YoloV3-SPP NMS源码详解
前言
该文链接至:YOLO-V3-SPP详细解析
本文主要讲解在推理阶段YoloV3-SPP的处理,分以下几点:
- 预处理数据
- 推理的NMS处理
关于map的计算,ultralytic版本的源码调用了pycoco库函数来计算map,因此这里不讲map的计算,感兴趣可以去看看我朋友关于对YOLOV5之MAP计算的博客:【YOLOV5-5.x 源码解读】val.py
源码
Yolo-V3-SPP版本是ultralytics版本,需要较详细的请去github下载
NMS源码
validation.py调用
pred = model(imgs)[0] # only get inference result
pred = non_max_suppression(pred, conf_thres=0.01, iou_thres=0.6, multi_label=False)
predict_test.py调用
# 网络进行正向传播,t为时间差,pred为返回结果
t1 = torch_utils.time_synchronized()
pred = model(img)[0] # only get inference result
t2 = torch_utils.time_synchronized()
print(t2 - t1)
# 非极大值抑制处理
pred = utils.non_max_suppression(pred, conf_thres=0.1, iou_thres=0.6, multi_label=True)[0]
这里pred为model的返回值,返回值的处理参照model.py的处理,这里给出关键部分的代码:
else: # inference 如果是验证或者推理阶段
# io的shpae(batch_size,anchor_num,grid_cell,grid_cell,xywh+obj_confidence+classes_num)
io = p.clone() # inference output
# clone返回一个张量的副本,其与原张量的尺寸和数据类型相同。
# 与copy_()不同,这个函数记录在计算图中。传递到克隆张量的梯度将传播到原始张量
# grid的shape=[batch_size, na, grid_h, grid_w, wh],和io最后一维取前两个xy后的shape一致,进行加法
io[..., :2] = torch.sigmoid(io[..., :2]) + self.grid
# xy 计算在feature map上的xy坐标,对应论文的sigmoid(tx)+cx
# anchor_wh的shape:[batch_size, na, grid_h, grid_w, wh]与io最后一维取第3,4个,即wh后的shape一致,进行乘法
io[..., 2:4] = torch.exp(io[..., 2:4]) * self.anchor_wh # wh yolo method 计算在feature map上的wh
io[..., :4] *= self.stride # xywh换算映射回原图尺度
# obj和类别预测经过sigmoid
torch.sigmoid_(io[..., 4:])
return io.view(bs, -1, self.no), p # view [1, 3, 13, 13, 85] as [1, 507, 85],3X13X13=507
# io的shape(batch_size,...,xywh+obj_confidence+classes_num)
# p的shape是(batch_size,anchor_num,grid_cell,grid_cell,xywh+obj_confidence+classes_num)
NMS源码
def non_max_suppression(prediction, conf_thres=0.1, iou_thres=0.6,
multi_label=True, classes=None, agnostic=False, max_num=100):
"""
Performs Non-Maximum Suppression on inference results
param: prediction[batch, num_anchors X (gird_x X gird_y), (xywh+obj_conf+cls_num)]
Returns detections with shape:
nx6 (x1, y1, x2, y2, conf, cls)
"""
# Settings
merge = False # merge for best mAP
min_wh, max_wh = 2, 4096 # (pixels) minimum and maximum box width and height
time_limit = 10.0 # seconds to quit after
t = time.time()
nc = prediction[0].shape[1] - 5 # number of classes
multi_label &= nc > 1 # multiple labels per box
output = [None] * prediction.shape[0]
for xi, x in enumerate(prediction): # image index, image inference 遍历每张图片
# Apply constraints
x = x[x[:, 4] > conf_thres] # confidence 根据obj confidence虑除背景目标
x = x[((x[:, 2:4] > min_wh) & (x[:, 2:4] < max_wh)).all(1)] # width-height 虑除小目标
# If none remain process next image
if not x.shape[0]:
continue
# Compute conf
x[..., 5:] *= x[..., 4:5] # conf = obj_conf * cls_conf
