神经网络(paddle)之--------线性神经网络以及python实现
paddle 中可以使用线性网络+卷积层 组成一个卷积神经网络。
这里介绍一下线性网络原理:
线性网络在结构上是与感知器非常的相似,只是其神经元的激活函数不同(网上关于感知器原理有很多,自己学习吧)。
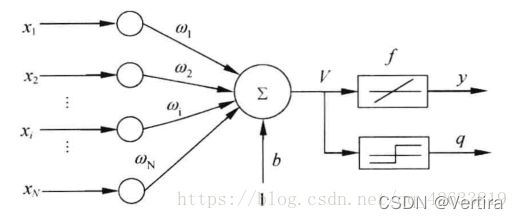
线性网络原理示意图
若网络中包含多个神经元节点,就可形成多个输出,这种神经网络可以用一种间接的方式解决线性不可分的问题,方法是用多个线性含糊对区域进行划分,神经结构和解决异或问题如下图所示:

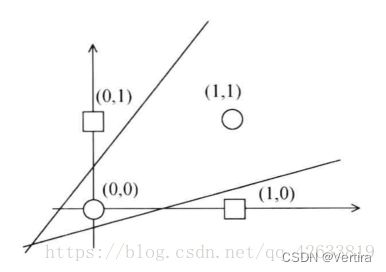
利用线性神经网络解决线性不可分问题的另一个方法是对神经元添加非线性输入,从而引入非线性成分,这样是原本的输入维度变大。如下图所示:

线性神经网络的学习算法就是LMS算法
二 线性神经网络学习的LMS算法(什么是LMS算法,网上搜一下)
定义第n次迭代产生的误差信号是:
![]()
采用均方差作为评价标准:
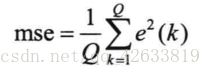
Q是输入训练样本的个数。线性神经网络的学习目标是找到适当的w,是的误差的均方差mse最小,只要将上市穗w求偏导,再令偏导为0,即可求出mse的极值。
调节权值是在斜面上沿着负梯度的方向对权值进行修正,最终到达最佳权值。

LMS算法的步骤:

其中学习率的选择要保证收敛的条件是:

其中R是输入向量x的自相关矩阵
![]()
学习率在学习过程中,随着学习的进行逐渐下降比始终不变要更加合理。学习率的下降公式:

