【Deep Learning A情感文本分类实战】2023 Pytorch+Bert、Roberta+TextCNN、BiLstm、Lstm等实现IMDB情感文本分类完整项目(项目已开源)

作者最近在看了大量论文的源代码后,被它们干净利索的代码风格深深吸引,因此也想做一个结构比较规范而且内容较为经典的任务
本项目使用Pytorch框架,使用上游语言模型+下游网络模型的结构实现IMDB情感分析
语言模型可选择Bert、Roberta
神经网络模型可选择BiLstm、LSTM、TextCNN、Rnn、Gru、FNN共6种
语言模型和网络模型扩展性较好
最终的准确率均在90%以上
一、Introduction
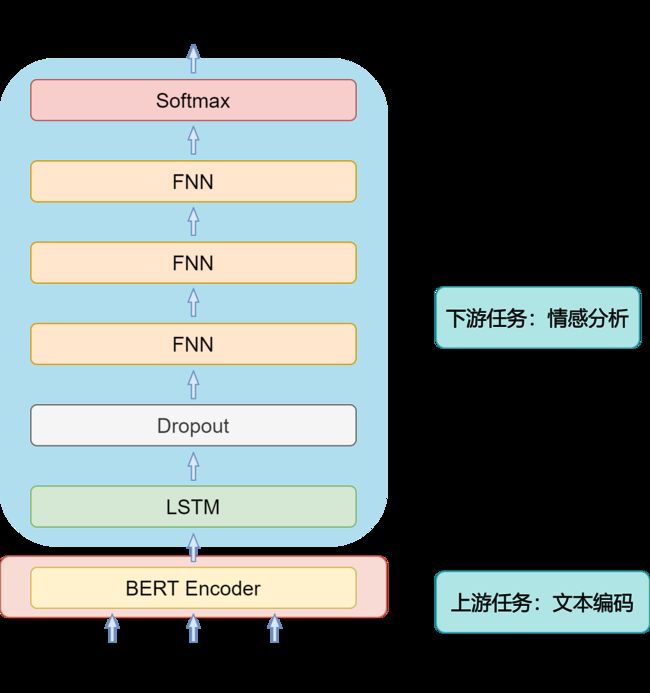
1.1 网络架构图
该网络主要使用上游预训练模型+下游情感分类模型组成
1.2 快速使用
该项目已开源在Github上,地址为 sentiment_analysis_Imdb
主要环境要求如下(环境不要太老基本没啥问题的)

下载该项目后,配置相对应的环境,在config.py文件中选择所需的语言模型和神经网络模型如下图所示,运行main.py文件即可

1.3 工程结构
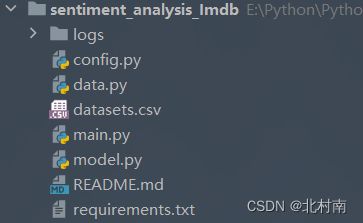
- logs 每次运行程序后的日志文件集合
- config.py 全局配置文件
- data.py 数据读取、数据清洗、数据格式转换、制作DataSet和DataLoader
- main.py 主函数,负责全流程项目运行,包括语言模型的转换,模型的训练和测试
- model.py 神经网络模型的设计和读取
二、Config
看了很多论文源代码中都使用parser容器进行全局变量的配置,因此作者也照葫芦画瓢编写了config.py文件
import os
import sys
import time
import torch
import random
import logging
import argparse
from datetime import datetime
def get_config():
parser = argparse.ArgumentParser()
'''Base'''
parser.add_argument('--num_classes', type=int, default=2)
parser.add_argument('--model_name', type=str, default='roberta',
choices=['bert', 'roberta', 'glove', 'fasttext', 'word2vce', 'elmo', 'gpt'])
parser.add_argument('--method_name', type=str, default='lstm',
choices=['gru', 'rnn', 'bilstm', 'textcnn', 'lstm', 'fnn'])
'''Optimization'''
parser.add_argument('--train_batch_size', type=int, default=8)
parser.add_argument('--test_batch_size', type=int, default=32)
parser.add_argument('--num_epoch', type=int, default=50)
parser.add_argument('--lr', type=float, default=1e-5)
parser.add_argument('--weight_decay', type=float, default=0.01)
'''Environment'''
parser.add_argument('--device', type=str, default='cuda')
parser.add_argument('--backend', default=False, action='store_true')
parser.add_argument('--workers', type=int, default=0)
parser.add_argument('--timestamp', type=int, default='{:.0f}{:03}'.format(time.time(), random.randint(0, 999)))
args = parser.parse_args()
args.device = torch.device(args.device)
'''logger'''
args.log_name = '{}_{}_{}.log'.format(args.model_name, args.method_name,
datetime.now().strftime('%Y-%m-%d_%H-%M-%S')[2:])
if not os.path.exists('logs'):
os.mkdir('logs')
logger = logging.getLogger()
logger.setLevel(logging.INFO)
logger.addHandler(logging.StreamHandler(sys.stdout))
logger.addHandler(logging.FileHandler(os.path.join('logs', args.log_name)))