# Box (center x, center y, width, height) to (x1, y1, x2, y2)
box = xywh2xyxy(x[:, :4])
# Detections matrix nx6 (xyxy, conf, cls)
if multi_label: # 针对每个类别执行非极大值抑制
i, j = (x[:, 5:] > conf_thres).nonzero(as_tuple=False).t()
x = torch.cat((box[i], x[i, j + 5].unsqueeze(1), j.float().unsqueeze(1)), 1)
else: # best class only 直接针对每个类别中概率最大的类别进行非极大值抑制处理
conf, j = x[:, 5:].max(1)
x = torch.cat((box, conf.unsqueeze(1), j.float().unsqueeze(1)), 1)[conf > conf_thres]
# Filter by class
if classes:
x = x[(j.view(-1, 1) == torch.tensor(classes, device=j.device)).any(1)]
# Apply finite constraint
# if not torch.isfinite(x).all():
# x = x[torch.isfinite(x).all(1)]
# If none remain process next image
n = x.shape[0] # number of boxes
if not n:
continue
# Sort by confidence
# x = x[x[:, 4].argsort(descending=True)]
# Batched NMS
c = x[:, 5] * 0 if agnostic else x[:, 5] # classes
boxes, scores = x[:, :4].clone() + c.view(-1, 1) * max_wh, x[:, 4] # boxes (offset by class), scores
i = torchvision.ops.nms(boxes, scores, iou_thres)
i = i[:max_num] # 最多只保留前max_num个目标信息
if merge and (1 < n < 3E3): # Merge NMS (boxes merged using weighted mean)
try: # update boxes as boxes(i,4) = weights(i,n) * boxes(n,4)
iou = box_iou(boxes[i], boxes) > iou_thres # iou matrix
weights = iou * scores[None] # box weights
x[i, :4] = torch.mm(weights, x[:, :4]).float() / weights.sum(1, keepdim=True) # merged boxes
# i = i[iou.sum(1) > 1] # require redundancy
except: # possible CUDA error https://github.com/ultralytics/yolov3/issues/1139
print(x, i, x.shape, i.shape)
pass
output[xi] = x[i]
if (time.time() - t) > time_limit:
break # time limit exceeded
return output
NMS源码解析
回顾NMS
Soft-NMS算法

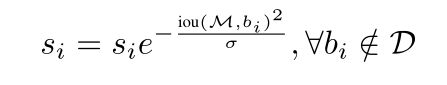
这里的 i o u ( M , b i ) iou(M,b_i) iou(M,bi)采用的是 G i o u Giou Giou
解析
def non_max_suppression(prediction, conf_thres=0.1, iou_thres=0.6,
multi_label=True, classes=None, agnostic=False, max_num=100):
传参:
- prediciton:shape为 ( b a t c h _ s i z e , a n c h o r × g r i d _ x × g r i d _ y , x y w h + o b j _ c o n f + c l s _ n u m ) (batch\_size,anchor\times grid\_x\times grid\_y,xywh+obj\_conf+cls\_num) (batch_size,anchor×grid_x×grid_y,xywh+obj_conf+cls_num)
- conf_thres:置信度和类别阈值
- Iou_thres:iou阈值
- multi_label:多类执行NMS标志位,True表示对每个类别执行NMS,False表示只对类别最大的执行NMS(注:这里不是指多分类和单分类,而仅仅是NMS的处理方式)
- classes:默认为None,作用是控制筛选输出的类别为指定的classes,作为一个特殊的功能扩展,对预测输出时可指定输出指定的类,默认不使用
- agnostic:
- max_num:NMS后最多只保留前max_num个目标信息
# Settings
merge = False # merge for best mAP
min_wh, max_wh = 2, 4096 # (pixels) minimum and maximum box width and height
time_limit = 10.0 # seconds to quit after
Merge后面是用来对经过NMS之后的预测框进行一个权重平衡,这里简单提一下,后面会讲到.
