零样本目标检测--GTNet: Generative Transfer Network for Zero-Shot Object Detection
一些必要知识:
(1)零样本学习(Zero shot learning)
一篇是 Lampert 2009年在CVPR上发表的Learning to Detect Unseen Object Class by Between-Class Attribute Transfer
这是最早提出 Zero Shot Learning 这一问题和概念的文章,核心思想就是用类间属性迁移来进行未知类别预测。具体地说,可以利用一个学习器,学习出一个动物是否具有马的外形,利用第二个学习器学习出一个动物是否具有斑纹,利用第三个学习器学习一个动物是否具有黑白间隔的颜色。当一张斑马的图片分别输入到这三个学习器之后,我们可以得到这张图片里的动物具有马的外形,斑纹以及黑白间隔的颜色。如果此时我们有一张表,这张表里记录着每一种动物这三种属性的取值,我们就可以通过查表的方式,将这张图片对应到斑马这一类别。这里的属性表,是可以事先总结好的,因为收集大量的未知类别的图片是困难的,但是仅仅总结每一类别相应的属性却是可行的。
同样是2009年,Hinton在NIPS上发表的Zero Shot Learning with Semantic Output Codes,核心思想就是用词向量进行未知类别预测。词向量(word2vec)是指将自然语言中的字词转为计算机可以理解的数字向量,并且其中意思相近的词将被映射到向量空间中相近的位置。具体地说,将训练标签编码为词向量,基于训练数据和词向量训练学习器。测试时输入测试数据,输出为预测的词向量,计算预测结果与未知类别词向量的距离,属于距离最近的类别。通过语义信息来搭建未见过类别和已见过类别的联系
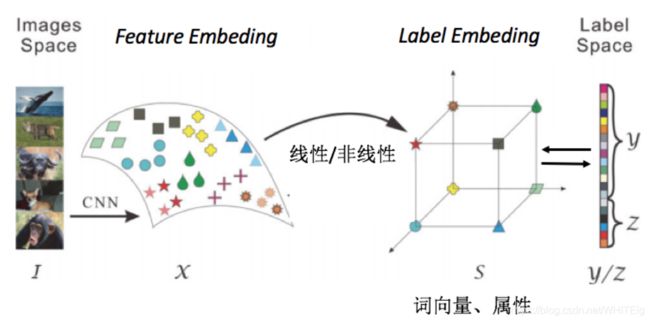
由以上两种可得,零样本学习的简单模式为:images space和label space分别为初始的图像空间和标签空间,在零样本学习中,一般会通过一些方法将图片映射到特征空间中,这个空间称为feature embeding;同样的标签也会被映射到一个label embeding当中,学习feature embeding和label embeding中的线性或非线性关系用于测试时的预测转化取代之前的直接由images space 到 label space的学习。如下图所示,一般把label embeding所在的空间叫做嵌入空间
(3)WGAN
对于GAN

CGAN首次提出为GAN增加限制条件,从而增加GAN的准确率。原始的GAN产生的数据模糊不清,为了解决GAN太过自由这个问题,一个很自然的想法就是给GAN加一些约束,于是便有了这篇Conditional Generative Adversarial Nets,这篇工作的改进非常straightforward,在生成模型和判别模型分别为数据加上标签,也就是加上了限制条件。实验表明很有效。
为了避免梯度消失问题,Arjovsky等人提出使用 Wasserstein距离替代原始的损失函数来衡量真假样本数据分布之问的距离,并通过简单的判别器参数裁剪实现。为了不降低判别器的能力,他们进一步改进了上述模型,提出了WGAN—GP,用梯度惩罚项替代参数裁剪操作。显然,条件生成网络(CVAE,CGAN)和改进的生成对抗训练机制(WGAN—GP)为稳定地合成具有丰富语义的视觉样本提供了巨大的可能性。
(4)Faster-RCNN
R-CNN:利用selective search 算法在图像中从上到下提取2000个左右的建议框;将每个建议框缩放(warp)成227*227的大小并输入到CNN,将CNN的fc7层的输出作为特征;将每个建议框提取的CNN特征输入到SVM进行分类;对于SVM分好类的建议框做边框回归,用Bounding box回归值校正原来的建议窗口,生成预测窗口坐标。
