CVPR佳作 | One-Shot都嫌多,Zero-Shot实例样本分割
欢迎关注“
计算机视觉研究院
”
计算机视觉研究院专栏
作者:Edison_G
给一个包含了未知种类多个实体的没训练过的新样本(the query image),如何检测以及分割所有这些实例???

长按扫描二维码关注我们
一、分割回顾
实例分割(Instance Segmentation)
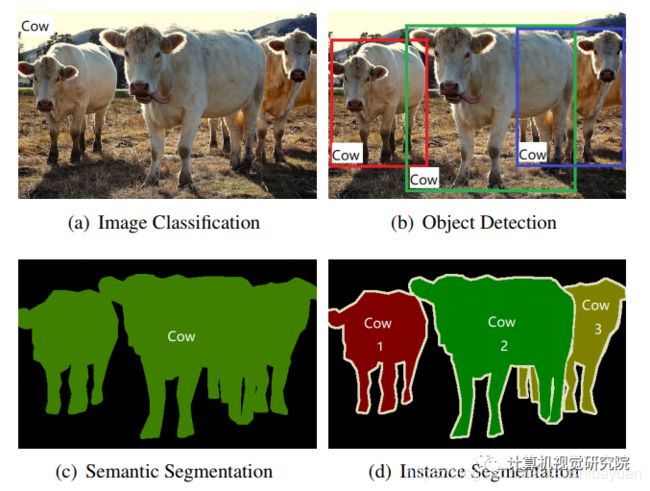
实例分割(Instance Segmentation)是视觉经典四个任务中相对最难的一个,它既具备语义分割(Semantic Segmentation)的特点,需要做到像素层面上的分类,也具备目标检测(Object Detection)的一部分特点,即需要定位出不同实例,即使它们是同一种类。因此,实例分割的研究长期以来都有着两条线,分别是自下而上的基于语义分割的方法和自上而下的基于检测的方法,这两种方法都属于两阶段的方法,下面将分别简单介绍。
以下摘自于:CSDN- 三十八元
两阶段实例分割
自上而下(Top-Down)
自上而下的实例分割方法的思路是:首先通过目标检测的方法找出实例所在的区域(bounding box),再在检测框内进行语义分割,每个分割结果都作为一个不同的实例输出。

这类方法的代表作就是大名鼎鼎的Mask R-CNN了,如下图,总体结构就是Faster R-CNN的两阶段目标检测,box head用来做检测,增加了mask head用来做分割,模型大家都很熟,细节就不再赘述。

自下而上(Bottom-Up)
自下而上的实例分割方法的思路是:首先进行像素级别的语义分割,再通过聚类、度量学习等手段区分不同的实例。

自下而上的工作并不多,通常的做法都是通过Instance Embedding的做法来做。举一篇CVPR2017的文章为例,
论文名称:Semantic Instance Segmentation with a Discriminative Loss Function
参考代码:https://github.com/Wizaron/instance-segmentation-pytorch
这篇论文的实例分割做法是:
(1)语义分割:首先在第一个阶段做了语义分割,得到了所有的物体mask;
(2)像素嵌入:再通过使用一个判别式损失函数来训练网络,网络的优化目标是将图像每个像素投影到 n维特征空间后,同属于一个实例的像素尽量靠近,形成一个 cluster, 每一个实例对应一个 cluster, 不同 cluster则尽量远离;
(3)后处理:最后使用聚类的方法(如mean-shift)来输出不同的实例。

文章的关键在于提出的判别式损失函数,它的组成如下:

(1)拉力。惩罚同一实例中所有元素与其平均值之间的距离。也就是说,获取一个实例的所有像素,并计算平均值。这种拉力会将同一实例中的所有像素点拉近到嵌入空间中的同一个点。简单说,就是减少每一个实例的嵌入方差。
(2)推力。获取所有中心点 (在嵌入空间embedding中,而不是空间中心),然后将它们推得更远。
(3)正则化。中心点不应该离原点太远。
文章的超参数设置和迭代方法还是有比较多的坑,感兴趣的可以去看原文和代码。更多关于Instance Embedding的文章可以看看[1]。
单阶段实例分割
下面就聊聊单阶段实例分割(Single Shot Instance Segmentation),这方面工作其实也是受到了单阶段目标检测研究的影响,因此也有两种思路,一种是受one-stage, anchot-based 检测模型如YOLO,RetinaNet启发,代表作有YOLACT和SOLO;一种是受anchor-free检测模型如 FCOS 启发,代表作有PolarMask和AdaptIS。
目前(2020年1月)来看,单阶段实例分割的精度最高的模型应该是新出的BlendMask(COCO, 41.3),在精度和速度上都超越了Mask R-CNN,已经很接近两阶段模型(SOTA应该是HTC?)了。
YOLACT&YOLACT++ ICCV 2019
原文:https://arxiv.org/abs/1904.02689
代码(官方):https://github.com/dbolya/yolact
YOLACT是我最早看的一篇单阶段实例分割的文章,主要参照了单阶段检测模型RetinaNet,因此把它归类于单阶段的实例分割。YOLACT将实例分割任务拆分成两个并行的子任务:
(1)通过一个Protonet网络, 为每张图片生成 k 个 原型mask
(2)对每个实例,预测k个的线性组合系数(Mask Coefficients)
最后通过线性组合,生成实例mask,在此过程中,网络学会了如何定位不同位置、颜色和语义实例的mask。
具体网络结构如下:

(1)Backbone:Resnet 101+FPN,与RetinaNet相同;
(2)Protonet:接在FPN输出的后面,是一个FCN网络,预测得到针对原图的原型mask
(3)Prediction Head:相比RetinaNet的Head,多了一个Mask Cofficient分支,预测Mask系数,因此输出是4*c+k。

