Attention注意力机制–原理与应用
Attention注意力机制–原理与应用
注意力机制即Attention mechanism在序列学习任务上具有巨大的提升作用,在编解码器框架内,通过在编码段加入A模型,对源数据序列进行数据加权变换,或者在解码端引入A模型,对目标数据进行加权变化,可以有效提高序列对序列的自然方式下的系统表现。
什么是Attention?
Attention模型的基本表述可以这样理解成(我个人理解):当我们人在看一样东西的时候,我们当前时刻关注的一定是我们当前正在看的这样东西的某一地方,换句话说,当我们目光移到别处时,注意力随着目光的移动野在转移,这意味着,当人们注意到某个目标或某个场景时,该目标内部以及该场景内每一处空间位置上的注意力分布是不一样的。这一点在如下情形下同样成立:当我们试图描述一件事情,我们当前时刻说到的单词和句子和正在描述的该事情的对应某个片段最先关,而其他部分随着描述的进行,相关性也在不断地改变。从上述两种情形,读者可以看出,对于Attention的作用角度出发,我们就可以从两个角度来分类Attention种类:空间注意力和时间注意力,即Spatial Attention 和Temporal Attention。这种分类更多的是从应用层面上,而从Attention的作用方法上,可以将其分为Soft Attention和Hard Attention,这既我们所说的,Attention输出的向量分布是一种one-hot的独热分布还是soft的软分布,这直接影响对于上下文信息的选择作用。
为什么要加入Attention?
再解释了Attention做了一件什么事之后,我们讨论一下为什么需要Attention模型,即Attention加入的动机:
- 序列输入时,随着序列的不断增长,原始根据时间步的方式的表现越来越差,这是由于原始的这种时间步模型设计的结构有缺陷,即所有的上下文输入信息都被限制到固定长度,整个模型的能力都同样收到限制,我们暂且把这种原始的模型称为简单的编解码器模型。
- 编解码器的结构无法解释,也就导致了其无法设计。
Attention到底是什么原理?
下面我们来看一下Attention的具体原理:
首先让编码器输出结构化的表示,假设这些表示,可以用下述集合表示,(Hold不住了,我要截图了,太麻烦了!!!)



由于定长上下文特征表示带来的信息损失,同时也是一种缺陷,由于不同的时间片或者空间位置的信息量明显有差别,利用定常表示无法很好的解决损失的问题,而Attention则恰好解决了这个问题。
所以说Attention的作用是?
让我们来看一个具体的例子!
这里直接上一幅图,举个具体的例子,然后咱们慢慢来解释:
让我们来看一下论文里其他研究者都是如何利用AttentionModel的:
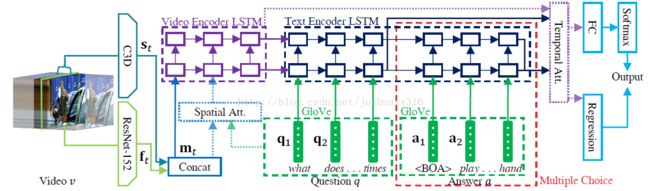
最新一篇CVPR2017年accepted paper关于VQA问题的文章中,作者使用到了基于Spatial和基于Temporal两个层面的Attetion模型,效果肯定提升了不用说,该问题更是极好的利用了这两点,其实这两种应用方式早在MT中得到了利用。

**今天实在太晚了,我要回家睡觉,先写到这,不然又不知道几点睡,不能总熬夜,周五前更新完
**上次说周五前更新完,结果拖了一周了,不过想想也没说哪个周五,啊哈哈哈。这里赶紧补上
上图的两种attention用法都属于soft attention,即通过确定性的得分计算来得到attended之后的编码隐状态,图示来自论文
Jang Y, Song Y, Yu Y, et al. TGIF-QA: Toward Spatio-Temporal Reasoning in Visual Question Answering[J]. arXiv preprint arXiv:1704.04497, 2017.
我们来讨论一下图示中的左边和右边两种attention是如何实现的。
(a)空间注意力 Spatial Attention
