paddle学习笔记:图像分割
paddle构建图像分割的一些深度学习模型
- 图像分割
- FCN
- Unet
- PSPnet
- DeepLab系列
- 总结
- 参考论文
图像分割
图像分割一直是图像处理中比较热门的话题。从最以前的传统算法到现在比较流行的深度学习方法,归根到底,就是我们需要对图像不同的区域进行划分。而划分的依据就是根据图像上的像素点数值的差异进行划分,传统算法是通过建立一个模型去提取差异,而深度学习就是通过卷积,池化等一系列操作将图像的特征图(feature map)提取出来,然后通过对特征图进行处理,就可以对其进行分类。
FCN
前面,我们大概叙述了下深度学习图像分割的原理。深度学习是现在用途非常广的方法,主要原因是深度学习可以让实验结果达到一个很好的效果,且容易上手。比较经典的深度学习网络有VGG,GoogleNet,ResNet等等。但这里,我们不讨论深度学习的发展历程,直接了解在图像分割领域里具有开创性的网络模型,首先是2015年提出的全卷积神经网络(FCN)。
FCN最大的特点就是它将以前神经网络里的线性层去掉了,而且它对特征图进行了上采样,恢复到原来的图像大小,使得输入图像和输出图像大小一致,然后再对图像进行分类。FCN在处理图像时,还做了很多细节的工作,它可以接受任意大小的图像,同时为了达到一定的分割精度,它将高层的特征信息与低层的特征信息进行融合,达到最好分割效果的是FCN8s。我们可以看下它的网络结构图

从图上就可以很清楚的明白它的网络结构了,接下来附上FCN8s的paddle代码(这里依据百度课程上老师代码所写,由于是讲解,写的比较繁琐)
# 导入一些库
import numpy as np
import paddle.fluid as fluid
from paddle.fluid.dygraph import Conv2D, Conv2DTranspose, Dropout, Pool2D, to_variable
from vgg import VGG16BN #导入VGG16作为backbone
class FCN8s(fluid.dygraph.Layer):
# TODO: create fcn8s model
def __init__(self, num_classes=59):
super(FCN8s, self).__init__()
backbone = VGG16BN(pretrained=False)
self.layer1 = backbone.layer1
self.layer1[0].conv._padding = [100, 100]
self.pool1 = Pool2D(pool_size=2, pool_stride=2, ceil_mode=True)
self.layer2 = backbone.layer2
self.pool2 = Pool2D(pool_size=2, pool_stride=2, ceil_mode=True)
self.layer3 = backbone.layer3
self.pool3 = Pool2D(pool_size=2, pool_stride=2, ceil_mode=True)
self.layer4 = backbone.layer4
self.pool4 = Pool2D(pool_size=2, pool_stride=2, ceil_mode=True)
self.layer5 = backbone.layer5
self.pool5 = Pool2D(pool_size=2, pool_stride=2, ceil_mode=True)
self.fc6 = Conv2D(num_channels=512, num_filters=4096, filter_size=7, act='relu')
self.fc7 = Conv2D(num_channels=4096, num_filters=4096, filter_size=1, act='relu')
self.drop = Dropout()
self.score = Conv2D(num_channels=4096, num_filters=num_classes, filter_size=1)
self.score_pool3 = Conv2D(num_channels=256, num_filters=num_classes, filter_size=1)
self.score_pool4 = Conv2D(num_channels=512, num_filters=num_classes, filter_size=1)
self.up_output = Conv2DTranspose(num_channels=num_classes, num_filters=num_classes,
filter_size=4, stride=2, bias_attr=False)
self.up_pool4 = Conv2DTranspose(num_channels=num_classes, num_filters=num_classes,
filter_size=4, stride=2, bias_attr=False)
self.up_final = Conv2DTranspose(num_channels=num_classes, num_filters=num_classes,
filter_size=16, stride=8, bias_attr=False)
def forward(self, inputs):
x = self.layer1(inputs)
x = self.pool1(x) # 1/2
x = self.layer2(x)
x = self.pool2(x) # 1/4
x = self.layer3(x)
x = self.pool3(x) # 1/8
pool3 = x
x = self.layer4(x)
x = self.pool4(x) # 1/16
pool4 = x
x = self.layer5(x)
x = self.pool5(x) # 1/32
