网络轻量化 - 泰勒剪枝
原文:《PRUNING CONVOLUTIONAL NEURAL NETWORKS FOR RESOURCE EFFICIENT INFERENCE》
目录
- 算法部分
-
- 通道重要性判断
-
- 通道重要性判断的主流方法
- 本文的通道重要性判断方法 - 一阶泰勒展开
- 与其他标准联合判断
- 对每个通道的重要性进行归一化
- FLOPs 正则化
- 使用迭代式剪枝来降低精度损失
- 代码部分
-
- hook 介绍
-
- register forward hook
- register backward hook
- Hook for Tensor
算法部分
通道重要性判断
通道重要性判断的主流方法
- 权重大小 Minimum weight w w w
- 激活值 Activation
- 互信息 Mutual information
- BN 层缩放系数
本文的通道重要性判断方法 - 一阶泰勒展开
动机:通过用一阶泰勒展开来计算通道对最后 inference 结果的影响,从而判断通道的重要性,大大降低了剪枝过程的计算量

与其他标准联合判断
多种权重重要性判断方法可以通过加权平均的方式进行联合

对每个通道的重要性进行归一化
为了保证跨层的通道可以公平比较(因为不同层的通道数不同),所以要进行归一化。

其中,分子是第 l l l 层,第 k k k 个通道的重要性;分母是整个第 l l l 卷积层的通道重要性的加和。
FLOPs 正则化
来自不同的层的通道,其计算量是不同的。
可以在评判标准中加入 FLOPs 因素来尽量降低计算量,而不只是降低参数量。
![]()
使用迭代式剪枝来降低精度损失
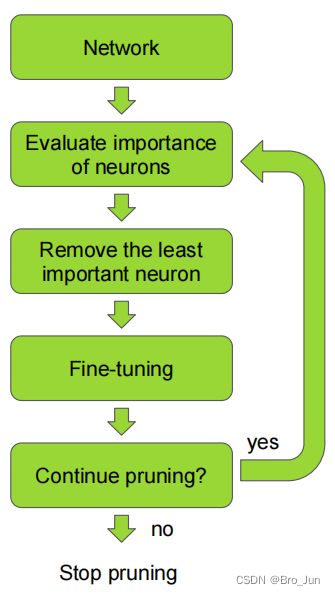
代码部分
仅介绍 hook 的用法
hook 介绍
在 PyTorch 的 computation graph 中,只有 leaf nodes 的变量会保存梯度,而所有中间变量的梯度只被用于反向传播,一旦反向传播完成,中间变量的梯度就会被自动释放,从而节约内存。module 是被封装在神经网络中间,所以很难获取网络中间模块的 input/output 及其 gradient。
针对Module,PyTorch 设计了两种 hook: register_forward_hook 和 register_backward_hook,分别用来获取正/反向传播时,中间层模块输入和输出的 feature/gradient,大大降低了获取模型内部信息流的难度。
针对Tensor,PyTorch 设计了 register_hook。
register forward hook
register_forward_hook的作用是获取前向传播过程中,各个网络模块的输入和输出。
对于模块 module,其使用方式为:
module.register_forward_hook(hook_fn)
其中 hook_fn为:
hook_fn(module, input, output) -> None
例子如下:
from torchvision import models
import torch
import torch.nn as nn
class ModifiedVGG16Model(torch.nn.Module):
def __init__(self):
super(ModifiedVGG16Model, self).__init__()
model = models.vgg16(pretrained=True)
self.features = model.features
## 锁住特征提取层不更新
"""
for param in self.features.parameters():
param.requires_grad = False
"""
self.classifier = nn.Sequential(
nn.Dropout(),
nn.Linear(25088, 4096),
nn.ReLU(inplace=True),
nn.Dropout(),
nn.Linear(4096, 4096),
nn.ReLU(inplace=True),
nn.Linear(4096, 102))
def forward(self, x):
x = self.features(x)
x = x.view(x.size(0), -1)
x = self.classifier(x)
return x
model = ModifiedVGG16Model()
# 构建计算flops的hook函数
def hook(module, inputs, outputs):
params = module.weight.size().numel()
W = outputs.size(2)
H = outputs.size(3)
module.flops = params * W * H
##给模型中的每个卷积层插入hook
for m in model.modules():
if isinstance(m, nn.Conv2d):
m.register_forward_hook(hook)
