一篇文章学会读取、修改图的像素值以及图片的加法、融合、运算
思维导图
思考一下对一张图片的操作能有什么操作?无非就是改变他的内容,往细了说,就是修改图片每一个像素点的值。
那么如何修改一个像素点的值呢?首先肯定要知道这个像素点的通道数吧(即色彩模式),然后才能进行修改。而对于修改来说,要么把原来的值修改成你自己想的一个值,要么把原来的值修改成另一幅图上的值(图片的融合...)。
因此给出本篇的思维导图:
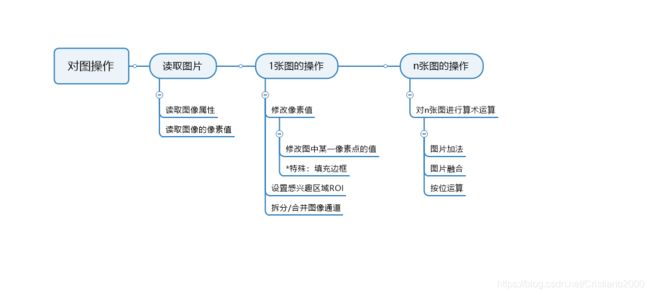
目录
1.读取图片
1.1读取图片属性
1.2读取图片的像素值
2.对1张图的操作
2.1修改像素值
2.1.1修改某一特定点的像素值
2.1.2为图片拓展边界
2.2设置ROI
2.3拆分/合并通道
3.对n张图的操作
3.1对n张图进行算术运算
3.1.1图片加法
3.1.2图片融合
3.1.3按位运算
1.读取图片
1.1读取图片属性
import numpy as np
import cv2 as cv
img = cv.imread('cr7.png')
# 返回图像的长与高,如果有色彩模式则返回通道的元组数,如果是灰度图则只有长、高
print(img.shape)
# 例如(512,512,3)或(512,512)
# 返回像素总数
print(img.size)
# 返回图像数据类型
print(img.dtype)
# 例如uint81.2读取图片的像素值
import numpy as np
import cv2 as cv
img = cv.imread('cr7.png')
#访问某像素的BGR三元组
print(img[0~*,0~*])
#访问某像素的B、G、R其中一值
print(img[0~*,0~*,0~2])
print(img.item(0~*,0~*,0~2)) # 速度更快但若要访问BGR三值得一个一个输出
2.对1张图的操作
2.1修改像素值
2.1.1修改某一特定点的像素值
import numpy as np
import cv2 as cv
img = cv.imread('cr7.png')
img.itemset((0~*,0~*,0~2),0~255)2.1.2为图片拓展边界
- 语法:cv2.copyMakeBorder(src, top, bottom, left, right, borderType, value)
- src:源图片。
- top,bottom,left,right:相应方向上拓展的边界的宽度。
- borderType:定义要添加边框的类型。有如下几种:
| 参数 | 含义 | 展示 |
| cv2.BORDER_CONSTANT | 用指定值(暂设为i)填充为边界 | iii|abcde|iii |
| cv2.BORDER_REFLECT | 从最近边界值开始反射填充边界 | cba|abcde|edc |
| cv2.BORDER_REFLECT_101 | 以最近边界值为对称轴开始反射填充边界 | dcb|abcde|dcb |
| cv2.BORDER_WRAP | 以本行最远边界值开始顺序填充边界 | cde|abcde|abc |
| cv2.BORDER_REPLICATE | 上下左右都用各自最近边界值填充边界 | aaa|abcde|eee |
注意:展示只展示了一边,另一边也是一样的。
- value:只有borderType是'cv2.BORDER_CONSTANT'是才需要,形式为(B,G,R)。
范例:
import cv2 as cv
img1 = cv.imread('cr7.jpg')
replicate = cv.copyMakeBorder(img1,100,100,100,100,cv.BORDER_REPLICATE)
reflect = cv.copyMakeBorder(img1,100,100,100,100,cv.BORDER_REFLECT)
reflect101 = cv.copyMakeBorder(img1,100,100,100,100,cv.BORDER_REFLECT_101)
wrap = cv.copyMakeBorder(img1,100,100,100,100,cv.BORDER_WRAP)
BLUE = [255,0,0]
constant= cv.copyMakeBorder(img1,100,100,100,100,cv.BORDER_CONSTANT,value=BLUE)
while(1):
cv.imshow('replicate',replicate)
cv.imshow('reflect', reflect)
cv.imshow('reflect101', reflect101)
cv.imshow('wrap', wrap)
cv.imshow('constant', constant)
if cv.waitKey(20) & 0xFF == 27:
break
cv.destroyAllWindows()
运行结果:
2.2设置ROI
roi = img[280:340, 330:390]2.3拆分/合并通道
什么是通道?
通道是构成颜色的色彩空间,不同的色彩模式使用不同数量的颜色通道。
例如RGB是三通道模式,存在红色通道、蓝色通道、绿色通道。
单通道即为灰度图。
import cv2 as cv
img1 = cv.imread('cr7.jpg')
# 拆分
b,g,r = cv.split(img) # 第一种方式
b = img [:, :, 0] # 第二种方式
# 合并
img = cv.merge((b,g,r)) # 也就是说3张灰度图可以组成一张RGB彩色图**猜猜cv.imshow(b)运行结果是什么?
是一张充满着深蓝、浅蓝、各种蓝的像素组成的图片吗?
错,这里将RGB模式下的蓝色通道分离出来后变成了单通道模式,所以运行结果是一张灰度图。
3.对n张图的操作
3.1对n张图进行算术运算
3.1.1图片加法
①图像加法的作用?
