用于对数据的获取与管理。
数据插入:将新的三元组插入到已有的RDF图中。SPARQL通过INSERT DATA语句完成该功能,其基本语法为:
INSERT DATA 三元组数据
三元组数据可以是多条三元组,不同的三元组通过“;” 分隔。如果待插入的三元组在RDF图中已经存在,那么系统会忽略该三元组。


数据删除:从RDF图中删除一些三元组。SPARQL通过DELETE DATA语句完成该功能,其基本语法为:
DELETE DATA 三元组数据
其中三元组数据可以是多条三元组,不同的三元组通过“;” 分隔。对于给定的每个三元组,如果其在RDF图中,则将其从图中删除,否则忽略该三元组


数据更新:更新RDF图中指定三元组的值。和SQL不同,SPARQL没有定义UPDATE操作,也就是说SPARQL语言没有直接更新已有数据的方法。但是,可以通过组合INSERT DATA语句和DELETE DATA语句来实现该功能。
➢ DELETE DATA:删除待修改的三元组;
➢ INSERT DATA:插入修改后的三元组;


数据查询:
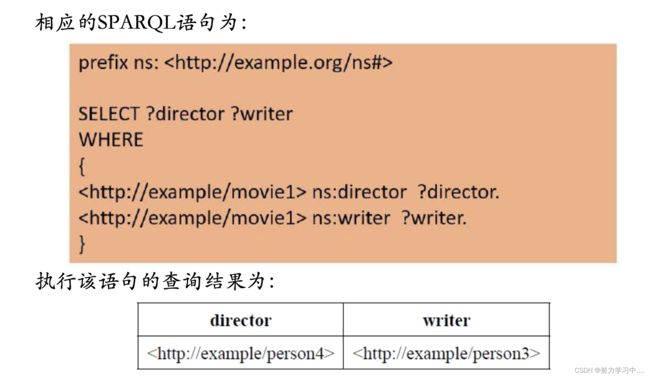
SELECT:最为常用的查询语句,其功能和SQL中的SELECT语句类似,从知识图谱中获取满足条件的数据;基本语法为:
SELECT 变量1 变量2 ...
WHERE 图模式
[ 修饰符 ]
SPARQL处理的数据具有更加灵活的存储结构,“变量1 变量2 ...”在知识图谱中没有直接的对应;
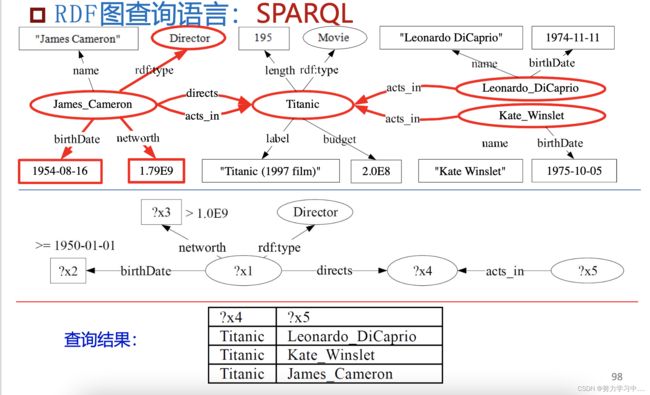
WHERE子句用于为SELECT子句中的变量提供约束,查询结果必须完全匹配该子句给出的图模式。图模式主要由两类元素组成,一类是三元组,例如“?x a Person”表示变量?x必须是Person的一个实例;另一类是通过FILTER关键字给出的条件限制,这些条件包括数字大小的限制、字符串格式的限制等;
ASK:用于测试知识图谱中是否存在满足给定条件的数据,如果存在则返回“yes”,否则返回“no”,该查询不会返回具体的匹配数据;
ASK 图模式

DESCRIBE:用于查询和指定资源相关的RDF数据,这些数据形成了对给定资源的详细描述;
DESCRIBE 资源或变量
[ WHERE 图模式 ]
DESCRIBE后既可以直接跟确定的资源标识符,也可以跟变量;
WHERE子句是可选的,用于限定变量需要满足的图模式;


CONSTRUCT:则根据查询图的结果生成RDF;
CONSTRUCT RDF图模板
WHERE 图模式
RDF图模板确定了生成的RDF图所包含的三元组类型,它由一组三元组构成,每个三元组既可以是包含变量的三元组模板,也可以是不包含变量的事实三元组;图模式则和上述SELECT 等语句中介绍的相同,用于约束语句中的变量;
该语句产生结果的基本流程为:首先执行WHERE子句,从知识图谱中获取所有满足图模式的变量取值;然后针对每一个变量取值,替换RDF图模板中的变量,生成一组三元组。