x = torch.randn(1, 3, 224, 224)
_ = model(x)
total_flops = 0
for m in model.modules():
if isinstance(m, nn.Conv2d):
total_flops += m.flops
print(total_flops)
register backward hook
和 register_forward_hook相似,register_backward_hook 的作用是获取神经网络反向传播过程中,各个模块输入端和输出端的梯度值。
对于模块 module,其使用方式为:
module.register_backward_hook(hook_fn)
其中hook_fn为:
hook_fn(module, grad_input, grad_output) -> Tensor or None
例子如下:
def hook_backward(module, grad_input, grad_output):
print(module)
print(grad_output)
for m in model.modules():
if isinstance(m, nn.Conv2d):
m.register_backward_hook(hook_backward)
x = torch.randn(1, 3, 224, 224)
out = model(x)
loss = out.mean()
loss.backward()
部分终端打印结果:
Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(tensor([[[[ 0.0000e+00, 0.0000e+00, 0.0000e+00, ..., 0.0000e+00,
0.0000e+00, 0.0000e+00],
[ 0.0000e+00, 0.0000e+00, 0.0000e+00, ..., 0.0000e+00,
0.0000e+00, 0.0000e+00],
[ 0.0000e+00, 0.0000e+00, 0.0000e+00, ..., 0.0000e+00,
0.0000e+00, 0.0000e+00],
...,
[ 0.0000e+00, 0.0000e+00, 0.0000e+00, ..., 0.0000e+00,
0.0000e+00, 0.0000e+00],
[ 0.0000e+00, 0.0000e+00, 0.0000e+00, ..., 0.0000e+00,
0.0000e+00, 0.0000e+00],
[ 0.0000e+00, 0.0000e+00, 0.0000e+00, ..., 0.0000e+00,
0.0000e+00, 1.6345e-06]],
[[ 0.0000e+00, 0.0000e+00, 0.0000e+00, ..., 0.0000e+00,
0.0000e+00, 0.0000e+00],
[ 0.0000e+00, 0.0000e+00, 0.0000e+00, ..., 0.0000e+00,
0.0000e+00, 0.0000e+00],
[ 0.0000e+00, 0.0000e+00, 0.0000e+00, ..., 0.0000e+00,
0.0000e+00, 0.0000e+00],
...,
[ 0.0000e+00, 0.0000e+00, 0.0000e+00, ..., 0.0000e+00,
0.0000e+00, 0.0000e+00],
[ 0.0000e+00, 0.0000e+00, 0.0000e+00, ..., 0.0000e+00,
0.0000e+00, 0.0000e+00],
[ 0.0000e+00, 0.0000e+00, 0.0000e+00, ..., 0.0000e+00,
0.0000e+00, 0.0000e+00]],
[[ 0.0000e+00, 0.0000e+00, 0.0000e+00, ..., 0.0000e+00,
0.0000e+00, 0.0000e+00],
[ 0.0000e+00, 0.0000e+00, 0.0000e+00, ..., 0.0000e+00,
0.0000e+00, 0.0000e+00],
[ 0.0000e+00, 0.0000e+00, 0.0000e+00, ..., 0.0000e+00,
0.0000e+00, 0.0000e+00],
...,
[ 0.0000e+00, 0.0000e+00, 0.0000e+00, ..., 0.0000e+00,
0.0000e+00, 0.0000e+00],
[ 0.0000e+00, 0.0000e+00, 0.0000e+00, ..., 0.0000e+00,
0.0000e+00, 0.0000e+00],
[ 0.0000e+00, 0.0000e+00, 0.0000e+00, ..., 0.0000e+00,
0.0000e+00, 0.0000e+00]],
...,