此外,论文中还用到了Fast NMS方法,比原有的NMS速度更快,精度减得不多。
之后,作者又提出了改进版的YOLACT++,改进之处主要有:
(1)参考Mask Scoring RCNN,添加fast mask re-scoring分支,更好地评价实例mask的好坏;
(2)Backbone网络中引入可变形卷积DCN;
(3)优化了Prediction Head中的anchor设计
YOLACT和YOLACT++的实验效果如下:

二、One shot实例分割
论文地址:https://arxiv.org/pdf/1811.11507.pdf
动机
该文聚焦在一个前沿的问题:给一个包含了未知种类多个实体的没训练过的新样本(the query image),如何检测以及分割所有这些实例。这个问题和现实应用密切相关,因为检测/分割的落地场景中不可能有类似MS-COCO或者OpenImages之类数据集包含了非常多的实例,现实任务中的实例是穷举不完的,如何从有限种类和数量的样本中学习到一些知识并推演到新的种类中是很具有挑战和实际意义的。该问题的研究大多还是停留在分类任务上,检测和分割少。
主要亮点:
1.提出siamese Mask R-CNN框架,能够仅给一个样本,就能够较好的检测&分割新的该样本同类实例;
2.构建了一个新的评测标准在MS-COCO。

Different from MRCNN:
正如名字一样,主体框架就是由SiameseNetwork + Mask R-CNN。改进前后的框架比对如下图。

主要的4处不同已经用红色标识,即R、Siamese、Matching、L1。R代表了输入不仅有Query Image还有Reference Image;SiameseNetwork则对两者分别进行encode;Matching是将编码后的2个feature vector进行逐一的匹配;L1则是算diff的手段。具体的匹配流程如下图。

该框架的结果如下:

三、Zero shot实例分割
研究者提出了一个新的任务称之为零样本实例分割(Zero-Shot Instance Segmentation)——ZSI。ZSI的任务要求在训练过程中,只用已经见过并有标注的数据进行训练,但在测试和推理时能够同时分割出见过和没见过的物体实例。
首先用数学语言对该任务进行描述,然后提出了一个方法来解决ZSI的问题。新方法包括零样本检测器(Zero-shot Detector)、Semantic Mask Head、Backgro Aware RPN和Synchronized Background Strategy。实验结果表明,提出的方法不仅在ZSI的任务上效果不错,在零样本检测任务上也取得了比之前已有研究更好的表现。
亮点:(部分采用:https://www.jiqizhixin.com/articles/2021-03-17)
1:针对零样本实例分割任务,提出应对的算法,该算法是基于Backgro Aware的检测-分割框架;
2:定义了零样本分割(ZSI)自己独特的测试基准;
3:测试结果表明在ZSD任务上超越了已有的方法,且在ZSI任务上的结果很有竞争力。

整个零样本实例分割的框架如下图所示。对于一张输入图像来讲,首先要使用骨干网络(backbone),BA-RPN和ROI Align来提取视觉特征和背景的词向量,然后经过Sync-bg模块后分别送入零样本检测器和语义分割头,从而得到实例分割的结果。

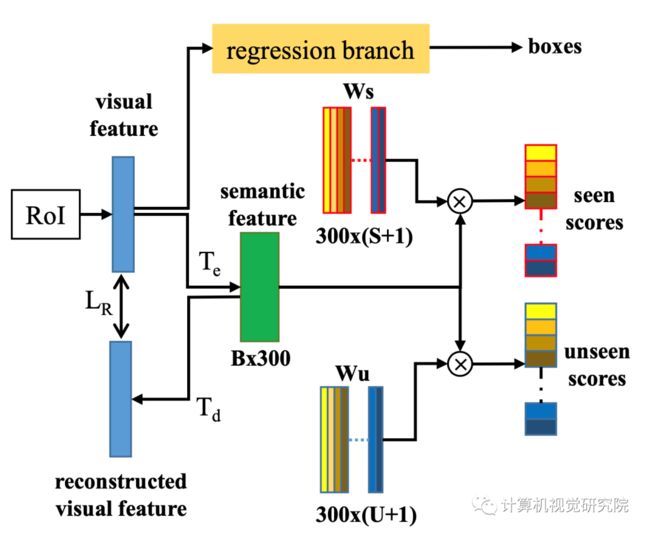
零样本检测器的设计细节如下图所示,采用了编码-解码结构,在测试/推理时只是用解码器的Te。
语义分割头的结构如下图4所示,它是一个encoder-decoder的架构,在训练阶段,使用encoder来把图像的特征编码到语义-文字特征向量。然后使用decoder把上面构建的语义-文字特征向量去重建图像的任务:检测,分割等。

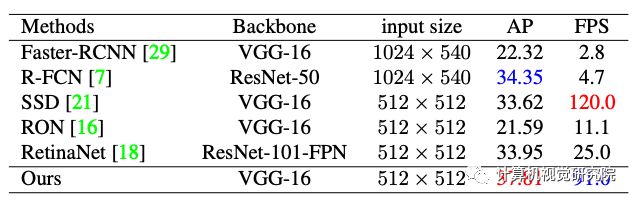
实验:

![]()
计算机视觉研究院学习群等你加入!
计算机视觉研究院主要涉及深度学习领域,主要致力于人脸检测、人脸识别,多目标检测、目标跟踪、图像分割等研究方向。研究院接下来会不断分享最新的论文算法新框架,我们这次改革不同点就是,我们要着重”研究“。之后我们会针对相应领域分享实践过程,让大家真正体会摆脱理论的真实场景,培养爱动手编程爱动脑思考的习惯!

扫码关注
计算机视觉研究院
公众号ID|ComputerVisionGzq
学习群|扫码在主页获取加入方式