一文看懂 “极大似然估计” 与 “最大后验估计” —— 最大后验估计篇
- 本文历次修订后全长 2万8000余字,受到 CSDN 博文字数限制,故切分两篇发布,所以现在是两文看懂了… 前篇介绍参数估计背景和极大似然估计;本篇介绍最大后验估计和两种方法对比
- 请务必先看前文:一文看懂 “极大似然估计” 与 “最大后验估计” —— 极大似然估计篇
文章目录
- 4. 最大后验估计(MAP)
-
- 4.1 后验概率密度
- 4.2 样本条件概率密度 p ( X ∣ D ) p(X|\mathcal{D}) p(X∣D) (模型分布)
-
- 4.2.1 贝叶斯分类器
- 4.2.2 联系参数后验概率密度 p ( θ ∣ D ) p(\theta|\mathcal{D}) p(θ∣D)
- 4.2.3 小结
- 4.3 最大后验估计的步骤
- 4.4 示例
-
- 4.4.1 已知先验概率和条件概率
- 4.4.2 朴素贝叶斯
- 5. MLE和MAP的联系
4. 最大后验估计(MAP)
- 考虑这个问题:贾跃亭老板下周回国的概率为多少?如果从频率派的角度看,因为贾老板跑路后从未回国,只要他不回来,概率就始终为0;但事实上贾老板下周回国的概率可能只是很小而非零,若哪天他的造车计划大获成功或者乐视网情况转好,其回国的可能性还会大大提升,这就比较符合贝叶斯学派的观点。 频率派的一个问题,就是在小的的观测数据集下,最大化似然函数值的方法容易与观测数据过度拟合
- 记贾老板下周回国为事件 Θ \Theta Θ,现在我们认为这是一个小概率事件,概率为小量 p ( Θ ) p(\Theta) p(Θ),可以看作一种先验知识。随着时间的推移,发生了事件 X X X,比如法拉第新车开始量产,或者法拉第资金链断裂,这时贾老板回国的可能性就会变化,对 Θ \Theta Θ 的估计也应当有相应调整,变成后验概率 p ( Θ ∣ X ) p(\Theta|X) p(Θ∣X)
- 最大后验估计寻求使后验概率最大的参数值,相比最大似然估计,这种方法融入了要估计量的先验分布。先验概率包含了人们根据以往经验对事件的一些初步认识,当某些事件 X X X 发生后,会影响人们原来的认识,贝叶斯公式可以对事件先验概率进行修正,得到事件的后验概率
- 最大后验估计的示意图如下

4.1 后验概率密度
- 利用贝叶斯公式,可以得到先验概率 p ( θ ) p(\theta) p(θ) 和 后验概率 p ( θ ∣ x ) p(\theta|x) p(θ∣x) 之间的关系如下
p ( θ ∣ x ) = p ( θ , x ) p ( x ) = p ( θ ) p ( x ∣ θ ) p ( x ) p(\theta|x) = \frac{p(\theta,x)}{p(x)} = \frac{p(\theta)p(x|\theta)}{p(x)} p(θ∣x)=p(x)p(θ,x)=p(x)p(θ)p(x∣θ) 这个公式提供了利用先验概率 p ( θ ) p(\theta) p(θ) 和条件概率函数值 p ( x ∣ θ ) p(x|\theta) p(x∣θ) 来计算后验概率 p ( θ ∣ x ) p(\theta|x) p(θ∣x) 的方法 - 在后验概率公式中,分母 p ( x ) = ∫ θ p ( x ∣ θ ) p ( θ ) d θ p(x) = \int_\theta p(x|\theta)p(\theta)d\theta p(x)=∫θp(x∣θ)p(θ)dθ,由于对 θ \theta θ 所在的参数空间整体进行了积分,因此不影响,有
p ( θ ∣ x ) ∝ p ( θ ) p ( x ∣ θ ) p(\theta|x) \propto p(\theta)p(x|\theta) p(θ∣x)∝p(θ)p(x∣θ) 可见,当事件 x x x 发生时,最大后验估计通过条件概率函数值 p ( x ∣ θ ) p(x|\theta) p(x∣θ) 对先验 p ( θ ) p(\theta) p(θ) 进行修正。经过整个数据集 D \mathcal{D} D 的修正后,后验概率密度