min_wh和max_wh作用:
- 筛选掉大小预测框
- 在nms时,max_wh会对不同类别的预测框进行区分,具体操作后面会详细说明
time_limit限制循环的运行时间不能超过10s
t = time.time()
nc = prediction[0].shape[1] - 5 # number of classes
multi_label &= nc > 1 # multiple labels per box
t = time.time():返回当前时间的时间戳(1970纪元后经过的浮点秒数)。
nc = prediction[0].shape[1] - 5
这里prediction的shape为[batch, num_anchors X (gird_x X gird_y), (xywh+obj_conf+cls_num)]
上述prediction[0].shape[1]即取prediciton最后一维的长度,由于前5个均是(xywh+obj),减去前面的维度即可以得到剩下cls_num的长度,nc表示类数目。
multi_label &= nc > 1
这是与运算&两个式子分别为:multi_label和nc>1,两个布尔值取与&。
output = [None] * prediction.shape[0]
prediction.shape[0]指batch_size个数,output为list,list个数为当前传入的predict的batch_size,如果在预测阶段传入一张图片,那么batch_size=1,那么这时的output为1个list,总之output的list个数为batch_size。
for循环代码的解释
for xi, x in enumerate(prediction): # image index, image inference 遍历每张图片
对于单张图片的nms处理,该循环只会执行一次,而对于验证集处理是一个batch进行nms处理,循环次数为batch_size。
prediciton的shape[batch, num_anchors X (gird_x X gird_y), (xywh+obj_conf+cls_num)]
x的shape为[num_anchors X (gird_x X gird_y), (xywh+obj_conf+cls_num)]
# Apply constraints
x = x[x[:, 4] > conf_thres] # confidence 根据obj confidence虑除背景目标
x = x[((x[:, 2:4] > min_wh) & (x[:, 2:4] < max_wh)).all(1)] # width-height 滤除小目标
x = x[x[:, 4] > conf_thres]
筛选出Obj_conf > conf_thres的预测框
x = x[((x[:, 2:4] > min_wh) & (x[:, 2:4] < max_wh)).all(1)]
筛选出预测框宽高在[min_wh,max_wh]之间的预测框信息
# If none remain process next image
if not x.shape[0]:
continue
x.shape[0]是当前图片筛选出来的预测框数量,如果当前图片经过conf_thres和滤除小目标后得到的预测框为0,那么这张图片不需要nms,continue下一张图片进行nms处理
# Compute conf
x[..., 5:] *= x[..., 4:5] # conf = obj_conf * cls_conf
x[…, 5:]表示cls_conf维度,x[…, 4:5]表示obj_conf
这里回顾下YOLO-V1的论文

每个grid cell预测cls_num个类的条件概率 P r ( C l a s s i ∣ O b j e c t ) Pr(Class_i\mid Object) Pr(Classi∣Object),我们要得到实际类别概率需要
P r ( C l a s s i ) = P r ( C l a s s i ∣ O b j e c t ) ∗ P r ( O b j e c t ) Pr(Class_i)=Pr(Class_i\mid Object)\ast Pr(Object) Pr(Classi)=Pr(Classi∣Object)∗Pr(Object)
实际等价于
P r ( C l a s s i ) = c l s _ c o n f ∗ o b j _ c o n f Pr(Class_i)=cls\_conf\ast obj\_conf Pr(Classi)=cls_conf∗obj_conf