return args, logger
三、Data
3.1 数据准备
首先需要下载IMDB数据集,并对其进行初步处理,其处理过程可参考一下文章IMDB数据预处理
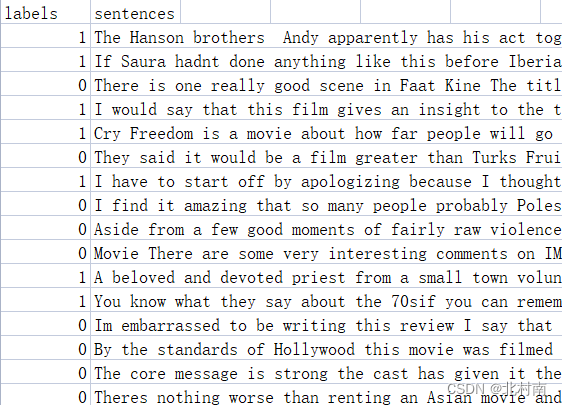
也可以直接从Github上获取已处理好的数据集,处理好的数据格式如下
3.2 数据预处理
由于IMDB数据量非常庞大,使用全数据的训练时间非常长(算力好的小伙伴可忽略),因此这里使用10%的数据量进行训练
data = pd.read_csv('datasets.csv', sep=None, header=0, encoding='utf-8', engine='python')
len1 = int(len(list(data['labels'])) * 0.1)
labels = list(data['labels'])[0:len1]
sentences = list(data['sentences'])[0:len1]
# split train_set and test_set
tr_sen, te_sen, tr_lab, te_lab = train_test_split(sentences, labels, train_size=0.8)3.3 制作DataSet
划分训练集和测试集之后就可以制作自己的DataSet
# Dataset
train_set = MyDataset(tr_sen, tr_lab, method_name, model_name)
test_set = MyDataset(te_sen, te_lab, method_name, model_name)MyDataset的结构如下
- 使用split方法将每个单词提取出来作为后续bertToken的输入
- 后续制作DataLoader需要使用collate_fn函数因此需要重写__getitem__方法
class MyDataset(Dataset):
def __init__(self, sentences, labels, method_name, model_name):
self.sentences = sentences
self.labels = labels
self.method_name = method_name
self.model_name = model_name
dataset = list()
index = 0
for data in sentences:
tokens = data.split(' ')
labels_id = labels[index]
index += 1
dataset.append((tokens, labels_id))
self._dataset = dataset
def __getitem__(self, index):
return self._dataset[index]
def __len__(self):
return len(self.sentences)3.4 制作DataLoader
得到DataSet之后就可以制作DataLoader了
- 首先需要编写my_collate函数,该函数的功能是对每一个batch的数据进行处理
- 在这里的数据处理是将文本数据进行Tokenizer化作为后续Bert模型的输入
- 通过计算可得知80%句子的长度低于320,因此将句子长度固定为320,多截少补
- partial是Python偏函数,使用该函数后,my_collate的输入参数只有一个batch
def my_collate(batch, tokenizer):
tokens, label_ids = map(list, zip(*batch))
text_ids = tokenizer(tokens,
padding=True,
truncation=True,
max_length=320,
is_split_into_words=True,
add_special_tokens=True,
return_tensors='pt')
return text_ids, torch.tensor(label_ids) # DataLoader
collate_fn = partial(my_collate, tokenizer=tokenizer)
train_loader = DataLoader(train_set, batch_size=train_batch_size, shuffle=True, num_workers=workers,
collate_fn=collate_fn, pin_memory=True)
test_loader = DataLoader(test_set, batch_size=test_batch_size, shuffle=True, num_workers=workers,
collate_fn=collate_fn, pin_memory=True)到此我们就完成制作了DataLoader,后续从DataLoader中可获取一个个batch经Tokenizer化后的数据
四、Language model
对于网络模型来说,只能接受数字数据类型,因此我们需要建立一个语言模型,目的是将每个单词变成一个向量,每个句子变成一个矩阵。关于语言模型,其已经发展历史非常悠久了(发展历史如下),其中Bert模型是Google大神出的具有里程碑性质的模型,因此本篇博客也主要采用此模型