p ( θ ∣ D ) ∝ p ( θ ) p ( D ∣ θ ) p(\theta|\mathcal{D}) \propto p(\theta)p(\mathcal{D}|\theta) p(θ∣D)∝p(θ)p(D∣θ) 将在合理的估计值 θ ^ \hat{\theta} θ^ 位置形成尖峰

- 我们的目标是找出最大后验估计值 θ ^ \hat{\theta} θ^,即
θ ^ = arg max θ p ( θ ∣ D ) = arg max θ ∏ x i ∈ D p ( θ ) p ( x i ∣ θ ) = arg max θ [ l o g p ( θ ) + ∑ x i ∈ D l o g p ( x i ∣ θ ) ] = arg min θ [ − l o g p ( θ ) − ∑ x i ∈ D l o g p ( x i ∣ θ ) ] \begin{aligned} \hat{\theta} &= \argmax\limits_{\theta} p(\theta|\mathcal{D}) \\ &=\argmax\limits_{\theta}\prod\limits_{x_i\in\mathcal{D}}p(\theta)p(x_i|\theta) \\ &=\argmax\limits_{\theta}[logp(\theta)+\sum_{x_i\in\mathcal{D}}log p(x_i|\theta) ]\\ &=\argmin\limits_{\theta}[-logp(\theta) - \sum_{x_i\in\mathcal{D}}log p(x_i|\theta)] \end{aligned} θ^=θargmaxp(θ∣D)=θargmaxxi∈D∏p(θ)p(xi∣θ)=θargmax[logp(θ)+xi∈D∑logp(xi∣θ)]=θargmin[−logp(θ)−xi∈D∑logp(xi∣θ)]
4.2 样本条件概率密度 p ( X ∣ D ) p(X|\mathcal{D}) p(X∣D) (模型分布)
- 1.1 节中我们分析过,参数估计的目的是为了得到模型分布,即数据集条件下的样本分布 p ( X ∣ D ) p(X|\mathcal{D}) p(X∣D),这时我们必须明确 MAP 和 MLE 的区别
- MLE 中,参数 Θ \Theta Θ 是一个定值,模型分布仅由其取值 θ \theta θ 决定,而 θ \theta θ 仅由数据集 D \mathcal{D} D 决定,也就是只有一个样本条件概率密度 p ( X ∣ D ) = p ( X ∣ Θ ) p(X|\mathcal{D})=p(X|\Theta) p(X∣D)=p(X∣Θ)(似然函数)
- MAP 中,参数 Θ \Theta Θ 是一个分布 p ( Θ ∣ D ) p(\Theta|\mathcal{D}) p(Θ∣D), Θ ^ \hat{\Theta} Θ^ 的每一个取值 θ ^ \hat{\theta} θ^ 都唯一地决定了一个模型分布,为了整体考虑需要对 θ \theta θ 做积分,即 p ( X ∣ D ) = ∫ p ( X , θ ∣ D ) d θ p(X|\mathcal{D}) = \int p(X,\theta|\mathcal{D})d\theta p(X∣D)=∫p(X,θ∣D)dθ,因此 MAP 方法最终往往要做一个复杂的积分
- 下面通过一个贝叶斯决策的例子说明 p ( X ∣ D ) p(X|\mathcal{D}) p(X∣D) 的作用
4.2.1 贝叶斯分类器
-
考虑构造一个贝叶斯分类器,使用贝叶斯公式计算
类后验概率如下
p ( w i ∣ x , D ) = p ( x ∣ w i , D ) p ( w i ∣ D ) p ( x ) = p ( x ∣ w i , D ) p ( w i ∣ D ) ∑ j p ( x ∣ w j , D ) p ( w j ∣ D ) \begin{aligned} p(w_i|x,\mathcal{D}) &= \frac{p(x|w_i,\mathcal{D})p(w_i|\mathcal{D})}{p(x)} \\ &= \frac{p(x|w_i,\mathcal{D})p(w_i|\mathcal{D})}{\sum_j p(x|w_j,\mathcal{D})p(w_j|\mathcal{D})} \end{aligned} p(wi∣x,D)=p(x)p(x∣wi,D)p(wi∣D)=∑jp(x∣wj,D)p(wj∣D)p(x∣wi,D)p(wi∣D) 贝叶斯分类器使用这个类后验概率密度函数预测任意样本 x x x 的类别,下面化简符号- 通常我们认为类先验概率可以事前得到,所以把 p ( w i ∣ D ) p(w_i|\mathcal{D}) p(wi∣D) 简写为 p ( w i ) p(w_i) p(wi)
- 像 1.1 节中一样将数据集 D \mathcal{D} D 按样本类别划分为,并假设第 i i i 类的样本对第 j ≠ i j\neq i j=i 类的类条件概率 p ( w j ∣ x , D ) p(w_j|x,\mathcal{D}) p(wj∣x,D) 没有任何影响,这样 p ( x ∣ w i , D ) p(x|w_i,\mathcal{D}) p(x∣wi,D) 就可以简化为 p ( x ∣ w i , D i ) p(x|w_i,\mathcal{D}_i) p(x∣wi,Di)
符号化简后,上式变为
p ( w i ∣ x , D ) = p ( x ∣ w i , D i ) p ( w i ) ∑ j p ( x ∣ w j , D j ) p ( w j ) p(w_i|x,\mathcal{D}) = \frac{p(x|w_i,\mathcal{D}_i)p(w_i)}{\sum_j p(x|w_j,\mathcal{D}_j)p(w_j)} p(wi∣x,D)=∑jp(x∣wj,Dj)p(wj)p(x∣wi,Di)p(wi) 假设一共有 c c c 个类别,这里计算类后验概率密度的核心是估计 c c c 个类条件概率密度p ( x ∣ w i , D ) p(x|w_i,\mathcal{D}) p(x∣wi,D),根据我们的假设,这里相当于处理 c c c 个独立的问题,每个问题都在单一的类别下发生,形式为已知一组从 p ( X ) p(X) p(X) 中 i.i.d 采样的样本 D \mathcal{D} D,估计条件概率 p ( X ∣ D ) p(X|\mathcal{D}) p(X∣D)
4.2.2 联系参数后验概率密度 p ( θ ∣ D ) p(\theta|\mathcal{D}) p(θ∣D)
-
考虑上一节最后提出的任意一个独立问题,基本目标是计算 p ( X ∣ D ) p(X|\mathcal{D}) p(X∣D),并且使得它尽量靠近 p ( X ) p(X) p(X),这里可以把它表示为 p ( X , θ ∣ D ) p(X,\theta|\mathcal{D}) p(X,θ∣D) 的边缘概率密度,即
p ( X ∣ D ) = ∫ p ( X , θ ∣ D ) d θ = ∫ p ( X ∣ θ , D ) p ( θ ∣ D ) d θ = ∫ p ( X ∣ θ ) p ( θ ∣ D ) d θ ( 测 试 样 本 X 的 选 取 和 D 独 立 ) \begin{aligned} p(X|\mathcal{D}) &= \int p(X,\theta|\mathcal{D})d\theta\\ &= \int p(X|\theta,\mathcal{D})p(\theta|\mathcal{D})d\theta \\ &= \int p(X|\theta)p(\theta|\mathcal{D})d\theta \space\space\space(测试样本X的选取和 \mathcal{D} 独立)\\ \end{aligned} p(X∣D)=∫p(X,θ∣D)dθ=∫p(X∣θ,D)p(θ∣D)dθ=∫p(X∣θ)p(θ∣D)dθ (测试样本X的选取和D独立) 注意其中出现了 MAP 过程中得到的后验概率分布 p ( θ ∣ D ) p(\theta|\mathcal{D}) p(θ∣D)。这是贝叶斯估计中最核心的公式,它将类条件概率密度p ( X ∣ D ) p(X|\mathcal{D}) p(X∣D)(注意这是 p ( X ∣ w i , D ) p(X|w_i,\mathcal{D}) p(X∣wi,D) 的简写)和未知参数的后验概率密度p ( θ ∣ D ) p(\theta|\mathcal{D}) p(θ∣D) 联系起来。如果 MAP 的估计结果为 θ ^ \hat{\theta} θ^(即 p ( θ ∣ D ) p(\theta|\mathcal{D}) p(θ∣D) 在 θ ^ \hat{\theta} θ^ 处形成最显著的尖峰),且- p ( X ∣ θ ) p(X|\theta) p(X∣θ) 光滑