FAST-RCNN:利用selective search 算法在图像中从上到下提取2000个左右的建议框;将整张图片输入CNN,进行特征提取;把建议框映射到CNN的最后一层卷积特征图上;通过RoI pooling层使每个建议框生成固定尺寸的特征图;利用Softmax Loss(探测分类概率) 和Smooth L1 Loss(探测边框回归)对分类概率和边框回归(Bounding box regression)联合训练,使用多任务损失函数。
差别:R-CNN把一张图像分解成大量的建议框,每个建议框拉伸形成固定大小的图像都会单独通过CNN提取特征,实际上这些建议框之间大量重叠,特征值之间完全可以共享,造成了运算能力的浪费。FAST-RCNN将整张图像归一化后直接送入CNN,在最后的卷积层输出的feature map上,加入建议框信息,使得在此之前的CNN运算得以共享。R-CNN中独立的SVM分类器和回归器需要大量特征作为训练样本。FAST-RCNN把类别判断和位置回归统一用深度网络实现,不再需要额外存储。而且由于ROI pooling的提出,不需要再input进行Corp和wrap操作,避免像素的损失,巧妙解决了尺度缩放的问题。
FASTER-RCNN:将整张图片输入CNN,进行特征提取;用RPN先生成一堆Anchor box,对其进行裁剪过滤后通过softmax判断anchors属于前景(foreground)或者后景(background),是一个二分类;同时,另一分支bounding box regression修正anchor box,形成较精确的proposal,把建议窗口映射到CNN的最后一层卷积特征图上;通过RoI pooling层使每个RoI生成固定尺寸的特征图;利用Softmax Loss(探测分类概率) 和Smooth L1 Loss(探测边框回归)对分类概率和边框回归(Bounding box regression)联合训练。
获取Anchors之后,接着进一步对Anchors进行越界剔除和使用nms非最大值抑制,剔除掉重叠的框;比如,设定IoU为0.7的阈值,即仅保留IoU不超过0.7的局部最大得分的box(粗筛)。最后留下大约2000个anchor,然后再取前N个box(比如300个);这样,进入到下一层ROI Pooling时region proposal大约只有300个。
bbox回归使得到的检测框A与GT框G尽可能接近,就是学习平移量和缩放系数,学到一种变换使得A变成G‘

当输入的anchor A与 G 相差较小时,可以认为这种变换是一种线性变换, 那么就可以用线性回归来建模对窗口进行微调。

对于训练bounding box regression网络回归分支,输入是cnn feature Φ,监督信号是Anchor与GT的差距,即训练目标是:输入 Φ的情况下使网络输出与监督信号尽可能接近。那么当bouding box regression工作时,再输入Φ时,回归网络分支的输出就是每个Anchor的平移量和变换尺度,显然即可用来修正Anchor位置了。
对于大小为 M*N*C 的特征,RPN输出: 大小为 M*N*2K 的positive/negative softmax分类特征矩阵、大小为 M*N*4K 的regression坐标回归特征矩阵,恰好满足RPN完成positive/negative分类+bounding box regression坐标回归。

Proposal层包含三个输入:分类结果,回归偏移量以及im_info。im_info保存了此次缩放的所有信息,作用是:判断将anchors映射回原图是否超出边界。
RoI Pooling层则负责收集proposal,并计算出proposal feature maps,送入后续网络。感兴趣区域在目标检测中理解为候选框,原图经过卷积层得到特征图后,相应的ROI就会在feature map上有映射,这个映射过程是roi pooling的一部分,roi pooling后续部分会进行max pooling,进而得到我们需要的feature map,送入后面继续计算。具体表述为:根据ROIS提供的候选框坐标,映射到FeatureMap,然后进行max-pooling。结果是,从具有不同大小的矩形框中,我们可以快速获得具有固定大小的相应特征映射。