一、采集图像的过程中可能会有噪音影响,因此多次采集同一图像,并相加后求平均值以得到清晰正确的图像。
二、多幅图像叠加做特效。
②图像加法的两种方式:
一、使用opencv函数的方法cv.add(),两数相加,上限255,超出255时为255。
二、使用numpy数组直接相加,两数相加,上限为255,超出255时对255取模。
import cv2 as cv
import numpy as np
img1 = cv.imread('cr7.png')
img2 = cv.imread('cr7.png')
img3 = cv.add(img1,img2)
img4 = img1 + img23.1.2图片融合
①图像融合的作用?区别于图像加法。
图像融合是为了在图片上显示更多的信息。
②图像融合的语法:
调用语法:
addWeighted(src1, alpha, src2, beta, gamma, dst=None, dtype=None)参数说明:
- src1, src2:需要融合相加的两副大小和通道数相等的图像
- alpha:src1的权重
- beta:src2的权重
- gamma:gamma修正系数,不需要修正设置为0,具体请参考《图像处理gamma修正(伽马γ校正)的原理和实现算法》
- dst:可选参数,输出结果保存的变量,默认值为None,如果为非None,输出图像保存到dst对应实参中,其大小和通道数与输入图像相同,图像的深度(即图像像素的位数)由dtype参数或输入图像确认。
- dtype:可选参数,输出图像数组的深度,即图像单个像素值的位数(如RGB用三个字节表示,则为24位),选默认值None表示与源图像保持一致。
- 返回值:融合相加的结果图像
————————————————
原文链接:https://blog.csdn.net/LaoYuanPython/article/details/109143281
③范例:
import cv2 as cv
import numpy as np
img1 = cv.imread('cr7.jpg')
img2 = cv.imread('azr.jpg')
img3 = cv.addWeighted(img1,0.5,img2,0.8,0)
cv.imshow('img3',img3)
cv.waitKey(0)
cv.destroyAllWindows()

3.1.3按位运算
本节将介绍如何提取一张图片的部分并将其放在另一张图片上。
基本操作思想:
- 制作一个掩膜将图一中我们不想要的部分覆盖,提取我们想要的部分,设为ROI。
- 制作这个掩膜的反转将图二中ROI区域所在的像素覆盖,从而提取出图二的其他部分。
- 将这两个提出的部分结合,形成我们想要的最终图形。
①那么就需要来了解一下掩膜是什么:
用选定的图像、图形或物体,对处理的图像(全部或局部)进行遮挡,来控制图像处理的区域或处理过程。用于覆盖的特定图像或物体称为掩模或模板。
数字图像处理中,图像掩模主要用于:
①提取感兴趣区,用预先制作的感兴趣区掩模与待处理图像相乘,得到感兴趣区图像,感兴趣区内图像值保持不变,而区外图像值都为0。
②屏蔽作用,用掩模对图像上某些区域作屏蔽,使其不参加处理或不参加处理参数的计算,或仅对屏蔽区作处理或统计。
③结构特征提取,用相似性变量或图像匹配方法检测和提取图像中与掩模相似的结构特征。
④特殊形状图像的制作。 ——————百度百科
简单来说,掩膜就是一块有洞洞的黑布,把这块黑布盖在图像上后,剩下能看见的(也就是洞洞透出来的)就是我们想要的部分。
②如何制作掩膜?
对图像先后进行灰度处理与阈值化处理后得到的就是掩膜。
——灰度处理:
imgGray = cv.cvtColor(img,cv.COLOR_BGR2GRAY)——阈值化处理:
基本思想:给定一组数据与一个阈值,依次比较数组中的每一个值与阈值,并依据比较的结果对数组中的值进行处理。
语法:
ret, mask = cv.threshold( src, thresh, maxval, type[, dst] )
- src:源图像
- thresh:阈值
- maxval:最大值
- type:阈值操作的类型,类型有如下
图源:https://blog.csdn.net/guduruyu/article/details/68059450


随便解释一个吧,如THRESH_BINARY:
将值与阈值(图二中的虚线)进行比较,如果值大于阈值则将值置为最大值。如果值小于阈值,则设为0。
③那么如何将掩膜反转?
# 制作掩膜
ret, mask = cv.threshold(imgGray, 10, 255, cv.THRESH_BINARY)
# 掩膜反转
mask_inv = cv.bitwise_not(mask)④如何使用掩膜提取出图片中我们仅需要的部分?
img_need = cv.bitwise_and(img,img,mask = mask)⑤范例:
import numpy as np
import cv2 as cv
# 加载两张图片
img1 = cv.imread('messi5.jpg')
img2 = cv.imread('opencv-logo-white.png')
# 现在创建logo的掩码,并同时创建其相反掩码
img2gray = cv.cvtColor(img2,cv.COLOR_BGR2GRAY)
ret, mask = cv.threshold(img2gray, 10, 255, cv.THRESH_BINARY)
mask_inv = cv.bitwise_not(mask)
# 仅从logo图像中提取logo区域
img2_fg = cv.bitwise_and(img2,img2,mask = mask)
# 现在将ROI中logo的区域涂黑
img1_bg = cv.bitwise_and(img1,img1,mask = mask_inv)
# 将logo放入ROI并修改主图像
dst = cv.add(img1_bg,img2_fg)
img1[0:rows, 0:cols ] = dst
cv.imshow('res',img1)
cv.waitKey(0)
cv.destroyAllWindows()