x = self.fc6(x)
x = self.drop(x)
x = self.fc7(x)
x = self.drop(x)
x = self.score(x)
x = self.up_output(x)
up_output = x # 1/16
x = self.score_pool4(pool4)
x = x[:, :, 5:5+up_output.shape[2], 5:5+up_output.shape[3]]
up_pool4 = x
x = up_pool4 + up_output
x = self.up_pool4(x)
up_pool4 = x
x = self.score_pool3(pool3)
x = x[:, :, 9:9+up_pool4.shape[2], 9:9+up_pool4.shape[3]]
up_pool3 = x # 1/8
x = up_pool3 + up_pool4
x = self.up_final(x)
x = x[:, :, 31:31+inputs.shape[2], 31:31+inputs.shape[3]]
return x
# 测试网络结构
with fluid.dygraph.guard():
x_data = np.random.rand(2, 3, 512, 512).astype(np.float32)
x = to_variable(x_data)
model = FCN8s(num_classes=59)
pred = model(x)
print(pred.shape)
Unet
Unet是从医学影像的角度出发的,作者通过它获得了2015年ISBI challenge的冠军。Unet的工作主要在两个方面:
1.Unet通过对数据增强来扩充可使用的带标注的医学样本(医学样本通常都很小)。
2.Unet是捕获了上下文的收缩路径,采用精确定位的对称网络结构。
Unet的结构十分简单,处理图像十分快,而且对医学影像精度很高,这使得Unet被广泛应用。我们还是先看下Unet的结构图:
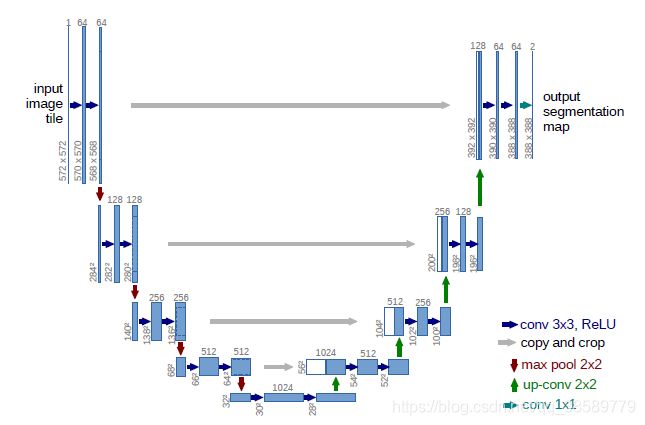
从图上看,Unet的最大特点就是中间层的输出结果需要拼接到上采样过程中。这里需要注意拼接与FCN的融合是不等价的,这里是按照通道数直接拼接,而FCN的融合有很多形式。
这里也同样附上paddle的代码
import numpy as np
import paddle
import paddle.fluid as fluid
from paddle.fluid.dygraph import to_variable, Layer, Conv2D, BatchNorm, Pool2D, Conv2DTranspose
class Encoder(Layer):
def __init__(self, num_channels, num_filters):
super(Encoder, self).__init__()
#TODO: encoder contains:
# 1 3x3conv + 1bn + relu +
# 1 3x3conc + 1bn + relu +
# 1 2x2 pool
# return features before and after pool
self.conv1 = Conv2D(num_channels, num_filters, filter_size=3, padding=1)
self.bn1 = BatchNorm(num_filters, act='relu')
self.conv2 = Conv2D(num_filters, num_filters, filter_size=3, padding=1)
self.bn2 = BatchNorm(num_filters, act='relu')
self.pool = Pool2D(pool_size=2, pool_stride=2, pool_type='max', ceil_mode=True)
def forward(self, inputs):
# TODO: finish inference part
x = self.conv1(inputs)
x = self.bn1(x)
x = self.conv2(x)
x = self.bn2(x)
x_pooled = self.pool(x)
return x, x_pooled
class Decoder(Layer):
def __init__(self, num_channels, num_filters):
super(Decoder, self).__init__()
# TODO: decoder contains:
# 1 2x2 transpose conv (makes feature map 2x larger)
# 1 3x3 conv + 1bn + 1relu +
# 1 3x3 conv + 1bn + 1relu
self.up = Conv2DTranspose(num_channels, num_filters, filter_size=2, stride=2)
self.conv1 = Conv2D(num_channels, num_filters, filter_size=3, padding=1)
self.bn1 = BatchNorm(num_filters, act='relu')
self.conv2 = Conv2D(num_filters, num_filters, filter_size=3, padding=1)
self.bn2 = BatchNorm(num_filters, act='relu')
def forward(self, inputs_prev, inputs):
# TODO: forward contains an Pad2d and Concat
x = self.up(inputs)
h_diff = (inputs_prev.shape[2] - x.shape[3])