所用的模型都是通过API从 Hugging Face官网 中直接下载的
Hugging Face中有非常多的好用的语言模型,小伙伴们也可尝试其他模型

使用AutoModel.from_pretrained接口下载预训练模型
使用AutoTokenizere.from_pretrained接口下载预训练模型的分词器
# Create model
if args.model_name == 'bert':
self.tokenizer = AutoTokenizer.from_pretrained('bert-base-uncased')
self.input_size = 768
base_model = AutoModel.from_pretrained('bert-base-uncased')
elif args.model_name == 'roberta':
self.tokenizer = AutoTokenizer.from_pretrained('roberta-base', add_prefix_space=True)
self.input_size = 768
base_model = AutoModel.from_pretrained('roberta-base')
else:
raise ValueError('unknown model')下载创建好Bert之后,在训练和测试的时候,每次从DataLoadr中获取一个个经过Tokenizer分词之后Batch的数据,随后将其投放到语言模型中
- ** input :input的数据是Tokenizer化后的数据如{ 'input_id' : ~ , 'token_type_ids' : ~ , 'attention_mask' : ~},**是将里面的三个dict分成一个个独立的dict,即{ 'input_id' : ~} ,{ 'token_type_ids' : ~} ,{ 'attention_mask' : ~}
- raw_outputs获取的是Bert的输出,Bert的输出主要有四个,其中last_hidden_state表示的是最后一层隐藏层的状态,也就是每个单词的Token的集合
raw_outputs = self.base_model(**inputs)
tokens = raw_outputs.last_hidden_state到此,上游语言模型全部结束,得到了一个个经过Bert后维度为[batch大小,句子长度,单词维度]的数据
五、Neural network model
关于RNN的原理解释,小伙伴可以看以下文章
【Deep Learning 7】RNN循环神经网络
5.1 RNN
Bilstm、lstm、gru本质上来说都是属于RNN模型,因此我们就以RNN模型为例子看看上游任务的数据是如何进入到下游文本分类的
RNN输入参数
- input_size:每个单词维度
- hidden_size:隐含层的维度(一般设置与句子长度一致)
- num_layers:RNN层数,默认是1,单层LSTM
- bias:是否使用bias
- batch_first:默认为False,如果设置为True,则表示第一个维度表示的是batch_size
- dropout:随机失活
- bidirectional:是否使用BiLSTM
由于是情感分析文本二分类任务,因此还需要一个FNN+Softmax模块进行分类预测
class Rnn_Model(nn.Module):
def __init__(self, base_model, num_classes, input_size):
super().__init__()
self.base_model = base_model
self.num_classes = num_classes
self.input_size = input_size
self.Rnn = nn.RNN(input_size=self.input_size,
hidden_size=320,
num_layers=1,
batch_first=True)
self.fc = nn.Sequential(nn.Dropout(0.5),
nn.Linear(320, 80),
nn.Linear(80, 20),
nn.Linear(20, self.num_classes),
nn.Softmax(dim=1))
for param in base_model.parameters():
param.requires_grad = (True)
再来看看RNN的传播过程
RNN输出参数
output, (hn, cn) = lstm(inputs)
output_last = output[:,-1,:]
- output:每个时间步输出
- output_last:最后一个时间步隐藏层神经元输出,也就是最终的特征表示
- hn:最后一个时间步隐藏层的状态
- cn:最后一个时间步隐藏层的遗忘门值
由于我们用不到hn和cn,因此直接使用_来代替
def forward(self, inputs):
# 上游任务
raw_outputs = self.base_model(**inputs)
cls_feats = raw_outputs.last_hidden_state
# 下游任务
outputs, _ = self.Rnn(cls_feats)
outputs = outputs[:, -1, :]
outputs = self.fc(outputs)