(5)类语义嵌入FastText(使用 fastText 训练的文本描述嵌入作为类语义嵌入)
One hot representation:one-hot编码就是保证每个样本中的单个特征只有1位处于状态1,其他的都是0。
Dristributed representation可以解决One hot representation的问题,它的思路是通过训练,将每个词都映射到一个较短的词向量上来。这个过程称为word embedding(词嵌入),即将高维词向量嵌入到一个低维空间。而得到最后的词向量的训练过程中引入了词的上下文。
word2vec是简化的神经网络,输入是One-Hot Vector,Hidden Layer,Output Layer维度跟Input Layer的维度一样。当这个模型训练好以后,需要的是这个模型通过训练数据所学得的参数,例如隐层的权重矩阵。这个模型是一般定义数据的输入和输出分为CBOW(Continuous Bag-of-Words) 与Skip-Gram两种模型。CBOW模型的训练输入是某一个特征词的上下文相关的词对应的词向量,而输出就是这特定的一个词的词向量。Skip-Gram模型和CBOW的思路相反,即输入是特定的一个词的词向量,而输出是特定词对应的上下文词向量。CBOW对小型数据库比较合适,而Skip-Gram在大型语料中表现更好。因为FastText结构与CBOW类似,因此这里只介绍CBOW结构:

训练时,输入为上下文单词的onehot(假设单词向量空间维度为V,上下文单词个数为C),所有onehot分别乘以共享的输入权重矩阵W,所得的向量相加求平均作为隐层向量,乘以输出权重矩阵得到向量,激活函数处理得到V-dim概率分布(其中的每一维代表着一个单词),概率最大的 id 所指示的单词为预测出的中间词(target word),与true label的onehot做比较,误差越小越好。训练完毕后,输入层的每个单词与矩阵W相乘得到的向量的就是我们想要的词向量(word embedding)
fasttext是facebook开源的一个集word2vec与文本分类的工具,典型应用场景是“带监督的文本分类问题”。提供简单而高效的文本分类和表征学习的方法,性能比肩深度学习而且速度更快。fastText方法包含三部分,模型架构,层次SoftMax和N-gram子词特征。使用fastText进行文本分类的同时也会产生词的embedding,即embedding是fastText分类的产物。
word2vec把语料库中的每个单词当成原子,它会为每个单词生成一个向量,这忽略了单词内部的形态特征,比如 “apple” 与 “apples”,两个单词都有较多的公共字符,即它们的内部形态类似,但是在传统的word2vec中,这种单词内部形态信息因为它们被转换成不同的id丢失了。为了克服这个问题,fastText使用了n-grams来代替单词,对于单词的n-grams是字符级别,对于句子的n-grams是字级别或者词级别。比如:
①我喜欢观看美剧
相应的bigram特征为:我喜 喜欢 欢观 观看 看美 美剧
相应的trigram特征为:我喜欢 喜欢观 欢观看 观看美 看美剧
②我 喜欢 观看 美剧
相应的bigram特征为:我/喜欢 喜欢/观看 观看/美剧
相应的trigram特征为:我/喜欢/观看 喜欢/观看/美剧
字符级别的n-grams来表示一个单词,比如对于“apple”,假设n的取值为3,则它的trigram特征有:
使用n-gram有如下优点
①为罕见的单词生成更好的词向量:根据上面的字符级别的n-gram来说,即是这个单词出现的次数很少,但是组成单词的字符和其他单词有共享的部分,因此这一点可以优化生成的词向量。
②在词汇单词中,即使单词没有出现在训练语料库中,仍然可以从字符级n-gram中构造单词的词向量。
③n-gram可以让模型学习到局部单词顺序的部分信息, 如果不考虑n-gram则便是取每个单词,这样无法考虑到词序所包含的信息,即也可理解为上下文信息,因此通过n-gram的方式关联相邻的几个词,这样会让模型在训练的时候保持词序信息。

fastText 模型输入一个词的序列(一段文本或者一句话),输出这个词序列属于不同类别的概率。序列中的词和词组组成特征向量,特征向量通过线性变换映射到中间层,中间层再映射到标签。
目前关于FastText还不是很清楚,之后看了再补充吧==
2.1 模型架构
论文:GTNet: Generative Transfer Network for Zero-Shot Object Detection
论文链接:https://arxiv.org/pdf/2001.06812v1
摘要:
提出了一种用于零样本目标检测的生成迁移网络(GTNet)。GTNet由目标检测模块和知识迁移模块组成。目标检测模块可以学习大规模的已知领域知识;知识迁移模块利用特征合成器生成未知的类特征,用于为目标检测模块训练新的分类层。为了综合类内方差和IoU方差,我们设计了一个基于IoU感知的生成式对抗网络(IoUGAN)作为特征合成器,可以方便地集成到GTNet中。
近年来,许多深度学习方法在目标检测方面取得了令人满意的效果。但是,检测器的性能依赖于带有全注释边界框的大型检测数据集。收集足够多的标记数据是不现实的,因为现实世界充斥着大量的类别。在这种情况下,这些方法受到零样本目标检测(zero-shot object detection, ZSD)任务的挑战,该任务的目的是在没有任何训练实例的情况下对新类进行分类和定位。零样本目标检测可分为语义嵌入空间和视觉特征空间两类。(1)现有的方法一般将从预测的边界框中获得的视觉特征映射到语义嵌入空间。在推理阶段,根据与所有类嵌入的相似度评分找到最近的类,从而预测类标签。然而,将高维视觉特征映射到低维语义空间,往往会由于二者之间的异质性而产生中心问题。 (2)在视觉特征空间中直接对物体进行分类,可以解决中心度问题。大量的零样本分类方法证明了该方法在视觉空间上的有效性。然而,视觉特征不仅包含类内方差,还包含IoU方差,IoU方差是对象检测的重要线索。
为了解决这些问题,我们提出了一种用于ZSD的生成式迁移网络(GTNet)。具体地,我们介绍了一个生成模型来综合视觉特征来解决中心问题。同时,在考虑IoU方差的基础上,我们设计了一个基于IoU感知的生成对抗网络(IoUGAN)来生成同时具有类内方差和IoU方差的视觉特征。对于特征合成器IoUGAN,包括三个单元模型:类特征生成单元(CFU)、前景特征生成单元(FFU)和背景特征生成单元(BFU)。CFU以类语义嵌入为条件,使用类内方差生成未知特征。FFU和BFU将IoU方差添加到CFU的结果中,分别得到了类特定的前景和背景特征。
该GTNet由目标检测模块和知识迁移模块组成。更具体地说,目标检测模块包含一个特征提取器、一个边界框回归器和一个已知类别分类器。另外,利用特征提取器从图像中提取感兴趣区域的特征。知识迁移模块由特征综合器和未知分类器组成。利用特征合成器生成视觉特征,训练未知的分类器。将训练好的未知类别分类器与特征提取器和边界框回归器进行集成,实现ZSD。
IoUGAN作为一种检测专用的特征合成方法,由三类单元模型组成:类特征生成单元(CFU)、前景特征生成单元(FFU)和背景特征生成单元(BFU)。每个单元包含一个生成器和一个鉴别器。IoUGAN的特征生成过程如图1所示。具体地说,CFU关注于为每个未知的类综合特性,而类内方差取决于类语义嵌入。FFU的目的是将IoU方差加入到CFU结果中,生成前景特征。此外,为了减少背景与未知类别之间的混淆,BFU综合了基于CFU结果的类特异性背景特征。
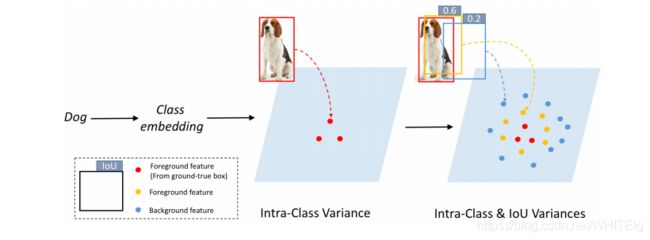
图1 特性合成过程。首先在类语义嵌入的基础上综合视觉特征。然后,我们进一步添加IoU方差的特点。
这项工作的主要贡献可以概括如下:
• 针对ZSD问题,我们提出了一种新颖的深度架构GTNet。GTNet利用一个特性合成器来生成未知的类特征。它只需要训练一个新的分类层,一个预先训练的检测器使用合成的特征。