经过上述代码之后,x原处cls_conf的位置的内容从 P r ( C l a s s i ∣ O b j e c t ) Pr(Class_i\mid Object) Pr(Classi∣Object)变为 P r ( C l a s s i ) Pr(Class_i) Pr(Classi)
# Box (center x, center y, width, height) to (x1, y1, x2, y2)
box = xywh2xyxy(x[:, :4])
xywh2xyxy方法如下
def xywh2xyxy(x):
# Convert nx4 boxes from [x, y, w, h] to [x1, y1, x2, y2] where xy1=top-left, xy2=bottom-right
y = torch.zeros_like(x) if isinstance(x, torch.Tensor) else np.zeros_like(x)
y[:, 0] = x[:, 0] - x[:, 2] / 2 # top left x
y[:, 1] = x[:, 1] - x[:, 3] / 2 # top left y
y[:, 2] = x[:, 0] + x[:, 2] / 2 # bottom right x
y[:, 3] = x[:, 1] + x[:, 3] / 2 # bottom right y
return y
将yolo格式的xywh转化为xyxy,赋给box,但不改变x对应为位置的内容
多类NMS前的处理和单类NMS前的处理
多类NMS
# Detections matrix nx6 (xyxy, conf, cls)
if multi_label: # 针对每个类别执行非极大值抑制
i, j = (x[:, 5:] > conf_thres).nonzero(as_tuple=False).t()
x = torch.cat((box[i], x[i, j + 5].unsqueeze(1), j.float().unsqueeze(1)), 1)
else: # best class only 直接针对每个类别中概率最大的类别进行非极大值抑制处理
conf, j = x[:, 5:].max(1)
x = torch.cat((box, conf.unsqueeze(1), j.float().unsqueeze(1)), 1)[conf > conf_thres]
multi_label :多类NMS为true,单类NMS为false。
i, j = (x[:, 5:] > conf_thres).nonzero(as_tuple=False).t()
x[:, 5:] > conf_thres表示将所有预测框的cls_conf和conf_thres进行匹配,如果大于这个阈值,则将该cls_conf设为true,否则设为false,debug详情如下:
![]()
这里Tensor:(1779,2)表示我当前预测图片的预测框有1779个,所需分类为2个
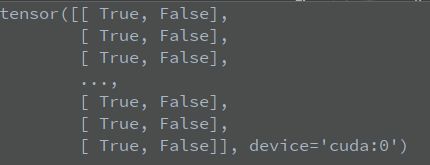
以上是x[:, 5:] > conf_thres的状态
nonzero(as_tuple=False).t()将上述变量的非零值,即True值的矩阵位置内容(预测框id,类别)保存下来,赋给i,j变量(该(i,j)坐标可在x[:, 5:]变量寻址获得大于conf_thres的类别置信度cls_conf,形象地说,寻址的tensor为(预测框id个数,类别),其中i表示预测框id,j表示类别)
注意:i表示的预测框id个数中可能预测框来自同一个id,但是类别不同,表示该预测框的两个类别置信度都>conf_thres
x = torch.cat((box[i], x[i, j + 5].unsqueeze(1), j.float().unsqueeze(1)), 1)
box[i]表示预测框i,状态如下:
![]()
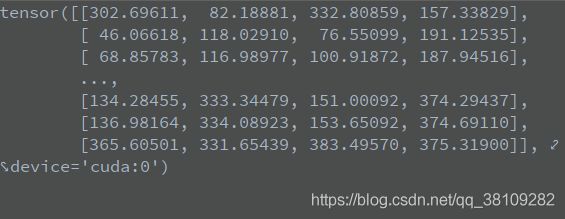
x[i, j + 5].unsqueeze(1)表示对x在第2个维度进行扩展一个维度,原来的shape是[预测框数量,xywh+obj+cls_num]
x[i, j + 5]的状态如下:
![]()
经过unsqueeze(1)后,状态如下:
![]()
j.float().unsqueeze(1)将类别转化为浮点类型,并且在位置的维度升维,状态如下:
![]()
将上述三个变量在第2个维度上拼接,得到的x的状态如下:
![]()
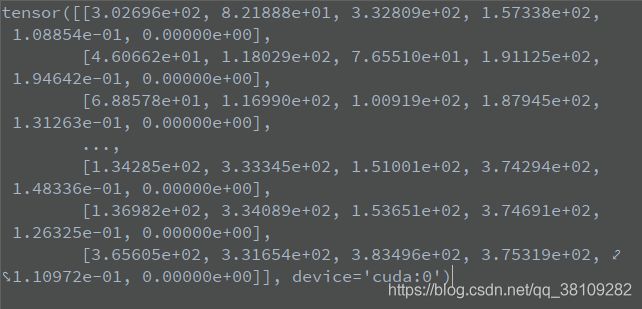
其中选取x[0]=[3.02696e+02, 8.21888e+01, 3.32809e+02, 1.57338e+02, 1.08854e-01, 0.00000e+00]
有6个数值,前四个参数表示 ( x l e f t − t o p , y l e f t − t o p , x r i g h t − t o p , y r i g h t − t o p ) (x_{left-top},y_{left-top},x_{right-top},y_{right-top}) (xleft−top,yleft−top,xright−top,yright−top),后两个参数表示 ( c l s _ c o n f , j . f l o a t ( ) ) (cls\_conf,j.float()) (cls_conf,j.float())
单类NMS
else: # best class only 直接针对每个类别中概率最大的类别进行非极大值抑制处理
conf, j = x[:, 5:].max(1)
x = torch.cat((box, conf.unsqueeze(1), j.float().unsqueeze(1)), 1)[conf > conf_thres]
max(1)表示取x[:, 5:]的类别维度的最大值,返回其中最大的cls_conf及所表示的类别j
torch.cat同多类NMS处理相同
多类NMS和单类NMS的区别
上面两个部分都是在NMS前进行筛选的操作,为了形象说明,我做的实验是分两类,那么我将定义筛选前变量为 ( b o x _ i d , c l s _ c o n f 1 , c l s _ c o n f 2 ) (box\_id,cls\_conf1,cls\_conf2) (box_id,cls_conf1,cls_conf2)
多类NMS:只要该预测框预测的预测类别 c l s _ c o n f 1 cls\_conf1 cls_conf1和 c l s _ c o n f 2 cls\_conf2 cls_conf2置信度大于conf_thres,那么该预测类别将会保存下来,最后筛选得到 ( b o x _ i d , c l s _ c o n f 1 ) (box\_id,cls\_conf1) (box_id,cls_conf1)和 ( b o x _ i d , c l s _ c o n f 2 ) (box\_id,cls\_conf2) (box_id,cls_conf2)
这里注意,对于筛选到的预测框中,含有不同的 c l s _ c o n f 1 cls\_conf1 cls_conf1和 c l s _ c o n f 2 cls\_conf2 cls_conf2的预测框可能是同一个 b o x _ i d box\_id box_id,它们都可能会送进NMS处理.由于这个预测框是同一个预测框,只是预测了 c l s _ c o n f 1 cls\_conf1 cls_conf1和 c l s _ c o n f 2 cls\_conf2 cls_conf2,在进行NMS时,表示同一个预测框,预测不同类的两个target的IOU是完全重叠的。从这同一个框的两个target来分析哪个框会得到保留,对于NMS原理可知,假设是soft-NMS原理,那么至少会有一个框得到保留,最极端的情况就是当这同一预测框的两个target具有相同的 c l s _ c o n f cls\_conf cls_conf,那么这两框可能都会被保留。
单类NMS:预测框只筛选出其中一个类别的target,筛选条件为 m a x ( c l s _ c o n f 1 , c l s _ c o n f 2 ) max(cls\_conf1,cls\_conf2) max(cls_conf1,cls_conf2),注意单类NMS不需要经过conf_thres筛选,只取最大类别置信度的预测框,那么所有的预测框都会被筛选上,并且一个预测框对应一个target。
classes参数的作用
# Filter by class
if classes:
x = x[(j.view(-1, 1) == torch.tensor(classes, device=j.device)).any(1)]
我的实验classes设为None,意味着上述代码并没有执行,其中的意思:
classes参数说明讲得很清楚了
j的状态是:
![]()
j.view(-1,1)的状态是:
![]()
classes是一个list或者nparrary,定义为指定的类别list,控制NMS指对指定的类别进行NMS,抛弃其他类别,输出指定的类别预测或验证,估计预测时使用较多,作为一个功能扩展,默认不使用.