w_diff = (inputs_prev.shape[3] - x.shape[3])
x = fluid.layers.pad2d(x, paddings=[h_diff//2, h_diff - h_diff//2, w_diff//2, w_diff - w_diff//2])
x = fluid.layers.concat([inputs_prev, x], axis=1)
x = self.conv1(x)
x = self.bn1(x)
x = self.conv2(x)
x = self.bn2(x)
return x
class UNet(Layer):
def __init__(self, num_classes=59):
super(UNet, self).__init__()
# encoder: 3->64->128->256->512
# mid: 512->1024->1024
#TODO: 4 encoders, 4 decoders, and mid layers contains 2 1x1conv+bn+relu
self.down1 = Encoder(num_channels=3, num_filters=64)
self.down2 = Encoder(num_channels=64, num_filters=128)
self.down3 = Encoder(num_channels=128, num_filters=256)
self.down4 = Encoder(num_channels=256, num_filters=512)
self.mid_conv1 = Conv2D(num_channels=512, num_filters=1024, filter_size=1)
self.mid_bn1 = BatchNorm(1024, act='relu')
self.mid_conv2 = Conv2D(1024, 1024, filter_size=1)
self.mid_bn2 = BatchNorm(1024, act='relu')
self.up4 = Decoder(1024, 512)
self.up3 = Decoder(512, 256)
self.up2 = Decoder(256, 128)
self.up1 = Decoder(128, 64)
self.last_conv = Conv2D(64, num_classes, filter_size=1)
def forward(self, inputs):
x1, x = self.down1(inputs)
print(x1.shape, x.shape)
x2, x = self.down2(x)
print(x2.shape, x.shape)
x3, x = self.down3(x)
print(x3.shape, x.shape)
x4, x = self.down4(x)
print(x4.shape, x.shape)
# middle layers
x = self.mid_conv1(x)
x = self.mid_bn1(x)
x = self.mid_conv2(x)
x = self.mid_bn2(x)
print(x4.shape, x.shape)
x = self.up4(x4, x)
print(x3.shape, x.shape)
x = self.up3(x3, x)
print(x2.shape, x.shape)
x = self.up2(x2, x)
print(x1.shape, x.shape)
x = self.up1(x1, x)
print(x.shape)
x = self.last_conv(x)
return x
# 测试网络
with fluid.dygraph.guard(fluid.CUDAPlace(0)):
model = UNet(num_classes=59)
x_data = np.random.rand(1, 3, 123, 123).astype(np.float32)
inputs = to_variable(x_data)
pred = model(inputs)
print(pred.shape)
PSPnet
PSPnet的工作主要是提出了Global Pyramid Pooling,通过这步操作将不同区域的上下文聚合成全局上下文信息。具体来说,就是它将特征图缩放到几个不同的尺寸,使得特征具有全局和多尺度信息,这一点在准确率提升上上非常有用。它的网络结构图如下

具体的代码如下:
import numpy as np
import paddle.fluid as fluid
from paddle.fluid.dygraph import to_variable, Layer, Conv2D, BatchNorm, Dropout
from resnet_dilated import ResNet50 #导入残差网络
# pool with different bin_size
# interpolate back to input size
# concat
class PSPModule(Layer):
def __init__(self, num_channels, bin_size_list):
super(PSPModule, self).__init__()
self.bin_size_list = bin_size_list
num_filters = num_channels // len(bin_size_list)
self.features = []
for i in range(len(bin_size_list)):
self.features.append(
fluid.dygraph.Sequential(
Conv2D(num_channels=num_channels, num_filters=num_filters, filter_size=1),
BatchNorm(num_channels=num_filters, act='relu')))