2. RDF图查询语言:SPARQL W3C RDF 标准查询语言

4 Neo4j使用简介
1. Neo4j:Neo4j是一个开源的图数据库系统,它将结构化的数据存储在图上而不是表中。Neo4j基于Java实现,它是一个具备完全事务特性的高性能数据库,具有成熟数据库的所有特性。Neo4j是一个本地数据库(又称基于文件的数据库),这意味着不需要启动数据库服务器,应用程序不用通过网络访问数据库服务,而是直接在本地对其进行操作,因此访问速度快。因其开源、高性能、轻量级等优势,Neo4j 受到越来越多的关注。更多信息请参考官网:
https://neo4j.com/https://neo4j.com/
2. 常见的图数据库平台

3. Neo4j的特点
查询语言Neo4j CQL (与Cyper类似)
遵循属性图数据模型;
支持UNIQUE约束;
包含一个用于执行CQL命令的UI;
支持完整的ACID规则(ACID:指数据库事务正确执行的四个基本要素,包含原子性(Atomicity), 一致性(consistency), 隔离性(Isolation), 持久性(Durability));
支持查询数据导出到JSON和XLS格式
提供了REST API,可以被任何编程语言访问;
支持两种Java API ,Cypher API和Native API 来开发java两种程序;
4. Neo4j 的优点与缺点
优点: 易于学习,易于表示半结构化数据,性能出众,加载数据快,内存占用低,只需选择需要倒入的数据,无需考虑数据大小,简单而强大的数据模型;
缺点: 支持节点数、关系和属性有限制,不支持SPARQL查询
5. CQL语言
(1)数据类型: 与java基本一致,主要用于定义节点和关系的属性
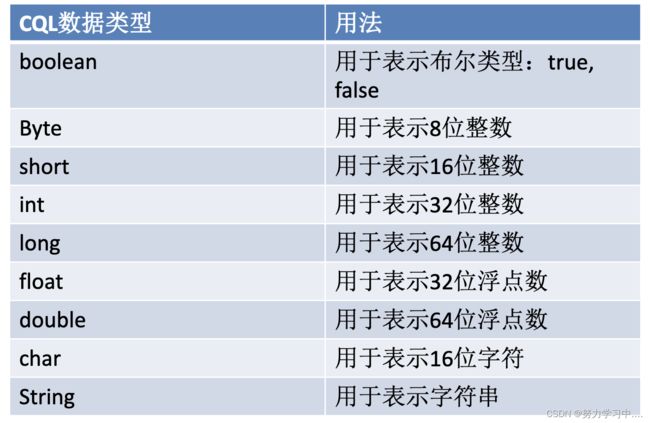
节点常用’()’表示,’()’内第一个为节点名,可以在后面添加多个标签名,添加标签名需要在每个标签前添加 ’:’符号;
关系常用’[]’表示,’[]’内第一个为关系名,可以在后面添加多个标签名,添加标签名需要在每个标签前添加 ’:’符号;
(2)常用命令
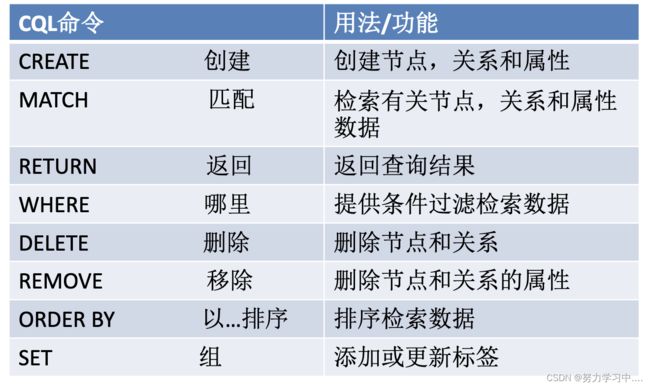
Neo4j CQL——CREATE
CREATE:
创建节点或关系
CREATE (
CREATE(
{
...
}) //创建有属性节点
CREATE (
}]->(
示例:
CREATE(node:player {name:”KobeBryant”, team:”Lakers”, top_score:”81”})
CREATE(player:player)-[re:play_in]->(team:team)
Neo4j CQL——MATCH
MATCH:
用于获取有关节点、关系和属性的数据
MATCH(
MATCH()-[
示例:
MATCH (n:player) RETURN n//返回当前所有player节点
MATCH (n:player) SET n.citizenship=‘US’//为所有player节点设置属性
MATCH (n) DELETE n//删除所有节点
MATCH (n:player)-[re]->() REMOVE re.name//删除以player起始的关系的
属性name
注意:MATCH不能单独使用,需要结合RETURN等语句组合使用
Neo4j CQL——RETURN
RETURN
用于返回节点或关联关系或它们的某些属性
RETURN
...
示例:
MATCH (n:player) RETURN n //返回所有player节点
CREATE (nod:team{name:’Lakers’,city:’LosAngeles’}) RETURN nod//创建
并返回新创建节点
MATCH ()-[re]->(nod:team) return re.name,nod.city//返回team节点的
city属性及指向它的所有关系的name属性
注意:RETURN不能单独使用,需要和MATCH等语句组合使用
Neo4j CQL——DELETE&REMOVE&SET
DELETE
删除节点,删除节点及相关节点与关系
DELETE
DELETE
示例:
MATCH (b) DELETE b//删除所有节点
MATCH (a:team)-[re]->() DELETE re //删除所有以team为起始点的关系
REMOVE
删除节点或关系的属性或标签
REMOVE
示例:
MATCH (nod:player) REMOVE nod.team//删除所有player节点的team属性
MATCH (n:player)-[re]->() REMOVE re.name//删除以player起始的关系的name属性
SET
添加或更新节点与关系的属性值(属性值不存在,就添加,否则更新)
SET
示例:MATCH(n:player) SET n.citizenship=‘US’//为所有player节点设置属性
Neo4j CQL——WHERE
WHERE
类似于SQL语句中的WHERE用于过滤MATCH获得的结果
WHERE
示例
MATCH (n:player)-[re]->() WHERE n.team=‘Lakers’ RETURN re//返回起始节点为
team=’Lakers’的player的关系
MATCH (p:player),(t:team) WHERE p.team=t.name CREATE (p)-[re:play_in]->(t)//创
建特定关系
Neo4j CQL——ORDER BY&UNION
ORDER BY
对返回结果排序
ORDER BY
注意:不加该语句将会对结果按照返回的第一个属性进行升序排序,
在该语句后添加DESC关键字可以获得降序排序。
UNION
将两组不同的结果合并成一组结果
UNION
注意:UNION 要求查询时列名相同,若不同可以使用AS关键字对列重命名, UNION返回数据中会去掉重复项。
Neo4j CQL——LIMIT&SKIP&IN
LIMIT&SKIP
返回前n个结果&跳过n个结果
LIMIT n & SKIP n
示例
MATCH (n:player) RETURN n LIMIT 25
MATCH (n:player) RETURN n SKIP 25
IN
提供值的集合
WHERE
示例
MATCH (n:player) WHERE n,top_score IN [51,52]