- p ( θ ∣ D ) p(\theta|\mathcal{D}) p(θ∣D) 积分拖尾的影响足够小(就是说 p ( θ ∣ D ) p(\theta|\mathcal{D}) p(θ∣D) 在 θ ^ \hat{\theta} θ^ 处足够尖锐)
则可以如下估计类条件概率密度为 p ( x ∣ w i , D ) ≈ p ( x ∣ w i , θ ^ ) p(x|w_i,\mathcal{D})\approx p(x|w_i,\hat{\theta}) p(x∣wi,D)≈p(x∣wi,θ^) 当以上两条件不满足时,即我们对 θ ^ \hat{\theta} θ^ 的把握不是很强时,上面的式子指导我们应该对所有的 θ \theta θ 求积分来得到满意的 p ( X ∣ D ) p(X|\mathcal{D}) p(X∣D) (注意其实是类条件概率密度 p ( x ∣ w i , D i ) p(x|w_i,\mathcal{D}_i) p(x∣wi,Di) 的简写)
4.2.3 小结
-
欲基于贝叶斯估计方法构造贝叶斯分类器,一些基本假设如下
- 条件概率密度 p ( x ∣ Θ ) p(x|\Theta) p(x∣Θ) 的数学形式完全已知,只是 Θ \Theta Θ 取值 θ \theta θ 未知
- 参数向量 Θ \Theta Θ 的 先验概率 p ( Θ ) p(\Theta) p(Θ) 包含了我们对 θ \theta θ 的全部先验知识
- 其余的关于参数向量 Θ \Theta Θ 的信息包含在 i.i.d 采样的数据集 D \mathcal{D} D 中,他们都服从未知的概率密度函数 p ( X ) p(X) p(X)
问题的核心在于计算后验概率密度函数 p ( θ ∣ D ) p(\theta|\mathcal{D}) p(θ∣D),一旦得到就能如下计算(类)后验概率
p ( X ∣ D ) = ∫ p ( X ∣ θ ) p ( θ ∣ D ) d θ (1) p(X|\mathcal{D}) = \int p(X|\theta)p(\theta|\mathcal{D})d\theta \tag{1} p(X∣D)=∫p(X∣θ)p(θ∣D)dθ(1) 根据贝叶斯公式,有
p ( θ ∣ D ) = p ( D ∣ θ ) p ( θ ) ∫ p ( D ∣ θ ) p ( θ ) d θ (2) p(\theta|\mathcal{D}) = \frac{p(\mathcal{D}|\theta)p(\theta)}{\int p(\mathcal{D}|\theta)p(\theta)d\theta} \tag{2} p(θ∣D)=∫p(D∣θ)p(θ)dθp(D∣θ)p(θ)(2) 再利用样本间独立性假设,有
p ( D ∣ θ ) = ∏ k = 1 n p ( x k ∣ θ ) (3) p(\mathcal{D}|\theta) = \prod_{k=1}^n p(x_k|\theta) \tag{3} p(D∣θ)=k=1∏np(xk∣θ)(3) 这样就完成了对问题的正式解答。构造的贝叶斯分类器示意图如下

-
这里可以考虑和最大似然估计的关系
- 假设 p ( D ∣ θ ) p(\mathcal{D}|\theta) p(D∣θ) 在 θ ^ \hat{\theta} θ^ 处有一个很尖的峰值
- 若先验概率 p ( θ ^ ) p(\hat{\theta}) p(θ^) 非零且在附近邻域变化不大,则根据等式 (2) , p ( θ ^ ∣ D ) p(\hat{\theta}|\mathcal{D}) p(θ^∣D) 处也是一个峰值
- 则根据等式(1), p ( x ∣ D ) p(x|\mathcal{D}) p(x∣D) 将趋近于 p ( x ∣ θ ^ ) p(x|\hat{\theta}) p(x∣θ^),后者就是最大似然法优化的最大似然函数