def forward(self, inputs):
out = [inputs]
for idx, f in enumerate(self.features):
x = fluid.layers.adaptive_pool2d(input=inputs, pool_size=self.bin_size_list[idx])
x = f(x)
x = fluid.layers.interpolate(x, inputs.shape[2::], align_corners=True)
out.append(x)
# out is list
out = fluid.layers.concat(out, axis=1) #NxCxHxW
return out
class PSPNet(Layer):
def __init__(self, num_classes=59, backbone='resnet50'):
super(PSPNet, self).__init__()
res = ResNet50(pretrained=False)
# stem: res.conv, res.pool2d_max
self.layer0 = fluid.dygraph.Sequential(
res.conv,
res.pool2d_max
)
self.layer1 = res.layer1
self.layer2 = res.layer2
self.layer3 = res.layer3
self.layer4 = res.layer4
num_channels = 2048
# psp: 2048 -> 2048*2
self.pspmodule = PSPModule(num_channels, [1, 2, 3, 6])
num_channels *= 2
# cls: 2048*2 -> 512 -> num_classes
self.classifier = fluid.dygraph.Sequential(
Conv2D(num_channels=num_channels, num_filters=512, filter_size=3, padding=1),
BatchNorm(num_channels=512, act='relu'),
Dropout(0.1),
Conv2D(num_channels=512, num_filters=num_classes, filter_size=1)
)
# aux: 1024 -> 256 -> num_classes
def forward(self, inputs):
x = self.layer0(inputs)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.pspmodule(x)
x = self.classifier(x)
x = fluid.layers.interpolate(x, inputs.shape[2::], align_corners=True)
return x
# 测试
with fluid.dygraph.guard(fluid.CPUPlace()):
x_data=np.random.rand(2,3, 473, 473).astype(np.float32)
x = to_variable(x_data)
model = PSPNet(num_classes=59)
pred = model(x)
print(pred.shape)
DeepLab系列
DeepLab v1提出了一种新的卷积——空洞卷积,因为该作者希望特征图可以扩大它的感受野,而又不希望引入多余的数据产生不必要的信息。DeepLab v2采用了atrous spatial pyramid pooling(ASPP)进行多尺度分割,还将前面backbone的网络替换成残差网络。DeepLab v3改进了ASPP模块,backbone里的残差网络也进行了修改。DeepLab v3+采用Xception作为backbone,并且将ASPP用ASPP+decoder去替换。需要注意的是,v1和v2都采用了全连接条件随机场(Fully-connect CRF),为了提高定位性能。后来v3和v3+发现不加这个也不影响效果,故后面的就没加。具体的区别见下表

这里,我们主要实现DeepLab v3,先给出论文中的网络结构图
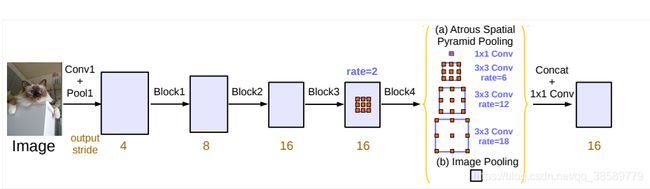
具体的代码实现如下:
import numpy as np
import paddle.fluid as fluid
from paddle.fluid.dygraph import to_variable, Layer, Conv2D, BatchNorm, Dropout
from resnet_multi_grid import ResNet50 # 导入残差网络
class ASPPPooling(Layer):
def __init__(self, num_channels, num_filters):
super(ASPPPooling, self).__init__()
self.features = fluid.dygraph.Sequential(
Conv2D(num_channels, num_filters, 1),
BatchNorm(num_filters, act='relu')
)
def forward(self, inputs):
n, c, h, w = inputs.shape
x = fluid.layers.adaptive_pool2d(inputs, 1)
x = self.features(x)
x = fluid.layers.interpolate(x, (h,w), align_corners=False)
return x
class ASPPConv(fluid.dygraph.Sequential):
# TODO:
def __init__(self, num_channels, num_filters, dilation):