# If none remain process next image
n = x.shape[0] # number of boxes
if not n:
continue
经过上述代码的类阈值筛选之后,判断x是否还能继续NMS
agnostic参数的作用
# Batched NMS
c = x[:, 5] * 0 if agnostic else x[:, 5] # classes
agnostic默认使用false,c的参数为tensor(预测框id,)
x的shape为 ( x l e f t − t o p , y l e f t − t o p , x r i g h t − t o p , y r i g h t − t o p , c l s _ c o n f , j . f l o a t ( ) ) (x_{left-top},y_{left-top},x_{right-top},y_{right-top},cls\_conf,j.float()) (xleft−top,yleft−top,xright−top,yright−top,cls_conf,j.float())
x[:, 5]表示第6个参数的信息j.float(),即表示类别
c的状态为:
![]()
agnostic为True会使获得的类别变量c全为第一类,若为false则c获取的是所有预测框id对应的类
该变量的具体作用未知,由于未用到,还不清楚具体的作用。
boxes, scores = x[:, :4].clone() + c.view(-1, 1) * max_wh, x[:, 4]
x[:, :4]表示 ( x l e f t − t o p , y l e f t − t o p , x r i g h t − t o p , y r i g h t − t o p ) (x_{left-top},y_{left-top},x_{right-top},y_{right-top}) (xleft−top,yleft−top,xright−top,yright−top)信息
c.view(-1, 1)的状态为:
![]()
max_wh为4096
对于agnostic为fasle时,max_wh能将c中非0类的坐标信息 ( x l e f t − t o p , y l e f t − t o p , x r i g h t − t o p , y r i g h t − t o p ) (x_{left-top},y_{left-top},x_{right-top},y_{right-top}) (xleft−top,yleft−top,xright−top,yright−top)乘以max_wh。
在进行nms时,会区分boxes坐标
当agnostic为True时,c的值将会全为0,boxes信息将不会区分不同类的坐标信息,对所有类进行NMS操作.
以上agnostic参数的具体实现在于对boxes不同类nms的处理
boxes不同类区分坐标信息,分类进行NMS操作
boxes = x[:, :4].clone() + c.view(-1, 1) * max_wh,这里将不同类别的坐标以max_wh倍数进行区分,具体作用请看如下debug,我的0类的boxes信息debug如下:
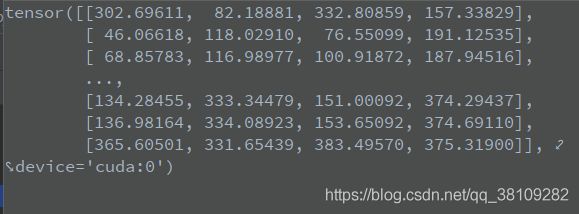

经过区分,不同类的boxes信息的iou是0,那么nms只会对同类预测框操作。
scores为x的第5个参数,即cls_conf,类置信度
i = torchvision.ops.nms(boxes, scores, iou_thres)
i = i[:max_num] # 最多只保留前max_num个目标信息
调用torchvision自带的nms库函数,采用giou来进行NMS
merge参数的作用
if merge and (1 < n < 3E3): # Merge NMS (boxes merged using weighted mean)
try: # update boxes as boxes(i,4) = weights(i,n) * boxes(n,4)
iou = box_iou(boxes[i], boxes) > iou_thres # iou matrix
weights = iou * scores[None] # box weights
x[i, :4] = torch.mm(weights, x[:, :4]).float() / weights.sum(1, keepdim=True) # merged boxes
# i = i[iou.sum(1) > 1] # require redundancy
except: # possible CUDA error https://github.com/ultralytics/yolov3/issues/1139