return outputs输出的outputs就是预测结果
5.2 GRU
其实熟悉了RNN网络模块之后,其他几个网络模块的也就非常好理解了
将nn.RNN修改为nn.GRU
class Gru_Model(nn.Module):
def __init__(self, base_model, num_classes, input_size):
super().__init__()
self.base_model = base_model
self.num_classes = num_classes
self.input_size = input_size
self.Gru = nn.GRU(input_size=self.input_size,
hidden_size=320,
num_layers=1,
batch_first=True)
self.fc = nn.Sequential(nn.Dropout(0.5),
nn.Linear(320, 80),
nn.Linear(80, 20),
nn.Linear(20, self.num_classes),
nn.Softmax(dim=1))
for param in base_model.parameters():
param.requires_grad = (True)
def forward(self, inputs):
raw_outputs = self.base_model(**inputs)
tokens = raw_outputs.last_hidden_state
gru_output, _ = self.Gru(tokens)
outputs = gru_output[:, -1, :]
outputs = self.fc(outputs)
return outputs5.3 LSTM
将nn.RNN修改为nn.LSTM
class Lstm_Model(nn.Module):
def __init__(self, base_model, num_classes, input_size):
super().__init__()
self.base_model = base_model
self.num_classes = num_classes
self.input_size = input_size
self.Lstm = nn.LSTM(input_size=self.input_size,
hidden_size=320,
num_layers=1,
batch_first=True)
self.fc = nn.Sequential(nn.Dropout(0.5),
nn.Linear(320, 80),
nn.Linear(80, 20),
nn.Linear(20, self.num_classes),
nn.Softmax(dim=1))
for param in base_model.parameters():
param.requires_grad = (True)
def forward(self, inputs):
raw_outputs = self.base_model(**inputs)
tokens = raw_outputs.last_hidden_state
lstm_output, _ = self.Lstm(tokens)
outputs = lstm_output[:, -1, :]
outputs = self.fc(outputs)
return outputs5.4 BILSTM
bilstm与其他几个网络模型稍微有点不同,需要修改的地方有三处
- 将nn.RNN修改为nn.LSTM
- 在nn.LSTM中添加 bidirectional=True
- 一个BILSTM是由两个LSTM组合而成的,因此FNN输入的维度也要乘2,即 nn.Linear(320 * 2, 80)
class BiLstm_Model(nn.Module):
def __init__(self, base_model, num_classes, input_size):
super().__init__()
self.base_model = base_model
self.num_classes = num_classes
self.input_size = input_size
# Open the bidirectional
self.BiLstm = nn.LSTM(input_size=self.input_size,
hidden_size=320,
num_layers=1,
batch_first=True,
bidirectional=True)
self.fc = nn.Sequential(nn.Dropout(0.5),
nn.Linear(320 * 2, 80),
nn.Linear(80, 20),
nn.Linear(20, self.num_classes),
nn.Softmax(dim=1))
for param in base_model.parameters():
param.requires_grad = (True)
def forward(self, inputs):
raw_outputs = self.base_model(**inputs)
cls_feats = raw_outputs.last_hidden_state
outputs, _ = self.BiLstm(cls_feats)