super(ASPPConv, self).__init__(
Conv2D(num_channels, num_filters, filter_size=3, padding=dilation, dilation=dilation),
BatchNorm(num_filters, act='relu'))
class ASPPModule(Layer):
# TODO:
def __init__(self, num_channels, num_filters, rates):
super(ASPPModule, self).__init__()
self.features = []
self.features.append(fluid.dygraph.Sequential(
Conv2D(num_channels, num_filters, 1),
BatchNorm(num_filters, act='relu')
)
)
self.features.append(ASPPPooling(num_channels, num_filters))
for r in rates:
self.features.append(
ASPPConv(num_channels, num_filters, r)
)
self.project = fluid.dygraph.Sequential(
Conv2D(num_filters*(2 + len(rates)), num_filters, 1),
BatchNorm(num_filters, act='relu'))
def forward(self, inputs):
res = []
for op in self.features:
res.append(op(inputs))
x = fluid.layers.concat(res, axis=1)
x = self.project(x)
return x
class DeepLabHead(fluid.dygraph.Sequential):
def __init__(self, num_channels, num_classes):
super(DeepLabHead, self).__init__(
ASPPModule(num_channels, 256, [12, 24, 36]),
Conv2D(256, 256, 3, padding=1),
BatchNorm(256, act='relu'),
Conv2D(256, num_classes, 1)
)
class DeepLab(Layer):
# TODO:
def __init__(self, num_classes=59):
super(DeepLab, self).__init__()
resnet = ResNet50(pretrained=False)
self.layer0 = fluid.dygraph.Sequential(
resnet.conv,
resnet.pool2d_max)
self.layer1 = resnet.layer1
self.layer2 = resnet.layer2
self.layer3 = resnet.layer3
self.layer4 = resnet.layer4
# multigrid
self.layer5 = resnet.layer5
self.layer6 = resnet.layer6
self.layer7 = resnet.layer7
feature_dim = 2048
self.classifier = DeepLabHead(feature_dim, num_classes)
def forward(self, inputs):
n, c, h, w = inputs.shape
x = self.layer0(inputs)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.layer5(x)
x = self.layer6(x)
x = self.layer7(x)
x = self.classifier(x)
x = fluid.layers.interpolate(x, (h,w), align_corners=False)
return x
# 测试
with fluid.dygraph.guard():
x_data = np.random.rand(2, 3, 512, 512).astype(np.float32)
x = to_variable(x_data)
model = DeepLab(num_classes=59)
pred = model(x)
print(pred.shape)
总结
这里是这几天从百度上学习的paddle课程, 课程地址
还有一些我个人感觉比较有意思的论文,等我将论文的代码实现了,后续会放上来。后面会附上这些模型的论文题目,感兴趣的可以去看看。
参考论文
FCN:Fully Convolutional Networks for Semantic Segmentation
Unet:U-Net: Convolutional Networks for Biomedical Image Segmentation
PSPnet:Pyramid Scene Parsing Network
DeepLab v1: Semantic image segmentation with deep convolutional nets and fully connected CRFs
DeepLab v2: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs
DeepLab v3: Rethinking Atrous Convolution for Semantic Image Segmentation
DeepLab v3+: Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation