P7选修 深度学习介绍
7. 第 1 讲(选修):深度学习介绍_哔哩哔哩_bilibili


 Pytorch 中训练 DNN 的概述,首先是 Define Neural Network、Loss Function、Optimizer,这三步用到了 torch.nn 和 torch.optim 模块。加载数据主要用到 torch.utils.data.Dataset 和 torch.utils.data.DataLoader 模块。反复进行训练和验证,最后得到模型进行测试
Pytorch 中训练 DNN 的概述,首先是 Define Neural Network、Loss Function、Optimizer,这三步用到了 torch.nn 和 torch.optim 模块。加载数据主要用到 torch.utils.data.Dataset 和 torch.utils.data.DataLoader 模块。反复进行训练和验证,最后得到模型进行测试

手动设计
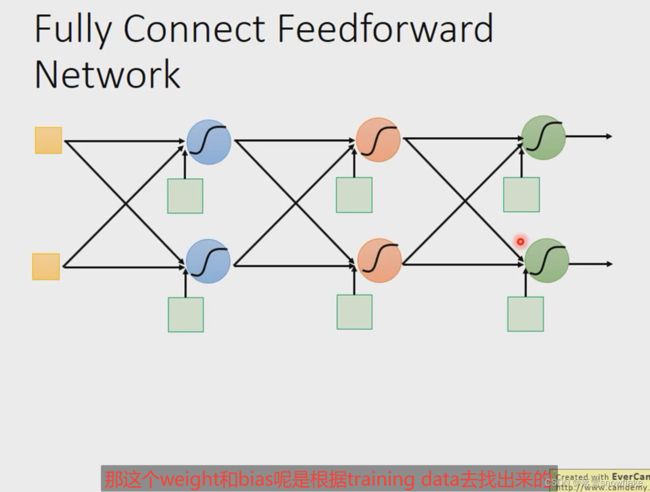

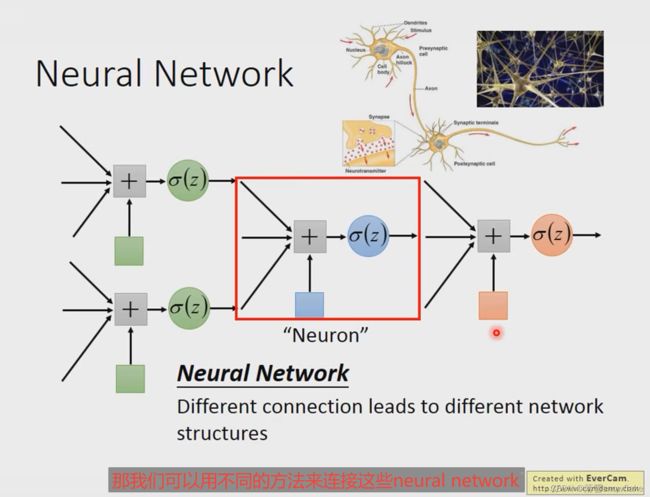
 Layer1 的所有输出都与 Layer2 的所有输入连接,所以叫全连接。
Layer1 的所有输出都与 Layer2 的所有输入连接,所以叫全连接。
Layer1 的输出给 Layer2,Layer2 的输出给 Layer3,所以叫前馈网络。




神经网络中的矩阵运算
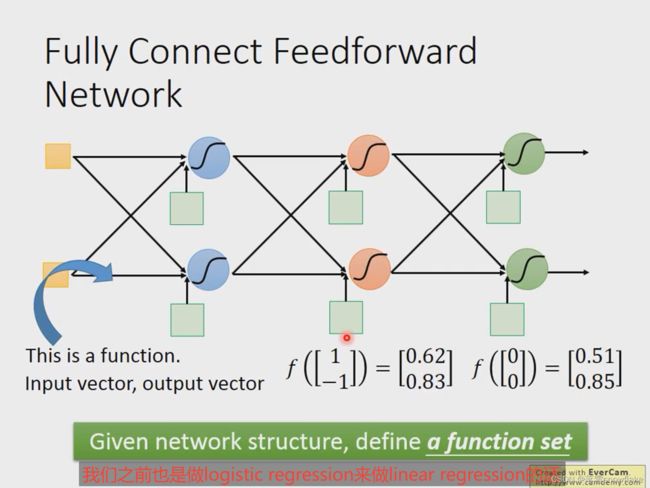
神经网络的计算可以用矩阵操作来表示,如下图是一个计算例子。



一个深度神经网络可以表示成一个函数,它的函数表达式如图所示。写成矩阵运算的好处是可以用 GPU 加速,普通的 GPU 只是做矩阵运算比较快(相比 CPU)。
可以使用GPU加速 ,矩阵运算


手写体识别例子

清晰度16*16,输入是236维,涂黑的地方是1,没有涂黑的地方就是0,output中每一个y是代表每一个输出数字的概率。




自己设计layer
每个neual如何设计




文字处理 正面情绪负面情绪
深度学习长久来看,具有一定的优势,只是一下子看起来没有那么显著。
它跟传统方法比起来的差异就没有那么惊人,但是还是有进步的。
能不能自动学level structure?其实是可以的,在经验算法中是可以这样的训,可以自动地找出Networks Stucture。不过还没有普及,比如阿法狗没有用这种方法。
能不能自己去设计network Structure?可不可以不要fully connected?可不可以layer1中地第一个连接到layer2中地第三个(可不可以乱写)?
可以,一个特殊的解法就是Convolutional Neural Network(CNN),

二、goodness of function
我们已经完成了第一步Neural Network,下面我们进行第二步goodness of function,即定义一个function地好坏。
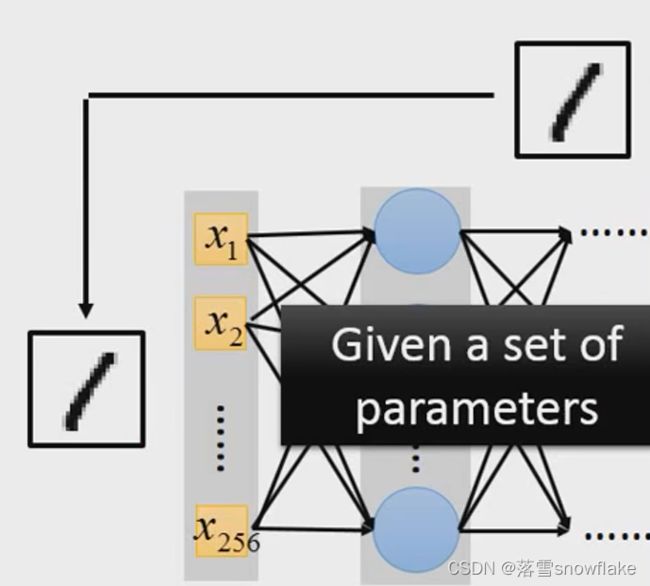
在neural network里面怎么决定一组参数它地好坏了?就假设给另一组参数
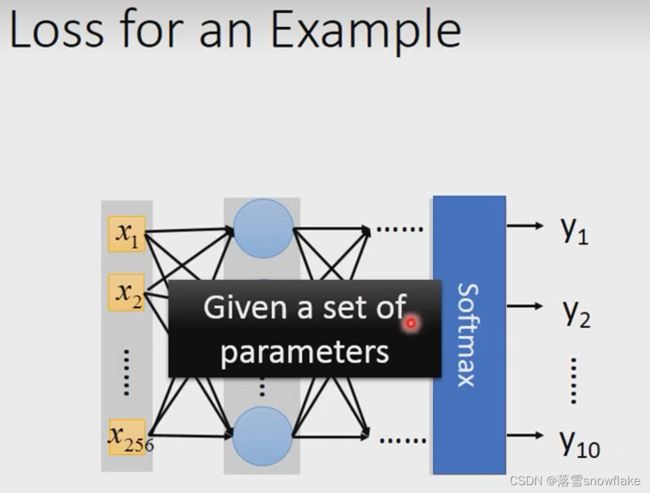
做手写数字图像辨识,有一张image,跟它地label,这张label告诉我们这是一个mortal class classsification地问题

所以label1告诉我们说 现在地target是一个10维vector,只有它在第一维对应到地数字1的地方,她的值是1,其他地方是0.

那就input这张image的piexl:

然后通过neuralwork后
得到一个output: 称之为y;

target称之为![]() :
:

接下来计算y和![]() 之间的cos值:
之间的cos值:
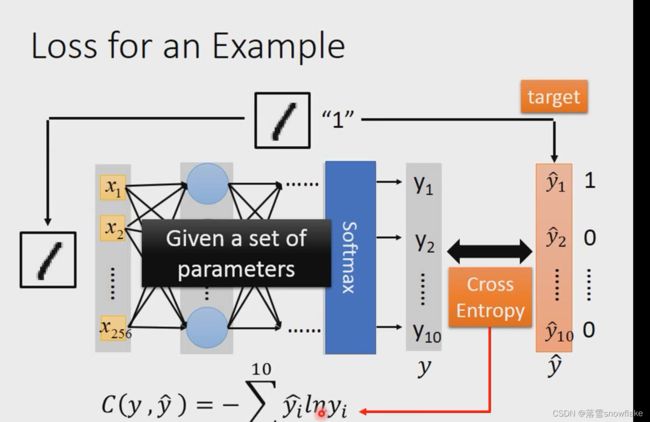
接下来调整netural work参数,让Cross Entropy越小越好。
当然整个training data里面不会只有一笔data,有大堆的data。
第一笔data计算出![]() ,
,
第二笔计算出![]() .;
.;
第三笔计算出![]() ;
;

一直到第n笔:

最后将所有的cross entropy值计算求和:

然后就是接下来在function set里面找一个function:它可以minimizes total loss L

或者是找一组network parameter:将它写成![]() :它可以minimize total loss L
:它可以minimize total loss L

怎么解这个问题呢?怎么找一个minimize total loss L
引用的方法就是Gradient Descent
在deep learing中用gradient design和linear regression那边什么都没有差别。
 中一大堆参数w1,w2,……b1,……,首先给定初始值0.2,-0.1,……,0.3,……;然后计算偏微分;
中一大堆参数w1,w2,……b1,……,首先给定初始值0.2,-0.1,……,0.3,……;然后计算偏微分;

将偏微分集合起来叫grady:

有了这些偏微分,就可以更新参数:

所有的参数减去learing rate:在图中写的是 。然后偏微分乘以它得到一个新的参数,然后计算它的gradient:
。然后偏微分乘以它得到一个新的参数,然后计算它的gradient:

然后再根据gradient再更新参数

然后按照这个计算下去就会得到一组好的参数,就做完network training了。



为什么要deep learning?

越deep越低

任何一个N维的Netural都可以用一个hidden layer的neural network来表示,只要这个hidden layer的内容足够多,它就可以表示成任何fuction;