• 我们提出了一个新的条件生成模型IoUGAN来综合未知的类特征,包括类内方差和IoU方差。此外,IoUGAN还可以作为特征合成器集成到GTNet中。
相关工作
全监督目标检测:过去几年,目标检测是由深度卷积神经网络驱动的。最流行的模型可以分为单级网络,如SSD, YOLO和双级网络,如Faster R-CNN, R-FCN。具体来说,像SSD、YOLO这样的单级网络只需要一步就可以完成分类和边界框回归。R-FCN通过区域建议网络(RPN)对第一阶段预定义的锚盒偏移量进行预测,然后对第二阶段的边界框预测进行分类和细化。这些目标检测模型只能检测训练数据集中出现的类别。然而,它们不能直接应用于预测在训练中看不到的类别。
零样本分类:现有的大多数零样本分类方法都将视觉特征投射到语义空间中。以前的一些工作建议学习语义-视觉映射,而不是学习视觉-语义映射。此外,也有一些工作学习中间空间,这是共同的视觉特征和语义嵌入。与此相反,一些条件生成模型通过利用GANs综合未知类别的视觉特征,将零样本分类问题转化为一般的全监督问题。我们还使用生成模型来生成伪特征,将ZSD转换成一个完全超可视的目标检测问题。与cGANs的零样本分类不同,IoUGAN可以将IoU方差加入到综合特征中。
零样本目标检测:关于ZSD的当代研究有五项。具体地说,提出了一个背景感知模型,以减少背景和未知类之间的混淆。提出了由最大边缘损失和元类聚类损失构成的分类损失。使用嵌入的凸组合来解决ZSD问题。通过探索类的自然语言描述来探测未知的类。提出了一个极性丢失函数,用于更好地调整视觉特性和语义嵌入。所有这些方法都侧重于将视觉特征从预测的边界框映射到语义嵌入空间。相反,我们提出了一个生成方法来处理ZSD问题。
零样本目标检测的生成方法
GTNet由两个模块组成:目标检测模块和知识迁移模块。然后,我们设计了一个新的条件生成模型(即IoUGAN)作为特征合成器,嵌入到知识迁移模块中。(用已知类别数据训练特征提取模块、边框回归模块和IoUGAN模块,用未知类别数据输入IoUGAN然后训练分类器)
3.1 生成迁移网络
网络概述:如图2所示,GTNet由一个目标检测模块和一个知识迁移模块组成。具体来说,该目标检测模块由一个已知分类器、一个边界盒回归器和一个特征提取器组成。为了重用回归参数来检测未知的类,边界盒回归器在所有类别之间共享,而不是特定于每个类别。特征提取器用于提取图像的感兴趣区域特征。具体来说,特征提取器采用了更快的R-CNN,在竞争的端到端检测模型中具有优越的性能。特征合成器(IoUGAN)是一种条件生成模型,它可以根据类语义嵌入来学习生成视觉特征。

图2 生成迁移网络(GTNet)的说明。它由目标检测模块和知识迁移模块组成。知识迁移模块由特征合成器(即IoUGAN)和未知的类别分类器组成。利用特征提取器和类语义嵌入对合成器进行训练。一个经过训练的特征合成器可以采样未知的类特征,这些特征可以用来训练未知的类别分类器。经过训练的未知分类器进一步与特征提取器和回归器集成,实现零样本目标检测。
零样本目标检测器的构建过程:在大规模已知类数据集中对目标检测模块进行预处理。然后利用特征提取器中的真实特征和相应的类嵌入对特征合成器IoUGAN进行训练。经过训练的合成器可以通过输入相应的类语义嵌入来生成未知类的视觉特征。最后,我们使用生成的特征来训练一个未知的类别分类器。在推理阶段,我们将经过训练的未知类分类器与特征提取器和回归器相结合来检测未知类。
3.2 IoU感知的生成对抗网络
为了生成具有IoU方差的不同类的特征,我们提出了一个简单而有效的IoUGAN,它主要由三个单元模型(即CFU、FFU和BFU)组成,如图3所示。每个单元包含一个生成器和一个鉴别器。此外,由于生成模型的训练更加稳定,我们将WGAN作为生成模型的基本组件。
- CFU:它侧重于根据给定的类语义嵌入和噪声向量生成类内方差的特征。
- FFU:将IoU方差加入到CFU的结果中,输出类特定的前景特征。
- BFU:以CFU的结果作为输入,输出类特定的背景特征。
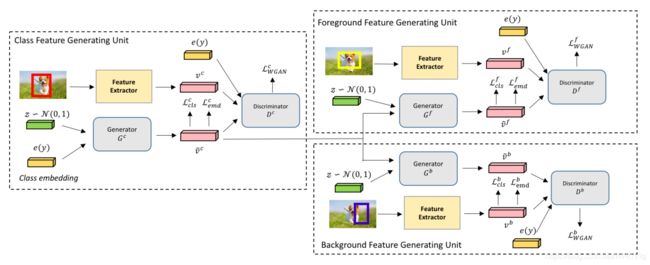
图3 iou感知的生成对抗网络(IoUGAN)的说明。类特征生成单元(CFU)以类嵌入和随机噪声向量作为输入,输出具有类内方差的特征。然后,前景特征生成单元(FFU)和背景特征生成单元(BFU)将IoU方差添加到CFU的结果中,分别输出类特定的前景和背景特征。
定义和表示:我们使用特征提取器来采样已知类别的视觉特征。IoUGAN的训练集表示为:
![]()
其中:![]() 表示从图像的GT box提取到的特征;
表示从图像的GT box提取到的特征;![]() 是特定类的前景特征,从一个边界框与真实框的IoU大于阈值
是特定类的前景特征,从一个边界框与真实框的IoU大于阈值 ![]() 的正边界框提取得到;
的正边界框提取得到;![]() 是特定类的背景特征,从一个边界框与真实框的IoU小于阈值
是特定类的背景特征,从一个边界框与真实框的IoU小于阈值 ![]() 的负边界框提取得到;
的负边界框提取得到;![]() 表示S个已知类别的类标签
表示S个已知类别的类标签![]() ;
;![]() 表示特定类别的语义嵌入。注意,提取
表示特定类别的语义嵌入。注意,提取![]() 和
和![]() 的正边界框和负边界框是由RPN预测的。在训练过程中,我们从
的正边界框和负边界框是由RPN预测的。在训练过程中,我们从 ![]() 个样本中随机选取
个样本中随机选取 ![]() 对应的
对应的 ![]() 和
和 ![]() 送入IoUGAN。此外,我们还得到了未知类别
送入IoUGAN。此外,我们还得到了未知类别![]() 的语义嵌入,其中U是类别数,来自一个不相交标签集
的语义嵌入,其中U是类别数,来自一个不相交标签集 ![]() ,e(U)是对应的未知类的语义嵌入。
,e(U)是对应的未知类的语义嵌入。
CFU:我们没有使用IoU方差直接生成不同类的特性,而是简化了使用CFU首先生成具有类内方差的特性的任务。我们使用从GT box提取的特征 ![]() 作为真实的特征来引导生成器捕获目标的整体特征。给定 S 类已知类别的训练数据,在CFU中,我们的目标是学习条件生成器
作为真实的特征来引导生成器捕获目标的整体特征。给定 S 类已知类别的训练数据,在CFU中,我们的目标是学习条件生成器 ![]() ,以高斯随机噪声 z 和类嵌入
,以高斯随机噪声 z 和类嵌入![]() 作为它的输入,并输出一个类别 y 的视觉特征
作为它的输入,并输出一个类别 y 的视觉特征![]() 。鉴别器
。鉴别器![]() 是输出为实值的多层感知器,。
是输出为实值的多层感知器,。![]() 试图最小化损失,而
试图最小化损失,而 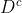 则试图最大化损失。
则试图最大化损失。
训练CFU的结果:在已知类嵌入![]() 的条件下,一旦
的条件下,一旦 ![]() 学会合成已知类别的视觉特征(
学会合成已知类别的视觉特征(![]() ),那么通过类嵌入
),那么通过类嵌入![]() ,它还可以生成未知类别u的视觉特征
,它还可以生成未知类别u的视觉特征 ![]() 。训练CFU中条件WGAN的损耗为:
。训练CFU中条件WGAN的损耗为:
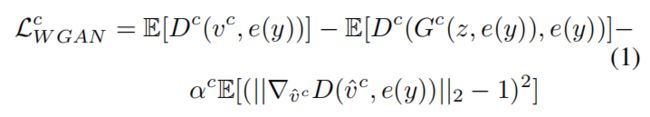
这里 ![]() 是
是 ![]() 和
和 ![]() 的凸组合,参数取值为0到1;
的凸组合,参数取值为0到1;![]() 是惩罚系数;E是期望。Wasserstein距离由前两项近似得到,第三项约束鉴别器的梯度为单位范数,同时约束实对
是惩罚系数;E是期望。Wasserstein距离由前两项近似得到,第三项约束鉴别器的梯度为单位范数,同时约束实对 ![]() 和生成对
和生成对 ![]() 的凸组合。
的凸组合。