Neo4j CQL——字符串函数
1.UPPER:字母大写
UPPER (
示例:MATCH (n:player) RETURN n.UPPER(n,citizenship)
2.LOWER:字母小写
LOWER (
示例:MATCH (n:player) RETURN n.UPPER(n,team)
3.SUBSTRING:获取子字符串
SUBSTRING(
示例:MATCH (n:player) RETURN n.SUBSTRING(n.name,0,1)
Neo4j CQL——聚合函数
1.COUNT:返回MATCH得到的行数
COUNT(
示例:MATCH (n:player) RETURN COUNT(n)
2.MAX&MIN:返回MATCH返回的结果的一组最大值/最小值
MAX(
示例:MATCH(n:player) RETURN MIN(n.top_score)
3.SUM:返回MATCH得到的所有行的和
SUM(
示例:MATCH(n:player) RETURN SUM(n.top_score)
4.AVG:返回MATCH得到的所有行的平均值
AVG(
示例:MATCH(n:player) RETURN AVG(n.top_score)
Neo4j CQL——关系函数
1.STARTNODE&ENDNODE:用于指到关系的开始节点/结束节点
STARTNODE (
示例:MATCH (n)-[re]->(b) RETURN ENDNODE(re)
2.ID:获得关系的ID
ID (
示例:MATCH (n)-[re]->(b) RETURN ID(re)
3.TYPE:用于获取字符串表示中的一个关系的TYPE
TYPE(
示例:MATCH (n)-[re]->(b) RETURN TYPE(re)