print(x, i, x.shape, i.shape)
pass
merge参数默认为false:
如果为true,将会给筛选的boundingbox以一定权重分配宽高,权重分配以当前筛选的box信息和总的box信息进行iou计算,将iou>Iou_thres的box保存下来,将当前最佳框的宽高以如下公式更新:
b o x i = 0 [ x 1 , y 1 , x 2 , y 2 ] = ∑ i = 1 t a r g e t c l s i [ x 1 _ i , y 1 _ i , x 2 _ i , y 2 _ i ] ∑ i = 1 t a r g e t c l s i box_{i=0}[x_1,y_1,x_2,y_2]=\frac{\sum_{i=1}^{target}cls_i[x_{1\_i},y_{1\_i},x_{2\_i},y_{2\_i}]}{\sum_{i=1}^{target}cls_i} boxi=0[x1,y1,x2,y2]=∑i=1targetclsi∑i=1targetclsi[x1_i,y1_i,x2_i,y2_i]
其中, i = 0 i=0 i=0表示 c l s _ c o n f cls\_conf cls_conf最高的一个box, i = 1 i=1 i=1到 t a r g e t target target个boxes均是与 b o x m a x _ c o n f box_{max\_conf} boxmax_conf的iou>iou_thres筛选得到的box
这里的代码如果看不懂,可以看这个版本的代码:
原文:nms源码解读
elif method == 'merge': # weighted mixture box
while len(dc): # dc是按置信度排好序的box信息
if len(dc) == 1:
det_max.append(dc)
break
i = bbox_iou(dc[0], dc) > nms_thres # i = True/False的集合
weights = dc[i, 4:5] # 根据i,保留所有True
dc[0, :4] = (weights * dc[i, :4]).sum(0) / weights.sum() # 重叠框位置信息求解平均值
det_max.append(dc[:1])
dc = dc[i == 0]
关于NMS中的具体操作是比较简单的,主要复杂的是NMS前的一些处理.以上代码的NMS是调包使用,具体源码实现我不太清楚,这里给出几个版本的NMS实现,hard-nms,hard-nms-and,soft-nms,diou-nms,原文:nms源码解读
# 推理时间:0.0030s
elif method == 'soft_nms': # soft-NMS https://arxiv.org/abs/1704.04503
sigma = 0.5 # soft-nms sigma parameter
while len(dc):
# if len(dc) == 1: 这是U版的源码 我做了个小改动
# det_max.append(dc)
# break
# det_max.append(dc[:1])
det_max.append(dc[:1]) # append dc的第一行 即target
if len(dc) == 1:
break
iou = bbox_iou(dc[0], dc[1:]) # 计算target与其他框的iou
# 这里和上面的直接置0不同,置0不需要管维度
dc = dc[1:] # dc=target往后的所有预测框
# dc必须不包括target及其前的预测框,因为还要和值相乘, 维度上必须相同
dc[:, 4] *= torch.exp(-iou ** 2 / sigma) # 得分衰减
dc = dc[dc[:, 4] > conf_thres]
# 推理时间:0.00299
elif method == 'diou_nms': # DIoU NMS https://arxiv.org/pdf/1911.08287.pdf
while dc.shape[0]: # dc.shape[0]: 当前class的预测框数量
det_max.append(dc[:1]) # 让score最大的一个预测框(排序后的第一个)为target
if len(dc) == 1: # 出口 dc中只剩下一个框时,break
break
# dc[0] :target dc[1:] :其他预测框
diou = bbox_iou(dc[0], dc[1:], DIoU=True) # 计算 diou
dc = dc[1:][diou < nms_thres] # remove dious > threshold 保留True 删去False