FFU:RPN预测的边界框总是不能与ground-truth边界框完全重叠。即使一个和ground-true框有较大IoU的正边界框,从这个正边界框中提取出来的特征仍然比从ground-true框中提取出来的特征少一些信息。检测器应该对前景特征的信息丢失具有鲁棒性。在本例中,我们使用FFU将IoU方差随机添加到CFU输出的特征中。因此,将前景特征 ![]() 作为训练FFU的真实特征。
作为训练FFU的真实特征。
有了CFU的输出 ![]() 和高斯潜在变量 z,训练FFU的条件WGAN的损耗为:
和高斯潜在变量 z,训练FFU的条件WGAN的损耗为:
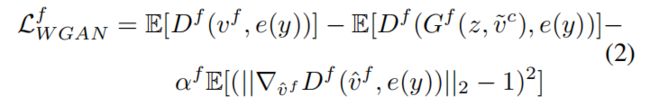
这里 ![]() 是
是 ![]() 和
和 ![]() 的凸组合,参数取值为0到1;
的凸组合,参数取值为0到1;![]() 是惩罚系数。不同于CFU的生成器,不使用语义嵌入作为FFU生成器的输入,因为这里假设语义信息已经被
是惩罚系数。不同于CFU的生成器,不使用语义嵌入作为FFU生成器的输入,因为这里假设语义信息已经被 ![]() 保存。
保存。
BFU:背景和未知类的混淆限制了零样本检测器的性能。为了增强检测器对背景类和未知类的区分能力,我们使用BFU来生成特定类的背景特征。我们使用背景特征 ![]() 作为训练BFU的真实特征来引导生成器。
作为训练BFU的真实特征来引导生成器。
有了CFU的输出 ![]() 和高斯潜在变量 z,训练BFU的条件WGAN的损耗为:
和高斯潜在变量 z,训练BFU的条件WGAN的损耗为:

这里 ![]() 是
是 ![]() 和
和 ![]() 的凸组合,参数取值为0到1;
的凸组合,参数取值为0到1;![]() 是惩罚系数。
是惩罚系数。
总体目标函数:
训练过程中,合成的特征应该非常适合训练检测器的判别分类层,这里我理解的是类似于GAN里面的附加分类器,这里添加一个分类层。在输入数据上训练的判别分类层被用于分类合成特征 ![]() ,这样我们可以在合成特征上最小化分类损失。请注意,为了简单起见,我们使用
,这样我们可以在合成特征上最小化分类损失。请注意,为了简单起见,我们使用 ![]() 表示生成的所有特征(即
表示生成的所有特征(即![]() 、
、![]() 和
和![]() )。为此,我们使用负对数似然,
)。为此,我们使用负对数似然,
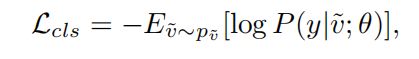
其中,y表示![]() 的类标签,
的类标签,![]() 是
是 ![]() 属于它真正的类标签y的预测概率。此外,我们进一步使用
属于它真正的类标签y的预测概率。此外,我们进一步使用![]() ,
,![]() ,
,![]() 表示三个单元的分类损失函数。计算条件概率是用参数为
表示三个单元的分类损失函数。计算条件概率是用参数为 的单层FC网络,参数是在已知类别的真实特征上预训练的。
的单层FC网络,参数是在已知类别的真实特征上预训练的。
此外,我们希望类  的生成特征接近相同类的真实特征并且远离其他不同类
的生成特征接近相同类的真实特征并且远离其他不同类  的真实特征(
的真实特征(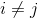 )。在一个batch中,我们通过将真实特征和生成特征配对来生成匹配(同类)和不匹配(不同类)的特征对。最后,通过余弦嵌入损耗函数,使匹配和不匹配特征之间的距离分别最小化和最大化:
)。在一个batch中,我们通过将真实特征和生成特征配对来生成匹配(同类)和不匹配(不同类)的特征对。最后,通过余弦嵌入损耗函数,使匹配和不匹配特征之间的距离分别最小化和最大化:
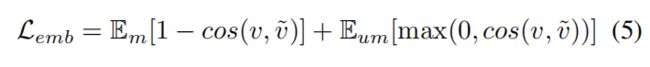
其中 ![]() 和
和 ![]() 分别是匹配(m)和非匹配(um)对分布的期望。同样,我们用
分别是匹配(m)和非匹配(um)对分布的期望。同样,我们用  表示所有的真实特征(即
表示所有的真实特征(即![]() 、
、![]() 和
和![]() )。我们进一步使用
)。我们进一步使用 ![]() ,
,![]() ,
,![]() 分别表示三个单元的嵌入损失函数。其他损失(