4.3 最大后验估计的步骤
- 找出参数的最大后验估计
- 和最大似然估计步骤类似,先找出后验概率密度 p ( θ ∣ D ) p(\theta|\mathcal{D}) p(θ∣D) (或其正相关形式)的表示,然后通过令偏导数为 0 找出使后验概率最大的估计值 θ ^ \hat{\theta} θ^
- 有时我们也可以直接从数据集 D \mathcal{D} D 中估计出先验概率 p ( θ ) p(\theta) p(θ) 和条件概率函数 p ( D ∣ θ ) p(\mathcal{D}|\theta) p(D∣θ),进而直接计算 θ ^ \hat{\theta} θ^ 各种取值下的后验概率(比如朴素贝叶斯),然后直接取最大即可
- 如有需要,可以进一步计算类条件概率密度构造贝叶斯分类器
4.4 示例
4.4.1 已知先验概率和条件概率
-
假设有5个袋子,每个袋子中都有无限饼干(樱桃或柠檬味),已知5个袋子中两种口味混合比例和被拿到的概率如下
- 10%概率拿到;樱桃100%
- 20%概率拿到;樱桃75% + 柠檬25%
- 40%概率拿到;樱桃50% + 柠檬50%
- 20%概率拿到;樱桃25% + 柠檬75%
- 10%概率拿到;柠檬100%
现在从同一个袋子中连续拿到了两个柠檬饼干,那么这个袋子最可能是哪个袋子?
分析:设 θ i \theta_i θi 表示拿到第 i i i 个袋子,各个袋子被拿到的概率就是先验 p ( θ i ) p(\theta_i) p(θi),我们需要根据事件 X X X:“连续从一个袋子中拿到两个饼干” 这件事在每个袋子中发生的似然性来调整它们。
-
设从第 i i i 个袋子中拿出柠檬饼干的概率为 p i p_i pi,拿到第 i i i 个袋子的概率为 q i q_i qi,根据后验概率公式,优化目标是:
arg max θ p ( θ ∣ x ) = arg max θ p ( θ i ) p ( X ∣ θ i ) = arg max θ q i ∗ p i 2 \begin{aligned} \argmax\limits_{\theta}p(\theta|x) &= \argmax\limits_{\theta}p(\theta_i)p(X|\theta_i) \\ &= \argmax\limits_{\theta}q_i*p_i^2 \end{aligned} θargmaxp(θ∣x)=θargmaxp(θi)p(X∣θi)=θargmaxqi∗pi2 分别把五个袋子的数据带入,发现第4个袋子的后验概率最大,因此选择第4个袋子
4.4.2 朴素贝叶斯
- 朴素贝叶斯是一种基于最大后验估计的分类算法。设输入空间 X ∈ R n \mathcal{X}\in \mathbb{R}^n X∈Rn 为 n n n 维向量集合,输出空间 Y = { c 1 , c 2 , . . . , c k } \mathcal{Y} = \{c_1,c_2,...,c_k\} Y={c1,c2,...,ck}。 X , Y X,Y X,Y 分别是定义在 X , Y \mathcal{X,Y} X,Y 上的随机向量/变量,从真实分布 P ( X , Y ) P(X,Y) P(X,Y) 独立同分布地采样得到训练数据集 T = { ( x 1 , y 1 ) , ( x 2 , y 2 ) , . . . , ( x N , y N } T = \{(\pmb{x}_1,y_1),(\pmb{x}_2,y_2),...,(\pmb{x}_N,y_N\} T={(xxx1,y1),(xxx2,y2),...,(xxxN,yN}
- 这是一种生成式方法,利用数据分布估计先验概率 p ( Y = c k ) p(Y=c_k) p(Y=ck) 和条件概率函数 p ( X = x ∣ Y = c k ) p(X=x|Y=c_k) p(X=x∣Y=ck),进而得到联合概率分布 P ( X , Y ) P(X,Y) P(X,Y) 用于预测