outputs = outputs[:, -1, :]
outputs = self.fc(outputs)
return outputs5.5 TextCNN
既然RNN可以做文本分类,那CNN呢?答案当然是可以的,早在2014年就出现了TextCNN,原模型如下

欸,看起来可能有点抽象,看另一篇解释该模型的图可能好理解多了
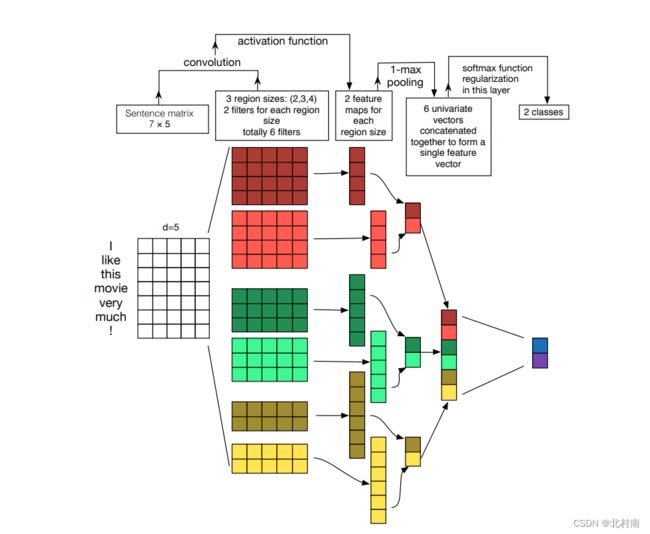
- 首先原句与卷积核分别为[2,768]、[3,768]、[4,768]且channels为2的filtet进行卷积运算得到6个一维向量
- 随后将每个一维向量中取出最大值,将这6个最大值拼接成[6,2]的Tensor
- 最后进行常规的分类预测
- 注意nn.ModuleList的Pytorch代码技巧,ModuleList可以理解为可存储卷积核的List
class TextCNN_Model(nn.Module):
def __init__(self, base_model, num_classes):
super().__init__()
self.base_model = base_model
self.num_classes = num_classes
for param in base_model.parameters():
param.requires_grad = (True)
# Define the hyperparameters
self.filter_sizes = [2, 3, 4]
self.num_filters = 2
self.encode_layer = 12
# TextCNN
self.convs = nn.ModuleList(
[nn.Conv2d(in_channels=1, out_channels=self.num_filters,
kernel_size=(K, self.base_model.config.hidden_size)) for K in self.filter_sizes]
)
self.block = nn.Sequential(
nn.Dropout(0.5),
nn.Linear(self.num_filters * len(self.filter_sizes), self.num_classes),
nn.Softmax(dim=1)
)
def conv_pool(self, tokens, conv):
tokens = conv(tokens)
tokens = F.relu(tokens)
tokens = tokens.squeeze(3)
tokens = F.max_pool1d(tokens, tokens.size(2))
out = tokens.squeeze(2)
return out
def forward(self, inputs):
raw_outputs = self.base_model(**inputs)
tokens = raw_outputs.last_hidden_state.unsqueeze(1)
out = torch.cat([self.conv_pool(tokens, conv) for conv in self.convs],
1)
predicts = self.block(out)
return predicts5.7 FNN
因为我们使用的是Bert模型,其模型本身是由12层Transformer组成,每层Transformer又由复杂的Attention网络组成,所以Bert模型本身就是一个非常好的网络模型,所以可能我不太需要加RNN、CNN这些操作,直接使用FNN或许也可以实现不错的效果(7.Result部分的消融实验也证实了该想法)。
在讲解这个代码之前,不得不再次提起Bert的输出了,输入一个句子,Bert的输出是
【CLS】token1 token 2 token3 token4 ... token n 【SEP】
token表示每个输入单词的向量 ,【CLS】表示整个句子的向量,做FNN需要整个句子的输入,因此我们需要获取的是【CLS】。【CLS】是隐层0号位的数据,因此具体获取【CLS】的代码是
cls_feats = raw_outputs.last_hidden_state[:, 0, :]完整FNN网络模块代码如下
class Transformer(nn.Module):
def __init__(self, base_model, num_classes, input_size):
super().__init__()
self.base_model = base_model
self.num_classes = num_classes
self.input_size = input_size
self.linear = nn.Linear(base_model.config.hidden_size, num_classes)
self.dropout = nn.Dropout(0.5)
self.softmax = nn.Softmax()
for param in base_model.parameters():
param.requires_grad = (True)
def forward(self, inputs):
raw_outputs = self.base_model(**inputs)
cls_feats = raw_outputs.last_hidden_state[:, 0, :]