分别表示三个单元的嵌入损失函数。其他损失(![]() 和
和 )侧重于生成的特征与同类的真实特征之间的相似性,而嵌入损失
)侧重于生成的特征与同类的真实特征之间的相似性,而嵌入损失 ![]() 也强调了生成的特征与其他类特征之间的差异性。使用β1β2,β3,γ1,γ2和γ3作为衡量各自的损失的超参数来训练CFU,FFU,BFU的最终目标,表示为:
也强调了生成的特征与其他类特征之间的差异性。使用β1β2,β3,γ1,γ2和γ3作为衡量各自的损失的超参数来训练CFU,FFU,BFU的最终目标,表示为:

实现细节
特征提取器采用了Faster R-CNN,使用Resnet-101作为特征提取器的主干。所看到的分类器和class-agnostic回归器都是单个全连层(FC)。另一方面,对于IoUGAN的三个单元(CFU,FFU,BFU),生成器G都是三层FC网络,输出层的维度与特征的大小相等,隐藏层的大小为4096。判别器D为两层FC网络,输出大小为1,隐藏层大小为4096。新的分类层是一个单层的FC,其输入大小等于特征大小,输出大小等于未知类的数量加上一(即背景类)。
数据集:ILSVRC-2017 detection dataset,MSCOCO,VisualGenome (VG)
评估准则:对于ILSVRC-2017数据集,我们使用平均精度(mean average precision, mAP)来评估性能。依据论文(Bansal et al. 2018),对于MSCOCO和VG,使用Recall@100作为评价指标,该指标定义为仅从图像中选择前100个proposals(根据预测得分排序)时的召回率。这是因为,对于MSCOCO和VG等大型多注释数据集,很难为类别的所有实例注释所有边界框。mAP对丢失的注释很敏感,它会将这种检测视为假阳性。
比较方法
将文章提出的方法与最新的三种方法(Rahman et al. 2018;Bansal et al. 2018;Li等人,2019b)做对比。为了与该方法(Li et al. 2019b)进行比较,使用fastText (Edouard Grave和Bojanowski 2017)训练的文本描述嵌入作为类语义嵌入。该研究(Li et al. 2019b)使用文本描述嵌入扩展了其他两种ZSD方法(Rahman et al. 2018;Bansal et al. 2018)并报告结果。我们只需复制论文(Li等,2019b)并粘贴表1和表2中结果。
我们在ILSVRC-2017数据集中比较模型的mAP。从表1可以看出,所提出的方法在大多数类别上的性能都优于其他比较模型,与ZS-DTD相比提高了1.9% (Li et al. 2019b提出的方法)。在有相似概念的类别上的表现(仓鼠、老虎、蝎子)比那些相似较小的类别(如老鼠、口琴、响尾蛇)要好得多。此外,我们的模型在注射器类别上有了显著的改进,从3.1%提高到30.4%,但是在老鼠类别上的性能比第一名降低了25.5%。但值得注意的是,注射器在训练数据集中有23个相似的类别,而老鼠只有5个相似的类别。这一现象表明,当我们已知的类域中有足够多的相似类别时,我们的方法可以有效地将知识转移到未知的类域。当在训练数据集中类似的类很少时,生成模型很难合成有判别性的视觉特征。
对于MSCOCO和VG数据集,以Recall@100做比较,使用了三种不同的IoU重叠阈值(即0.4、0.5、0.6)。另外,为了便于讨论,本文除另有规定外,均以IoU 0.5为例。从实验结果可以看出,所提出的模型总体上比其他比较基准具有更好的性能。具体来说,在MSCOCO上,该模型将Recall@100从该方法(Li et al. 2019b)实现的34.3%提高到44.6%,在VG上将Recall@100从7.2%提高到11.3%。

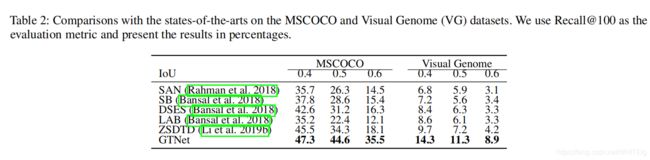
图4显示了使用MSCOCO数据集作为示例检测输出。这些例子证实了所提出的方法可以检测出在训练过程中看不到的类。当目标很小并且在一组未知的类中有类似的类时,往往会发生故障检测。