[[ 0.0000e+00, 0.0000e+00, 0.0000e+00, ..., 0.0000e+00,
0.0000e+00, 0.0000e+00],
[ 0.0000e+00, 0.0000e+00, 0.0000e+00, ..., 0.0000e+00,
0.0000e+00, 0.0000e+00],
[ 0.0000e+00, 0.0000e+00, 0.0000e+00, ..., 0.0000e+00,
0.0000e+00, 0.0000e+00],
...,
[ 0.0000e+00, 0.0000e+00, 0.0000e+00, ..., 0.0000e+00,
0.0000e+00, 0.0000e+00],
[ 0.0000e+00, 0.0000e+00, 0.0000e+00, ..., 0.0000e+00,
0.0000e+00, 0.0000e+00],
[ 0.0000e+00, 0.0000e+00, 0.0000e+00, ..., 0.0000e+00,
0.0000e+00, 0.0000e+00]],
[[ 0.0000e+00, 0.0000e+00, 0.0000e+00, ..., 0.0000e+00,
0.0000e+00, 0.0000e+00],
[ 0.0000e+00, 0.0000e+00, 0.0000e+00, ..., 0.0000e+00,
-1.4269e-04, 0.0000e+00],
[ 0.0000e+00, 0.0000e+00, 0.0000e+00, ..., 0.0000e+00,
0.0000e+00, 0.0000e+00],
...,
[ 0.0000e+00, 0.0000e+00, 0.0000e+00, ..., 0.0000e+00,
0.0000e+00, 0.0000e+00],
[ 0.0000e+00, 0.0000e+00, 0.0000e+00, ..., 0.0000e+00,
0.0000e+00, 0.0000e+00],
[ 0.0000e+00, 0.0000e+00, 0.0000e+00, ..., 0.0000e+00,
0.0000e+00, 0.0000e+00]],
[[ 0.0000e+00, 0.0000e+00, 0.0000e+00, ..., 0.0000e+00,
0.0000e+00, 0.0000e+00],
[ 0.0000e+00, 0.0000e+00, 0.0000e+00, ..., 0.0000e+00,
0.0000e+00, 0.0000e+00],
[ 0.0000e+00, 0.0000e+00, 0.0000e+00, ..., 0.0000e+00,
0.0000e+00, 0.0000e+00],
...,
[ 0.0000e+00, 0.0000e+00, 0.0000e+00, ..., 0.0000e+00,
0.0000e+00, 0.0000e+00],
[ 0.0000e+00, 0.0000e+00, 0.0000e+00, ..., 0.0000e+00,
0.0000e+00, 0.0000e+00],
[ 0.0000e+00, 0.0000e+00, 0.0000e+00, ..., 0.0000e+00,
0.0000e+00, 0.0000e+00]]]]),)
Hook for Tensor
对于中间变量 z,hook 的使用方式为:
z.register_hook(hook_fn)
其中 hook_fn为一个用户自定义的函数,为:
hook_fn(grad) -> Tensor or None
例子如下:
x = torch.Tensor([0, 1, 2, 3]).requires_grad_()
y = torch.Tensor([4, 5, 6, 7]).requires_grad_()
w = torch.Tensor([1, 2, 3, 4]).requires_grad_()
z = x+y
# ===================
def hook_fn(grad):
print(grad)
z.register_hook(hook_fn)
# ===================
o = w.matmul(z)
print('=====Start backprop=====')
o.backward()
print('=====End backprop=====')
print('x.grad:', x.grad)
print('y.grad:', y.grad)
print('w.grad:', w.grad)
print('z.grad:', z.grad)
终端输出为:
=====Start backprop=====
tensor([1., 2., 3., 4.])
=====End backprop=====
x.grad: tensor([1., 2., 3., 4.])
y.grad: tensor([1., 2., 3., 4.])
w.grad: tensor([ 4., 6., 8., 10.])
z.grad: None