predicts = self.softmax(self.linear(self.dropout(cls_feats)))
return predicts六、Train and Test
最后就是编写对应的训练函数和测试函数啦
可能有些小伙伴不懂tqdm函数,它的功能就是能显示动态进度,如下图所示
![]()
训练函数
注意要开启训练模式,即self.Mymodel.train(),如此有些层如dropout层参数可以进行更新
def _train(self, dataloader, criterion, optimizer):
train_loss, n_correct, n_train = 0, 0, 0
# Turn on the train mode
self.Mymodel.train()
for inputs, targets in tqdm(dataloader, disable=self.args.backend, ascii='>='):
inputs = {k: v.to(self.args.device) for k, v in inputs.items()}
targets = targets.to(self.args.device)
predicts = self.Mymodel(inputs)
loss = criterion(predicts, targets)
optimizer.zero_grad()
loss.backward()
optimizer.step()
train_loss += loss.item() * targets.size(0)
n_correct += (torch.argmax(predicts, dim=1) == targets).sum().item()
n_train += targets.size(0)
return train_loss / n_train, n_correct / n_train测试函数
注意要开启验证模式,即self.Mymodel.eval(),如此有些层如dropout参数不会更新了
def _test(self, dataloader, criterion):
test_loss, n_correct, n_test = 0, 0, 0
# Turn on the eval mode
self.Mymodel.eval()
with torch.no_grad():
for inputs, targets in tqdm(dataloader, disable=self.args.backend, ascii=' >='):
inputs = {k: v.to(self.args.device) for k, v in inputs.items()}
targets = targets.to(self.args.device)
predicts = self.Mymodel(inputs)
loss = criterion(predicts, targets)
test_loss += loss.item() * targets.size(0)
n_correct += (torch.argmax(predicts, dim=1) == targets).sum().item()
n_test += targets.size(0)
return test_loss / n_test, n_correct / n_test
最后在run函数中进行多次训练和获取最佳训练准确率
# Get the best_loss and the best_acc
best_loss, best_acc = 0, 0
for epoch in range(self.args.num_epoch):
train_loss, train_acc = self._train(train_dataloader, criterion, optimizer)
test_loss, test_acc = self._test(test_dataloader, criterion)
if test_acc > best_acc or (test_acc == best_acc and test_loss < best_loss):
best_acc, best_loss = test_acc, test_loss
七、Result
到了最快乐的炼丹时间,看看最终的效果怎么样
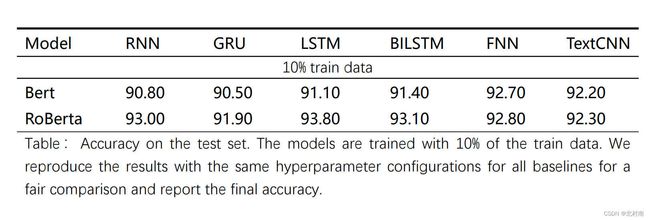
分析
- LSTM与BiLSTM的效果总体上要优于其他模型
- Roberta比Bert的效果好,Roberta不愧是升级版Bert
- FNN的效果好是因为Transformers本身就是LSTM的改进版
- Roberta+LSTM/BiLSTM的组合效果是最优的
- TextCNN的化效果有点鸡肋,因为CNN主要关注局部而RNN关注全局。此外还有一个思路是将RNN和CNN进行拼接结合,这样局部和全局都可以关注到,作者在其他数据集上跑过效果还不错的,感兴趣的小伙伴可以试试看
八、Conclusion
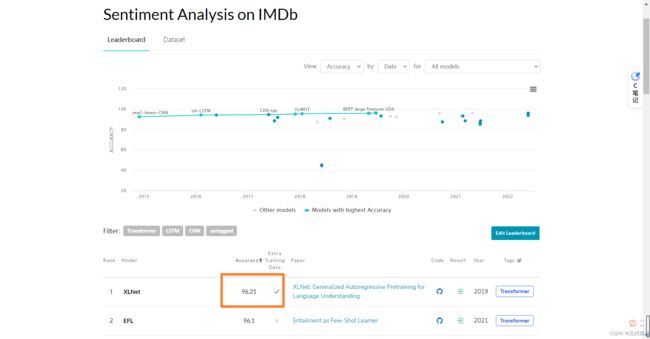
目前该数据集的SOTA是使用XLNet模型跑的96.21%,本模型只是用了10%的数据集+简单的网络架构+未调参就可以达到93%的准确率,效果还是不错的
最后,本文若有一些问题抑或大家有新的想法和需求,欢迎在评论区留言讨论