条件独立性假设:考察条件概率分布 P ( X = x ∣ Y = c k ) = P ( X ( 1 ) = x ( 1 ) , X ( 2 ) = x ( 2 ) , . . . , X ( n ) = x ( n ) ∣ Y = c k ) , k = 1 , 2 , . . . K P(X=x|Y=c_k) = P(X^{(1)}=x^{(1)},X^{(2)}=x^{(2)},...,X^{(n)}=x^{(n)}|Y=c_k), \space\space k=1,2,...K P(X=x∣Y=ck)=P(X(1)=x(1),X(2)=x(2),...,X(n)=x(n)∣Y=ck), k=1,2,...K 假设 x ( j ) x^{(j)} x(j) 可取值有 S j S_j Sj 个, j = 1 , 2 , . . . , n j=1,2,...,n j=1,2,...,n, Y Y Y 可取值有 K K K 个,那么参数个数最多为 K ∏ j = 1 n S j K \prod_{j=1}^n S_j K∏j=1nSj,参数数量为指数级,因此直接估计 P ( X , Y ) P(X,Y) P(X,Y) 是不可行的。为此朴素贝叶斯作了条件独立性假设,即
P ( X = x ∣ Y = c k ) = P ( X ( 1 ) = x ( 1 ) , . . . . , X ( n ) = x ( n ) ∣ Y = c k ) = ∏ j = 1 n P ( X ( j ) = x ( j ) ∣ Y = c k ) \begin{aligned} P(X=x|Y=c_k) &= P(X^{(1)}=x^{(1)},....,X^{(n)}=x^{(n)}|Y=c_k) \\ &= \prod_{j=1}^n P(X^{(j)}=x^{(j)}|Y=c_k) \end{aligned} P(X=x∣Y=ck)=P(X(1)=x(1),....,X(n)=x(n)∣Y=ck)=j=1∏nP(X(j)=x(j)∣Y=ck) ** ** - 得到联合分布 P ( X , Y ) P(X,Y) P(X,Y) 后,就可以利用贝叶斯公式得到后验概率,再用 MAP 方式估计未见样本类别,即
y = f ( x ) = arg max c k P ( Y = c k ) ∏ j P ( X ( j ) = x ( j ) ∣ Y = c k ) ∑ k P ( Y = c k ) ∏ j P ( X ( j ) = x ( j ) ) ∣ Y = c k ) = arg max c k P ( Y = c k ) ∏ j P ( X ( j ) = x ( j ) ∣ Y = c k ) k = 1 , 2 , . . . , K \begin{aligned} y = f(\pmb{x}) &= \argmax_{c_k}\frac{P(Y=c_k)\prod_jP(X^{(j)}=x^{(j)}|Y=c_k)}{\sum_kP(Y=c_k)\prod_jP(X^{(j)}=x^{(j)})|Y=c_k)} \\ &= \argmax_{c_k}P(Y=c_k)\prod_jP(X^{(j)}=x^{(j)}|Y=c_k) \end{aligned} \space \space\space \space k=1,2,...,K y=f(xxx)=ckargmax∑kP(Y=ck)∏jP(X(j)=x(j))∣Y=ck)P(Y=ck)∏jP(X(j)=x(j)∣Y=ck)=ckargmaxP(Y=ck)j∏P(X(j)=x(j)∣Y=ck) k=1,2,...,K 其中先验概率 P ( Y = c k ) P(Y=c_k) P(Y=ck) 和样本每一维(特征)的条件概率 P ( X ( j ) = a j l ) P(X^{(j)}=a_{jl}) P(X(j)=ajl) 都使用极大似然估计方式估计得到,即
P ( Y = c k ) = ∑ i = 1 N I ( y i = c k ) N k = 1 , 2 , . . . , K P(Y=c_k) = \frac{\sum_{i=1}^N I(y_i=c_k)}{N} \space\space\space k=1,2,...,K P(Y=ck)=N∑i=1NI(yi=ck) k=1,2,...,K 设第 j j j 个特征 x ( j ) x^{(j)} x(j) 可能取值的集合为 { a j 1 , a j 2 , . . . , a j S j } \{a_{j1},a_{j2},...,a_{jS_j}\} {aj1,aj2,...,ajSj},条件概率估计为