LMS算法的一个缺点是,他对输入向量自相关矩阵R的条件数敏感,当一个矩阵的条件数比较大时,矩阵就成为病态矩阵,这种矩阵中的元素做微笑的改变就可能引起线性方程解的很大变化。
在算法上,LMS算法和感知器学习算法没有什么区别,,但是,在感知器算法中,得到的线基本是在刚刚可以区分的位置上,这样使分类边界离一个类别过近,使得系统对于误差更加敏感;但是LMS算法往往处于两类中间的位置。这一区别与两种神经网络的不同传输函数有关。
三 python实现LMS算法
# -*- coding: utf-8 -*-
"""
Created on Fri Sep 28 21:42:40 2018
@author: Heisenberg
"""
import numpy as np
import matplotlib.pyplot as mpl
a=0.1 ##学习率 0y=-x
即:分类线方程为:y=-x
'''
def sgn(v):
if v>0:
return 1
else:
return 0 ##跟上篇感知器单样本训练的-1比调整成了0,为了测试需要。-1训练不出结果
##读取实际输出
'''
这里是两个向量相乘,对应的数学公式:
a(m,n)*b(p,q)=m*p+n*q
在下面的函数中,当循环中xn=1时(此时W=([0.1,0.1])):
np.dot(W.T,x)=(1,1)*(0.1,0.1)=1*0.1+1*0.1=0.2>0 ==>sgn 返回1
'''
def get_v(W,x):
return sgn(np.dot(W.T,x))##dot表示两个矩阵相乘,求两个向量的点积
##读取误差值
def get_e(W,x,d):
return d-get_v(W,x)
##权重计算函数(批量修正)
'''
对应数学公式: w(n+1)=w(n)+a*x(n)*e
对应下列变量的解释:
w(n+1) <= neww 的返回值
w(n) <=oldw(旧的权重向量)
a <= a(学习率,范围:0神经网络每次读入一个样本,进行修正,
达到预期误差值或者最大尝试次数结束,修正过程结束
'''
cnt=0
while True:
err=0
i=0
for xn in X:
W,e=neww(W,D[i],xn,a)
i+=1
err+=pow(e,2) ##lms算法的核心步骤,即:MES
err/=float(i)
cnt+=1
print("第 %d 次调整后的权值:"%cnt)
print(W)
print("误差:%f"%err)
if err=maxtrycount:
break
print("最后的权值:",W)
##输出结果
print("开始验证结果...")
for xn in X:
print("D%s and W%s =>%d"%(xn,W.T,get_v(W,xn)))
##测试准确性:
print("开始测试...")
test=np.array([1,2,3])
print("D%s and W%s =>%d"%(test,W.T,get_v(W,test)))
test=np.array([1,-3,-5])
print("D%s and W%s =>%d"%(test,W.T,get_v(W,test)))
#输出图像
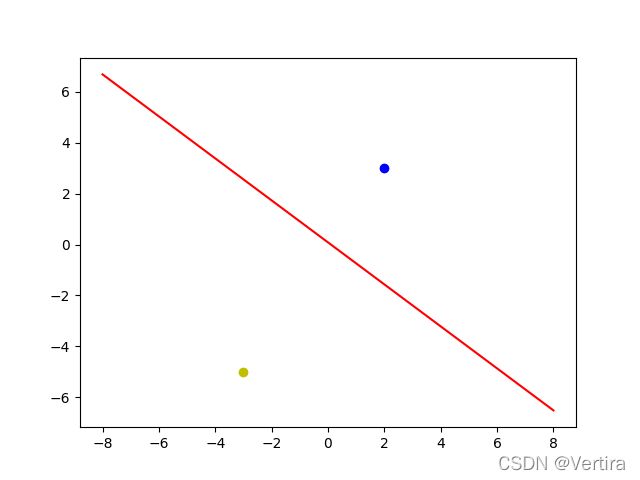
x1 = [2]
y1 = [3]
x2 = [-3]
y2 = [-5]
k=-W[1]/W[2]
d=-W[0]/W[2]
xdata=np.linspace(-8,8) #x轴的刻度划分一个8个刻度
mpl.figure()#调用函数创建一个绘图对象,并且使他成为当前的绘图对象
mpl.plot(xdata,xdata*k+d,'r')# r代表是红色
mpl.plot(x1,y1,'bo') #x1,y1的俩个点用蓝色圆圈标记
mpl.plot(x2,y2,'yo') #黄色标记
mpl.show()
运行结果:
第 1 次调整后的权值:
[-0.04748122 0.47266369 0.57314077]
误差:0.000000
最后的权值: [-0.04748122 0.47266369 0.57314077]
开始验证结果...
D[1 1 1] and W[-0.04748122 0.47266369 0.57314077] =>1
D[1 1 0] and W[-0.04748122 0.47266369 0.57314077] =>1
D[1 0 1] and W[-0.04748122 0.47266369 0.57314077] =>1
D[1 0 0] and W[-0.04748122 0.47266369 0.57314077] =>0
开始测试...
D[1 2 3] and W[-0.04748122 0.47266369 0.57314077] =>1
D[ 1 -3 -5] and W[-0.04748122 0.47266369 0.57314077] =>0
参考:
神经网络学习(2)————线性神经网络以及python实现_就是这个七昂的博客-CSDN博客_python线性神经网络一、线性神经网络结构模型在结构上与感知器非常相似,只是神经元激活函数不同,结构如图所示:若网络中包含多个神经元节点,就可形成多个输出,这种神经网络可以用一种间接的方式解决线性不可分的问题,方法是用多个线性含糊对区域进行划分,神经结构和解决异或问题如图所示: 利用线性神经网络解决线性不可分问题的另一个方法是对神经元添加非线性输入,从而引入非线性成分,这样...https://blog.csdn.net/qq_42633819/article/details/82874840?spm=1001.2101.3001.6650.1&utm_medium=distribute.pc_relevant.none-task-blog-2~default~CTRLIST~default-1.pc_relevant_paycolumn_v2&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2~default~CTRLIST~default-1.pc_relevant_paycolumn_v2&utm_relevant_index=2