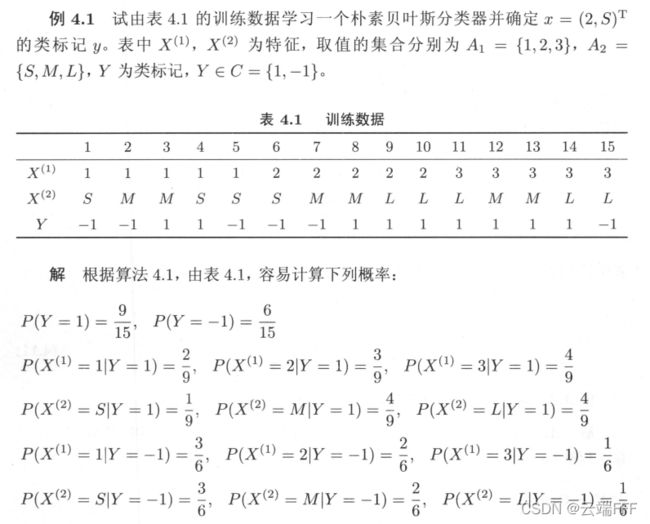
P ( X ( j ) = a j l ∣ Y = c k ) = ∑ i = 1 N I ( x i ( j ) = a j l , y i = c k ) ∑ i = 1 N I ( y i = c k ) j = 1 , 2 , . . . , n ; l = 1 , 2 , . . . . , S j ; k = 1 , 2 , . . . , K P(X^{(j)}=a_{jl}|Y=c_k) = \frac{\sum_{i=1}^N I(x_i^{(j)}=a_{jl},y_i=c_k)}{\sum_{i=1}^N I(y_i=c_k)} \\ \space \\ j = 1,2,...,n; \space\space\space l = 1,2,....,S_j;\space\space\space k=1,2,...,K P(X(j)=ajl∣Y=ck)=∑i=1NI(yi=ck)∑i=1NI(xi(j)=ajl,yi=ck) j=1,2,...,n; l=1,2,....,Sj; k=1,2,...,K 式中 x i ( j ) x_i^{(j)} xi(j) 是第 i i i 个样本的第 j j j 个特征; a j l a_{jl} ajl 是第 j j j 个特征可能取的第 l l l 个值 - 示例

5. MLE和MAP的联系
-
看贝叶斯公式
p ( Θ ∣ X ) = p ( X ∣ Θ ) p ( Θ ) p ( X ) p(\Theta|X) = \frac{p(X|\Theta)p(\Theta)}{p(X)} p(Θ∣X)=p(X)p(X∣Θ)p(Θ) 随着数据量的增加,条件概率函数值 p ( X ∣ Θ ) p(X|\Theta) p(X∣Θ) 对先验 p ( Θ ) p(\Theta) p(Θ) 的修正越来越大,参数分布会越来越向数据靠拢,先验的影响力会越来越小。因此在数据量趋向无限时,MAP 得到的参数后验概率一般会收敛到狄拉克函数,这时 MLE 和 MAP 最终会得到相同的估计

-
如果先验是均匀分布,则贝叶斯方法MAP等价于频率方法MLE,因为先验是均匀分布本质上表示对事物没有任何预判
-
看最大后验估计的优化目标
θ ^ = arg min θ [ − l o g p ( θ ) − ∑ i = 1 n l o g p ( x i ∣ θ ) ] \hat{\theta} = \argmin\limits_{\theta}[-logp(\theta) - \sum_{i=1}^nlog p(x_i|\theta)] θ^=θargmin[−logp(θ)−i=1∑nlogp(xi∣θ)] 可见这里第二项 arg min θ ∑ i = 1 n l o g p ( x i ∣ θ ) \argmin\limits_{\theta}\sum_{i=1}^nlog p(x_i|\theta) θargmin∑i=1nlogp(xi∣θ) 正是最大似然估计的优化目标 NLL,所以MLE和MAP在优化时的不同就是在于先验项 − l o g p ( θ ) -logp(\theta) −logp(θ)。如果我们假设先验是一个高斯分布,即
p ( θ ) = c o n s t a n t × e x p ( − θ 2 2 σ 2 ) p(\theta) = constant \times exp(-\frac{\theta^2}{2\sigma^2}) p(θ)=constant×exp(−2σ2θ2)于是有
− l o g p ( θ ) = c o n s t a n t + θ 2 2 σ 2 -logp(\theta) = constant + \frac{\theta^2}{2\sigma^2} −logp(θ)=constant+2σ2θ2 可见,在MAP中使用一个高斯分布的先验等价于在MLE中使用一个L2正则项